DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
DataX 也是使用这种可插拔的设计,采用了 Framework + Plugin 的架构设计
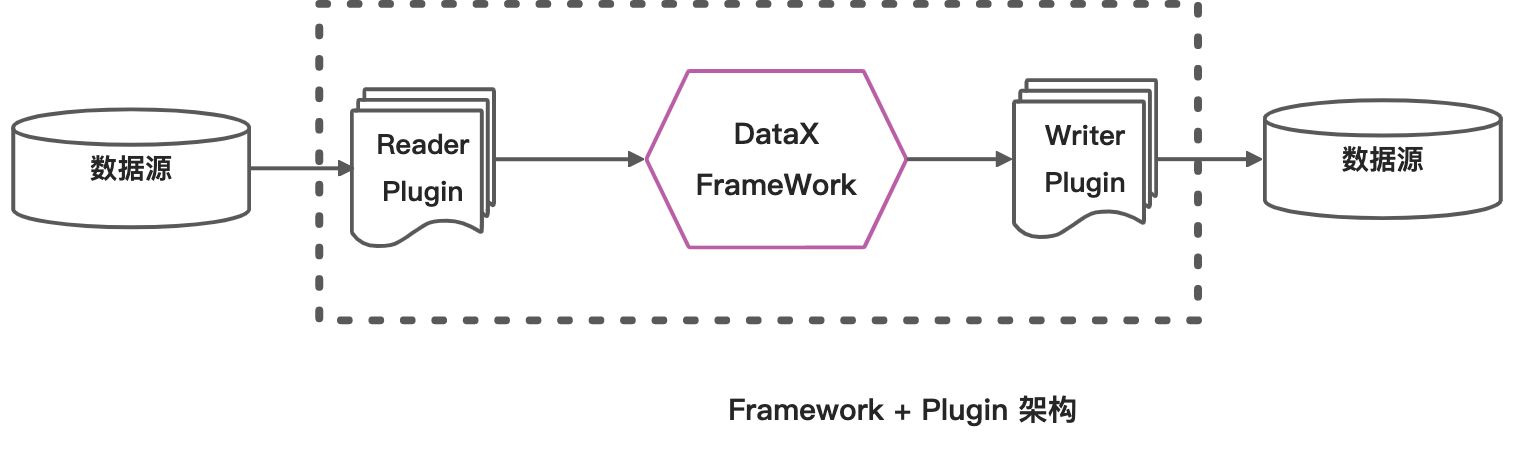
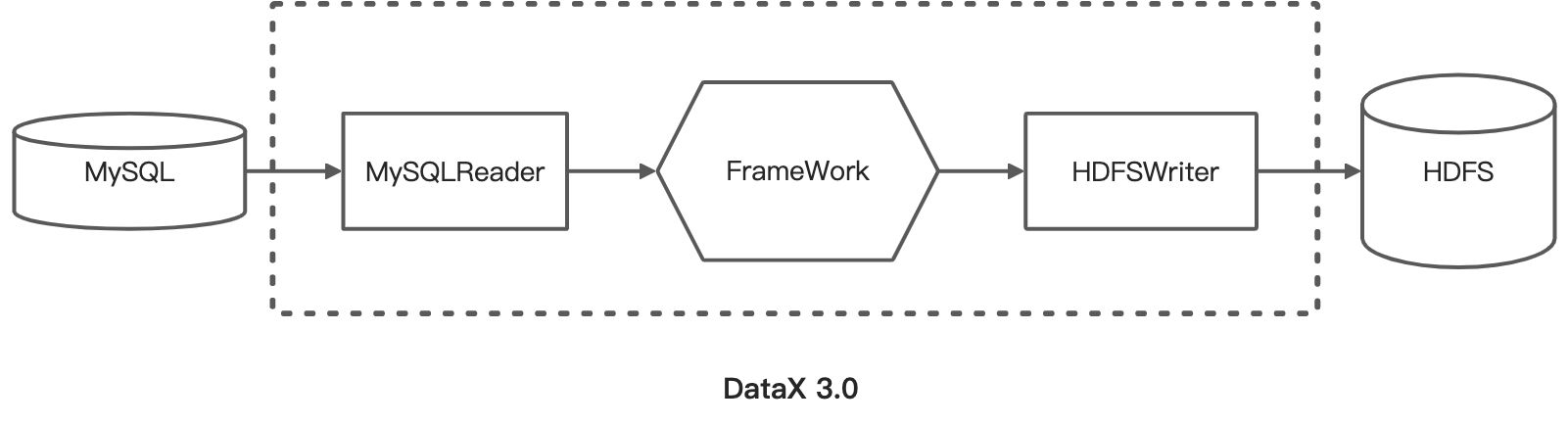
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
Job执行
首先,Job根据不同的分片策略,将任务分为多个任务组,每个组包含等量的子任务。然后提交给调度器,调度器启动后,执行读写逻辑线程。如下图示: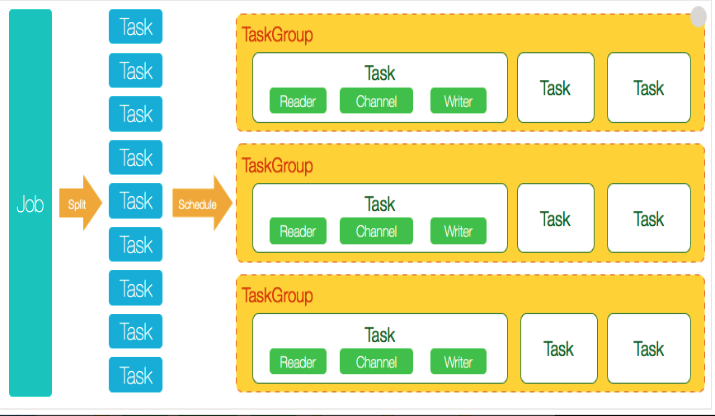
大体的交互流程如下示: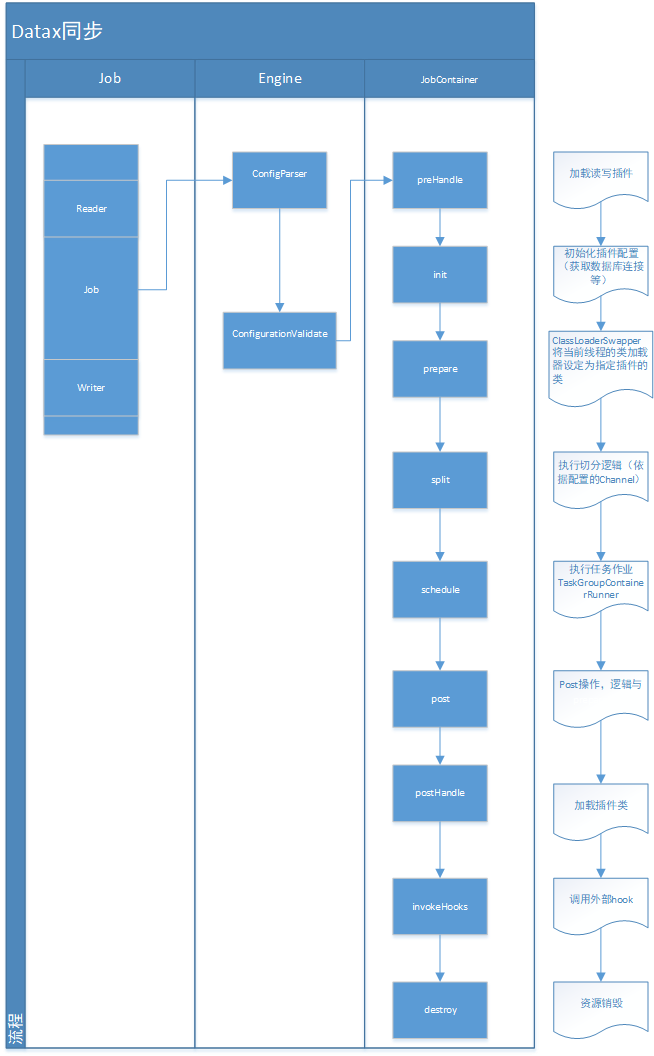
调用方式
运行
命令行调用:python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
其中,’datax.py’ 是python编写的调用入口。本地debug
Engine是DataX入口类,该类负责初始化Job或者Task的运行容器,并运行插件的Job或者Task逻辑。
com.alibaba.datax.core.Engine 的main方法。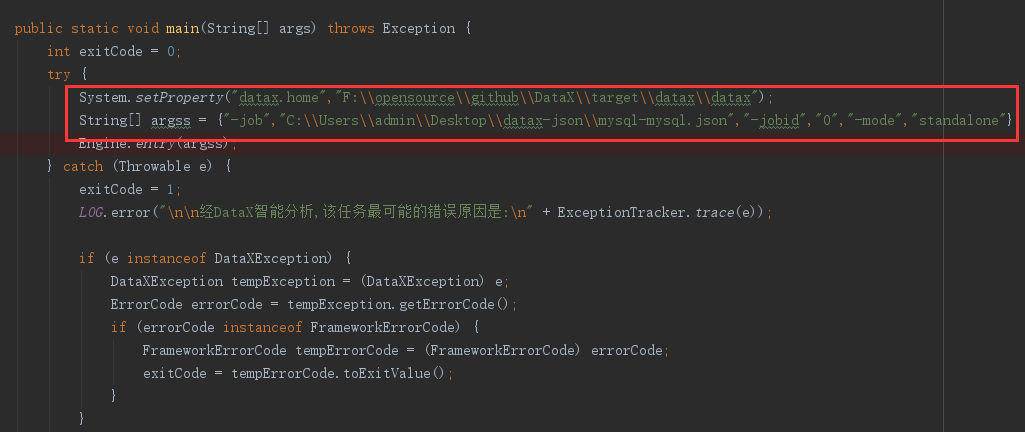
核心类介绍
JobContainer
jobContainer主要负责的工作全部在start()里面,包括init、prepare、split、scheduler、post以及destroy和statistics。
JobContainer的schedule首先完成的工作是把上一步reader和writer split的结果整合到具体taskGroupContainer中,同时不同的执行模式调用不同的调度策略,将所有任务调度起来。
将调度执行逻辑委派给AbstractScheduler的schedule(taskGroupConfigs),方法中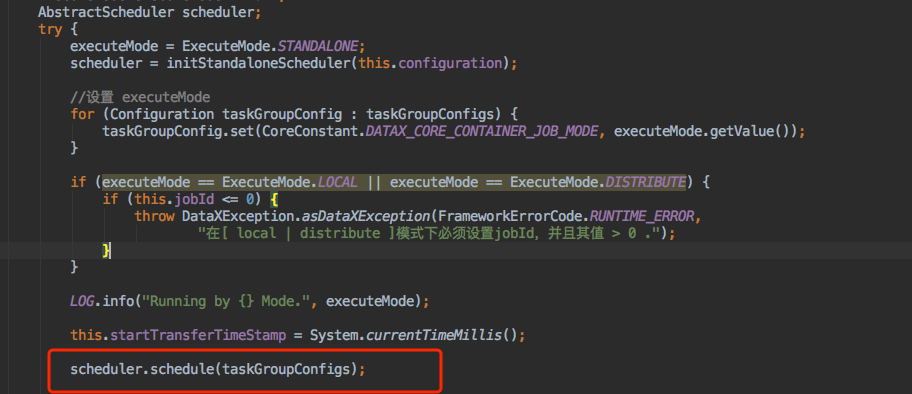
AbstractScheduler
AbstractScheduler的子类执行任务线程,使用固定大小线程池管理taskGroup。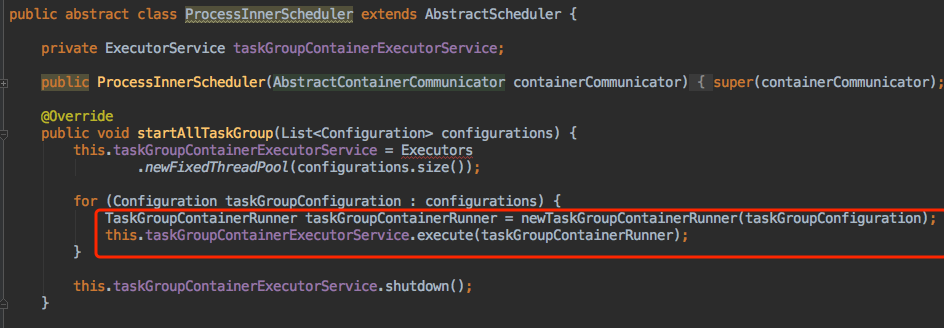
TaskGroupContainerRunner
TaskGroupContainerRunner的run方法,执行TaskGroupContainer的start方法。这样,一个任务组就开始在线程池中运行了。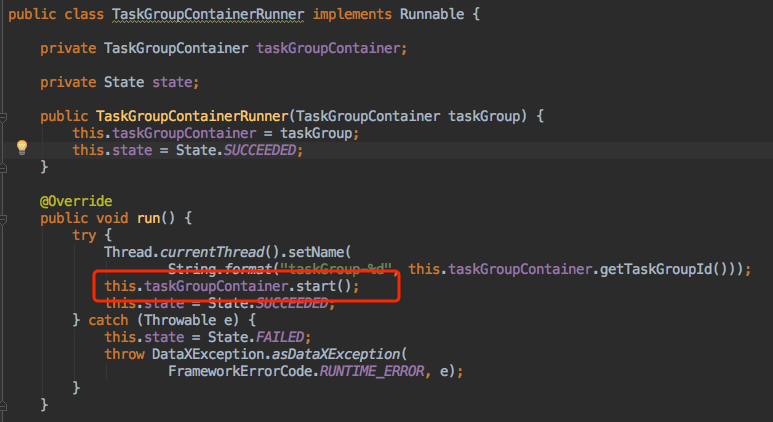
TaskExecutor
TaskExecutor是一个完整task的执行器,内部包含reader和writer线程。读写组件
以mysql为例。读写组件类图如下示: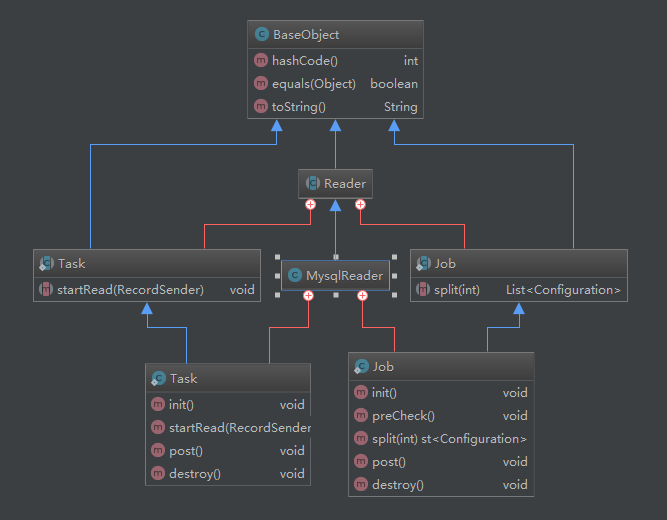
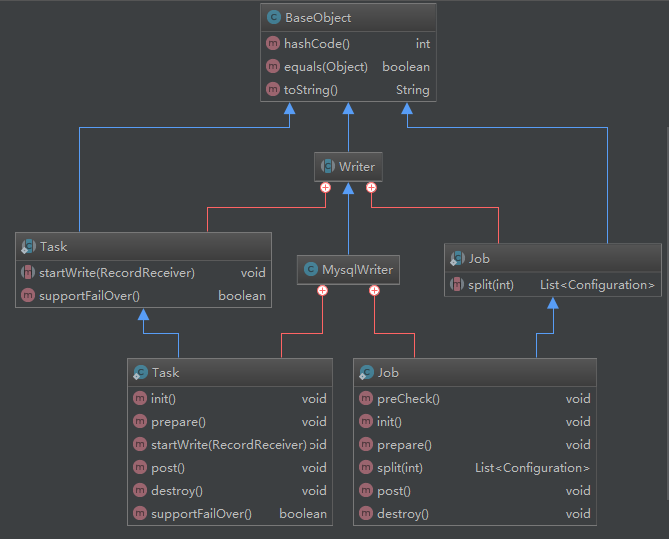
reader和writer内部结构类似,核心内部类Job和Task。
Job主要负责一系列的环境处理;Task完成了读取或写入的实现逻辑。
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"connection": [{"querySql": ["SELECT * FROM table1"],"jdbcUrl": ["jdbc:mysql://localhost:3306/datax?useSSL=false&useUnicode=true&characterEncoding=UTF-8"]}],"password": "root","username": "root"}},"writer": {"name": "mysqlwriter","parameter": {"column": ["*"],"writeMode": "update","preSql": ["delete from table2"],"connection": [{"jdbcUrl": "jdbc:mysql://localhost:3306/datax?useSSL=false&useUnicode=true&characterEncoding=UTF-8","table": ["table2"]}],"password": "root","username": "root"}}}],"setting": {"speed": {"byte": 1048576,"channel": 5}}}}
源码
fork了datax的源码,后续进行源码分析,增加代码注释。DataX源码分析地址
源码解析

若有收获,就点个赞吧
0 人点赞
