1、课程目标
- 1、掌握hbase相关概念
- 2、掌握搭建一个hbase集群
- 3、掌握hbase shell 命令行操作
- 4、掌握hbase的内部原理
- 5、掌握hbase寻址机制
- 6、掌握hbase的rowkey设计
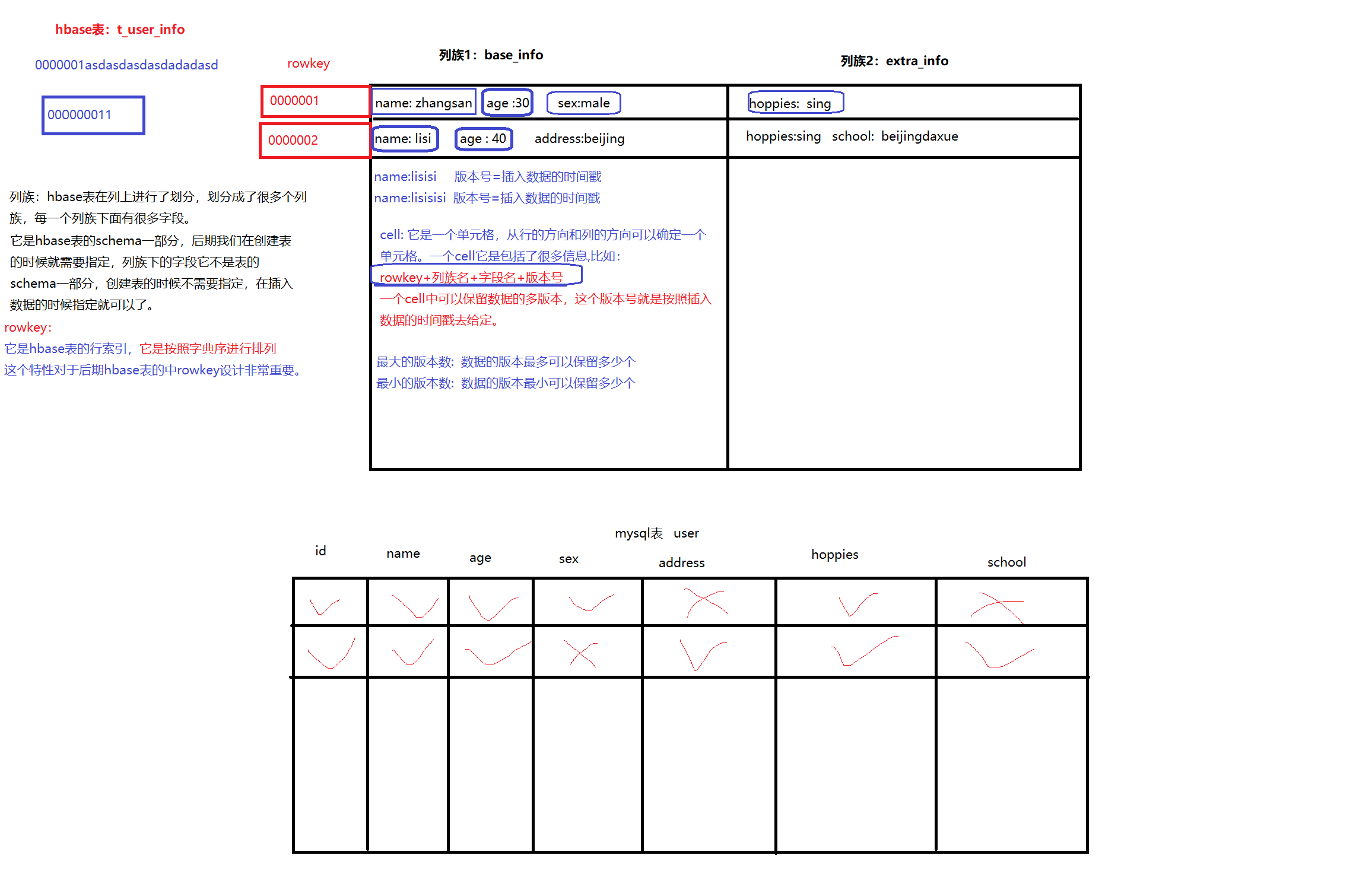
2、hbase概述
2.1、hbase是什么
hbase是基于hdfs进行数据的存储,具有高可靠、高性能、列存储、可伸缩、实时读写的nosql数据库。它可以存储海量数据,并且后期查询性能很多,可以实现上亿条数据的秒级返回。
2.2 、hbase表的特性
- 1、大
- hbase表可以存储海量数据
- 2、无模式
- mysql表中每一行数据他们的字段都是一样
- hbase表中不同的行可以有不同的列(字段)
- 3、面向列
- mysql表中的数据是基于行进行存储,把每一行数据写入到磁盘文件中
- hbase表中的数据是基于列进行存储,把相同列的数据写入到磁盘文件中
- 4、稀疏
- hbase表中为null的列,不占用实际的存储空间
- 5、数据的多版本
- hbase表中的数据在进行更新操作的时候,并没有直接把原始数据删除掉,而是保留数据的多个版本,这个数据的版本号就是按照数据插入时的时间戳去确定
- 6、数据类型单一
4、hbase集群结构
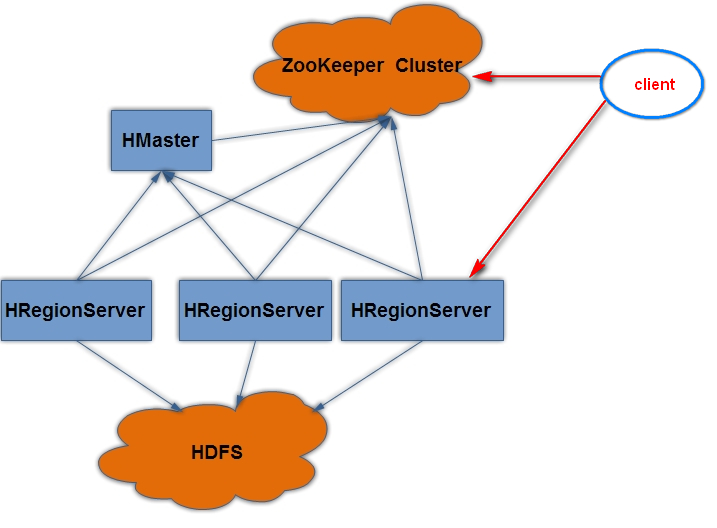
- 1、client
- 它就是hbase集群提供了一些客户端操作的表的api,后期通过这套api去操作hbase表的数据
- 2、zookeeper
- 作用
- 1、保证hbase集群的高可用
- 2、接受和保存hbase中HMaster和HRegionServer的注册和心跳信息
- 3、保存了hbase集群的元数据信息
- 4、它是所有hbase表的寻址入口
- 后期客户端程序要操作hbase表,必须要有连接上zk.
- 作用
- 3、HMaster
- 它是hbase集群的老大
- 作用
- 1、它会接受客户端的创建表和删除表的操作。
- 2、它会给HRegionServer小弟分配对应的region去管理。
- 3、实现HRegionServer负载均衡,也就是说避免某个HRegionServer管理的region过多
- 4、发送了挂掉的HRegionServer之后,把它所管理的region重新分配给其他的活着的HRegionServer
- 作用
- 它是hbase集群的老大
- 4、HRegionServer
- 它是hbase集群的小弟
- 作用
- 1、它会接受客端户的读写数据的请求。
- 2、它会接受HMaster给它分配的region,并且进行管理
- 3、它会切分在运行过程中变得过大的 region
- 作用
- 它是hbase集群的小弟
5、region
1、准备
- 先搭建zk和hadoop集群
- 2、下载对应的安装包
- http://archive.apache.org/dist/hbase/1.2.1/hbase-1.2.1-bin.tar.gz
- hbase-1.2.1-bin.tar.gz
- 3、规划安装目录
- /export/servers
- 4、上传安装包到服务器
- 5、解压安装包到指定的规划目录
- tar -zxvf hbase-1.2.1-bin.tar.gz -C /export/servers
- 6、重命名解压目录
- mv hbase-1.2.1 hbase
7、修改配置文件
- 1、需要把hadoop中配置文件引入进来
- 把hadoop/etc/hadoop/core-site.xml hdfs-site.xml 拷贝到hbase的conf目录
2、vim conf/hbase-env.sh
• #指定java环境变量export JAVA_HOME=/export/servers/jdk#指定hbase集群由外部的zk集群管理export HBASE_MANAGES_ZK=false
3、vim conf/hbase-site.xml
<!-- 指定hbase在HDFS上存储的路径 8020为Hadoop中core-site.xml中找到 或者是hdfs.xml --><property><name>hbase.rootdir</name><value>hdfs://node01:8020/hbase</value></property><!-- 指定hbase是分布式的 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- 指定zk的地址,多个用“,”分割 --><property><name>hbase.zookeeper.quorum</name><value>node01:2181,node02:2181,node03:2181</value></property>
4、vim regionservers
#指定哪些节点是HRegionServer
node02
node03- 5、vim backup-masters
#指定哪些是备用的HMaster
node02
- 1、需要把hadoop中配置文件引入进来
- 8、配置环境变量
export HBASE_HOME=/export/servers/hbase
export PATH=$PATH:$HBASE_HOME/bin 9、分发
scp -r hbase node02:/export/servers
scp -r hbase node03:/export/serversscp /etc/profile node02:/etcscp /etc/profile node03:/etc
10、让所有节点的环境变量生效
- 在所有节点执行
- source /etc/profile
- 在所有节点执行
6、hbase集群的启动和停止
6.1、启动
- 1、先启动zk和hdfs
- 2、进入hbase/bin
- start-hbase.sh
- 你在哪里启动就在当前机器产生一个HMaster
- 通过regionservers文件中指定的主机名来启动HRegionServer节点
- 通过backup-masters文件中指定的主机名来启动备用的HMaster
- start-hbase.sh
6.2、停止
- 1、进入到hbase/bin
- stop-hbase.sh
7、访问hbase集群的web管理界面
- 1、启动好hbase集群
- 访问web页面
- hmaster主机名或者ip地址:16010
- 访问web页面
8、hbase shell的命令行操作
- 通过执行hbase/bin/hbase shell
实现对hbase表做增删改查
- 1、创建一个hbase表
create ‘t_user_info’,’base_info’,’extra_info’ - 2、查看hbase集群有哪些表
list - 3、查看表的描述信息
describe ‘t_user_info’ - 4、修改表的属性
alter ‘t_user_info’,NAME => ‘base_info’,VERSIONS => ‘3’ - 5、添加数据
put ‘t_user_info’,’0001’,’base_info:name’,’zhangsan’
put ‘t_user_info’,’0001’,’base_info:age’,’30’
put ‘t_user_info’,’0001’,’base_info:sex’,’male’
put ‘t_user_info’,’0001’,’extra_info:school’,’bejing’ - 6、查询
- scan
- 全表扫描
scan ‘t_user_info’
- 全表扫描
- get
get ‘t_user_info’,’0001’ ——> select * from user where id =1
get ‘t_user_info’,’0001’,{COLUMN => ‘base_info’}
get ‘t_user_info’,’0001’,{COLUMN => ‘base_info:name’}
get ‘t_user_info’,’0001’,{COLUMN => ‘base_info:age’, VERSIONS => 2}
get ‘t_user_info’,’0001’,{COLUMN => ‘base_info:age’, TIMESTAMP => 1546229642754}
- scan
7、删除数据
delete ‘t_user_info’,’0001’,’base_info:age’deleteall 't_user_info','0001'
8、删除表
disable ‘t_user_info’
drop ‘t_user_info’
- 1、创建一个hbase表
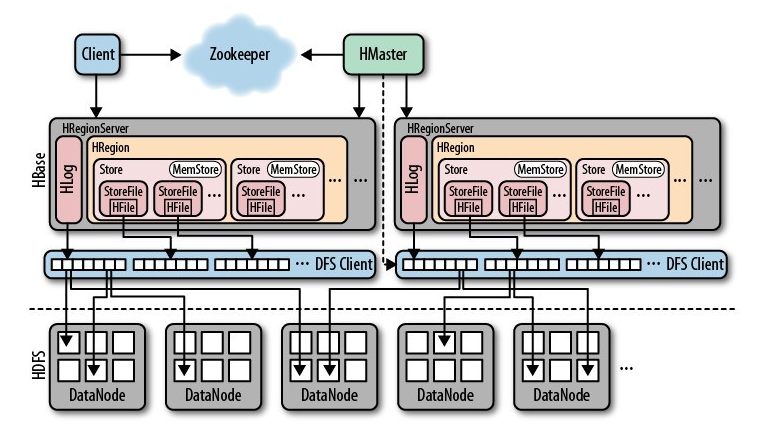
9、hbase的内部原理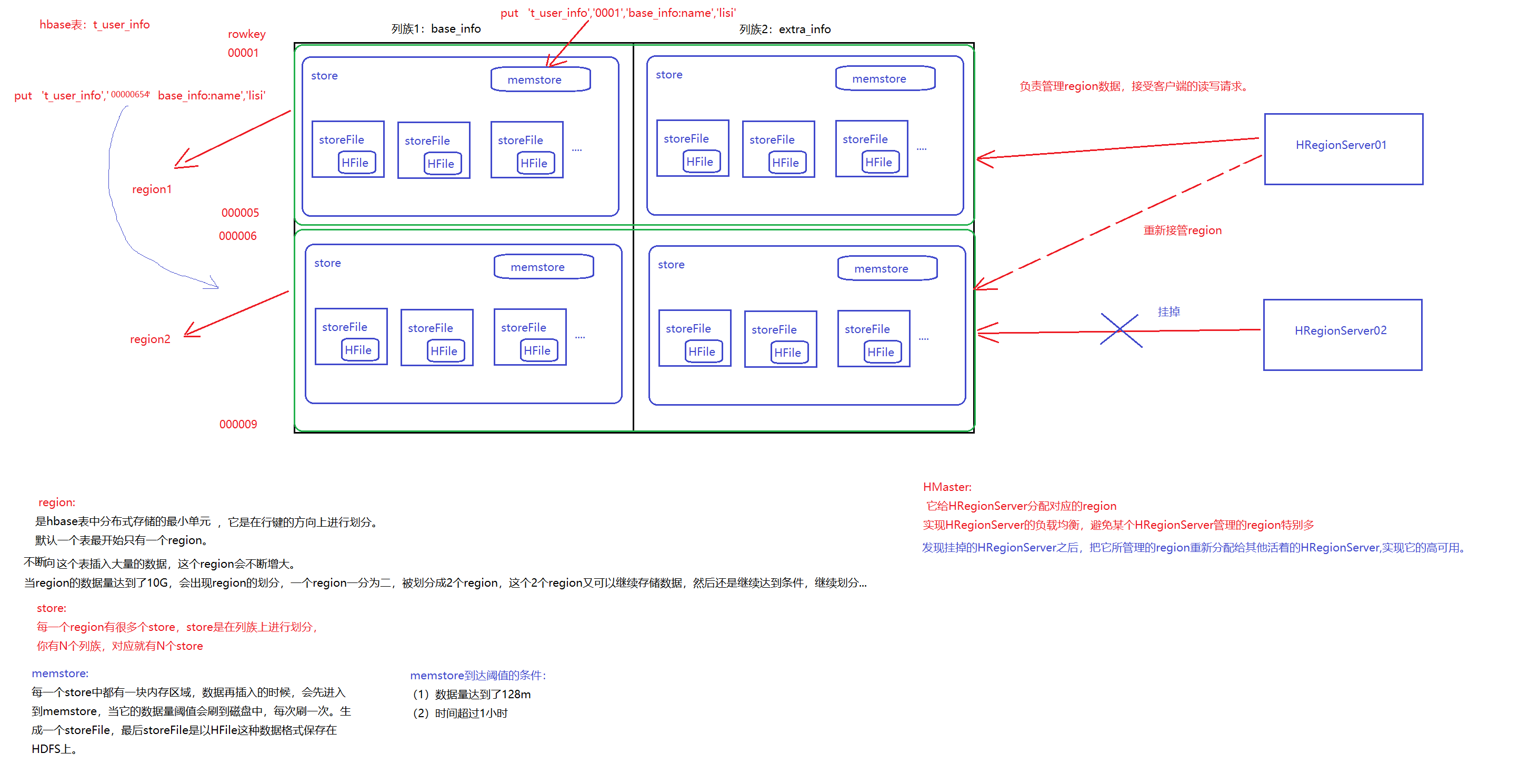
10、hbase的寻址机制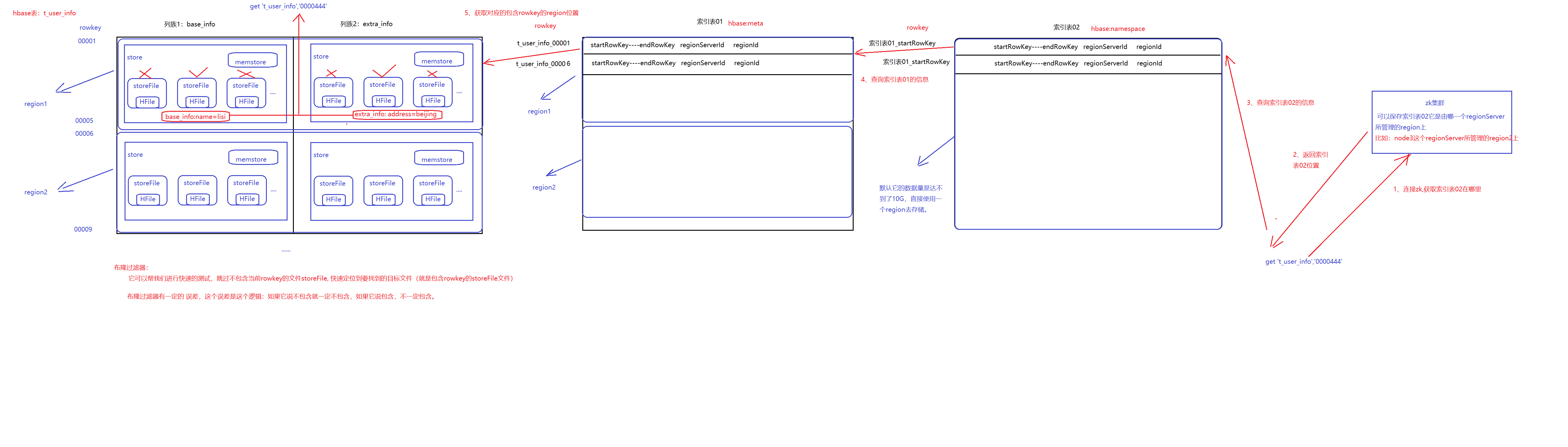
11、HBASE的应用场景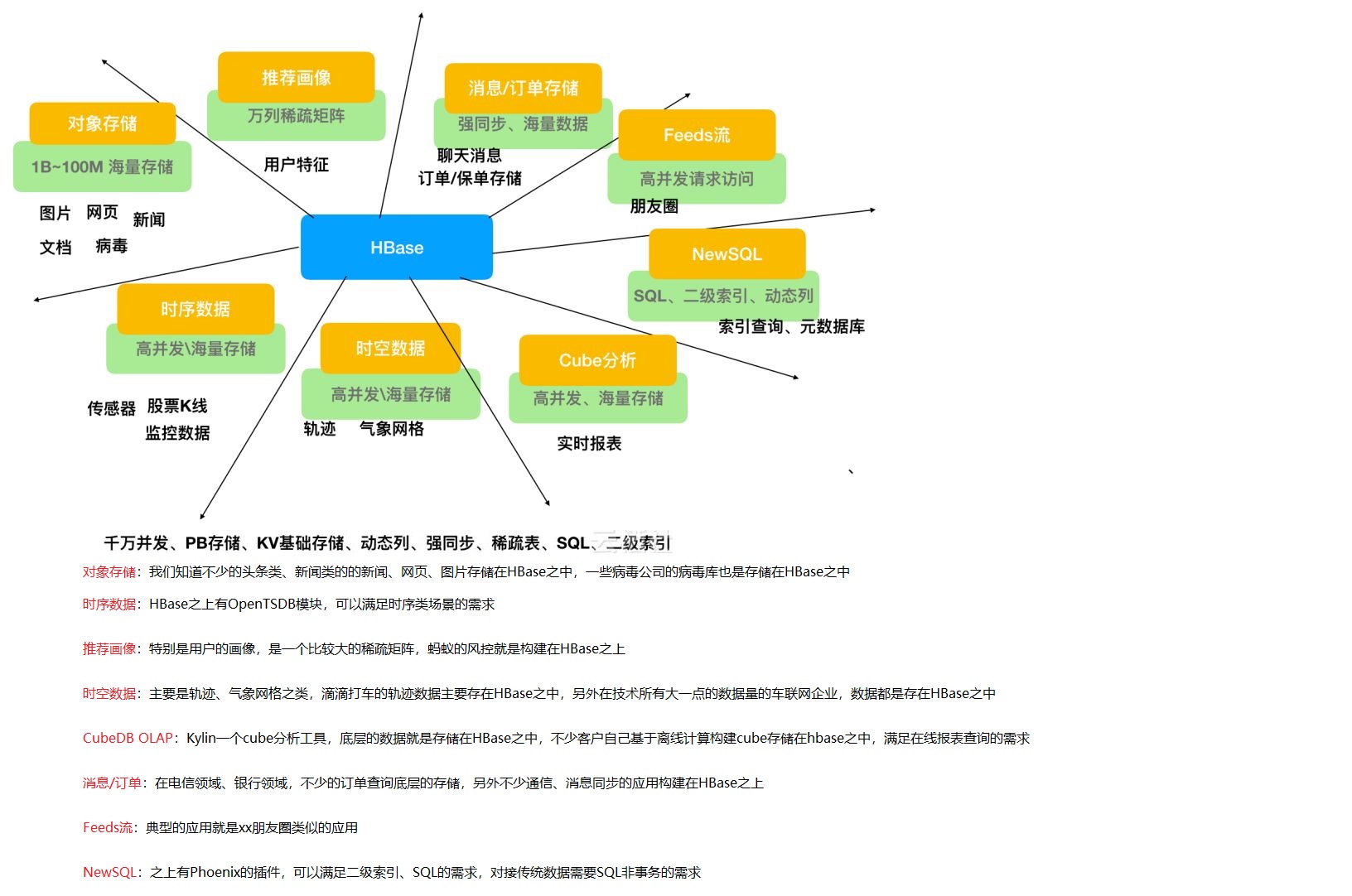

若有收获,就点个赞吧
0 人点赞
