2.1.5 DAG原理(源码级)
- sparkContext创建DAGScheduler->创建EventProcessLoop->调用eventLoop.start()方法开启事件监听
- action调用sparkContext.runJob->eventLoop监听到事件,调用handleJobSubmitted开始划分stage
- 首先对触发job的finalRDD调用createResultStage方法,通过getOrCreateParentStages获取所有父stage列表,然后创建自己。
如:父(stage1,stage2),再创建自己stage3 - getOrCreateParentStages内部会调用getShuffleDependencies获取所有直接宽依赖(从后往前推,窄依赖直接跳过)
在这个图中G的直接宽依赖是A和F,B因为是窄依赖所以跳过,所以最后B和G属于同一个stage - 接下来会循环宽依赖列表,分别调用getOrCreateShuffleMapStage:
— 如果某个RDD已经被划分过会直接返回stageID;否则就执行getMissingAncestorShuffleDependencies方法,继续寻找该RDD的父宽依赖,窄依赖老规矩直接加入:
— 如果返回的宽依赖列表不为空,则继续执行4,5的流程直到为空为止; — 如果返回的宽依赖列表为空,则说明它没有父RDD或者没有宽依赖,此时可以直接调用createShuffleMapStage将该stage创建出来 - 因此最终的划分结果是stage3(B,G)、stage2(C,D,E,F)、stage1(A)
- 创建ResultStage,调用submitStage提交这个stage
- submitStage会首先检查这个stage的父stage是否已经提交,如果没提交就开始递归调用submitStage提交父stage,最后再提交自己。
每一个stage都是一个taskSet,每次提交都会提交一个taskSet给TaskScheduler
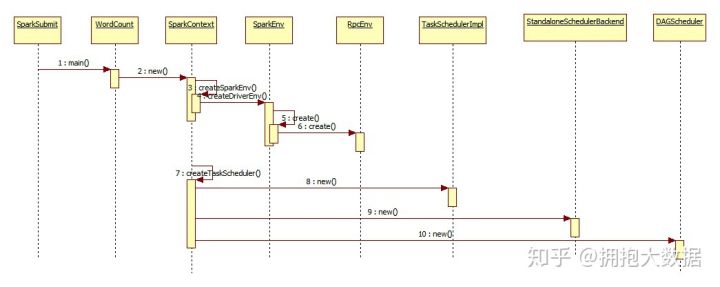
2.1.6 SparkContext 创建流程(源码级)
2.1.7 Spark SQL 运行原理
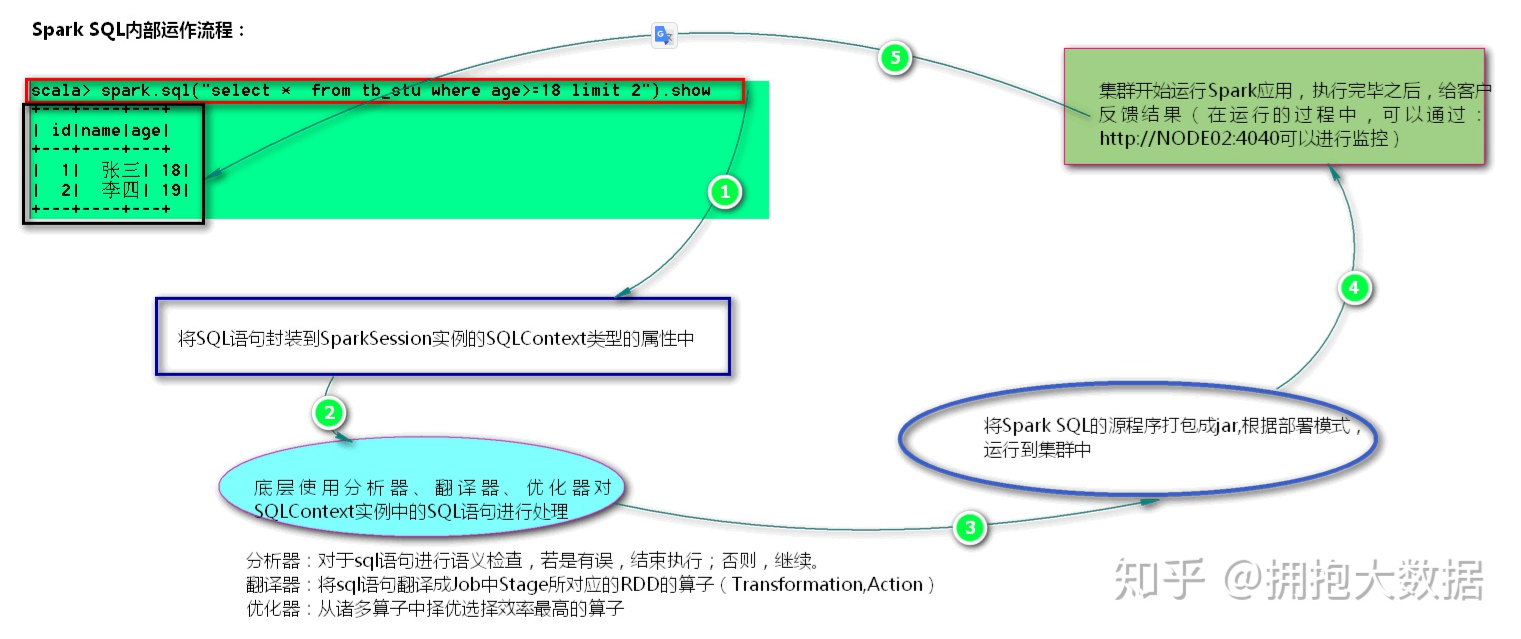
SQL语句封装到SQLContext对象中
- 调用分析器检查语义、调用翻译器翻译成RDD算子、调用优化器选择最佳算子
- 打包成jar包上传集群
- 走常规spark作业流程
2.1.8 Spark的内存模型
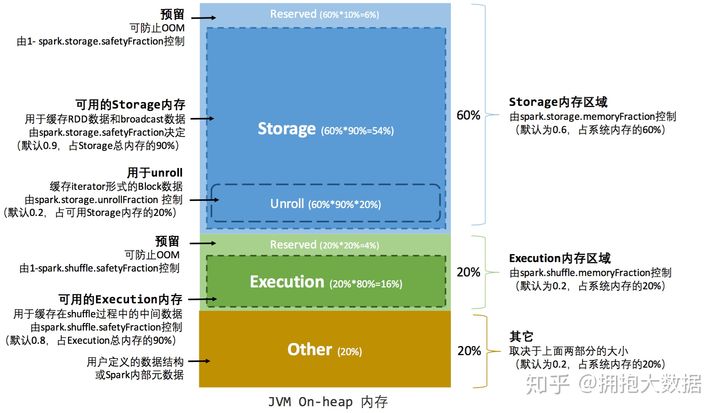
executor的**内存分为4+1块:
- Execution:计算用内存,用于执行各种算子时存放临时对象的内存
- Storage:缓存用内存,主要存储catch到内存中的数据,广播变量也存在这里
- User Memory:用户用内存,存储RDD依赖关系等RDD的信息
- Reserved Memory:预留内存,用来存储Spark自己的对象
- Off-heap Memory:堆外内存,开启之后计算和缓存的内存都分别可以存在堆外内存。堆外内存不受spark GC的影响。
- Execution和Storage采用联合内存机制,可以互相借用对方的内存区域,但是Execution可以强制征收Storage的内存,反过来不行。
- Task共用executor的内存区域,spark准备了一个hashMap用来记录各个task使用的内存,task申请新的内存时,如果剩余内存不够则会阻塞直到有足够的内存为止。每个task至少需要1/2N的内存才能被启动。
2.1.9 算子原理
2.1.9.1 foreach和foreachPartition的区别
两个算子都是属于Action算子,但是适用于场景不同,foreach主要是基于输出打印使用,进行数据的显示,而foreachPartition的适用于各种的connection连接创建时候进行使用,保证每个分区内创建一个连接,提高执行效率,减少资源的消耗。2.1.9.2 map与mapPartitions的区别
两个算子都属于transformtion算子,转换算子,但是适用于场景不同,map是处理每一条数据,也就是说,执行效率稍低,而mapPartition是处理一个分区的数据,返回值是一个集合,也就是说,在效率方面后者效率更高,前者稍低,但是在执行安全性方面考虑,map更适合处理大数据量的数据,而mappartition适用于中小型数据量,如果数据量过大那么会导致程序的崩溃,或oom。2.2 spark版本2.x 与1.6的区别
底层的执行内存模型发生改变,从之前的静态内存模型,改为动态内存模型,在spark2.X以后推出了一个全新的特性,叫DataSet,DataSet相当于整合了DF和RDD之间的关系,可以更容易的操作Spark的API。

若有收获,就点个赞吧
0 人点赞
