1 List的扩充
Arraylist默认数组大小是10,扩容后的大小是扩容前的1.5倍,最大值小于Integer 的最大值减8,如果新创建的集合有带初始值,默认就是传入的大小,也就不会扩容
private static final int DEFAULT_CAPACITY = 10; private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0)newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }
2 数据类型强制转换
首先,要注意是(short)10/10.22,而不是(short) (10/10.22),前者只是把10强转为short,又由于式子中存在浮点数,所以会对结果值进行一个自动类型的提升,浮点数默认为double,所以答案是double;后者是把计算完之后值强转short。
3 socket操作
![[Java小题狂做]第四弹 (牛客网选择题) - 图4](/uploads/projects/gremmie@ldp97p/533ed5c072034e8f07732afdfafd7420.png)
服务器端,首先是服务器初始化Socket,然后是与端口进行绑定(blind()),端口创建ServerSocket进行监听(listen()),然后调用阻塞(accept()),等待客户端连接。与客户端发生连接后,会进行相关的读写操作(read(),write()),最后调用close()关闭连接。博客上看的,不知道全面不全面,大神轻喷。
TCP客户端:
1.建立连接套接字,设置Ip和端口监听,socket()
2.建立连接 connect
3.write() 获取网络流对象 发送数据
4.read()获取网络流对象 接收数据
5.关闭套接字
TCP服务器端
1.建立端口监听 socket()
2.绑定指定端口 bind()
3.listen 进行端口监听
4.accept() 阻塞式 直到有客户端访问
5.read()获取客户端发送数据
6.write()发送返回数据
7.close关闭端口监听
4 异常处理机制
1.try和catch语句
●将要处理的代码放入try块中,然后创建相应的catch块的列表。如果生成都异常与catch中提到的相匹配,那么catch条件中的块语句就被执行。try块后可能有许多catch块,每个都处理不同的异常。每个catch中的参数都是Exception的子类。
2.finally语句
●finally语句定义一个总是执行的代码,而不考虑异常是否被捕获。
3.throw引起一个异常 ●调用申明抛出异常 ●throw语句强制抛出异常
5 HashMap和Hashtable
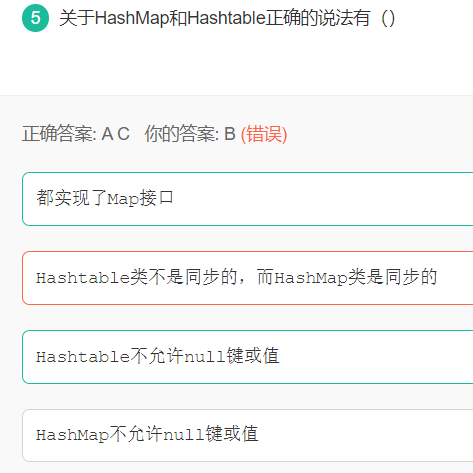
HashMap和Hashtable都是典型的Map实现,选项A正确。 Hashtable在实现Map接口时保证了线程安全性,而HashMap则是非线程安全的。所以,Hashtable的性能不如HashMap,因为为了保证线程安全它牺牲了一些性能。因此选项B错误 Hashtable不允许存入null,无论是以null作为key或value,都会引发异常。而HashMap是允许存入null的,无论是以null作为key或value,都是可以的。选项C正确,D错误。
1、继承不同。public class Hashtable extends Dictionary implements Map public class HashMap extends AbstractMap implements Map 2、Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。 3、Hashtable中,key和value都不允许出现null值。 在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。 4、两个遍历方式的内部实现上不同。 Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 5、哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。 6、Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数
6 static是否可以修饰外部类
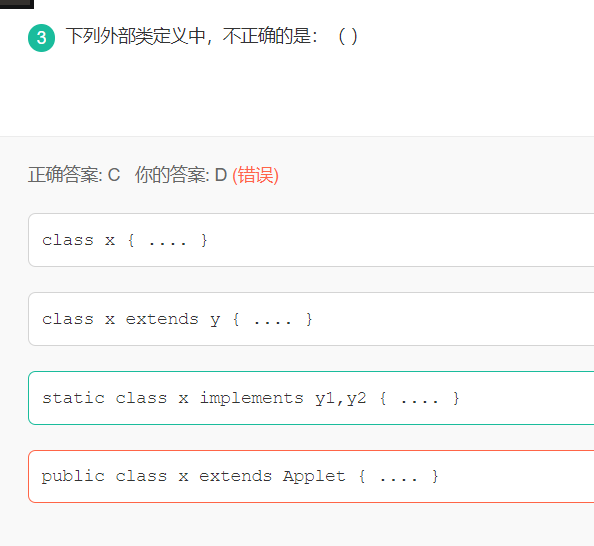
static修饰的为类成员,会随着类的加载而加载,比如静态代码块,静态成员,静态方法(这里只是加载,并没有调用)等等,可以想象一下,如果把一个Class文件中的外部类设为static,目的难道是让这个类随着应用的启动而加载吗?如果在这次使用过程中根本没有使用过这个类,那么是不是就会浪费内存。这样来说设计不合理,总而言之,设计不合理的地方,Java是不会让它存在的。
而为什么内部类可以使用static修饰呢,因为内部类算是类的成员了,如果没有使用静态来修饰,那么在创建内部类的时候就需要先有一个外部类的对象,如果我们一直在使用内部类,那么内存中就会一直存在外部类的引用,而我们有时候只需要使用内部类,不需要外部类,那么还是会浪费内存,甚至会造成内存溢出。使用static修饰内部类之后,内部类在创建对象时就不需要有外部类对象的引用了。
最终结论就是:static可以用来修饰内部类,但是不可以用来修饰外部类
7 final super int Integer
下列表述错误的是?()正确答案: D 你的答案: A (错误)A:int是基本类型,直接存数值,Integer是对象,用一个引用指向这个对象。B:在子类构造方法中使用super()显示调用父类的构造方法,super()必须写在子类构造方法的第一行,否则编译不通过C:封装的主要作用在于对外隐藏内部实现细节,可以增强程序的安全性D:final是java中的修饰符,可以修饰类、接口、抽象类、方法和属性。
8 web.xml的存放位置
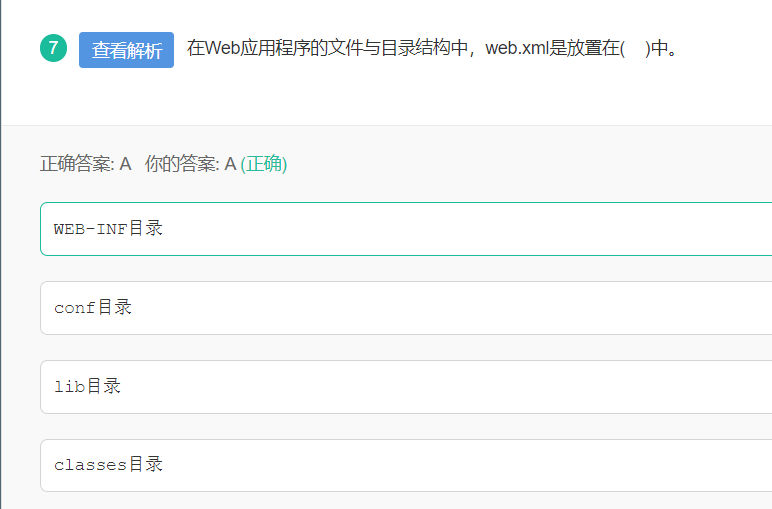
web.xml文件是用来初始化配置信息,web.xml是放置在WEB-INF目录中
9 collection的子接口
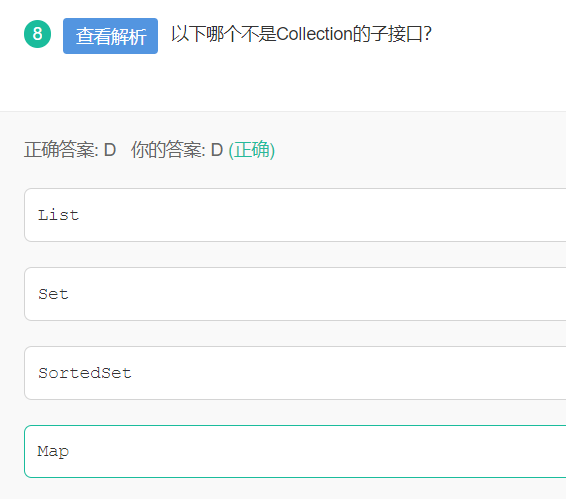
Collection主要的子接口:
List:可以存放重复内容
Set:不能存放重复内容,所有重复的内容靠hashCode()和equals()两个方法区分
Queue:队列接口
SortedSet:可以对集合中的数据进行排序
Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。
10 servlet service的描述
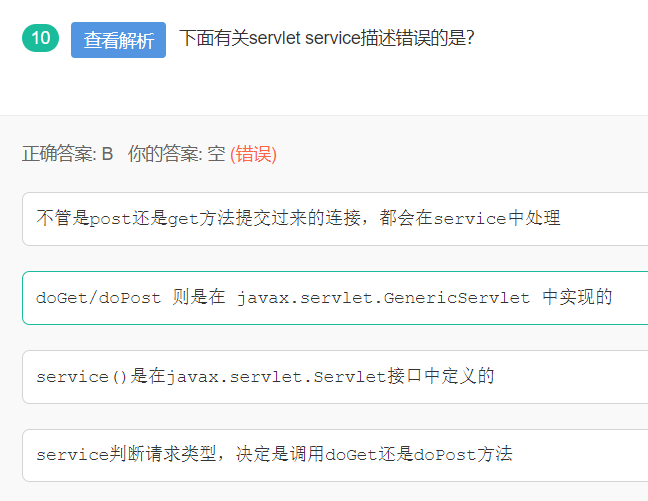
doGet/doPost 则是在 javax.servlet.http.HttpServlet 中实现的
11 GBK编码字节流到UTF-8的转换
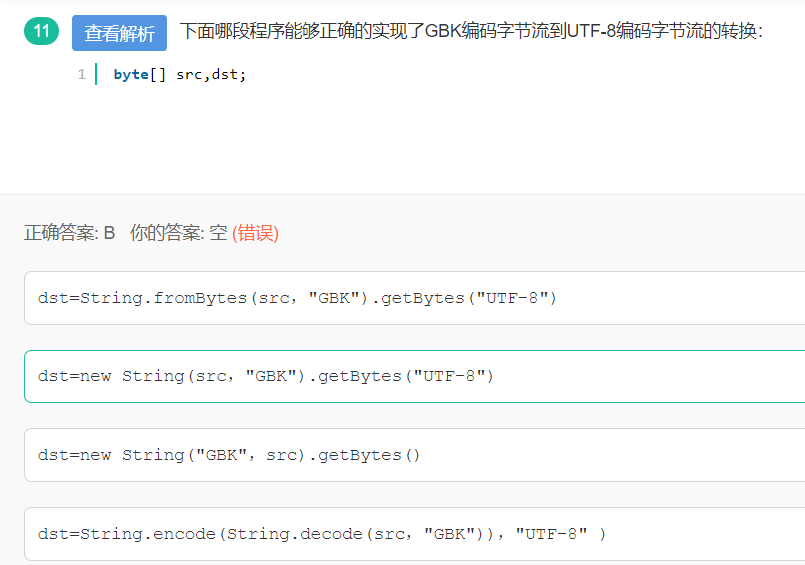
选B,先通过GBK编码还原字符串,在该字符串正确的基础上得到“UTF-8”所对应的字节串。
12 包装类和基本数据类型

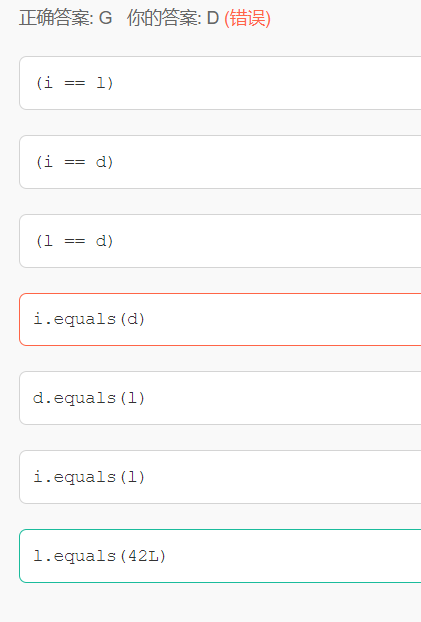
包装类的“==”运算在不遇到算术运算的情况下不会自动拆箱
包装类的equals()方法不处理数据转型
1、基本型和基本型封装型进行“==”运算符的比较,基本型封装型将会自动拆箱变为基本型后再进行比较,因此Integer(0)会自动拆箱为int类型再进行比较,显然返回true; int a = 220; Integer b = 220; System.out.println(a==b);//true
2、两个Integer类型进行“==”比较, 如果其值在-128至127 ,那么返回true,否则返回false, 这跟Integer.valueOf()的缓冲对象有关,这里不进行赘述。 Integer c=3; Integer h=3; Integer e=321; Integer f=321; System.out.println(c==h);//true System.out.println(e==f);//false 3、两个基本型的封装型进行equals()比较,首先equals()会比较类型,如果类型相同,则继续比较值,如果值也相同,返回true。 Integer a=1; Integer b=2; Integer c=3; System.out.println(c.equals(a+b));//true 4、基本型封装类型调用equals(),但是参数是基本类型,这时候,先会进行自动装箱,基本型转换为其封装类型,再进行3中的比较。
int i=1;int j = 2;Integer c=3;System.out.println(c.equals(i+j));//true
第二点 如果Integer是new出来的,直接为false。因为new出来的不会去引用存在的缓存对象
13 import 正确的访问方式
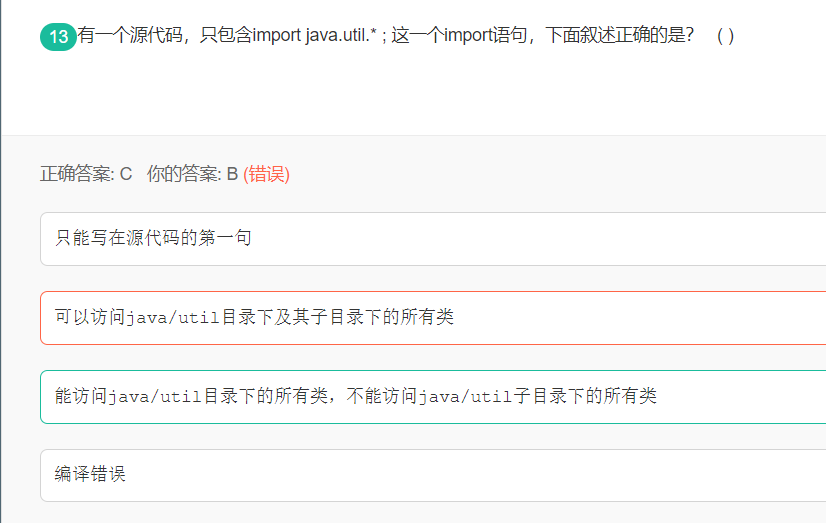
导入java.util.*不能读取其子目录的类,因为如果java.util里面有个a类,java.util.regex里面也有个a类,我们若是要调用a类的方法或属性时,应该使用哪个a类呢。所以也应该选C
14 GC的回收机制
A,Java没有指针,只有引用。
C,并不是程序结束的时候进行GC,GC的时间是不确定的,且GC的过程需要经过可达性分析,一个对象只有被标记两次才会被GC。
下图是一个对象被GC的全过程。![[Java小题狂做]第四弹 (牛客网选择题) - 图16](/uploads/projects/gremmie@ldp97p/0378f82f4f9d346ed82438faf0b272c7.png)
15 i++和++i表达式
本人的讲解比较简单明了(初学者也可以看懂),如有不对的地方请各路大神指点。
i++ 先赋值在计算结果;
++i 先计算结果再赋值。
int i = 0;
i = i ++; // 左边这个i其实是障眼法,就是一个中间变量,可以和下行的i合并;
System.out.println(i); 这里等价于:
int i = 0;
System.out.println(i++); 这下再看,先赋值(先将i传给println函数打印出来,在计算表达式结果)
所以打印出来的是0,实际上整个表达式的结果已经是1了,只是没有打印出整个表达式的结果。
所以我们知道如下结论:
1、无论怎么变,i++和++i的整个表达式的结果都是1.
2、有时我们打印的是表达式的结果(System.out.println(++i)),
有时我们打印的只是一个中间变量(System.out.println(i++))。
Ps:
int i = 0;
i++;
System.out.println(i); //值为1 打印的是表达式的结果
_
int i = 0;
++i;
System.out.println(i); //值为1 打印的是表达式的结果
**_int i = 0;
i = i++;
System.out.println(i); //值为0 打印的是中间变量(JVM中间缓存变量机制)
**_int i = 0;
i = ++i;
System.out.println(i); //值为1 打印的是表达式的结果**
我们把目光放到这里,这里i=i++执行后,i++相当于白执行了,被暂存区的值0所覆盖。这个取决于Java编译器如何去进行分析。
16 Java的体系结构
Java体系结构包括四个独立但相关的技术:
- Java程序设计语言
- Java.class文件格式
- Java应用编程接口(API)
- Java虚拟机
我们再在看一下它们四者的关系: 当我们编写并运行一个Java程序时,就同时运用了这四种技术,用Java程序设计语言编写源代码,把它编译成Java.class文件格式,然后再在Java虚拟机中运行class文件。当程序运行的时候,它通过调用class文件实现了Java API的方法来满足程序的Java API调用
17 重写和重载
方法重写
- 参数列表必须完全与被重写方法的相同;
- 返回类型必须完全与被重写方法的返回类型相同;
- 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。
- 父类的成员方法只能被它的子类重写。
- 声明为final的方法不能被重写。
- 声明为static的方法不能被重写,但是能够被再次声明。
- 子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为private和final的方法。
- 子类和父类不在同一个包中,那么子类只能够重写父类的声明为public和protected的非final方法。
- 重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
- 构造方法不能被重写。
- 如果不能继承一个方法,则不能重写这个方法。
方法重载
- 被重载的方法必须改变参数列表(参数个数或类型或顺序不一样);
- 被重载的方法可以改变返回类型;
- 被重载的方法可以改变访问修饰符;
- 被重载的方法可以声明新的或更广的检查异常;
- 方法能够在同一个类中或者在一个子类中被重载。
- 无法以返回值类型作为重载函数的区分标准。
18 多线程和多进程
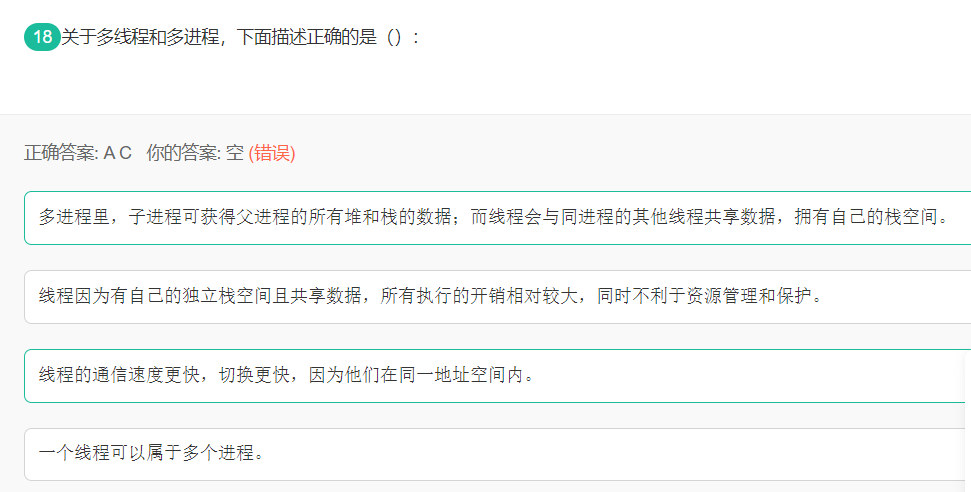
A.子进程得到的是除了代码段是与父进程共享以外,其他所有的都是得到父进程的一个副本,子进程的所有资源都继承父进程,得到父进程资源的副本,子进程可获得父进程的所有堆和栈的数据,但二者并不共享地址空间。两个是单独的进程,继承了以后二者就没有什么关联了,子进程单独运行;进程的线程之间共享由进程获得的资源,但线程拥有属于自己的一小部分资源,就是栈空间,保存其运行状态和局部自动变量的。 B.线程之间共享进程获得的数据资源,所以开销小,但不利于资源的管理和保护;而进程执行开销大,但是能够很好的进行资源管理和保护。 C.线程的通信速度更快,切换更快,因为他们共享同一进程的地址空间。 D.一个进程可以有多个线程,线程是进程的一个实体,是CPU调度的基本单位。
19 哪个类可以被继承


20 数组

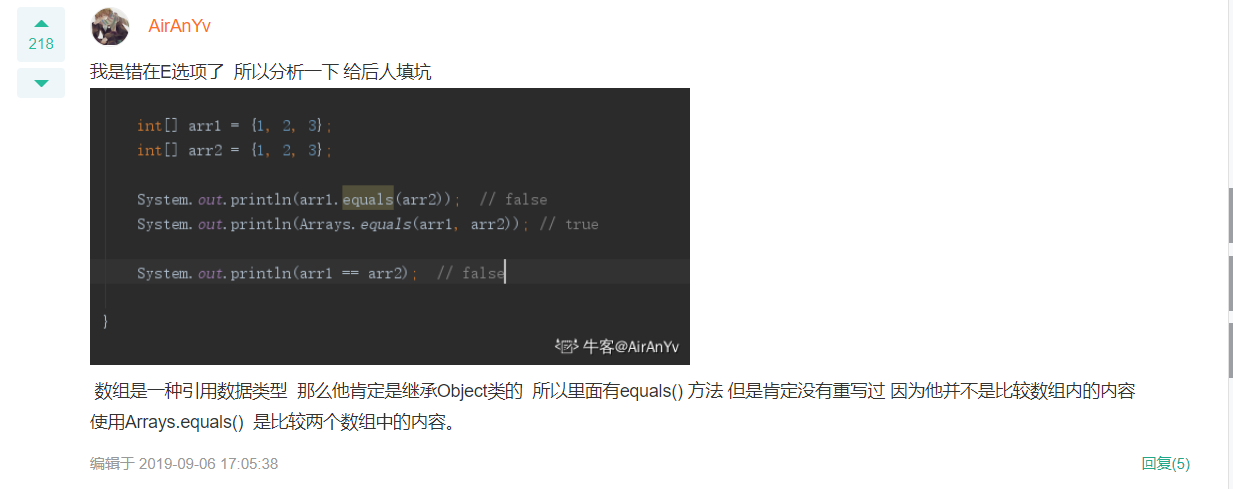
当数组的初始化完成后数组在内存中所占用的空间将会被固定,即使我们清空这个数组中的元素,它所占用的空间依然会被保留。这造成了Java数组长度的不可变,选项B错误。 Java语言中,数组是一种引用类型的变量,使用它定义变量时,这个引用变量还没有指向任何有效的内存空间,因此定义数组时不能指定数组的长度。而由于这个引用变量并没有指向任何有效的内存空间,所以没有空间来存储任何元素,只有当对数组初始化后,才可以使用这个数组。D选项正确的定义方式为int[] array =new int[100]。 本题易错点是E选项,数组是一种引用数据类型,继承自Object类的,所以其中也包含了未被重写的equals()方法,所有的引用变量都能调用equals()方法来判断他是否与其他引用变量相等,使用这个方法来判断两个引用对象是否相等的判断标准与使用==运算符没有区别,只有在两个引用变量指向同一个对象才会返回true。如果想达到E选项描述的效果,需要使用Arrays.equals()方法。
以上大部分知识点都是来自于牛客网评论区的前辈。
为大家整理了一下,希望能帮到你

若有收获,就点个赞吧
0 人点赞
