数据库系统(DBS)有一个互相关联的数据的集合和一组用以访问这些数据的程序组成。这个数据集合通常称为数据库,其中包含了关于某个企业的信息。DBS的主要目标是提供一种可以方便、高效地存取数据库信息地途径。
设计数据库系统的目的是为了管理大量信息。对数据的管理即涉及信息存储结构的定义,又涉及信息操作机制的提供。此外,数据库系统还必须提供所存储信息的安全性保证,即使在系统崩溃或是有人企图越权访问时也应保障信息的安全性。如果数据将被多用户共享,那么系统还必须设法避免可能产生的异常结果。
在大多数组织中信息是非常重要的,因而计算机科学家开发了大量的用于有效管理数据的概念和技术。
这些概念和技术正式本书所关注的。
1.数据库系统的应用
企业信息:
- 销售:用于存储客户、产品和购买信息
- 会计:用于存储付款、收据、账户余额、资产和其他会计信息。
- 人力资源:用于存储雇员、工资、所得税和津贴的信息,以及产生工资单。
银行和金融:
- 银行业:用于存储客户信息、账户、贷款、以及银行的交易记录
- 信用卡交易:用于记录信用卡消费的情况和产生每月清单。
2.数据库系统的目标
数据库系统作为商业数据计算机化管理的早期方法而产生。
文件处理系统是传统的操作系统所支持的。
在DBS(数据库系统出现以前,各个组织通常都采用这样的系统来存储信息)
在文件处理系统中存储组织信息的主要弊端包括:
- 数据的冗余和不一致:这种冗余除了导致存储和访问开销增大外,还能导致数据不一致性,即统一数据的不同副本不一致。
- 数据访问困难:举个简单的例子,现在有个学生信息的数据集合,然后我们并没有对这些学生信息进行信息的归类与统计,当我们需要提取学生的姓名或者学号的时候,就需要去人工手动提取或者要求数据管理部门的程序员写相关的程序来提取信息,但这两种方法都不是太方便。而且,当我们提取出姓名学号之后,某一天我们又需要提取某一门学科分数在90分以上的学生名单,这个时候之前提取出来的学生名单就没有丝毫用处了,又要用那两种方法从头再来。这里需要指出的是,传统的文件处理环境不支持以一种方便而高效的方式去获取所需的数据。我们需要开发通用的、能对变化的需求做出更快反应的数据检索系统。
- 数据鼓励:由于数据分散在不同的文件中,这些文件有可能具有不同的格式,因此编写新的应用程序来检索适当数据是很困难的。
- 完整性问题:数据库中所存储数据的值必须满足某些特定的一致性约束。
- 原子性问题:比如银行的借贷系统,用户的借钱和还钱的步骤必须同一时间进行,要么都做,要么都不做,否则发生故障了,就会使得虚拟网上钱财凭空增多或减少。这是非常恐怖的,所以也就是说,转账这个操作,必须要做到和现实中一样,要么全部发生,要么根本不发生。在传统的文件处理系统中,保持原子性也是很难做到的。
- 并发访问异常:假设每个取款操作对应执行的程序是读取原始账余额,在其上减去取款的金额,然后将结果写回。如果两次取款的程序并发执行,可能它们读取到的余额是相同的100,然后分别扣除了10和20,返回了两个余额值90和80,而事实上我们正确的余额扣除之后是70。为了消除这种情况发生的可能性,系统必须进行某种形式的管理。但是,由于数据可能被多个不同的应用程序访问,这些程序相互间事先又没有协调,管理就很难进行。
-
3.数据试图
数据库系统是一些互相关联的数据以及一组使得用户可以访问和修改这些数据的程序的集合。数据库系统的一个主要目的是给用户提供数据的抽象视图,也就是说,系统隐藏关于数据存储和维护的某些细节
3.1数据抽象
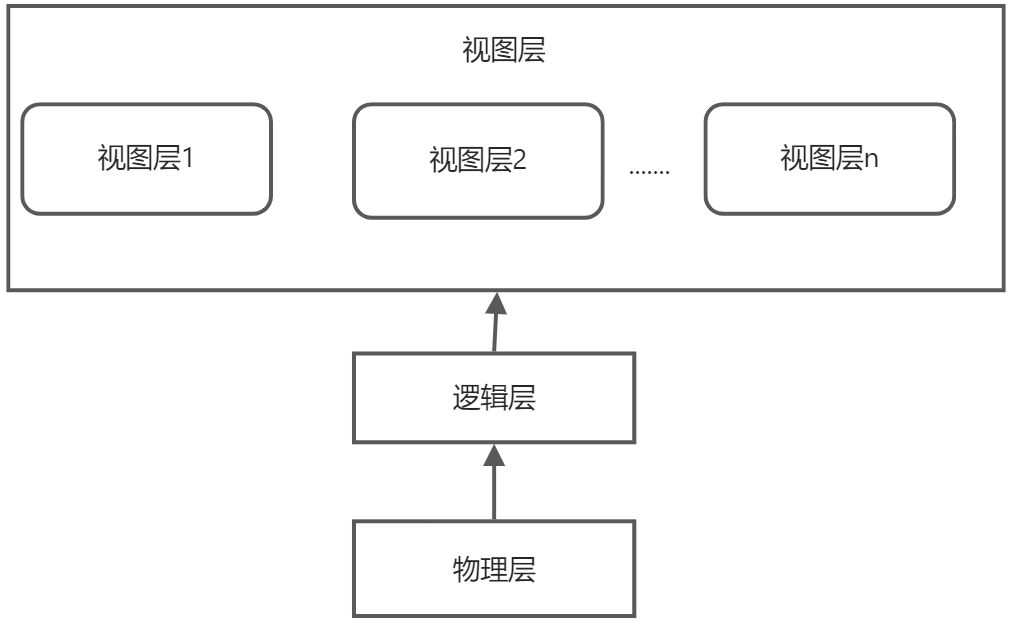
一个可用的系统必须能够高效地检索数据。系统开发人员通过如下几个层次上的抽象来对用户屏蔽复杂性,以简化用户与系统的交互。
物理层:最低层次的抽象,描述数据实际上是怎样存储的。物理层详细描述复杂的底层数据结构。
- 逻辑层:比物理层层次稍高的抽象,描述数据库中存储什么数据以及这些数据间存在什么关系
- 视图层:用户能够接触的层次,是最高层次的抽象,只描述整个数据库的某个部分
3.2实例和模式
随着时间的推移,信息会被插入或是删除,数据库也就发生了改变。特定时刻存储在数据库中的信息的集合乘坐数据库的一个实例(instance)。而数据库的总体设计乘坐数据库模式(schema)。数据库模式即使发生变化,也不频繁。
数据库模式和实例的概念可以通过与用程序设计语言写出的程序进行类比来季节。数据库模式对应于程序设计语言中的变量声明 。每个变量在特定的时刻会有特定的值,程序中变量在某一时刻的值对应数据库模式的一个实例,
数据库在视图层也可以有几种模式,有时称为子模式,它描述了数据库的不同视图
在这些模式中,因为程序员使用逻辑模式来构造数据库应用程序,从其对应用程序的效果来看,逻辑模式是目前最重要的一种模式。物理模式隐藏在逻辑模式下,并且通常可以在应用程序丝毫不受影响的情况下被轻易地更改。应用程序如果不依赖于物理模式,他们就被称为是具有物理数据独立性,因此即使物理模式改变了,它们也无需重写。
4.MySQL数据库基础
4.1数据库地操作
4.1.1显示当前的数据库
SHOW DATABASES;
4.1.2创建数据库
CREATE DATABASE db_namecreate_specification:[DEFAULT] CHARACTER SET charset_name[DEFAULT] COLLATE collation_name
- 上述代码中大写的表示关键字
- 【】是可选项
- CHARACTER SET:指定数据库采用的字符集
- COLLATE:指定数据库字符集的校验规则
示例:创建一个名为 test1的数据库
CREATE DATABASE test1;
说明:当我们创建数据库没有指定的字符集和校验规则时,系统会使用默认字符集:utf8,校验规则时:utf8_general_ci
示例:如果系统没有test2的数据库,则创建一个名叫test2的数据库,如果有则不创建
CREATE DATABASE IF NOT EXISTS test2;
示例:如果系统没有test的数据库,则创建一个使用utfmb4字符集的test数据库,如果有则不创建
CREATE DATABASE IF NOT EXITS test CHARACTER SET utf8mb4;
说明:MySQL的utf8编码不是真正的utf8,没有包含某些复杂的中文字符.MySQL真正的utf8时使用utf8mb4
4.1.3使用数据库
use 数据库名;
4.1.4删除数据库
语法:DROP DATABASE [IF EXISTS] name;
说明:数据库删除以后,内部看不到对应的数据库.里面的表和数据都被全部删掉
drop database if exists test1; drop database if exists test2;
4.2常用数据类型
4.2.1数值类型
分为整形和浮点型
| 数据类型 | 大小 | 说明 | 对应Java类型 |
|---|---|---|---|
| BIT[(M)] | M指定位数,默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用Boolean对应BIT,此时默认是1位,即只能存0和1 |
| TINYINT | 1字节 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | |
| SMALLINT | 2字节 | ||
| INT | 4字节 | ||
| BIGINT | 8字节 | ||
| FLOAT(M,D) | 4字节 | ||
| DOUBLE(M,D) | 8字节 | ||
| DECIMAL(M,D) | M/D最大值+2 | ||
| NUMERIC(M,D) | M/D最大值+2 |

若有收获,就点个赞吧
0 人点赞
