在Java2的版本众,Java就提供了特设类。 比如:Dictionary, Vector, Stack, 和 Properties 这些类用来存储和操作对象组。 虽然这些类都是非常实用的,但他们都缺少一个核心且统一的主题。 由于这个原因,使用Vector类的方式和使用Properties类的方式有着很大的不同
集合框架被涉及成接口或类要满足以下几个目标
- 该框架必须是高性能的,基本组合(动态数组,链表,树,哈希表)的实现也必须是高效的
- 该框架允许不同类型的集合,以类似的方法工作,具有高度的互操作性
- 对于一个集合的扩展和适应必须是简单的,不能太复杂,否则就陷入了“造轮子”的死循环
为此,整个集合框架就围绕一组标准接口而设计。你可以直接使用这些接口的标准实现,诸如:LinkedList,HashSet和TreeSet等,除此之外你也可以通过这些接口实现自己的集合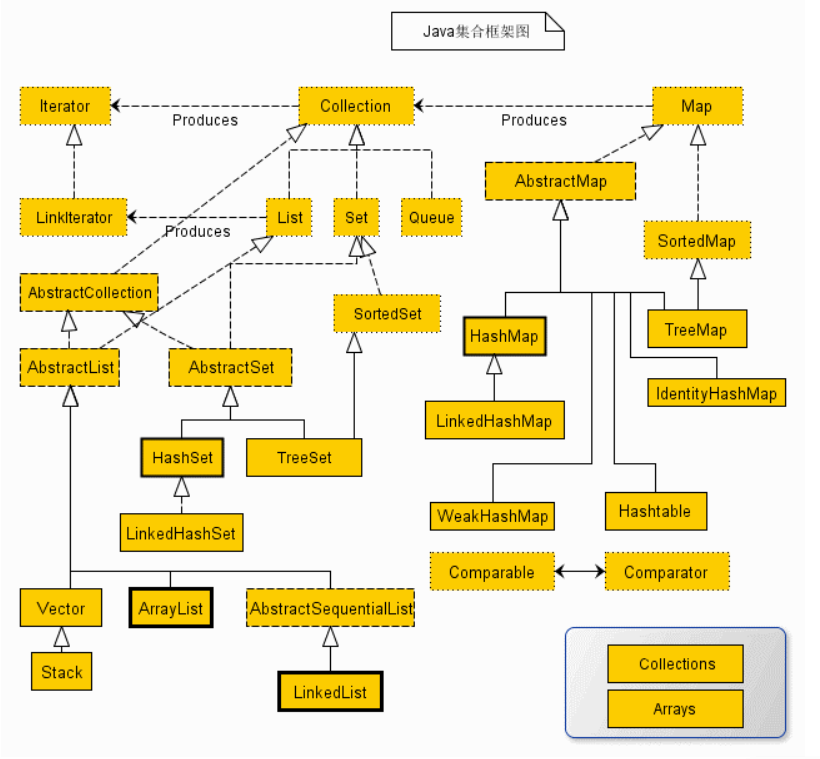
Java 集合框架 Java Collection Framework ,又被称为容器 container ,是定义在 java.util 包下的一组 接口 interfaces 和其实现类 classes 。 其主要表现为将多个元素 element 置于一个单元中,用于对这些元素进行快速、便捷的存储 store 、检索 retrieve 、管理 manipulate ,即平时我们俗称的增删查改 CRUD 。 例如,一副扑克牌(一组牌的集合)、一个邮箱(一组邮件的集合)、一个通讯录(一组姓名和电话的映射关系)等等。
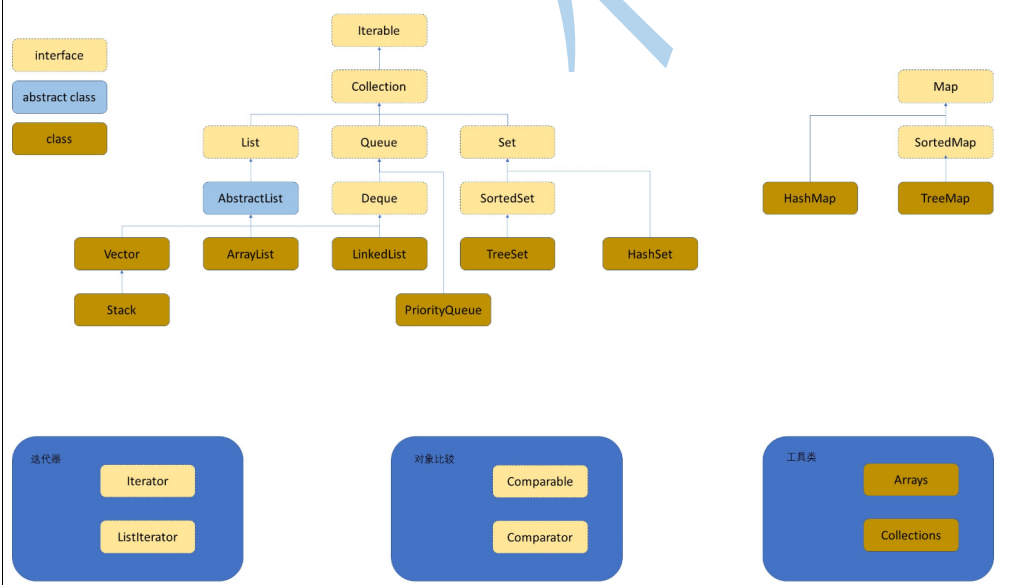
集合接口
Collection接口
Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。
Collection 接口存储一组不唯一,无序的对象。
List接口
List接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。 List 接口存储一组不唯一,有序(插入顺序)的对象。
Set接口
Set具有与Collection完全一样的接口,只是行为上不同,Set不保存重复的元素。 Set接口存储一组唯一,无序的对象。
SortedSet
继承于Set保存有序的集合
Map
Map 接口存储一组键值对象,提供key(键)到value(值)的映射。
SortedMap
继承于 Map,使 Key 保持在升序排列。
Enumeration
这是一个传统的接口和定义的方法,通过它可以枚举(一次获得一个)对象集合中的元素。这个传统接口已被迭代器取代。
Set和List的区别
- Set接口实例存储的是无序的,不重复的数据。List接口实例存储的是有序的,可以重复的元素
Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>。遍历Set的三种方法
1.迭代遍历: Set set = new HashSet(); Iterator it = set.iterator(); while (it.hasNext()) { String str = it.next(); System.out.println(str); }
2.for循环遍历: for (String str : set) { System.out.println(str); }
List 和数组类似,可以动态增长,根据实际存储的数据的长度自动增长 List 的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector>
集合实现类(集合类)
Java提供了一套实现了Collection接口的标准集合类。其中一些是具体类,这些类可以直接拿来使用,而另外一些是抽象类,提供了接口的部分实现。
如何使用迭代器
通常情况下,你会希望遍历一个集合中的元素。例如,显示集合中的每个元素。
一般遍历数组都是采用for循环或者增强for,这两个方法也可以用在集合框架,但是还有一种方法是采用迭代器遍历集合框架,它是一个对象,实现了Iterator 接口或 ListIterator接口。
迭代器,使你能够通过循环来得到或删除集合的元素。ListIterator 继承了 Iterator,以允许双向遍历列表和修改元素。
import java.util.*;public class Test{public static void main(String[] args) {List<String> list=new ArrayList<String>();list.add("Hello");list.add("World");list.add("HAHAHAHA");//第一种遍历方法使用 For-Each 遍历 Listfor (String str : list) { //也可以改写 for(int i=0;i<list.size();i++) 这种形式System.out.println(str);}//第二种遍历,把链表变为数组相关的内容进行遍历String[] strArray=new String[list.size()];list.toArray(strArray);for(int i=0;i<strArray.length;i++) //这里也可以改写为 for(String str:strArray) 这种形式{System.out.println(strArray[i]);}//第三种遍历 使用迭代器进行相关遍历Iterator<String> ite=list.iterator();while(ite.hasNext())//判断下一个元素之后有值{System.out.println(ite.next());}}}
三种方法都是用来遍历ArrayList集合,第三种方法是采用迭代器的方法,该方法可以不用担心在遍历的过程中会超出集合的长度。
Map
概述:
以键值对来保存数据——key ,——value 键(key)值(value)来保存数据,其中值(value)可以重复,但键(key)必须是唯一,相同就覆盖;
也可以为空,但最多只能有一个key为空;
它的主要实现类有HashMap(去重)、LinkedHashMap、TreeMap(排序)。 指的都是对key 的操作;
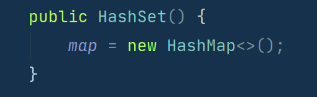
HashSet去重和HashMap的关系: HashSet依赖Map 存储数据,set在保存数据时,实际上是在向Map中key这一列中存数据;
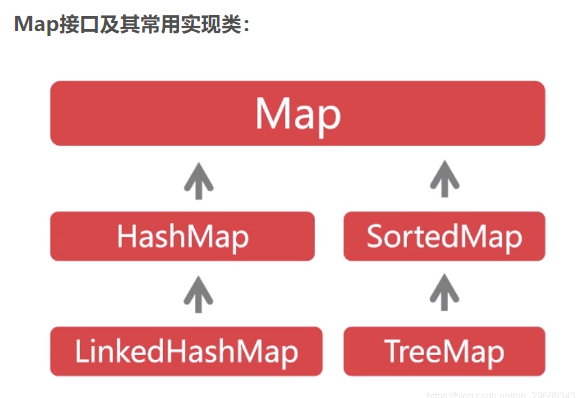
Map的通用方法
put(key,value):存入Map中的一个key-value键值对映射;
get(key):返回指定key所映射的值;
int size():返回键值对的数量;
remove(key):删除指定key的一对映射;
containsKey(key):判断是否包含指定的key;
Map的使用方法(无序)
HashMap的基本用法
构造方法:
HashMap():无参构造,默认初始化长度为16,负载因子为0.75; HashMap(int initalCapacity):指定初始化长度; HashMap(int initalCapacity,float loadFactor):指定初始化长度和负载因子; HashMap的负载因子初始值为什么是0.75?👇
一、负载因子的作用
负载因子是和扩容机制有关的,意思是如果当前容器的容量,达到了我们设定的最大值,就要开始执行扩容操作。
举个例子👇
比如说当前的容器容量是16,负载因子是0.75,16*0.75=12,也就是说,当容量达到了12的时候就会进行扩容操作。
相当于一个扩容机制的阈(yu)值
系统默认的负载因子值就是0.75,而且我们还可以在构造方法中去指定。
代码演示
package Map;import java.util.*;/*** @author Gremmie102* @date 2022/6/20 14:17* @purpose :*/public class Test1 {public static void main(String[] args) {//创建HashMapMap<String,String> map = new HashMap<>();//存放元素map.put("齐天大圣", "葛玉礼");map.put("齐天大圣","Gremmie");map.put("天蓬元帅","韩宇航");//取出元素String str1 = map.get("齐天大圣");String str2 = map.get("天蓬元帅");System.out.println(str1+" "+str2);//获取map的长度int size = map.size();System.out.println(size);//判断是否包含指定keyboolean b1 = map.containsKey("齐天大圣");boolean b2 = map.containsValue("Gremmie");System.out.println(b1+" "+b2);System.out.println(map);}}
输出结果👇
Gremmie 韩宇航 2 true true {齐天大圣=Gremmie, 天蓬元帅=韩宇航}
Process finished with exit code 0
我们可以看到,因为key值相同,齐天大圣后面一个value-Gremmie把前面一个value葛玉礼覆盖掉了,所以不难发现同样的key值不可以对应两个value,但是两个不同的key可以对应同一个vaule.
HashMap的无序体现在哪里?
代码演示👇
package Map;import java.util.*;/*** @author Gremmie102* @date 2022/6/20 14:31* @purpose :*/public class Test2 {public static void main(String[] args) {//创建HashMapMap<String,Integer> map = new HashMap<>();//有序得创建元素map.put("大娃",1);map.put("二娃",2);map.put("三娃",3);map.put("四娃",4);map.put("五娃",5);map.put("六娃",6);map.put("七娃",7);map.put("爷爷",8);map.put("蛇精",9);//输出mapSystem.out.println(map);}}
输出结果:
{四娃=4, 三娃=3, 五娃=5, 大娃=1, 蛇精=9, 七娃=7, 六娃=6, 二娃=2, 爷爷=8}
我们不难发现,map中存储的顺序既不是我们插入的顺序,也不是大小或者字典顺序。
它其实是按照自己的算法进行排序的。
HashMap遍历-keySet
概述:
keySet是map集合中所有key的集合,我们可以通过遍历keySet的方法取出所有的value;
代码演示
package Map;import java.util.Map;import java.util.Set;import java.util.HashMap;/*** @author Gremmie102* @date 2022/6/20 15:11* @purpose :*/public class Test3 {public static void main(String[] args) {//创建HashMapMap<String, Integer> map = new HashMap<>();//存放元素map.put("大哥", 1);map.put("二哥", 2);map.put("三哥", 3);map.put("四哥", 4);map.put("五哥", 5);//获取keySet,keySet是map集合中所有key的集合,我们可以通过遍历keySet的方法取出所有的value;Set<String> keySet = map.keySet();for (String key : keySet) {System.out.println(map.get(key));}}}
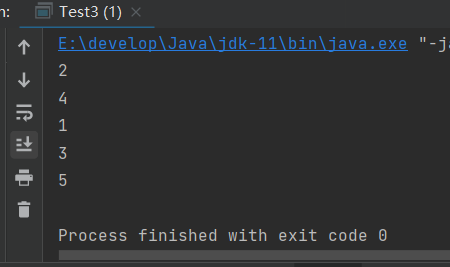
HashMap遍历-values
package Map;import java.util.*;/*** @author Gremmie102* @date 2022/6/20 15:16* @purpose :*/public class Test4 {public static void main(String[] args) {//创建HashMapMap<String, Integer> map = new HashMap<>();//存放元素map.put("大哥", 1);map.put("二哥", 2);map.put("三哥", 3);map.put("四哥", 4);map.put("五哥", 5);//获取values,values是map所有值的集合,可以直接通过遍历values并输出for (Integer integer : map.values()) {System.out.println(integer);}}}
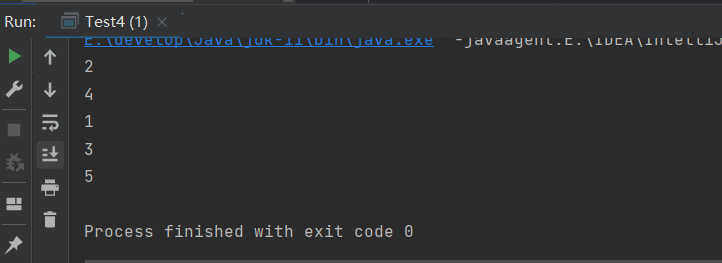
HashMap遍历-entrySet
entrySet是所有entry的集合,可以通过遍历entrySet的方式获取key和value并输出;
package Map;import java.util.HashMap;import java.util.Map;import java.util.Set;/*** @author Gremmie102* @date 2022/6/20 15:43* @purpose :*/public class Test5 {public static void main(String[] args) {//创建HashMapMap<String,Integer> map = new HashMap<>();//存放元素map.put("大哥",1);map.put("二哥",2);map.put("三哥",3);map.put("四哥",4);map.put("五哥",5);//获取entrySet,entrySet是所有entry的集合,可以通过遍历entrySet的方式获取key和value并输出Set<Map.Entry<String, Integer>> entrySet = map.entrySet();for (Map.Entry<String, Integer> entry : entrySet) {System.out.println(entry.getKey() + "==>" + entry.getValue());}}}
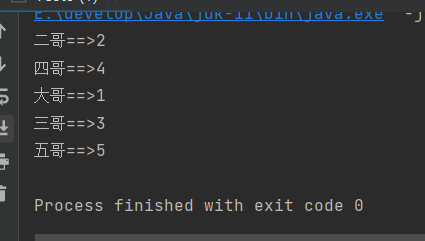
HashMap遍历-Iterator
概述
iterator是一个迭代器,iterator.hasNext()用来判断是否还存在下一个entry,iterator.next()用来获取下一个entry。
map实例
package Map;import java.util.*;/*** @author Gremmie102* @date 2022/6/20 16:07* @purpose :*/public class 学生信息管理 {public static void main(String[] args) {Map<String,Integer> 成绩1 = new HashMap<>();Map<String,Integer> 成绩2 = new HashMap<>();成绩1.put("语文",103);成绩1.put("数学",102);成绩1.put("英语",101);成绩2.put("物理",98);成绩2.put("地理",97);成绩2.put("化学",96);Map<String,Map<String,Integer>> 小葛 = new HashMap<>();小葛.put("主三门",成绩1);小葛.put("副三门",成绩2);System.out.println(小葛);}}
输出结果:👇
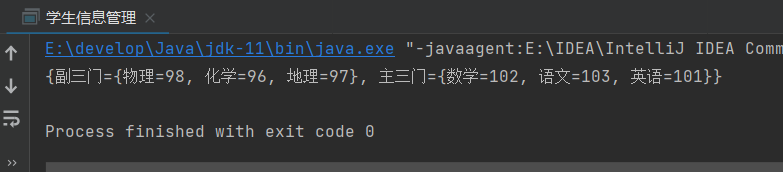

若有收获,就点个赞吧
0 人点赞
