摘要
本文主要介绍如何快速使用本公众号体验 ChatGPT 与 DALL.E。并附录了一篇简单的公众号接入踩坑教程:在已有 openai 账户的情况下,订阅号如何使用 Node.JS 快速接入它们。
公众号快速接入教程
有兴趣了解如何接入公众号,并且有一定基础的同学可以继续看下这个接入教程。
怎么创建 openai 账户,网上已经有很多教程了,我就不多赘述了。其实公众号怎么接入,网上也有一些教程,但是或多或少都有些前置要求,比如,已经有了一台服务器做消息处理;或者要调用别人的某某服务。
先问一下 ChatGPT

复制它回答的代码,新建一个 js 文件,安装一下相关依赖。并从 openai 账户页注册并复制一个密钥,即可完成调用。相信基本前端入门的同学都能够顺利完成执行并初次尝试。
其实它这个回答已经有些落后了,因为这个模型是根据 2021年及以前的数据训练的,回答难免会有些落伍。我们其实可以直接看文档:
https://sequelize.org/docs/v6/core-concepts/model-basics/
文档也已经非常清晰,而且调用非常简单。所以我们明白,接入 ChatGPT 核心,其实非常简单。
第一步:部署微信云托管服务
既然 node 调用 GPT 如此简单,那我们的主要工作其实就是搞一个消息服务,能处理订阅号接受的消息,并做调用与回答即可。
幸运的事,2023年了,微信公众号开发在这方面已经非常成熟,在公众号后台「开发者工具」中
有一个「微信云托管」,它真如它自身所描述,免服务器免运维,而且在一定使用量下还是免费的
真的是,你只要写代码,push 代码,剩下它都能帮你搞定。
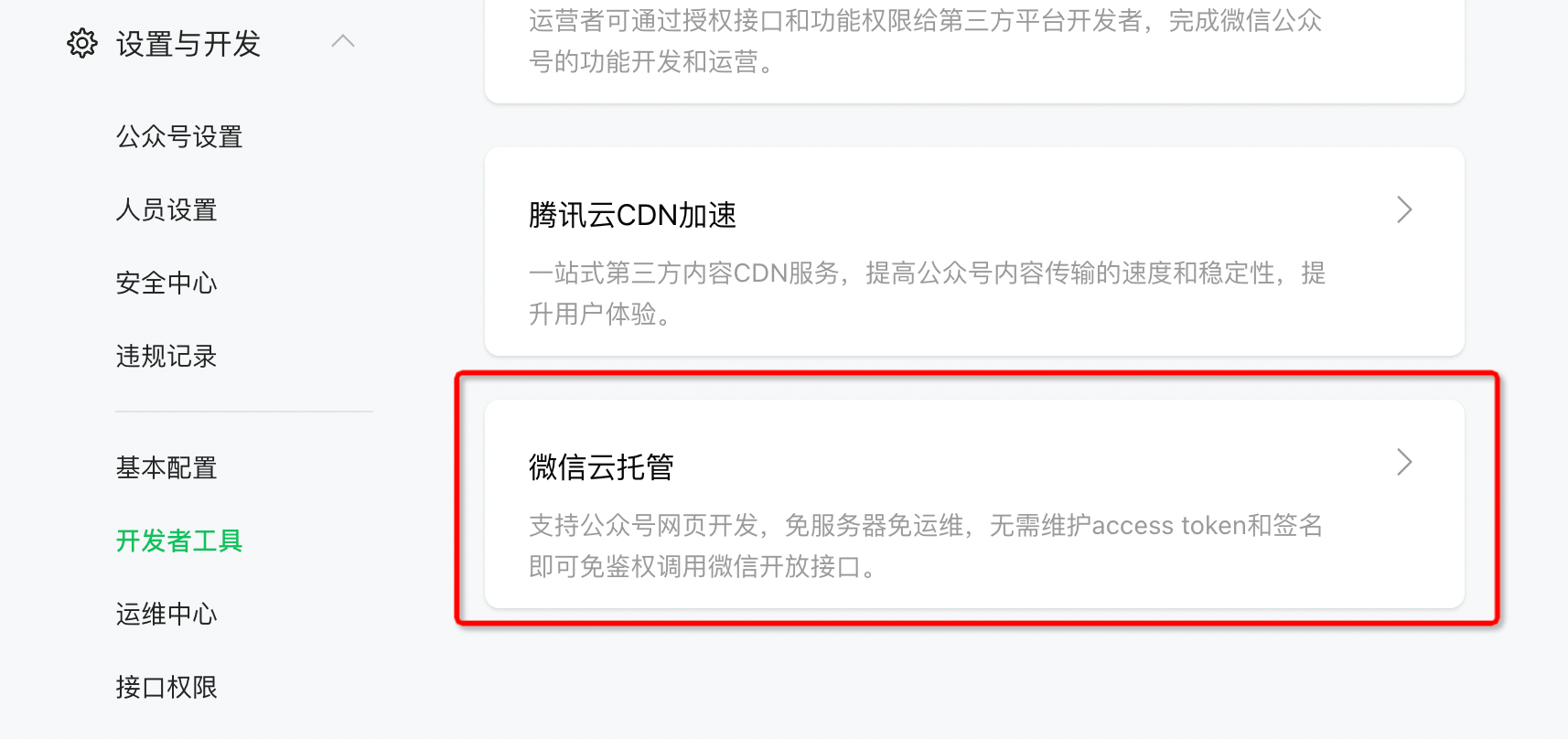
我们的消息服务非常简单,可以直接用 Koa 模板快速部署一个服务。

后续的过程非常简单、傻瓜,我就不一一截图展示了,官方也有标准的教程文档:
快速入门-Node.JS自定义部署 | 微信开放文档
然后很快你就能部署一个最简单的服务器,并通过它系统生成的域名,打开一个这样的网站。
修改代码也非常简单。在前一步流程中,你授权你的 github 后,它在你的 gihthub 会建一个仓库(记得新建完以后,去把仓库设置为私有),每当你给这个仓库 push master 代码时,它就会自动拉取最新代码重新部署。
到此为止,你就已经成功搭建了一个服务器,还给你配置了数据库,你可以在上面开发任何你想要的功能。
第二步:开发一个简单的消息接口
微信给的模板代码(https://github.com/WeixinCloud/wxcloudrun-koa)中的案例代码,是没有消息相关的。所以我们得自己先开发一个消息接口,使得能接收到 公众号的消息并针对性做定制回复。
开发之前,对一些未开发过微信公众号的同学做点儿科普。订阅号的消息推送分几种:
- 被动消息回复:指用户给公众号发一条消息,系统接收到后,可以回复一条消息。
- 主动回复/客服消息:可以脱离被动消息的5秒超时权限,在48小时内可以主动回复。但需要公众号完成微信认证。
相关文档地址:
- 介绍文档:
- 代码示例:
作为个人公众号,一般都无法完成企业认证,所以我们没办法,只能使用被动消息回复。只用微信云托管实现被动消息回复非常简单。在上述的代码示例文档是以 Express 为示例的,但逻辑是一样的,我再列一个 koa 下的最小实现代码。
// 一个用户发什么消息,就反弹什么消息的消息回复功能router.post('/message/post', async ctx => {const { ToUserName, FromUserName, Content, CreateTime } = ctx.request.body;ctx.body = {ToUserName: FromUserName,FromUserName: ToUserName,CreateTime: +new Date(),MsgType: 'text',Content: `反弹你发的消息:${Content}`,};});
复制这段代码,添加到你的 index.js文件中,commit & push master 后,微信云托管会自动部署。如果没有的话,可以手动点一下发布,走「执行流水线」发布。
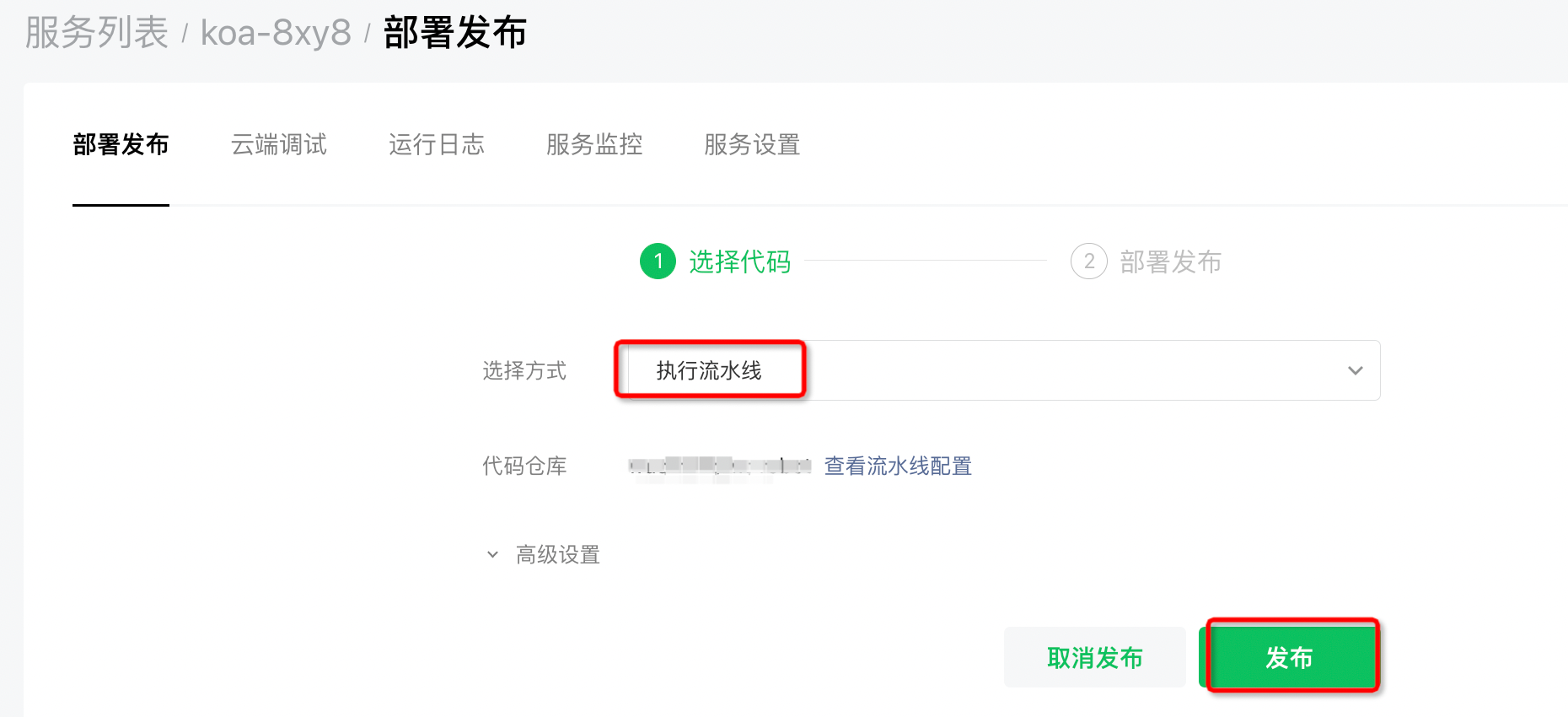
部署以后,在云托管后台的「设置-全局设置」中,添加「消息推送」。除了 「Path」要手动填写一下 刚刚代码的路由名「/message/post」外,其他都是可以下拉选择的。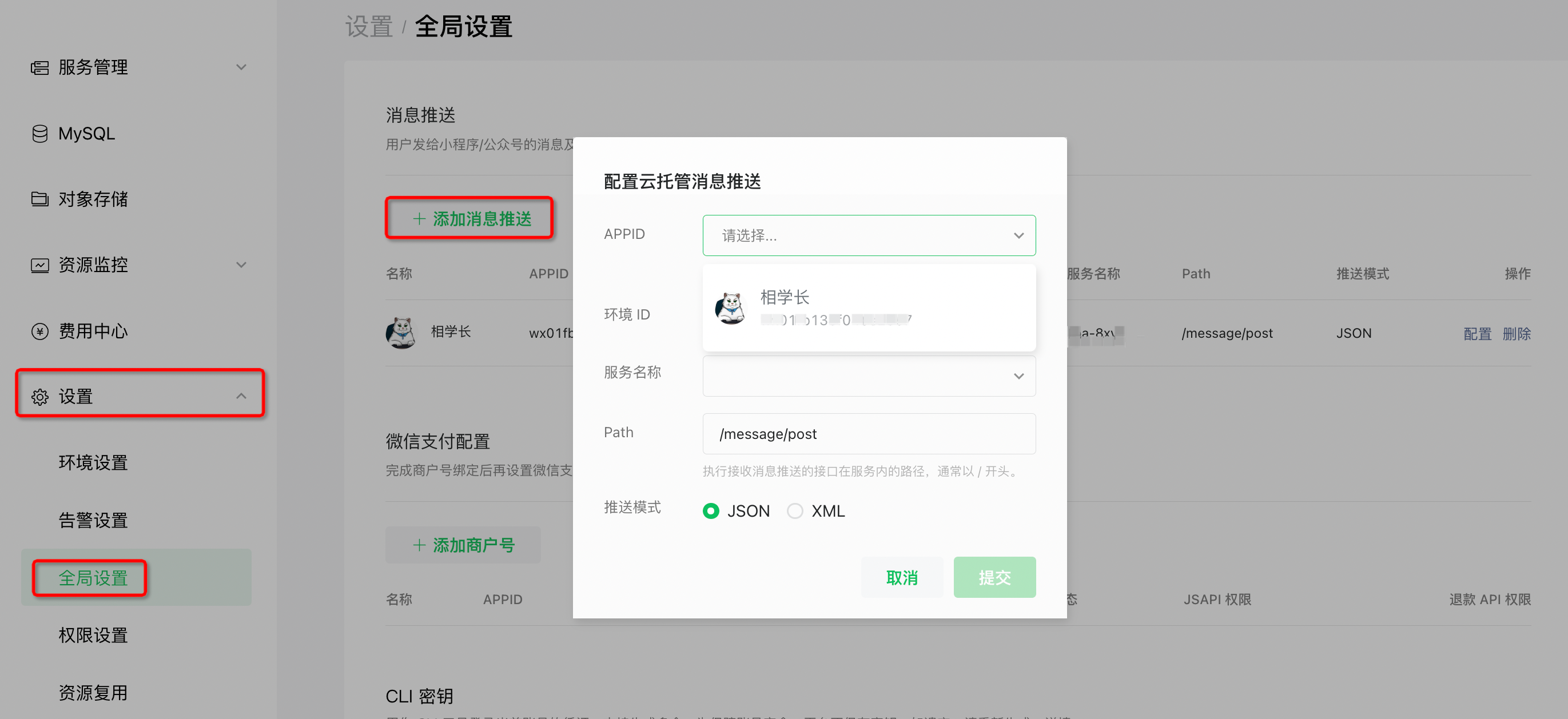
点提交以后,它会检验一下 接口是否能调通,OK的话,你的消息服务就部署成功了,可以通过微信公众号发个消息测试一下看看。
如果这里添加校验失败,可能的原因是这些,请自行排查:
- 并未成功部署云托管服务;
- 云托管服务并未有一个名为
/message/post的POST接口; - 该接口逻辑无法正常执行并返回;
都添加好后,可以在 「服务列表 - 服务器koa-xxx - 运行日志」里看具体日志情况,方便排查一些问题。
第三步:本地开发与调试
每次都 push 代码到线上测试,未免效率太低。我们还是要搭建一个本地联调的环境。官方是推荐下载 Docker,配置 VsCode 插件去做联调。其实也没必要,咱们需求比较简单。只要本地有 MySql ,安装一个 PostMan,就足够做调试了。我自己尝试部署 Docker,虽然也成功了,但过程难免还是会有些奇奇怪怪的地方,没注意卡住了,怪挺费时的。所以还是简单 npm install & npm start 吧。
至于 MySql 与 PostMan 怎么安装,这个就靠大家自己百度或问 ChatGPT 了。
同样的,部署本地环境比较简单,我就不一步一步贴流程了,但会把一些可能要踩的坑,或者一些可能需要的文档,跟大家讲一下:
- 如果本地不是走
docker,那么数据库并不会做初始化,所以需要自己 命令行 或者其他 GUI 工具来初始化一下库。在container.config.js这个文件中,提供了初始化命令:CREATE DATABASE IF NOT EXISTS nodejs_demo;模板代码里的数据库名为nodejs_demo。 - 如果本地不是走
docker,数据库的账号密码需要自己环境变量设置一下,否则是无法连接数据库的。 koa应用模板里用的ORM是sequelize,使用比较简单,也足够用,没用过可以看文档学一下,这是它的文档地址:https://sequelize.org/docs/v6/core-concepts/model-basics/- 之前也提到的,真实响应超时大概3秒左右,而且文档里所说的重试似乎也不会发生。如果你微信发消息没响应,可以看看是否是超时了。
基于以上的信息,我再贴一个最小的能完成 CharGPT 调用的代码,方便本地调试。请记住,由于超时的问题,它很难在微信公众号里得到响应。你可以本地调试并获得结果。
const configuration = new Configuration({apiKey: 你的apiKey,});const openai = new OpenAIApi(configuration);async function getAIResponse(prompt) {const completion = await openai.createCompletion({model: 'text-davinci-003',prompt,max_tokens: 1024,temperature: 0.1,});return (completion?.data?.choices?.[0].text || 'AI 挂了').trim();}router.post('/message/post', async ctx => {const { ToUserName, FromUserName, Content, CreateTime } = ctx.request.body;const response = await getAIResponse(Content);ctx.body = {ToUserName: FromUserName,FromUserName: ToUserName,CreateTime: +new Date(),MsgType: 'text',Content: response,};});
通过 postman测试,你可以获得如下结果(当然,你的问题跟答案都可能会不一样)。

(这道题它出的未免有点儿蠢….)
第四步:解决超时与多轮对话的问题
网上大部分很多教程,并没有告诉大家如何去解决超时与多轮对话的问题。
解决这俩个问题,都必须依赖数据库。因此sequelize的文档还是建议大家看一下,后者换成你熟悉的 ORM。
超时问题
这个其实也好解,Promise.race即可。大致思路是:
- 先往数据库存一条 回复记录,把用户的提问存下来,以便后续查询。设置回复的内容为空,设置状态为 回复中(thinking)。
// 因为AI响应比较慢,容易超时,先插入一条记录,维持状态,待后续更新记录。await Message.create({fromUser: FromUserName,response: '',request: Content,aiType: AI_TYPE_TEXT, // 为其他AI回复拓展,比如AI作画});
- 抽象一个 chatGPT 请求方法
getAIMessage,函数内部得到 GPT 响应后,会更新之前那条记录(通过用户id & 用户提问 查询),把状态更新为 已回答(answered),并把回复内容更新上。
// 成功后,更新记录await Message.update({response: response,status: MESSAGE_STATUS_ANSWERED,},{where: {fromUser: FromUserName,request: Content,},},);
- 前置增加一些判断,当用户在请求时,如果 AI 还没完成响应,直接回复用户 AI 还在响应,让用户过一会儿再重试。如果 AI 此时已响应完成,则直接把 内容返回给用户。
// 找一下,是否已有记录const message = await Message.findOne({where: {fromUser: FromUserName,request: Content,},});// 已回答,直接返回消息if (message?.status === MESSAGE_STATUS_ANSWERED) {return `[GPT]: ${message?.response}`;}// 在回答中if (message?.status === MESSAGE_STATUS_THINKING) {return AI_THINKING_MESSAGE;}
- 最后就是一个
Promise.race
const message = await Promise.race([// 3秒微信服务器就会超时,超过2.9秒要提示用户重试sleep(2900).then(() => AI_THINKING_MESSAGE),getAIMessage({ Content, FromUserName }),]);
这样就解决了超时问题,就是如果响应比较慢的话,用户会一直重试发消息…有点儿蠢。没办法,谁叫咱们没有客服消息的接口权限呢。
多轮对话
曾经我以为,ChatGPT 实现多轮对话,可能是维持了一个 sessionId,只要带上这个 sessionId,就能实现多轮对话。后来我在 openai 文档里看了半天,也没看到类似功能的参数。你问 chatGPT,它也会跟你瞎扯淡,给你一个错误方向。

无奈去 google,才在 stackoverflow 找到了答案:https://stackoverflow.com/questions/74711107/openai-api-continuing-conversation
原来 ChatGPT 实现多轮对话方式很简单粗暴,就是把之前的对话存起来,重新拼接起来 + 这次的问题,一起作为 prompt再传给它就好了…
不过经过我实测,直接拼接似乎效果不太好,我尝试了一些拼接方案,目前这个方案效果还算比较满意:
async function buildCtxPrompt({ FromUserName }) {// 获取最近10条对话const messages = await Message.findAll({where: {fromUser: FromUserName,aiType: AI_TYPE_TEXT,},limit: 10,order: [['updatedAt', 'ASC']],});// 只有一条的时候,就不用封装上下文了return messages.length === 1? messages[0].request: messages.map(({ response, request }) => `Q: ${request}\n A: ${response}`).join('\n');}
需要注意的是,查询时,时间的排序不要错了,不然很容易 驴唇不对马嘴。
这样,我们就完成了一个能多轮对话的 微信 ChatGPT 了。至于 AI 作画怎么实现,这个就很简单,交给大家自己实现了。
为什么回答的效果不如 ChatGPT 官网
虽然我们开发了多轮对话,但我们发现,我们自己开发的服务似乎体验上不如 openai 官网提供的服务。我不是指 UI 交互上官网提供的更友好,而是 UI 对话上,官网的对话能力似乎会更强一些。比如 同样是问,「如何使用 Node.JS 调用你」,我们自己搭建的服务的回答是这样的: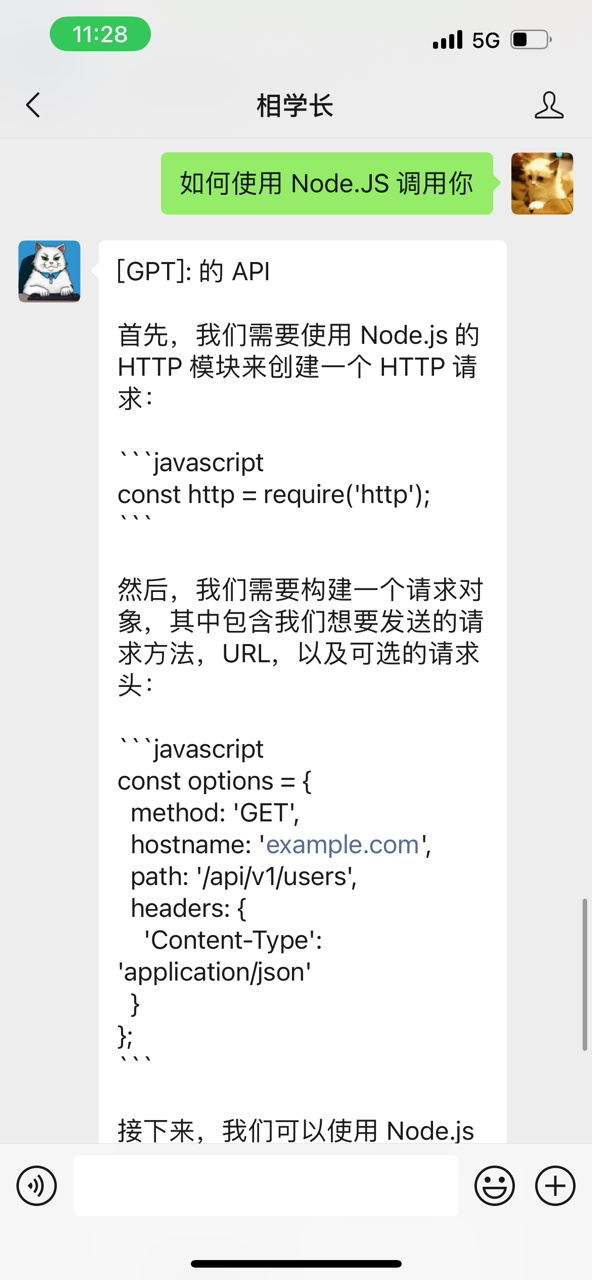
相比官网的回答,显然它没明白,「你」指的是 ChatGPT。那为什么我们自己搭建的 AI 助手能力不如官网提供的服务呢?官网并不开源,我无法从代码层面去感知,我只能基于官网文档的一些信息,做一些个人猜测。不过我对 AI 知识的了解非常少,如果有不对的,欢迎大佬们帮忙指正。
从官方文档来看,官方服务版的 ChatGPT 的模型并非基础版的text-davinci-003,而是经过了「微调:fine-tunes」。文档地址在这:https://platform.openai.com/docs/guides/fine-tuning
大致意思就是,可以通过 API 上传训练数据,基于现有模型,重新微调出一个「自定义的模型」。早在 21 年官网就有篇博文,介绍了通过这种方式,可以极大的提升某些领域的问答准确率。并且举了好几个公司的例子,在使用 微调版的自定义模型后,帮助它们的应用获得了非常高准确率的 AI 反馈。具体的内容可以看这篇博文:https://openai.com/blog/customized-gpt-3/
现在每天成百上千万人访问官服版的 ChatGPT,基于用户的问答反馈,又能生成海量的新的微调数据,这些数据又能重新去微调官服版的 ChatGPT 模型。于是官服版自然会比我们调用基础的text-davinci-003显得更准确与好用。
除了微调之外,还有一种我理解是 「知识库」的方式来提升某些具体领域的问答准确率。在某些特殊的领域,ChatGPT 可能没有一些完备的知识来回答你。这时,你可以把现有的「知识」作为上下文,拼接上当前的问题,合成一个 prompt 传递给 GPT,GPT会根据上下文总结出你问题的答案并回复给你。
但有一个问题就是,「知识库」往往数据非常庞大,实际调用 API 时,我们会发现 合并上下文后的 prompt ,已远远超出了 API 的限制。因此,openai 提供了一种两段式的方法:
- 先将巨量的知识库拆块,并使用 openai 提供的
Embeddings能力(AI 小白的理解是把大量文本向量化,实现更好的相似性匹配)将知识内容向量化。关于它的文档在这:https://platform.openai.com/docs/guides/embeddings/what-are-embeddings - 当用户提问时,可以通过「提问文本」,匹配到具体是知识库中的某一小节内容,把这小节知识提取出来。只把这一小节知识作为上下文,拼接到
prompt传递给 GPT。
官网文档以及 openai 的gihub 提供了几个案例,大家有兴趣可以读一下,加深一下了解:
- How to build an AI that can answer questions about your website:https://platform.openai.com/docs/tutorials/web-qa-embeddings
- Question Answering using Embeddings:https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb
所以官服版,可能也维持了一个自己的知识库,在我们提问时,可以基于这个知识库,帮我们做更准确的回答。
最后多说几句
一方面是关于 微信公众号 本身的感想。对,在大家在畅想 AI 时,我其实先想的是微信公众号。这可能是因为我非常早的接触到了 微信公众号开发。早在 2013/2014 年的时候,微信公众号刚起步,当时甚至还没有 订阅号/服务号 之分。
当年我大三,总是自称为互联网弄潮儿,确实也感觉到了这种第三方开放平台似乎在未来能扮演非常重要的作用。于是,我的第二专业毕业论文(工商管理二专),写的就是互联网开放平台相关的内容。
这在我大四找实习的时候,又遇到了巧事。过去与未来,产生了一种神奇的干涉,让我坍缩在微信公众号上。我经过曲曲折折,最终实习的一家创业公司,恰好也是做微信公众号开发的。以致于后来我的毕业设计,也是自己想的 -「基于微信开放平台实现一个借贷系统」。2015 年的毕设,我用了 Angular + Ionic + 微信开放平台,现在想想,还是比较「互联网弄潮儿」的。
后来我在那家公司干到 2017 年初才走,差不多是做了 2 年左右的微信公众号系统开发。在那之后,就几乎再也没碰过了。直到这个月,我重启了我大学时就建的个人公众号。
就好像一个好久没看到的小孩子,你会觉得它突然长高了很多一样。再次接触微信公众号开发,我也感觉它似乎「成熟」了,「强大」了很多。以前个人开发微信公众号的成本特别高,整服务器、数据库、域名注册、域名备案,还是需要费很多精力的,虽然当年也爱学习爱折腾不怕累。但现在这个微信云托管确实整的好,一条龙服务。
如果这套设施重新回到2015年,那个时候我也会 ORM,也会 Node.js,也会看文档,跟这篇文章的技术要求没有任何差异,甚至英文阅读水平比现在还好一些。相信我一定会因为半天就能部署一个自定义消息服务,一个自定义网站而振奋不已。同时,我的毕设可能也可以完成的更快更好。(我一直耿耿于怀,我的毕设只拿了良好,而不是优秀。而那些用着老套课题,各种网络 copy 的不少毕设却是优秀)
然后才是关于 AI 的感想。我第一次接触 AI,同样是大学,应该是大三的选修课程吧,课程名就是 「人工智能」。不瞒大家,我一个字的知识都没有记住。因为这堂课不用考试,最终考核就是自己写 2 页关于「人工智能」的某部分知识总结就行,而且还是 Word 打印就行。老师还特意强调,大家不用写(打印)太多,自己要多总结,2页就好了。
最终到期末的时候,大家就在各种网上找「人工智能」相关的文章或论文,然后裁剪裁剪,交给老师。我已经忘记我找的是什么内容了,大概就是七八页的内容,我裁剪到了 3 页,实在裁不下去了。毕竟相比人工智能,我的语文水平更高,我只是在裁剪与总结文字,并非是总结知识。
而我的一个室友,他比较懒,差不多也是七八页的内容,原模原样提交上去了。而最终,他获得了一个 优秀,而我又是一个 良好,人工智能就成为他这四年唯一一门分数超过我的学科。于是,第一次接触 AI ,就给我造成了并不是很好的影响。
进到社会以后,我应该至少超过 3 次有想学习 AI 的想法。因为这几年几乎每过一段时间,就会有一些相应的 爆炸性 新闻出来,比如 阿尔法狗大战柯洁。这让人觉得,程序员不学 AI,真的就要被淘汰了。同时,这也增加了我买显卡时,更想买旗舰显卡的理由。(我买它不仅仅是为了玩游戏,也是为了研究机器学习)
然后开始了 「搜索相关资料并添加收藏 - 打开资料学习 - 看不懂 - 算了不学了」的多轮循环。我现在的 Chrome 标签里还躺着 Google 的机器学习教程。我也不知道是几几年加的,总之很久了。

若有收获,就点个赞吧
0 人点赞
