今天给大家介绍一款基于ChatGPT的法律检索问答工具——AI 法律助手。
这个工具可以让用户向AI提出自己想要了解的法律问题,AI即可检索法律文件后生成回答。
不过,需要提醒的是,因为AI 法律助手不保证准确率,仅供参考学习哦!而且,这款工具还可以自行部署到 Vercel 上,使用起来也十分简单方便。
说了这么多,不知道大家是否被吸引了呢?欢迎点击下方的链接了解更多!
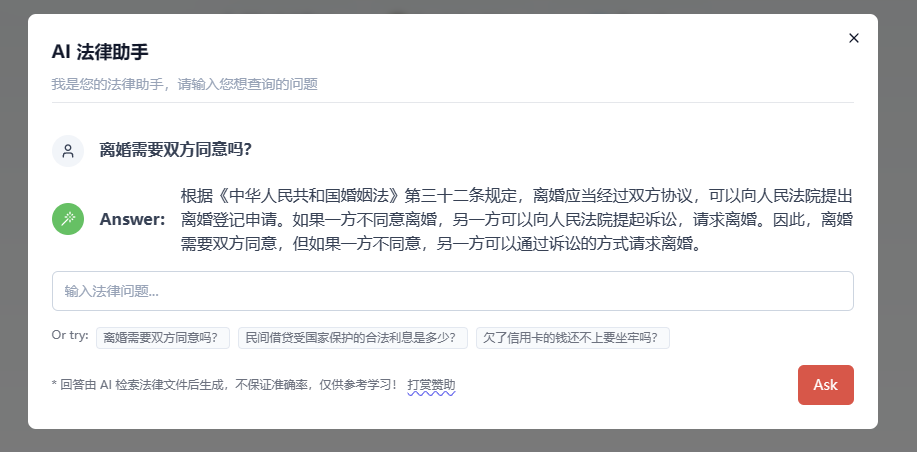
AI 法律助手工具地址
地址:https://law-cn-ai.vercel.app/
GitHub地址:https://github.com/lvwzhen/law-cn-ai
AI 法律助手
法律文件来源:https://github.com/LawRefBook/Laws
项目模板:https://github.com/supabase-community/nextjs-openai-doc-search
这个项目从 pages 目录中获取所有的 .mdx 文件,并将其处理成自定义上下文,以在OpenAI 文本自动补全提示中使用。
更多好玩
| 智能写作助手 | AI 百科全书 |
|---|---|
| AI 翻译专家 | ❤️打赏赞助❤️ |
部署
部署此starter到Vercel。Supabase集成将自动设置所需的环境变量并配置您的数据库概要。您只需要设置 OPENAI_KEY,然后就可以开始了!
技术细节
构建您自己的自定义ChatGPT涉及四个步骤:
- [👷 构建时间] 预处理知识库(您的 pages 文件夹中的 .mdx 文件)。
- [👷 构建时间] 在PostgreSQL中使用 pgvector 存储嵌入向量。
- [🏃 运行时] 执行向量相似性搜索,查找与问题相关的内容。
- [🏃 运行时] 将内容注入到OpenAI GPT-3文本自动补全中,并将响应流式传输到客户端。
👷 构建时间
步骤1和2发生在构建时间,例如当Vercel构建您的Next.js应用程序时。此时执行 generate-embeddings 脚本,该脚本执行以下任务:
除了存储嵌入向量之外,此脚本还为每个 .mdx 文件生成一个校验和,并将其存储在另一个数据库表中,以确保仅当文件更改时才重新生成嵌入向量。
🏃 运行时
步骤3和4在运行时发生,即用户提交问题时。发生这种情况时,执行以下一系列任务:
此为 SearchDialog(客户端)组件和vector-search(边缘函数)负责的相关文件。
数据库的初始化,包括 pgvector 扩展的设置存储在 supabase/migrations文件夹中,并在运行 supabase start 时自动应用于本地PostgreSQL实例。
本地开发
配置
- cp .env.example .env
-
启动 Supabase
确保已安装并在本地运行 Docker。然后运行
supabase start启动 Next.js 应用程序
部署
仅需将此 starter 部署到 Vercel。Supabase集成将自动设置所需的环境变量并配置您的数据库Schema。您只需设置 OPENAI_KEY 并开始使用即可!

了解更多
阅读我们如何建立Supabase文档的ChatGPT的博客帖子。
- [Docs] pgvector:嵌入和向量相似性函数。
- 观看Greg 关于Rabbit Hole Syndrome YouTube Channel的 “How I built this” video:


若有收获,就点个赞吧
0 人点赞
