前言
在去年年底 ChatGPT 刚火的时候我就有一个想法,它能不能帮我读一下晦涩难懂的保险条款,告诉我它到底在讲什么?到底什么病能赔多少钱?甚至能告诉我里面是不是藏有一些坑?
但是当我把条款内容复制到 ChatGPT 时,我们会发现,它直接告诉你:“太长了,它受不了”。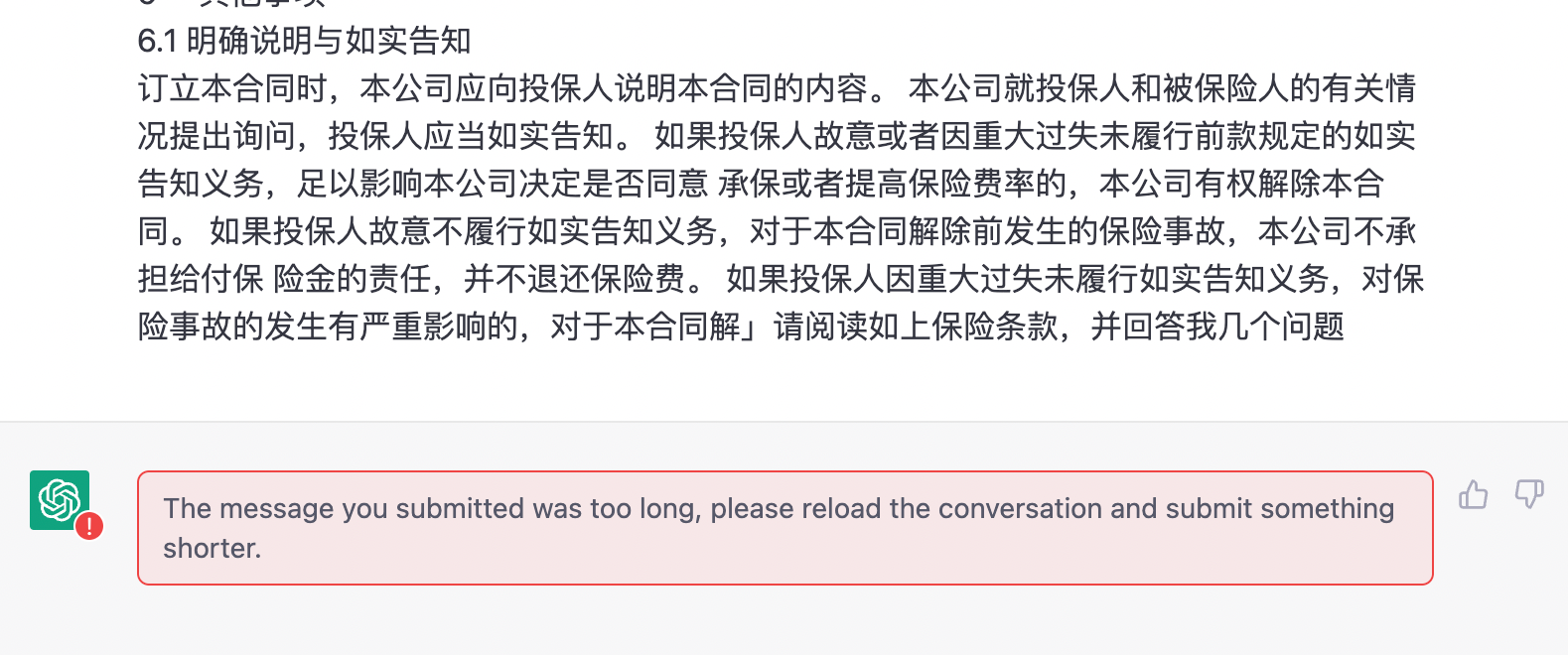
当我们自己打开 openai 的文档(https://platform.openai.com/docs/api-reference/completions/create),我们才明白:哦,原来它接受的最大长度是 4096个 tokens。但这个 一个 token 到底是多长呢?暂时还不知道,反正就是有这么个上限。很显然,我们的保险条款远远的超过了它的上限,因为我才复制两三页的内容它就 Error 了。
但我们还是纳闷,不应该啊,ChatGPT 不应该很强吗?它的官方例子可是摆了几十个案例,看网上的各种文章,它似乎在文字与编码领域,远超绝大数人类,怎么会连个保险条款都无法承受。
我想从这个案例中看看有没有其他路子,可惜确实没有合适的案例能解决我这种超长文本的诉求。于是我停止了这个想法,并先回家过了个快乐的新年。
但在最近,在我的不屑但可能没啥意义的努力下,我几乎完成了这个想法。先放几个截图给大家看看。
问蚂蚁爆款「好医保长期医疗」几个问题的答案:
问市面上很火的「达尔文7号重疾」的问题及答案:
如果你仔细看,你会发现,它已经能非常准确的回答这几个很多保险小白常问的问题了。
那我到底是怎么实现的呢?这篇文章来一探究竟。
先纠正一下
在我开始正文之前,先让 ChatGPT 跟大家做个简单介绍。
所以本文标题其实不对,准确说应该是「如何让 openai 的 API 帮我读懂保险条款」。因为我其实是调用了 openai 提供的 API 能力来满足需求的。更准确来说是调用了其 GPT-3 的一些模型,而不是挂代理直接问 ChatGPT。但为了大部分读者容易理解,就先取一个不恰当的标题了。
后文中,我将会以 GPT 通用指代我所调用的 openai 的 API 服务。
核心解决方案
话说在新年回来后,ChatGPT 仍愈演愈烈,因此我又来了点儿兴趣,并尝试把 GPT 接入我一个年久失修的个人公众号。就在这个接入的过程中,为了解决接入遇到的不少问题,我看了不少文档。果然是开卷有益,实干兴邦啊。过程中我又接触学习了一些有用知识。其中最重要的是两个点知识:
其一是:GPT 的多轮对话是如何实现的?其实很简单,就是把历史对话都存起来,然后按照时序重新拼接,再加上这次的问题,合并一起作为 prompt再传给 GPT 即可。
其二就是,如何让 GPT 理解超长文本知识并做问题回答?我在逛 openai 官方文档的时候,发现了其实人家早早就想到了这个问题,并贴心的准备好了教程文档。这在我上一篇 ChaGPT 的文章中也已提到:
公众号如何接入 ChatGPT 及 一些感想
- How to build an AI that can answer questions about your website:https://platform.openai.com/docs/tutorials/web-qa-embeddings
- Question Answering using Embeddings:https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb
它的思路其实很好理解,详细来说,主要是分几步:
- 先将巨量的文档知识拆块,并使用 openai 提供的
Embeddings能力将该部分内容向量化,并做映射存储。向量化的目的是为了做两部分文本的相似性匹配。关于它的文档在这:https://platform.openai.com/docs/guides/embeddings/what-are-embeddings - 当用户提问时,将用户的「提问文本」也做向量化。
- 遍历已拆块并向量化的文档内容,将之与向量化后的「提问文本」做内容相似性比较,找到最为相似的文档内容向量。
- 根据之前的映射关系,找到这段「向量」映射着的原始文档内容块。并把这个内容块作为上下文传给 GPT。
GPT 会根据这段上下文回答用户的提问。
原来如此,那么我只要把保险条款分段向量化,再根据用户提问匹配到相应的那段内容再回答不就好了吗。简单,上手吧。把大象放进冰箱需要几步?
这个问题似乎正如「把大象放入冰箱」。描述起来很简单,真正要做起来就举步维艰。
在我们面前最大的问题就是,到底怎么把这个文档做分割?
最简单的方案自然是,把保险条款按页码一页一页分块,如果一页内容也超了,那我们就半页半页分块。 但这忽略了一个最大的问题,就像大象的各个器官并非水平均分分布一样,知识内容并非是按页码分割的。一个知识可能第三页正好起了个标题,第四页才是详细的描述。而向量化匹配的时候,却可能只匹配到第三页的内容。比如这个「好医保长期医疗」的责任免除条款,就很容易丢失下半部分的免除责任,造成回答准确性降低。
除此外,这样的分割还容易让 GPT “学坏”。因为粗暴的按页分割,很容易把无关的知识传给 GPT,导致它可能会因为这些无关的信息返回错误的答案。比如如下关于用户信息告知的条款:
前一页内容如下:
后一页内容如下:
如果你询问的问题是:“如果投保时年龄填写错误,理赔时会怎么样”。
那很有可能你只会将第一页内容传给 GPT,它将会告诉你保司不承担任何责任,并不退回保险费。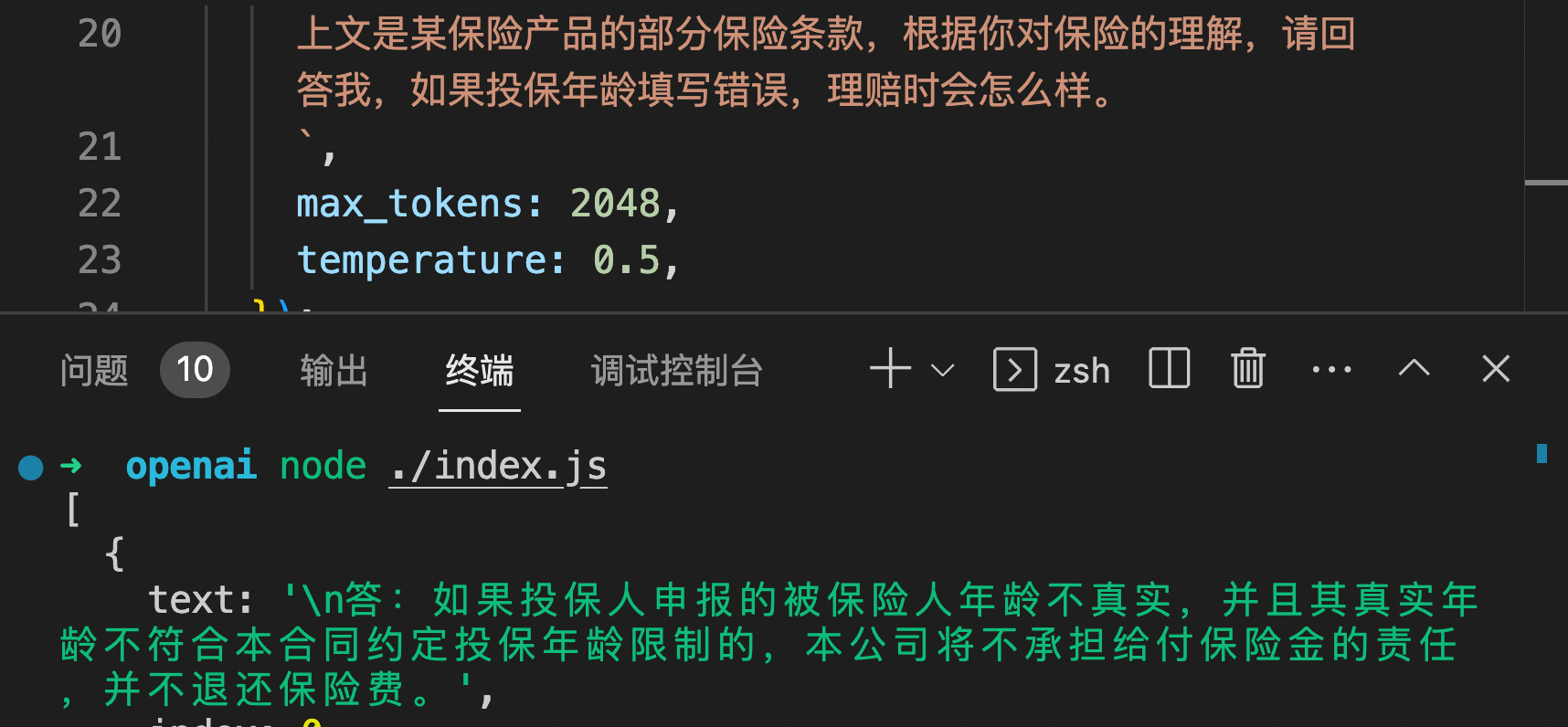
而用我实现的服务所拼接的知识块,得到的版本答案如下:
显然这个问题得到了准确回答。
如何分割文档
懂得了很多道理,也依旧过不好这一生。 - ChatGPT也不知道是谁说的
如何分割文档?其实这个也很好想方案,只是比较难搞。
保险条款是有文章结构的,只要咱们可以按文章标题给文档做结构化就好了。最终文档就会成为这样的一个文档树:
interface INode {title: string;content: string;children: INode[]}type DocTree = INode[]
然后我们在深度遍历这个文档树,去识别每个节点所包含的所有内容的长度,达到一定阈值就剪下来作为一个「知识块」。这就像剪一个西兰花 🥦,按自己可以含进去的大小,一朵朵剪下来。
通过这样的手段,我们就能在满足知识文本长度的限制下,切下最为连续完整的知识内容。这其实很简单,但如果一定要装逼取个算法名的话,那我称之为:西兰花算法。
但在我们切割西兰花之前,还有一个棘手的问题,怎么把一个条款文档先变成一棵西兰花(一颗文档树)?
第 0 步:先明白tokens咋回事
因为后文很多内容都跟这个tokens相关,所以我必须得提前介绍一下。
有时间的同学可以直接看官网介绍文档:What are tokens and how to count them?
没时间的同学可以继续听我简单总结一下:
tokens不是指prompt字符串的长度;token指的是一段话中可能被分出来的词汇。比如:i love you,就是三个token,分别为 「i」「love」「you」。- 不同语言
token计算不一样,比如中文的「我爱你」其实是算 5 个token,因为它会先把内容转成unicode。读过我公众号那篇文章关于 Emoji 你不知道的事的同学,你们就会知道,有些 emoji 的token长度会超出你的想象。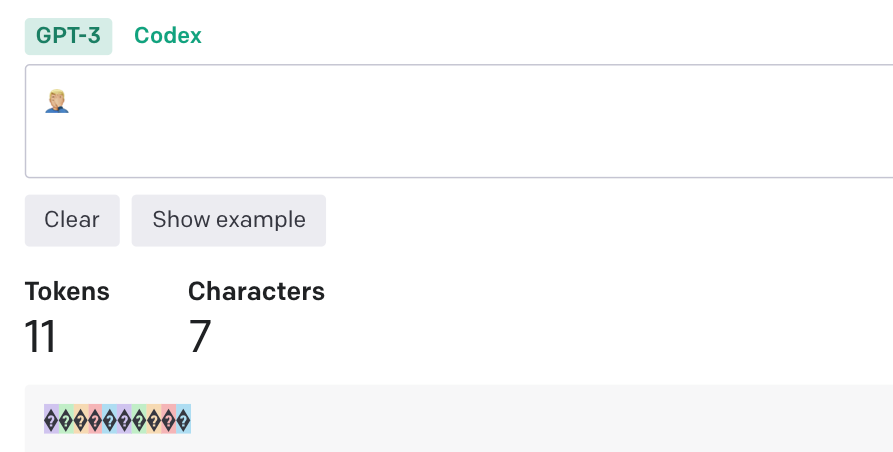
- 你可以用这个网站在线体验你的文字的
token长度:https://platform.openai.com/tokenizer - 在
node.js环境中,你可以用 gpt-3-encoder 这个 npm 包来计算tokens的长度。
第 1 步:标题的识别
我们可以先看看市面比较火爆的医疗与重疾险产品的条款。发现其实保险大部分条款是有一定格式标准的。几乎都是嵌套数字标题 + 内容。那是否可以依据一定的规则,识别出那部分是标题,然后根据标题做切割即可?比如说,根据 「数字 + ·? + 数字?」的正则做匹配。
虽然我正则写不来,但是 ChatGPT 写的来呀: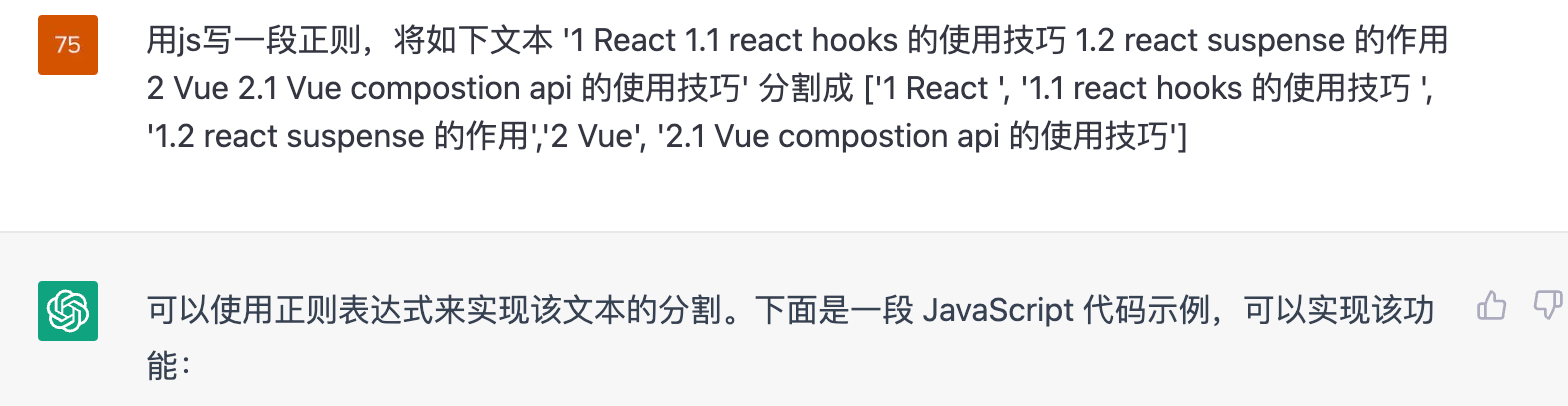
const text = '1 React 1.1 react hooks 的使用技巧 1.2 react suspense 的作用 2 Vue 2.1 Vue compostion api 的使用技巧';const regex = /(\d+\.?\d*)\s(\w+)/g;const matches = text.matchAll(regex);const result = [];for (const match of matches) {result.push(match[1] + ' ' + match[2]);}console.log(result);// output['1 React', '1.1 react', '1.2 react', '2 Vue', '2.1 Vue']
虽然它的回答不够完美,但是基本够我们继续下一步编码了。于是我尝试把 PDF 的全文内容复制出来,并做分割。然后我就会发现几个很麻烦的地方:
- 数字不是只在标题中出现,正文中也很容易出现各种数字。
- 有些注释内容,也有数字+内容的出现

所以我们复制出来的文本是这样的:
module.exports = `2.3 等待期自本合同生效(或最后复效)之日起 90 日内,被保险人因意外伤害4以外的原因, 被保险人因意外伤害发生上述情形的,无等待被确诊患有本合同约定的轻症疾病5、中症疾病6、重大疾病7的,我们不承担保险责任,这 90 日的时间称为等待期。期。轻症疾病 中症疾病重大疾病本合同的保险责任分为基本部分和可选部分。,本合 ,退还等待期内,我们的具体做法见下表:等待期内发生的情形我们的做法不承担本合同“2.4 保险责任”中约定的保险责任同继续有效不承担本合同“2.4 保险责任”中约定的保险责任您已交的本合同保险费8(不计利息),本合同终止2.4 保险责任1 保单生效对应日:本合同生效日每年(或半年、季、月)的对应日为保单年(或半年、季、月)生效对应日。若当月 无对应的同一日,则以该月最后一日为保单生效对应日。2 保单年度:自本合同生效日或年生效对应日零时起至下一个年生效对应日零时止为一个保单年度。3 保险费约定交纳日:分期交纳保险费的,首期保险费后的年交、半年交、季交或月交保险费约定交纳日分别为本合同的保单年生效对应日、半年生效对应日、季生效对应日或月生效对应日。`
所以,如果只是粗暴的根据某种标题规则来做分割,那我们只会得到错乱的结果。
那我们人眼是如何从页面中知道它是标题的呢?我们自然是根据这个文案的位置、大小,综合了我们的历史经验来判断它是不是标题。也就是说,要想真正从一段文本中做很好的标题识别以及内容分割,必须要获取这段文本的其他元数据。
我的下意识,自然是希望还有 AI 的能力。我把 PDF 转图片,都传给某个 AI,它很聪明,帮我 OCR 识别文档并做好了充分的文档结构化。
但我在 openai 官网并没有找到这样的 api 能力提供。由于我的 AI 储备非常薄弱,我也很难在网上找到可以满足我诉求的开源工具。而且根据我很可能不成熟的感觉,我感觉现在训练出来的开源 AI 模型,顶多只是识别出文字以及文字所在的绝对位置,也很难帮我直接把文档给按照标题结构化了。真有这样的需求,可能需要我自己准备大量材料来训练。这似乎再一次难倒了我。
于是我又想到了 pdf.js这个工具。我们 C端 部分投保协议就是利用这个工具包,把 PDF 文档转成 DOM 渲染到页面上。虽然我之前并没有使用过,但我相信它肯定可以拿到 PDF 上很多元数据,否则不可能做到还原成 DOM 去渲染。我甚至想,它有没有可能直接帮我转成一颗 根据标题已经结构化好的 DOM 树。
在我使用pdf.js后,我发现,刚才稍微想的有点多了,但也足够用了。它能把 PDF 文档的文字块以及这个文字块的文字与大小信息 解构出来。比如这样:
[{"str": "2.4","dir": "ltr","width": 13.2,"height": 10.56,"transform": [10.56, 0, 0, 10.56, 346.03, 285.05],"fontName": "g_d0_f1","hasEOL": false,"pageNum": 4},{"str": " 保险责任","dir": "ltr","width": 42.24,"height": 10.56,"transform": [10.56, 0, 0, 10.56, 364.39, 285.05],"fontName": "g_d0_f12","hasEOL": false,"pageNum": 4}]
其中的 width与height决定了文字块的大小,transform决定了文字块在文档上的绝对位置信息。pdf.js也是根据这些信息,把 PDF 内容以绝对位置与大小一个个的转成 DOM 并绘制在网页上。它不理解前后语序与内容结果,它只是粗暴的拼装。
但这对我来说已经够用了,有了这些信息,我就能分析出哪些文字块是标题,哪些文字块是正文的正常数字,哪些内容块是底部的注释内容。比如说:
- 出现最多的字体大小,有理由相信这就是正文字体大小
- 持续出现的一个很靠左的 X 坐标,且该坐标内容基本是数字,有理由相信,这就是数字标题或数字注释所在的 X 坐标
- 虽然符合上述第二条规则,但却比正文字体小很多,有理由相信,这是注释前的数字
等等等等吧,除此外,我们还需要判断什么时候到注释内容,什么是页码内容。因为这些内容都要做一些特殊处理。另外就是不同文档可能有些特殊的边界情况要处理一下。
虽然说这依旧很人肉,不智能,但至少能把路走通了。至于有些不是以 x.x.x 这样的数字做标题的文档,比如:第一章、第一节什么的,还是能拓展的,但就先不考虑了。
第 2 步:过长内容摘要化
事情走到这一步,大问题就没有了。但实际应用的时候,我们还是会发现一个小问题,就是很多小节的内容其实比较长,我们能做相似性映射的知识块其实往往不仅一块。当我们拼接多块知识的时候,内容又超出了。而如果我们只拼接一块内容,知识又不够完整。这又让我们抓耳挠腮了。
我仔细看了看这些小节的内容,我觉得,其实这段文本,要是用文言文来说,可能还可以再短一点(汉语真是博大精深)。但是我觉得如果让 GPT 帮我把它转成文言文的话,用户提问的问题很可能就映射不到了。当然,我也真的试了一下,发现 text-davinci-003这个模型似乎在文言文领域也不太行,保险条款它很难转成文言文。
但我有了另外一个思路,就是保险条款其实废话还是有些多的,我可以让 GPT 帮我做一些摘要性的总结,且尽量不丢失最核心的有效知识。在我网上搜索这块相关的知识时,发现 NLP 领域有一种叫「命名实体识别(https://baike.baidu.com/item/%E5%91%BD%E5%90%8D%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB/6968430)」的技术,常用于搜索引擎、信息提取、问答系统中。不管三七二十一了,openai 这么强大,那我就这么让它帮我这么做吧。
async function getSummary({ content, tokenLength }) {const promptContext = `'''{{content}}'''基于命名实体识别构建内容摘要:`;const contentTokenLength = tokenLength || encode(content).length;const promptContextTokenLength = encode(promptContext).length;const completion = await openai.createCompletion({model: 'text-davinci-003',prompt: promptContext.replace('{{content}}', content),// 1000 ~ 4096,最大也不能超过1000max_tokens: Math.min(4096 - contentTokenLength - promptContextTokenLength,1000,),temperature: 0,});return strip(completion?.data?.choices?.[0].text, ['\n']);}
实际测试下来,这样的方式相比直接总结摘要,从最终效果来看,返回的结果会稳定很多,且返回的知识不会只说到一半。具体原因也不懂,有资深的大佬可以帮忙指点一下。
经过这样摘要化以后,我们就能把一段较长的知识文本给有效缩短。当用户问起相关知识时,可以调用更多的知识块来回答用户。
第 3 步:超长内容极限压缩
事情走到这一步,你可能以为就真没啥问题了。但实际上我们又遇到了个小麻烦。就是有部分小节的内容依旧还是太长了。就像一颗基因变异的西兰花 🥦。
我已经剪到最小的分支了,但这个最小的分支依旧超过了max_tokens的限制。这又难倒我了,现在我该怎么分割它?这似乎回到了我最开始遇到的问题。
不过好在,这些变异的西兰花并没有动画灵能百分百中的那么夸张,大部分还只是 略超 max_tokens一些,几乎不会超过其两倍。而自己观察这些超出去的内容,往往是两种类型。
- 较长的表格,比如药品列表,如下图1。
- 一些责任或疾病的详细介绍,如下图2。
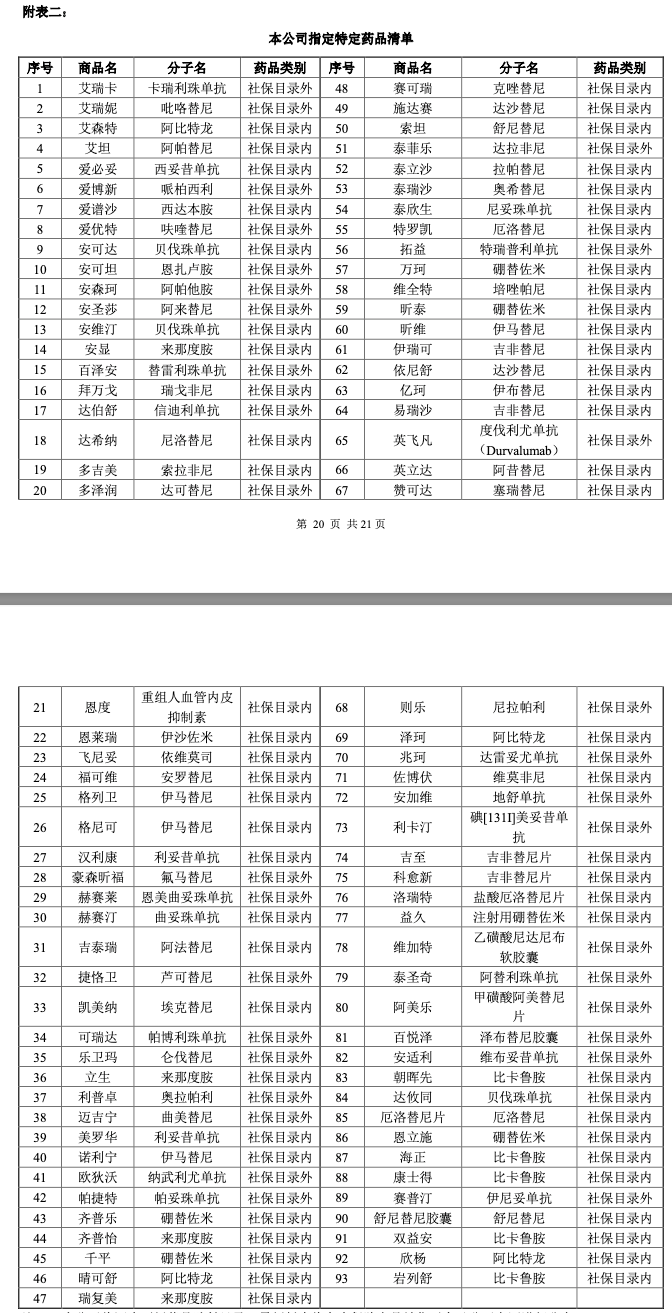

我们发现这些小节的内容,其实并不适合分割。比如药品列表要是分割成两块接近max_tokens的知识内容,一次性问答只能获取其中一块知识。这就会导致回答错误。比如你问有多少种药品可以报销,它自然会算错。责任也是一样。
但这些小节有另外一个方向,就是压缩内容。里面有很多文字其实是相似的,比如一堆的社保目录内/外。比如责任内容中频繁出现的:恶性肿瘤``保险金``被保险人等等。我们只要做一本字典,把这些很长的重复性文字,用另外一种特殊的较短的字符指代。这段长文本就会瞬间被压缩到较短的文本,我们再连同字典一起发给 GPT,让它再翻译回来并做摘要化,于是就绕过了max_tokens的限制。
但问题又来了,说的容易,代码怎么知道哪些文字是一段词语?如果代码不知道哪些文字是一段词语,又怎么做字典映射。总不能自己先把所有可能的词汇都预先想好吧。虽然保险有一些专业术语可以提前预设,但总归有更多的未知的。
这就引出了 NLP 领域的另外一门技术,分词。很开心的是,在中文领域,且在 node.js 生态中,有一个比较好用的分词工具「结巴分词-https://github.com/yanyiwu/nodejieba」。 不出意外,这也是 ChatGPT 告诉我的。
运用这个结巴分词,我们就可以把一段内容分割成一个个词汇,同时也支持传入用户预设的词汇字典。这样我们就能知道哪些词汇在一段文本中被重复使用多次。对于这些词汇,我们再用一个最短的字符去映射它。
const nodejieba = require('nodejieba');nodejieba.load({userDict: './userdict.utf8',});const longText = '相学长白天吃饭,相学长中午也吃饭,相学长晚上还吃饭';const words = nodejieba.cut(longText);console.log(words);// output['相学长','白天','吃饭',',','相学长','中午','也','吃饭',',','相学长','晚上','还','吃饭'];
为了映射的字符尽量的短,我也是挠了一下脑袋,本来最简单就是一个特殊字符加上从1递增的数字就好了,比如这样:*${index}。但是这个方式经过我实测,压缩完的tokens效果还不够极致。考虑到我们都是基本是中文环境,我最终选择了 26个字母大小写 + 24个拉丁字母大小写作为索引:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZαβγδεζηθικλμνξοπρστυφχψωΑΒΓΔΕΖΗΘΙΚΛΜΝΞΟΠΡΣΤΥΦΧΨΩ
根据第 0 步的知识,我们知道,千万别用 emoji 去做字典索引。
这样我们就得到最多100个索引,当然如果内容中已有出现具体的字母,最好还是针对该段内容剔除该字母。经过实际测试,这样的压缩效果会比数字映射法稍微好一些。且经过实测,这样问 openai 依旧能得到正确答案。举个例子:
上文中的,相学长白天吃饭,相学长中午也吃饭,相学长晚上还吃饭
会被转化成,a白天b,a中午也b,a晚上还b|上文中,a:相学长,b:吃饭
我们把这句话拿去问 GPT:相学长每天都在做什么。它能给出正确的回答:相学长每天都在吃饭。
除了字典法压缩外,其实还有一个也比较显著的手段。就是把全角字符全部转成半角字符。在我的实际测试中,一段 8247 个**tokens**长度的内容。换半角相比不换半角,能多压缩 580 个**tokens**,简直是效果惊人!
其实不仅仅超过**max_tokens**的文本需要压缩。我建议超过 3000 **tokens**的文本都得压缩一下。因为 openai 最大的 4096 个token限制。并非是限制 prompt。而是限制 prompt+ 它的答案。也就是说,当我们做摘要化的时候,如果我们提供的原始内容越长,它能返回的摘要就越短。这显然不符合我们的诉求。所以,虽然文章中这里写着是第三步,但实际操作时,压缩其实是第二步,压缩需要在摘要化之前。
也是因为**max_tokens**的计算涵盖了 GPT 的回答内容,所以当我们根据用户提问拼接知识块的时候,不能按照 **max_tokens**的限制去打满内容,尽量留出 几百到一千的 **tokens**给 GPT 做回答。
在我实操过程中呢,其实还存在一个文档的内容,怎么压缩也压缩不到预期的长度。我确实选择了逃避,因为这段内容是无数个疾病的详细介绍,我骗自己说这些详细介绍并没太大用。因此最终我做了一个特殊处理,如果是这个超长的疾病介绍,我就只保留了疾病标题,去掉了疾病的内容。
针对这种,再压缩也解决不了的问题,我目前确实还没找到非常好的解法。
最终经过我们对 PDF 文档的分割、压缩、小节内容摘要化、转成嵌套文档树,最终再上一个西兰花算法。我们就能完成对这个 PDF 文档的合理分割了。最终我们再把分割后的内容做向量化处理,就能实现一个比较好的基于超长保单文档的保险产品问答服务。
代码已开源
相关代码开源,有兴趣的同学自己下载继续研究吧~ https://github.com/wuomzfx/pdfGPT
关于到底怎么做向量化、怎么做匹配,我在本文就不多说了,这个还是比较容易了。包括其他还有一些特殊的处理,比如怎么把注释内容拼接到正文里。这些都可以在源码中方便寻找到。其他可能还稍微需要一点工具知识的,就是 node 中如何做两个 embedding 向量的相似性匹配。用 @stblib/blas这个 npm 包就行。DEMO 示例:
const ddot = require('@stdlib/blas/base/ddot');const x = new Float64Array(questionEmbedding);const y = new Float64Array(knowledgeEmbedding);const result = ddot(x.length, x, 1, y, 1),
如果还有哪里不明白的,欢迎评论区或者先尝试问下 ChatGPT~
最后一点小感悟
感觉人工智能的时代真的要到来了,连我这种 AI 小白,似乎都已经能完成一个可能真的能投入使用的服务。我再整个小程序,糊个页面,把一些异常容错机制再完善完善。再稍微整个爬虫,从保险行业协会网站帮用户快捷找到相关的保险条款。我几乎就能实现一个帮助用户回答保险产品的应用了。
亦或者,我可以自己预设一些问题。通过这些问题,我可以从保险条款中结构化出很多有效的信息,比如保额保费、责任细节、投保年限、续保年限等等。结构化之后,我又可以直接做不同产品的对比,根据用户的要求推荐比较合适的保险产品。这是一件挺有可能的事情,我尝试把之前的两个问答作为对比再次问 GPT 推荐哪款产品,它的回答比较中肯且有用。
总之,新的 AI 基础设施,已经能成为现在大部分工程师的有利工具。在某些垂直领域做一些深入研究,通过这些工具,AI 就能发挥出意想不到的作用,我们可以快速的产出各种有意思的产品。就好像 HTML5 跟 小程序 带来一系列有意思的 轻量APP 一样。相信,AI 浪潮在这两年就要席卷而来了~~

若有收获,就点个赞吧
0 人点赞
