摘要
本文介绍了一个完整的自动化工作流案例,并给出了全套可以运行的 Python 代码。
该工作流主要功能是实现:输入一个 B 站视频的 BV 号后,自动抓取其基本信息和 CC 字幕,并通过 OpenAI API 的 GPT-3.5 接口将视频的主要内容进行摘要,并将视频信息和摘要内容保存到相应的 Notion 页面中。
效果展示:
脚本使用演示

写在前面,啰嗦几句:撸一个本文中的小脚本费不了多少时间,我也乐于免费分享出来。但其实我在这个过程中更重要的收获是打破了自己的惯性思维和路径依赖,如果大家能跟随我改正这样的思维误区,肯定是比学会一个单独功能的脚本更大的收获。(当然了,也可能你本来就没有这个误区,那就说明真的只有我是傻——)
而且,OpenAI API 目前对输入长度有限制,后面我会给出两种折中的办法,但实际体验可能不一定比得上全文复制进去以后用 Notion AI 摘要。
总之,这是一篇完整的自动化工作流分享,你可以从中摘取你觉得有用的部分进行复现。
文章比较长,断断续续写了几天,希望大家点赞+收藏。拜谢。
需求 & 我过去的思维误区
众所周知,B 站是个学习网站。边看视频边记笔记是常见需求,B 站也因此专门加入了笔记功能。
但是 B 站笔记的编辑器满足不了太多需求(时间戳跳转的功能很不错),记一些关键的时间点和简单的笔记没问题,但是想要更系统化就要借助别的笔记软件了。
我自己原来大概有这样的工作流:下载视频→提取音频→音频转文字→辅助笔记。期间因为生产力工具的变化,方式也变化过许多,比如直接把下载的视频导入飞书妙记[1],既提取文字也方便跳转时间;使用 Notion AI 做视频信息的 Gallery;使用 logsql / B 站官方笔记的时间打戳功能,等等。
但是在这么多次工具的切换中,我始终没有克服自己的惯性思维和路径依赖,看到什么需求都想自己拿 Python 一把梭,做成自动化流程;而且工具更新了这么多次,我始终停留在视频和语音转文字里面不可自拔,致力于研究怎么更方便地下载视频,怎么提取音频,哪个 API 转文字的效果更好。
直到我昨天遇到了 @吕立青-JimmyLv 分享的工具:(我也参考了大佬的 prompt,这个项目也是开源的,可以直接本地化部署)
https://bilibili.jimmylv.cn/videobilibili.jimmylv.cn/video
操作很简单,只需要给一个视频地址,就能在几秒内把文字摘要出来…我当时愣了一下,咋可能这么快啊???一定是哪里不对…
然后我才突然突然意识到:「妈的,我是傻逼。B 站早就有 CC 字幕[2]了。」关键是,我不光知道这件事,还专门研究过怎么把 B 站接口 CC 字幕的 JSON 转成 SRT 格式[3],结果从来从来没想起来我能直接从这里获取视频的全部文字内容。
好了你们可以开始笑话我了…(捂脸)
Whatever,至少从今天开始我没必要去为了摘要笔记下载视频了…我对不起那些因为我的愚蠢而浪费的带宽和算力…
简化后的工作流
(0.前置工作:可以套一个循环,批量拉取一个 UP 主的所有视频或者自己的某个收藏夹;或者改变触发方式,比如交由一个飞书 bot 来触发执行;或者浏览器插件等方式。)
- 遇到一个视频,通过它的 BVID 获取基本信息;
- 自动抓取视频的 CC 字幕并解析;
- 将视频的文本内容发送给 OpenAI API,要求其进行内容摘要;
- 将视频的基本信息和 GPT-3.5 返回的摘要内容,填入 Notion 的相应页面。
抓取 Bilibili 视频基本信息
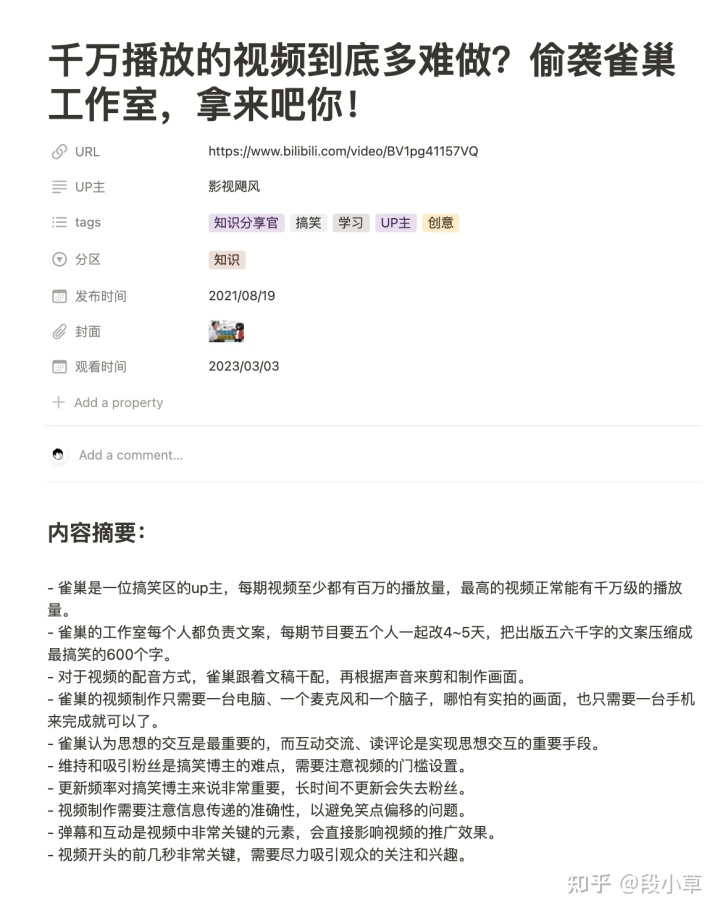
针对一个视频,我选择主要保存标题、URL、UP主、分区、tags、发布时间、记录日期、封面图等内容,大家可以根据自己的需求自定义所要抓取保存的字段。接下来就是常规的抓取数据的操作:
抓取入口
首先是确定入口。对于B站视频,BV 号(原来的 av 号)是唯一 ID,大部分 API 都是以 BVID 作为参数,视频 URL 直接字符串拼接就可以得到。
基本信息
标题、UP主、分区、发布时间、封面这几项都可以在视频信息的 API 中找到;tags 则是一个单独的 API;记录日期则是使用 time 模块计算程序运行时的当下日期。
这两个 API 都可以在用浏览器的调试工具找到,不需要额外的抓包操作,就不再赘述过程了。(GET 方法,参数是vid,后面的代码里会看到)
(顺便,写代码的过程中真有困难也可以多问问 ChatGPT,说不定会直接查到隐藏在 GIthub 深处的古早 API,以下不再重复演示,ChatGPT 对本文代码有一定帮助)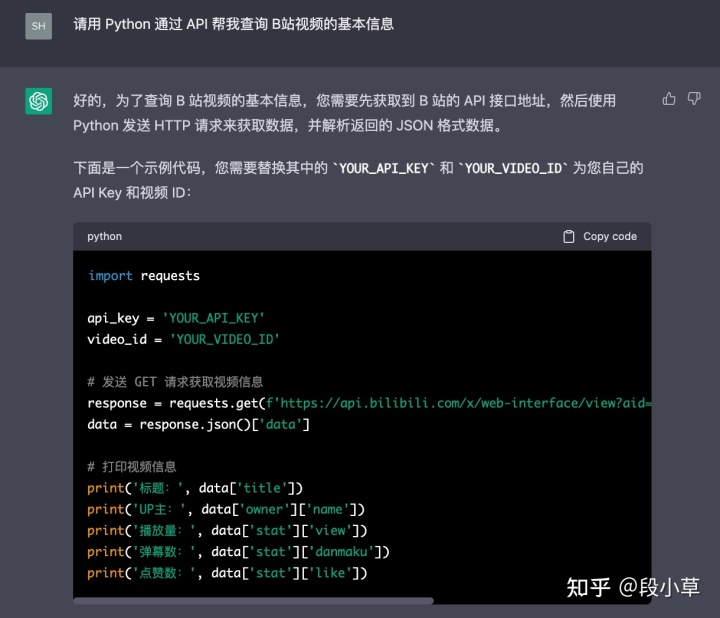
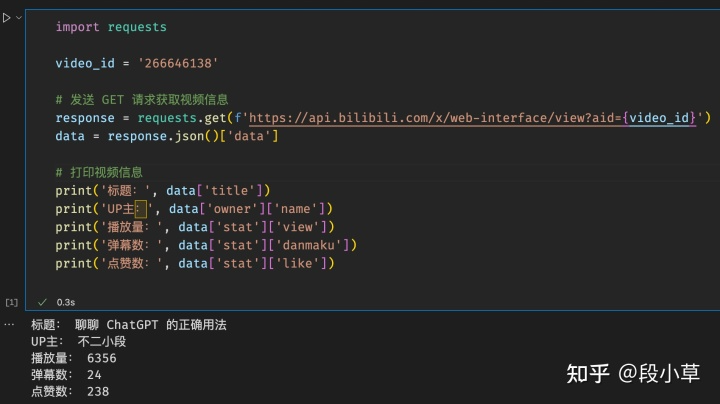
总之,这部分比较简单,直接扔代码就好了:
import requestsdef bili_info(bvid):params = (('bvid', bvid),)response = requests.get('https://api.bilibili.com/x/web-interface/view', params=params)return response.json()['data']def bili_tags(bvid):params = (('bvid', bvid),)response = requests.get('https://api.bilibili.com/x/web-interface/view/detail/tag', params=params)data = response.json()['data']if data:tags = [x['tag_name'] for x in data]if len(tags) > 5:tags = tags[:5]else:tags = []return tags
获取视频分区
稍微有点麻烦的是分区,B 站的分区比较碎,视频信息里却只有分区 ID 没有分区名称,而且这个分区的 ID 也是小分区不是大分区…常用 B 站的应该能听明白,类似下图,我只需要「科技区」,而不需要「软件应用」。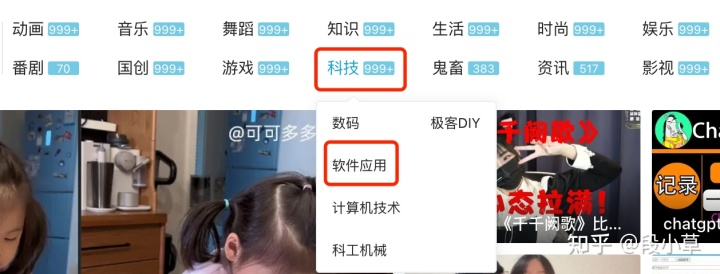
所以我用笨办法抓了一个分区字典,直接放在这里好了(可能不全,之后我有时间会补充修改):
sect = {13: {'name': '番剧', 'parent_tid': 13, 'parent_name': '番剧'},33: {'name': '连载动画', 'parent_tid': 13, 'parent_name': '番剧'},32: {'name': '完结动画', 'parent_tid': 13, 'parent_name': '番剧'},51: {'name': '资讯', 'parent_tid': 13, 'parent_name': '番剧'},152: {'name': '官方延伸', 'parent_tid': 13, 'parent_name': '番剧'},23: {'name': '电影', 'parent_tid': 23, 'parent_name': '电影'},167: {'name': '国创', 'parent_tid': 167, 'parent_name': '国创'},153: {'name': '国产动画', 'parent_tid': 167, 'parent_name': '国创'},168: {'name': '国产原创相关', 'parent_tid': 167, 'parent_name': '国创'},169: {'name': '布袋戏', 'parent_tid': 167, 'parent_name': '国创'},195: {'name': '动态漫·广播剧', 'parent_tid': 167, 'parent_name': '国创'},170: {'name': '资讯', 'parent_tid': 167, 'parent_name': '国创'},11: {'name': '电视剧', 'parent_tid': 11, 'parent_name': '电视剧'},177: {'name': '纪录片', 'parent_tid': 177, 'parent_name': '纪录片'},1: {'name': '动画', 'parent_tid': 1, 'parent_name': '动画'},24: {'name': 'MAD·AMV', 'parent_tid': 1, 'parent_name': '动画'},25: {'name': 'MMD·3D', 'parent_tid': 1, 'parent_name': '动画'},47: {'name': '短片·手书·配音', 'parent_tid': 1, 'parent_name': '动画'},210: {'name': '手办·模玩', 'parent_tid': 1, 'parent_name': '动画'},86: {'name': '特摄', 'parent_tid': 1, 'parent_name': '动画'},27: {'name': '综合', 'parent_tid': 1, 'parent_name': '动画'},4: {'name': '游戏', 'parent_tid': 4, 'parent_name': '游戏'},17: {'name': '单机游戏', 'parent_tid': 17, 'parent_name': '单机游戏'},171: {'name': '电子竞技', 'parent_tid': 4, 'parent_name': '游戏'},172: {'name': '手机游戏', 'parent_tid': 4, 'parent_name': '游戏'},65: {'name': '网络游戏', 'parent_tid': 4, 'parent_name': '游戏'},173: {'name': '桌游棋牌', 'parent_tid': 4, 'parent_name': '游戏'},121: {'name': 'GMV', 'parent_tid': 4, 'parent_name': '游戏'},136: {'name': '音游', 'parent_tid': 4, 'parent_name': '游戏'},19: {'name': 'Mugen', 'parent_tid': 4, 'parent_name': '游戏'},119: {'name': '鬼畜', 'parent_tid': 119, 'parent_name': '鬼畜'},22: {'name': '鬼畜调教', 'parent_tid': 119, 'parent_name': '鬼畜'},26: {'name': '音MAD', 'parent_tid': 119, 'parent_name': '鬼畜'},126: {'name': '人力VOCALOID', 'parent_tid': 119, 'parent_name': '鬼畜'},216: {'name': '鬼畜剧场', 'parent_tid': 119, 'parent_name': '鬼畜'},127: {'name': '教程演示', 'parent_tid': 119, 'parent_name': '鬼畜'},3: {'name': '音乐', 'parent_tid': 3, 'parent_name': '音乐'},28: {'name': '原创音乐', 'parent_tid': 3, 'parent_name': '音乐'},31: {'name': '翻唱', 'parent_tid': 3, 'parent_name': '音乐'},30: {'name': 'VOCALOID·UTAU', 'parent_tid': 3, 'parent_name': '音乐'},194: {'name': '电音', 'parent_tid': 3, 'parent_name': '音乐'},59: {'name': '演奏', 'parent_tid': 3, 'parent_name': '音乐'},193: {'name': 'MV', 'parent_tid': 3, 'parent_name': '音乐'},29: {'name': '音乐现场', 'parent_tid': 3, 'parent_name': '音乐'},130: {'name': '音乐综合', 'parent_tid': 3, 'parent_name': '音乐'},129: {'name': '舞蹈', 'parent_tid': 129, 'parent_name': '舞蹈'},20: {'name': '宅舞', 'parent_tid': 129, 'parent_name': '舞蹈'},198: {'name': '街舞', 'parent_tid': 129, 'parent_name': '舞蹈'},199: {'name': '明星舞蹈', 'parent_tid': 129, 'parent_name': '舞蹈'},200: {'name': '中国舞', 'parent_tid': 129, 'parent_name': '舞蹈'},154: {'name': '舞蹈综合', 'parent_tid': 129, 'parent_name': '舞蹈'},156: {'name': '舞蹈教程', 'parent_tid': 129, 'parent_name': '舞蹈'},181: {'name': '影视', 'parent_tid': 181, 'parent_name': '影视'},182: {'name': '影视杂谈', 'parent_tid': 181, 'parent_name': '影视'},183: {'name': '影视剪辑', 'parent_tid': 181, 'parent_name': '影视'},85: {'name': '短片', 'parent_tid': 181, 'parent_name': '影视'},184: {'name': '预告·资讯', 'parent_tid': 181, 'parent_name': '影视'},5: {'name': '娱乐', 'parent_tid': 5, 'parent_name': '娱乐'},71: {'name': '综艺', 'parent_tid': 5, 'parent_name': '娱乐'},241: {'name': '娱乐杂谈', 'parent_tid': 5, 'parent_name': '娱乐'},242: {'name': '粉丝创作', 'parent_tid': 5, 'parent_name': '娱乐'},137: {'name': '明星综合', 'parent_tid': 5, 'parent_name': '娱乐'},36: {'name': '知识', 'parent_tid': 36, 'parent_name': '知识'},201: {'name': '科学科普', 'parent_tid': 36, 'parent_name': '知识'},124: {'name': '社科·法律·心理', 'parent_tid': 36, 'parent_name': '知识'},228: {'name': '人文历史', 'parent_tid': 36, 'parent_name': '知识'},207: {'name': '财经商业', 'parent_tid': 36, 'parent_name': '知识'},208: {'name': '校园学习', 'parent_tid': 36, 'parent_name': '知识'},209: {'name': '职业职场', 'parent_tid': 36, 'parent_name': '知识'},229: {'name': '设计·创意', 'parent_tid': 36, 'parent_name': '知识'},122: {'name': '野生技能协会', 'parent_tid': 36, 'parent_name': '知识'},188: {'name': '科技', 'parent_tid': 188, 'parent_name': '科技'},95: {'name': '数码', 'parent_tid': 188, 'parent_name': '科技'},230: {'name': '软件应用', 'parent_tid': 188, 'parent_name': '科技'},231: {'name': '计算机技术', 'parent_tid': 188, 'parent_name': '科技'},232: {'name': '工业·工程·机械', 'parent_tid': 188, 'parent_name': '科技'},202: {'name': '资讯', 'parent_tid': 202, 'parent_name': '资讯'},203: {'name': '热点', 'parent_tid': 202, 'parent_name': '资讯'},204: {'name': '环球', 'parent_tid': 202, 'parent_name': '资讯'},205: {'name': '社会', 'parent_tid': 202, 'parent_name': '资讯'},206: {'name': '综合', 'parent_tid': 202, 'parent_name': '资讯'},211: {'name': '美食', 'parent_tid': 211, 'parent_name': '美食'},76: {'name': '美食制作', 'parent_tid': 211, 'parent_name': '美食'},212: {'name': '美食侦探', 'parent_tid': 211, 'parent_name': '美食'},213: {'name': '美食测评', 'parent_tid': 211, 'parent_name': '美食'},214: {'name': '田园美食', 'parent_tid': 211, 'parent_name': '美食'},215: {'name': '美食记录', 'parent_tid': 211, 'parent_name': '美食'},160: {'name': '生活', 'parent_tid': 160, 'parent_name': '生活'},138: {'name': '搞笑', 'parent_tid': 138, 'parent_name': '搞笑'},163: {'name': '家居房产', 'parent_tid': 160, 'parent_name': '生活'},161: {'name': '手工', 'parent_tid': 160, 'parent_name': '生活'},162: {'name': '绘画', 'parent_tid': 160, 'parent_name': '生活'},21: {'name': '日常', 'parent_tid': 160, 'parent_name': '生活'},223: {'name': '汽车', 'parent_tid': 223, 'parent_name': '汽车'},176: {'name': '汽车生活', 'parent_tid': 223, 'parent_name': '汽车'},224: {'name': '汽车文化', 'parent_tid': 223, 'parent_name': '汽车'},225: {'name': '汽车极客', 'parent_tid': 223, 'parent_name': '汽车'},240: {'name': '摩托车', 'parent_tid': 223, 'parent_name': '汽车'},226: {'name': '智能出行', 'parent_tid': 223, 'parent_name': '汽车'},227: {'name': '购车攻略', 'parent_tid': 223, 'parent_name': '汽车'},155: {'name': '时尚', 'parent_tid': 155, 'parent_name': '时尚'},157: {'name': '美妆护肤', 'parent_tid': 155, 'parent_name': '时尚'},158: {'name': '穿搭', 'parent_tid': 155, 'parent_name': '时尚'},159: {'name': '时尚潮流', 'parent_tid': 155, 'parent_name': '时尚'},234: {'name': '运动', 'parent_tid': 234, 'parent_name': '运动'},235: {'name': '篮球·足球', 'parent_tid': 234, 'parent_name': '运动'},164: {'name': '健身', 'parent_tid': 234, 'parent_name': '运动'},236: {'name': '竞技体育', 'parent_tid': 234, 'parent_name': '运动'},237: {'name': '运动文化', 'parent_tid': 234, 'parent_name': '运动'},238: {'name': '运动综合', 'parent_tid': 234, 'parent_name': '运动'},217: {'name': '动物圈', 'parent_tid': 217, 'parent_name': '动物圈'},218: {'name': '喵星人', 'parent_tid': 217, 'parent_name': '动物圈'},219: {'name': '汪星人', 'parent_tid': 217, 'parent_name': '动物圈'},220: {'name': '大熊猫', 'parent_tid': 217, 'parent_name': '动物圈'},221: {'name': '野生动物', 'parent_tid': 217, 'parent_name': '动物圈'},222: {'name': '爬宠', 'parent_tid': 217, 'parent_name': '动物圈'},75: {'name': '动物综合', 'parent_tid': 217, 'parent_name': '动物圈'}}
这样我们基础数据就准备好了。还需要解析一下 JSON,为了代码结构我放在后面的部分了。
抓取 B 站 CC 字幕并处理文本
抓取字幕 JSON 文件
接下来抓取 B 站的 CC 字幕。B 站早在 2018 年就支持了 CC 字幕。现在,大部分视频下都有 B 站后台自动生成的 CC 字幕(UP 主也可以自己在这个地方上传,不过这样做的人不多)。我们就可以在播放器右下角找到自动生成的 CC 字幕。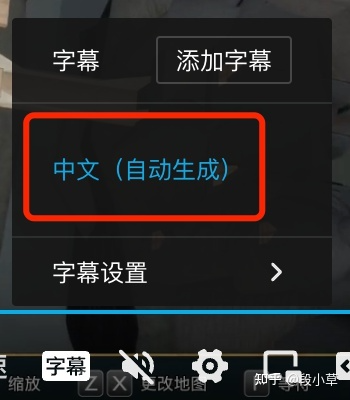
现在,我们就来白嫖 B 站为我们自动生成的这些语音转文字内容。
第一步:在player接口中找到subtitle_url 。
第二步:根据subtitle_url获取字幕数据并解析。都不难,就直接贴代码了。注意这里的字幕数据是 JSON,如果后续有更详细的打轴需求,还要转换成 SRT 比较好。由于后面还要进行进一步处理,我就先返回了列表。
(而且,这里暂时先没有处理多分 P 问题,如果你有需求并且到目前为止的代码都能看懂的话,可以自己研究一下,并不难的,无非就是把返回的视频列表中的 cid 逐个进行处理。)
评论区有人说获取不到字幕,我测了一下,如果请求次数多了,B 站就会屏蔽这一部分返回。
解决办法是添加headers 和cookies 。由于cookies是有时效的,你可以尝试先添加headers看是否能解决问题,如果还不行就麻烦一点全加上。
def bili_player_list(bvid):url = 'https://api.bilibili.com/x/player/pagelist?bvid='+bvidresponse = requests.get(url)cid_list = [x['cid'] for x in response.json()['data']]return cid_listdef bili_subtitle_list(bvid, cid):url = f'https://api.bilibili.com/x/player/v2?bvid={bvid}&cid={cid}'response = requests.get(url)subtitles = response.json()['data']['subtitle']['subtitles']if subtitles:return ['https:' + x['subtitle_url'] for x in subtitles]else:return []def bili_subtitle(bvid, cid):headers = {'authority': 'api.bilibili.com','accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','origin': 'https://www.bilibili.com','referer': 'https://www.bilibili.com/','user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63',}# add cookies if necessarysubtitles = bili_subtitle_list(bvid, cid)if subtitles:response = requests.get(subtitles[0], headers=headers)if response.status_code == 200:body = response.json()['body']return bodyreturn []# subtitle_text = bili_subtitle(bvid, bili_player_list(bvid)[0])
这一部分稍微有点绕,大家把几个接口返回的 JSON 格式挨着看一下就明白了。
预处理字幕文本
OpenAI API 对于输入输出长度有限制(后面会介绍),总之,我们需要先把字幕文本进行预处理到合适的长度。
处理的思路有两种:
一是直接对文本进行(有损的)压缩处理,实际测试下来效果也是可用的。
二是分段交给 GPT-3.5 进行 summarize 之后,再合并到一起再次进行 summarize。这样做的好处是信息损耗比较少,弊端自然就是调用 API 的次数比较多…花钱比较多…
下面分别把两种预处理的做法贴一下,大家自己选择吧。
第一种是有损压缩,思路参考了开源项目 BilibiliSummary [4],ChatGPT 帮我把 JS 转写成了 Python 代码:
limit = 7000def truncateTranscript(str):bytes = len(str.encode('utf-8'))if bytes > limit:ratio = limit / bytesnewStr = str[:int(len(str)*ratio)]return newStrreturn strdef textToBinaryString(str):escstr = str.encode('utf-8').decode('unicode_escape').encode('latin1').decode('utf-8')binstr = ""for c in escstr:binstr += f"{ord(c):08b}"return binstrdef getChunckedTranscripts(textData, textDataOriginal):result = ""text = " ".join([x["text"] for x in sorted(textData, key=lambda x: x["index"])])bytes = len(textToBinaryString(text))if bytes > limit:evenTextData = [t for i, t in enumerate(textData) if i % 2 == 0]result = getChunckedTranscripts(evenTextData, textDataOriginal)else:if len(textDataOriginal) != len(textData):for obj in textDataOriginal:if any(t["text"] == obj["text"] for t in textData):continuetextData.append(obj)newText = " ".join([x["text"] for x in sorted(textData, key=lambda x: x["index"])])newBytes = len(textToBinaryString(newText))if newBytes < limit:nextText = textDataOriginal[[t["text"] for t in textDataOriginal].index(obj["text"]) + 1]nextTextBytes = len(textToBinaryString(nextText["text"]))if newBytes + nextTextBytes > limit:overRate = ((newBytes + nextTextBytes) - limit) / nextTextByteschunkedText = nextText["text"][:int(len(nextText["text"])*overRate)]textData.append({"text": chunkedText, "index": nextText["index"]})result = " ".join([x["text"] for x in sorted(textData, key=lambda x: x["index"])])else:result = newTextelse:result = textoriginalText = " ".join([x["text"] for x in sorted(textDataOriginal, key=lambda x: x["index"])])return originalText if result == "" else result
第二种是分段进行 summarize,可以直接保留全部结果,也可以把结果整合后再 summarize 一次。分段的时候可以简单粗暴地直接把全文切分,如果想控制得特别精细,也可以借助官方工具 tiktoken[5] 计算 token 数量。(比如你要对外提供付费的服务,就要计算好你的 token,积少成多,能省下很多费用)。
实测新模型对中文有优化,token 比之前少了一半![6]
所以我这里就做简单些,直接把文稿切分成 3500 字左右,剩余的 token 留给返回结果。
def segTranscipt(transcript):transcript = [{"text": item["content"], "index": index, "timestamp": item["from"]} for index, item in enumerate(transcript)]text = " ".join([x["text"] for x in sorted(transcript, key=lambda x: x["index"])])length = len(text)seg_length = 3500n = length // seg_length + 1division = len(transcript) // nnew_l = [transcript[i * division: (i + 1) * division] for i in range(n)]segedTranscipt = [" ".join([x["text"] for x in sorted(j, key=lambda x: x["index"])]) for j in new_l]return segedTranscipt
使用 OpenAI API 进行文本摘要
OK,下面来到最重要的摘要部分。就是为了这口醋,才包的这碗饺子。
ChatGPT 不用介绍了,太火了。我们这次用刚刚推出的 ChatGPT gpt-3.5-turbo模型来做摘要。
注册
(略,免费的教程有很多,但如果真的有人现在都还没有账号又的确有使用需求又懒得找教程又不信任淘宝,可以走知乎的付费问答找我,愿者上钩。)
生成 API key
https://platform.openai.com/account/api-keysplatform.openai.com/account/api-keys
点击 Create new secret key,保存下来自己的密钥(注意可以生成多个,也可以删除已泄漏的密钥)。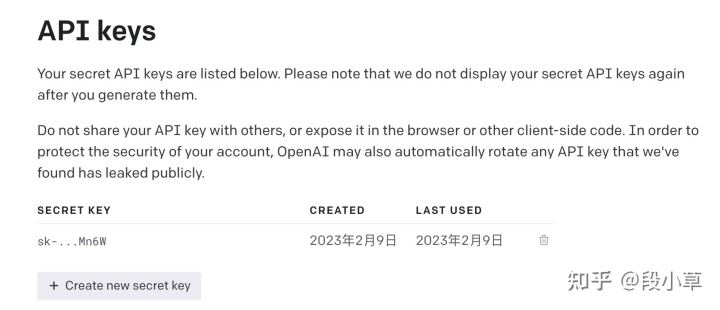
选择模型
这篇文章还没写完的时候,OpenAI 刚刚上线了 ChatGPT 版本的 API:gpt-3.5-turbo。下面是同一个 prompt 的不同输出比较: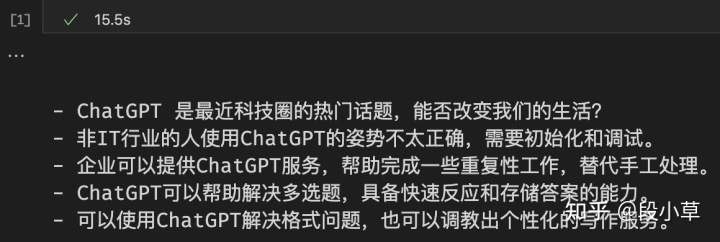
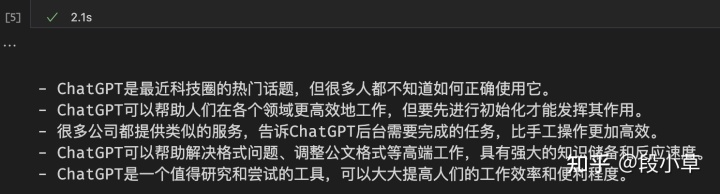
而且…gpt-3.5-turbo还便宜了 10 倍…选哪个模型不用说了吧…又快又好!
其他模型的选择详见 OpenAI API 文档[7]。
Python 调用 API
OpenAI API 有两个需要注意的问题,一是输入的内容太长,导致出错;二是返回的内容太长,导致不全。这里因为返回的是摘要内容,一般返回的内容并不会太长。所以我们主要解决输入内容太长的问题。
我们上面处理字幕的时候已经处理过了。(再次注意,OpenAI API 的输入输出是共用 token 限制长度的)
我这里直接展示gpt-3.5-turbo的调用方法,其他的用法还是请大家 RTFM[8]。
Python 的调用方法有两种,一是使用官方的 openai 包,二是自己模拟发送网络请求,效果是一致的。
1、调用官方 openai 包
首先,pip install openai 如果之前安装过,一定记得更新:pip install —upgrade openai
然后就可以开始使用了:
import openaiopenai.api_key = "sk-your key"def chat(prompt, text):completions = openai.ChatCompletion.create(model = 'gpt-3.5-turbo',messages = [{"role": "system", "content": prompt},{"role": "user", "content": text},],)ans = completions.choices[0].message.contentreturn ans
2、自己发送网络请求
import requestsdef chat(prompt, text):API_KEY = 'sk-your key'headers = {'Content-Type': 'application/json','Authorization': f'Bearer {API_KEY}',}json_data = {'model': 'gpt-3.5-turbo','messages': [{"role": "system", "content": prompt},{"role": "user", "content": text},],}response = requests.post('https://api.openai.com/v1/chat/completions', headers=headers, json=json_data)return response.json()['choices'][0]['message']['content']
到此为止我们的所有内容就都准备好了,最后只需要将它们自动存入 Notion 就可以了。
Notion 及 Notion API
Notion [9]是最近几年比较流行的一款 all in one 笔记应用,国内已经出现很多竞品了。我一度不太喜欢 Notion,因为它过于丰富了,各种模板趋于花哨。后来想了想那不是 Notion 的问题,是用户的问题,可能只是我的某种心理作祟,就又用回来了。不过毕竟是在线软件,重要笔记还是尽量离线备份。
除了基础的笔记功能外,Notion 面向所有用户免费提供了集成开发能力,可以通过API定制自己的服务。Notion 现在也推出了自己的 Notion AI[10],我试了一下效果也挺好的(用的应该是优化过的 gpt-3.5),不过没有提供接口调用,所以这次的文本处理还是用官方的 GPT-3.5 来做。
注册应用
Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.www.notion.so/my-integrations
在这个链接中 Create a new integration,填写相应内容即可。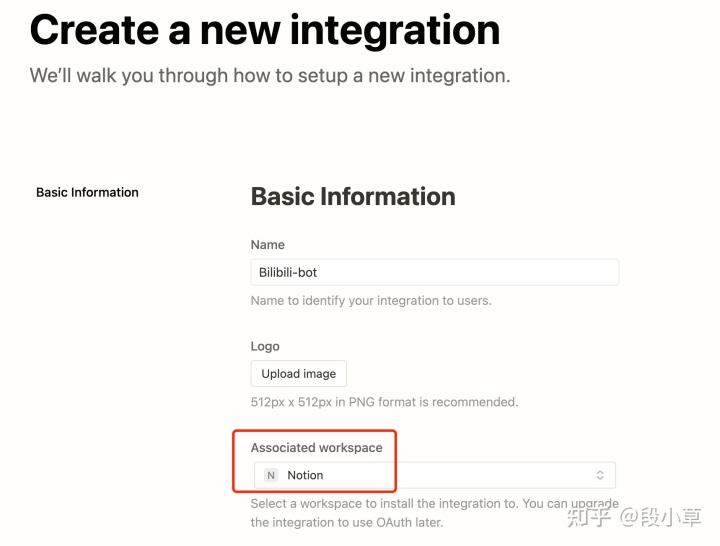
建立成功后保存下来密钥即可。
在 database 中添加应用
database/Gallery 是 Notion table 的一种展现形式,新建一个空白页面,添加 table,然后新建 database 即可。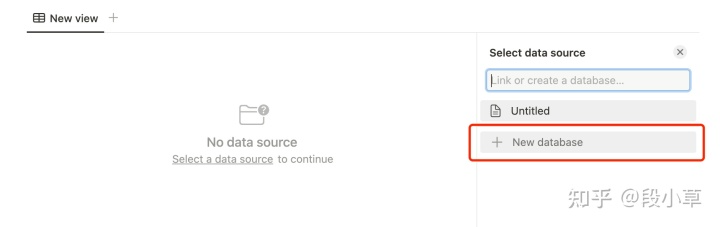
如果打算抓取封面图,并喜欢 Gallery 的展现形式的话,可以额外添加一个 view。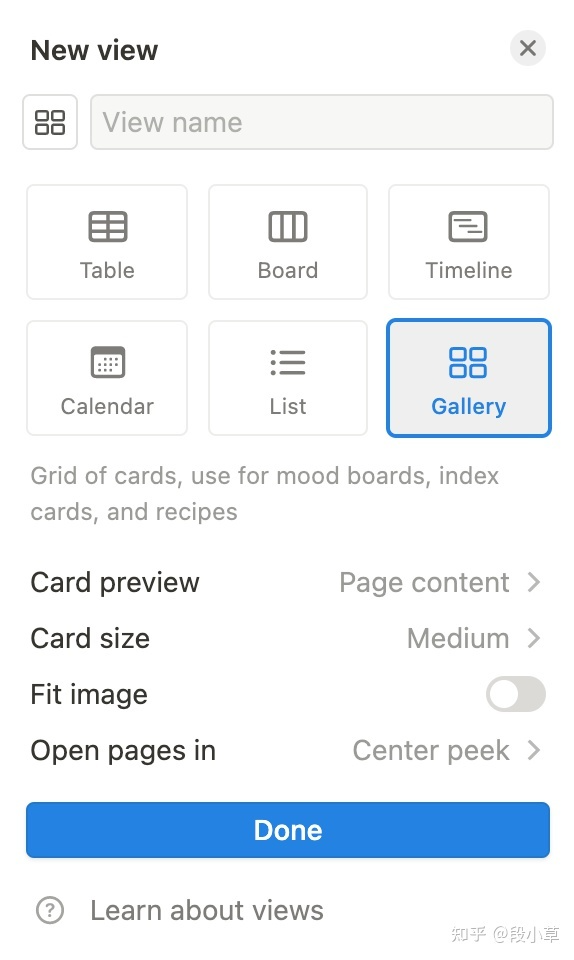
同时,我们需要确定好 database 的数据结构(类似于新建 SQL 表)。我是这样做的(这一步其实也可以用代码完成,不过似乎没什么必要吧…):
要注意这些字段的类型。重点区分「分区」和「tags」,前者是select,后者是multi-select 。封面要选择 file & media。
然后将刚才刚才新建的 integration 添加到这个页面。(Notion 的 API 权限比较严格,类似于你新建了一个应用,然后允许这个应用访问你的这个笔记页面)
添加的入口以前在右上角的 share,现在统一整合在了设置里的「add connections」,如果在这个地方找不到你刚才新建的 integration,看一下是不是选错 workspace 了。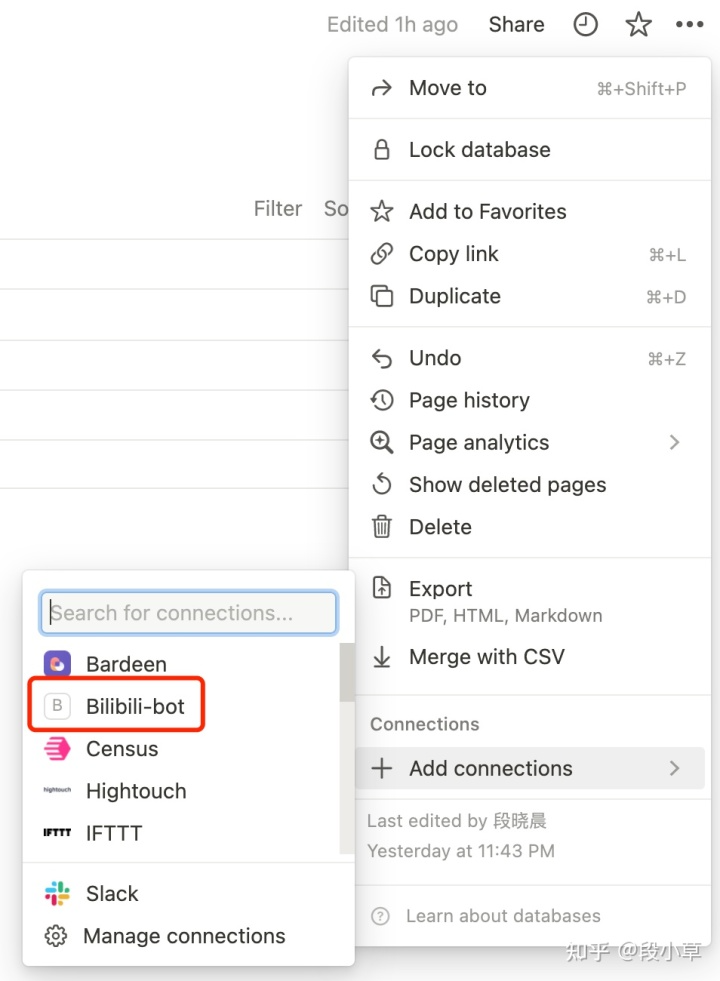
使用 API 提交基础数据和摘要后的文本
这一步要结合上一步 database 的数据结构,字段内容保持一致。
如果要系统了解Notion API,有两个比较好的途径,一是官方的文档[11],二是官方团队提供的Postman Collection[12]。我建议通读一下docs的部分(下面的内容会涉及到一些,但不如官方文档详细,不过官方文档其实也没多详细…),然后涉及到具体的 API 用法的直接去测试 Postman 里的示例。
具体到我们这次会用到的接口,其实只有一个,就是向页面 POST 内容。这一部分篇幅原因不再展开了,RTFM。
这里需要用到页面的 database_id,一定注意要进入到 table 页面,而不是 table 页所属的上级页面:
然后复制这个页面的地址,或者直接在表格右上角复制本 table 的链接: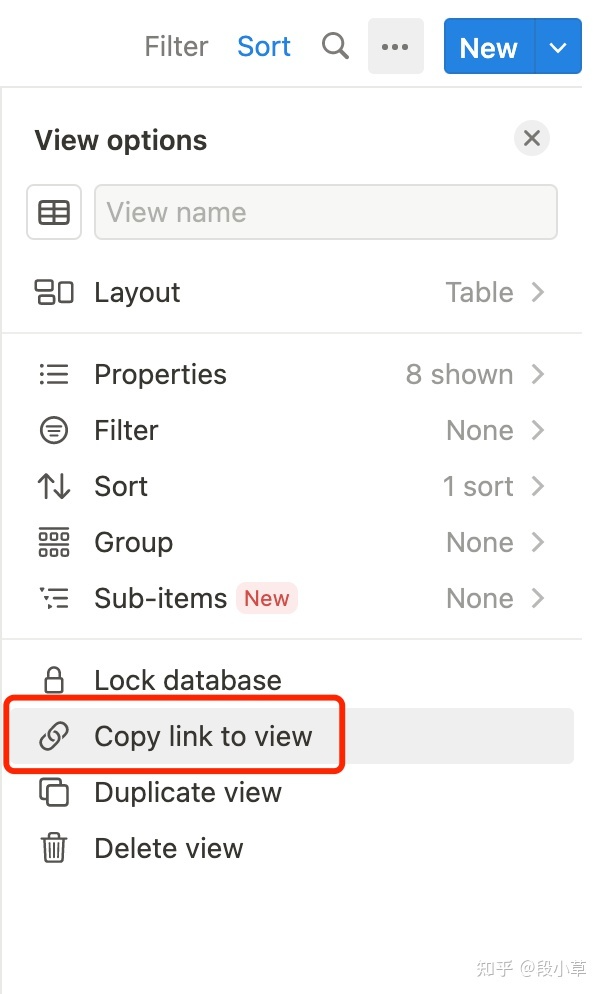
得到一个类似如下的链接:
https://www.notion.so/buerxd/a6bd8e45fa184fc4aa57a236be0ab7a9?v=f2d45efb35124b0a9791a7c3454ef47e
其中的 a6bd8e45fa184fc4aa57a236be0ab7a9 部分就是 database_id。
剩余的直接贴代码:
import timetoken = 'your secret key'database_id = 'your databse id'def insert2notion(token, database_id, bvid, summarized_text):headers = {'Notion-Version': '2022-06-28','Authorization': 'Bearer '+token,}info = bili_info(bvid)tags = bili_tags(bvid)multi_select = []pubdate = time.strftime("%Y-%m-%d", time.localtime(info['pubdate']))for each in tags:multi_select.append({'name': each})body= {"parent": {"type": "database_id","database_id": database_id},"properties": {"标题": { "title": [{"type": "text","text": {"content": info['title']}}]},"URL": { "url": 'https://www.bilibili.com/video/'+bvid},"UP主": { "rich_text": [{"type": "text","text": {"content": info['owner']['name']}}]},"分区": { "select": {"name": sect[info['tid']]['parent_name']}},'tags': {'type': 'multi_select', 'multi_select': multi_select},"发布时间": { "date": {"start": pubdate, "end": None }},"观看时间": { "date": {"start": time.strftime("%Y-%m-%d", time.localtime()), "end": None }},"封面": {'files': [{"type": "external", "name": "封面",'external': {'url': info['pic']}}]},},"children": [{"object": "block","type": "heading_2","heading_2": {"rich_text": [{"type": "text","text": {"content": "内容摘要:"}}]}},{"object": "block","type": "paragraph","paragraph": {"rich_text": [{"type": "text","text": {"content": summarized_text,"link": None,}}]}}]}notion_request = requests.post("https://api.notion.com/v1/pages", json = body, headers=headers)if(str(notion_request.status_code) == "200"):print("导入信息成功")return(notion_request.json()['url'])else:print("导入失败,请检查Body字段")print(notion_request.text)return('')
导入以后会在表中添加一行数据,并返回一个 URL,这个 URL 就是这行数据的单独页面。
最后,万事俱备,准备好所有需要用的函数后,我们最终把它们串起来,并稍加用法提示和调试即可:
def main():token = 'your-token'database_id = 'your-db-id'while True:blink = input('请输入B站视频链接:')bvid = blink.split('/')[4]print(f'开始处理视频信息:{bvid}')prompt = '我希望你是一名专业的视频内容编辑,请你尝试修正以下视频字幕文本中的拼写错误后,将其精华内容进行总结,然后以无序列表的方式返回,不要超过5条!确保所有的句子都足够精简,清晰完整。'transcript_text = bili_subtitle(bvid, bili_player_list(bvid)[0])if transcript_text:print('字幕获取成功')seged_text = segTranscipt(transcript_text)summarized_text = ''i = 1for entry in seged_text:try:response = chat(prompt, entry)print(f'完成第{str(i)}部分摘要')i += 1except:print('GPT接口摘要失败, 请检查网络连接')response = '摘要失败'summarized_text += '\n'+responseinsert2notion(token, database_id, bvid, summarized_text)else:print('字幕获取失败\n')if __name__ == '__main__':main()
完整代码(替换其中的 key 和 db_id 即可运行):
https://gist.github.com/loveQt/1714808c6ee8b732596ecb6e38c23ea7gist.github.com/loveQt/1714808c6ee8b732596ecb6e38c23ea7
遗留问题:
- B 站字幕的接口有概率失败,大部分视频其实都有 CC 字幕,如果获取失败就多 sleep 几秒;
- OpenAI API 似乎可能大概网络访问有障碍了?
- 虽然 prompt 要求的是无序列表,但经常会返回有序列表,甚至混着来…
不过都不是大问题,已经可用了。我后面也会继续实践这个工作流,看能否真正提高效率。
实际使用后的补充,大家可以自己再完善:
- 字幕文件本身识别错误比较多,可以在给 GPT 的 prompt 中加上「尝试修正文稿中的 typos」;
- 在运行的时候,外层套个 while True,方便不间断地录入下一个视频。这样平时只要开一个 terminal 在旁边,遇到视频直接扔链接就行了。
- 有能力的大佬也可以做成桌面或者浏览器插件…我自己反正是只会 Python 的 API 小子,也没时间再去学习其他完整的技术路线了。
- 这篇文章,思路比代码重要,代码比较糙,token 数量也是估算的不精确,如大规模使用还需优化。大家见谅。
根据评论区反馈的问题,回复一下:
- 获取不到字幕,就自己加上 headers 和 cookies;
- 的确有些视频没有字幕,应该是 UP 主在 B 站后台设置里关掉了(默认是打开的),这种情况如果还想做摘要,就只能下载视频+语音转文字了,我后面会再写一篇文章,加上这个工作流。
参考
- ^https://www.feishu.cn/product/minutes
- ^https://baike.baidu.com/item/CC%E5%AD%97%E5%B9%95/10513152
- ^https://gitee.com/KGDKL/BiliCC-Srt
- ^https://github.com/lxfater/BilibiliSummary/
- ^https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
- ^https://www.zhihu.com/question/587083296/answer/2917778995
- ^https://platform.openai.com/docs/models/overview
- ^https://platform.openai.com/docs/guides/chat
- ^https://www.notion.so/
- ^https://www.notion.so/product/ai
- ^https://developers.notion.com/
- ^https://www.postman.com/notionhq/workspace/notion-s-api-workspace/overview

若有收获,就点个赞吧
0 人点赞
