前言
ControlNet 的作用是通过添加额外控制条件,来引导 Stable Diffusion 按照创作者的创作思路生成图像,从而提升 AI 图像生成的可控性和精度。在使用 ControlNet 前,需要确保已经正确安装 Stable Diffusion 和 ControlNet 插件。
目前 ControlNet 已经更新到 1.1 版本,相较于 1.0 版本,ControlNet1.1 新增了更多的预处理器和模型,原有的模型也通过更好的数据训练获得了更优的性能。以下我做简要梳理,想要了解更多内容可以参考作者的文档:
GitHub - lllyasviel/ControlNet-v1-1-nightly: Nightly release of ControlNet 1.1
ControlNet 的使用方式非常灵活,既可以单模型应用,也可以多模型组合应用。清楚 ControlNet 的一些原理方法后,可以帮助我们更好的提升出图效果。
以下通过一些示例,简要介绍 ControlNet 的实际用法。
模型下载
lllyasviel/ControlNet-v1-1 at main
ControlNet 单模型应用
线稿上色
Canny 边缘检测
Canny 是比较常用的一种线稿提取方式,该模型能够很好的识别出图像内各对象的边缘轮廓。模型文件: control_v11p_sd15_canny.pth配置文件:control_v11p_sd15_canny.yaml
方法:通过 ControlNet 边缘检测模型或线稿模型提取线稿(可提取参考图片线稿,或者手绘线稿),再根据提示词和风格模型对图像进行着色和风格化。
应用模型:Canny、SoftEdge、Lineart。
用随机种子(”房间里的狗”)进行批量测试
使用说明(以下其它模型同理):
- 展开 ControlNet 面板,上传参考图,勾选 Enable 启用(如果显存小于等于 4G,勾选低显存模式)。
- 预处理器选择 Canny(注意:如果上传的是已经经过预处理的线稿图片,则预处理器选择 none,不进行预处理),模型选择对应的 control_v11p_sd15_canny 模型。
- 勾选 Allow Preview 允许预览,点击预处理器旁的 按钮生成预览。
其它参数说明:
- Control Weight:使用 ControlNet 生成图片的权重占比影响(多个 ControlNet 组合使用时,需要调整权重占比)。
- Starting Control Step:ControlNet 开始参与生图的步数。
- Ending Control Step:ControlNet 结束参与生图的步数。
- Preprocessor resolution:预处理器分辨率,默认 512,数值越高线条越精细,数值越低线条越粗糙。
- Canny 低阈值/高阈值:数值越低线条越复杂,数值越高线条越简单。
Canny 1.1中的改进
以前的cnet 1.0的训练数据集有几个问题,包括
(1)一小部分灰度人类图像重复了数千次,导致以前的模型有点可能生成灰度人类图像
(2)一些图像质量不高,非常模糊,或者有明显的JPEG伪影
(3)一小部分图像有错误的配对提示,这是我们数据处理脚本中的一个错误造成的。新模型修复了训练数据集的所有问题,在许多情况下应该更加合理。
因为Canny模型是最重要的(也许是最经常使用的)控制网之一,我们用基金在一台有8个Nvidia A100 80G的机器上训练它,批处理量为8×32=256,为期3天,花费72×30=2160美元(8个A100 80G,每小时30美元)。该模型是从Canny 1.0恢复的。
一些合理的数据增量被应用于训练,比如随机的左右翻转。
虽然很难评价一个控制网,但我们发现Canny 1.1比Canny 1.0更稳健一些,视觉质量也更高一些。
Soft Edge 软边缘检测
模型文件: control_v11p_sd15_softedge.pth
配置文件:control_v11p_sd15_softedge.yaml
训练数据: SoftEdge_PIDI, SoftEdge_PIDI_safe, SoftEdge_HED, SoftEdge_HED_safe。
可接受的预处理程序: SoftEdge_PIDI, SoftEdge_PIDI_safe, SoftEdge_HED, SoftEdge_HED_safe。
这个模型与以前的模型相比有很大的改进。所有用户应尽快更新。
ControlNet 1.1中的新内容:现在我们增加了一种新的软边类型,称为 “SoftEdge_safe”。这是因为HED或PIDI倾向于在软估计内隐藏原始图像的损坏的灰度版本,这种隐藏的模式会分散ControlNet的注意力,导致不良结果。解决方案是使用预处理将边缘图量化为几个层次,这样就可以完全去除隐藏的图案。
其表现可以大致概括为::
稳健性: SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
最大的结果质量: SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
考虑到这种权衡,我们建议默认使用SoftEdge_PIDI。在大多数情况下,它工作得非常好。
SoftEdge 可以理解为是 ControlNet1.0 中 HED 边缘检测的升级版。ControlNet1.1 版本中 4 个预处理器按结果质量排序:SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe,其中带 safe 的预处理器可以防止生成的图像带有不良内容。相较于 Canny,SoftEdge 边缘能够保留更多细节。
SoftEdge保留结构,再进行着色和风格化
用随机种子(”a handsome man”)进行批量测试
Lineart 精细线稿提取
模型文件: control_v11p_sd15_lineart.pth
配置文件:control_v11p_sd15_lineart.yaml
这个模型是在awacke1/image-to-Line-Drawings上训练的。该预处理器可以从图像中生成详细或粗略的线性图(Lineart和Lineart_Coarse)。该模型的训练有足够的数据增量,可以接收手动绘制的线性图。
Lineart 精细线稿提取是 ControlNet1.1 版本中新增的模型,相较于 Canny,Lineart 提取的线稿更加精细,细节更加丰富。
Lineart 的预处理器有三种模式:lineart_coarse(粗略模式),lineart_realistic(详细模式),lineart_standard(标准模式),处理效果有所不同,对比如下:
该模型的训练有足够的数据增量,可以接收手动绘制的线性图。


Anime Lineart 二次元线条
模型文件: control_v11p_sd15s2_lineart_anime.pth
配置文件:control_v11p_sd15s2_lineart_anime.yaml
这个模型可以把真实的动漫线图或提取的线图作为输入。
你需要一个文件 “anything-v3-full.safetensors “来运行这个演示。
这个模型不支持猜测模式。
用随机种子(”1个女孩,在教室里,裙子,制服,红头发,包,绿眼睛”)进行批量测试
用随机种子(”1个女孩,军刀,在晚上,剑,绿眼睛,金头发,长筒袜”)进行批次测试
Normal 法线图
模型文件: control_v11p_sd15_normalbae.pth
配置文件:control_v11p_sd15_normalbae.yaml
可接受的预处理程序: 法线BAE
这个模型可以接受来自渲染引擎的法线图,只要法线图遵循ScanNet的协议
也就是说,你的法线图的颜色应该看起来像这个图片的第二列
注意,这种方法比ControlNet 1.1中的normal-from-midas方法要合理得多,之前的方法将被放弃
用随机种子(”花做的人”)进行批量测试
随机种子(”房间”)进行批量测试
Normal 1.1中的改进:
Normal 1.0中的normal-from-midas方法既不合理也不符合物理学原理。这种方法在很多图像中都不能很好地工作。法线1.0模型不能解释由渲染引擎创建的真实法线图。
这个Normal 1.1要合理得多,因为预处理器被训练成用相对正确的协议(NYU-V2的可视化方法)来估计法线图。这意味着只要颜色正确(蓝色是前面,红色是左边,绿色是上面),Normal 1.1就能解释来自渲染引擎的真实法线图。
在我们的测试中,这个模型很稳健,可以达到与深度模型类似的性能。在以前的CNET 1.0中,Normal 1.0的使用频率不高。但这个Normal 2.0有很大的改进,有可能被更频繁地使用。
涂鸦成图
方法:通过 ControlNet 的 Scribble 模型提取涂鸦图(可提取参考图涂鸦,或者手绘涂鸦图),再根据提示词和风格模型对图像进行着色和风格化。
应用模型:Scribble
Scribble 涂鸦
模型文件: control_v11p_sd15_scribble.pth
配置文件:control_v11p_sd15_scribble.yaml
训练数据: 合成的涂鸦
可接受的预处理程序: 合成的涂鸦(Scribble_HED、Scribble_PIDI等)或手绘的涂鸦
我们修复了以前训练数据集中的几个问题。该模型从ControlNet 1.0恢复,用A100 80G的200个GPU小时训练。
Scribble 比 Canny、SoftEdge 和 Lineart 的自由发挥度要更高,也可以用于对手绘稿进行着色和风格处理。Scribble 的预处理器有三种模式:Scribble_hed,Scribble_pidinet,Scribble_Xdog,对比如下,可以看到 Scribble_Xdog 的处理细节更为丰富:
用随机种子(“man in library”)进行批量测试
Scribble 手动涂鸦示例(根据手绘草图,生成图像):
可以不用参考图,直接创建空白画布,手绘涂鸦成图。
建筑/室内设计
方法:通过 ControlNet 的 MLSD 模型提取建筑的线条结构和几何形状,构建出建筑线框(可提取参考图线条,或者手绘线条),再配合提示词和建筑/室内设计风格模型来生成图像。
应用模型:MLSD
MLSD
模型文件:control_v11p_sd15_mlsd.pth
配置文件:control_v11p_sd15_mlsd.yaml
修复了之前训练数据集中的几个问题。该模型从ControlNet 1.0恢复,用A100 80G的200个GPU小时训练。
测试:
MLSD 1.1中的改进
以前的cnet 1.0的训练数据集有几个问题,包括
(1)一小部分灰度人类图像重复了数千次,导致以前的模型有点可能生成灰度人类图像
(2)一些图像质量不高,非常模糊,或者有明显的JPEG伪影
(3)一小部分图像有错误的配对提示,这是我们数据处理脚本中的一个错误造成的。新的模型修复了训练数据集的所有问题,在许多情况下应该是更合理的。
我们扩大了训练数据集,增加了30万张图片,通过使用MLSD来寻找其中有超过16条直线的图片。
一些合理的数据增量被应用于训练,比如随机的左右翻转。
从MLSD 1.0开始恢复,用A100 80G的200个GPU小时继续训练。
颜色控制画面
方法:通过 ControlNet 的 Segmentation 语义分割模型,标注画面中的不同区块颜色和结构(不同颜色代表不同类型对象),从而控制画面的构图和内容。
应用模型:Seg
Segmentation
基于语义分割的稳定扩散控制。
模型文件:control_v11p_sd15_segg .pth
配置文件:control_v11p_sd15_segg .yaml
训练数据:COCO + ADE20K
现在模型可以接收两种类型的ADE20K或COCO注释。我们发现识别分割协议对于ControlNet编码器来说是微不足道的,训练多个分割协议的模型可以获得更好的性能。
提取参考图内容和结构,再进行着色和风格化
测试
如果还想在车前面加一个人,只需在 Seg 预处理图上对应人物色值,添加人物色块再生成图像即可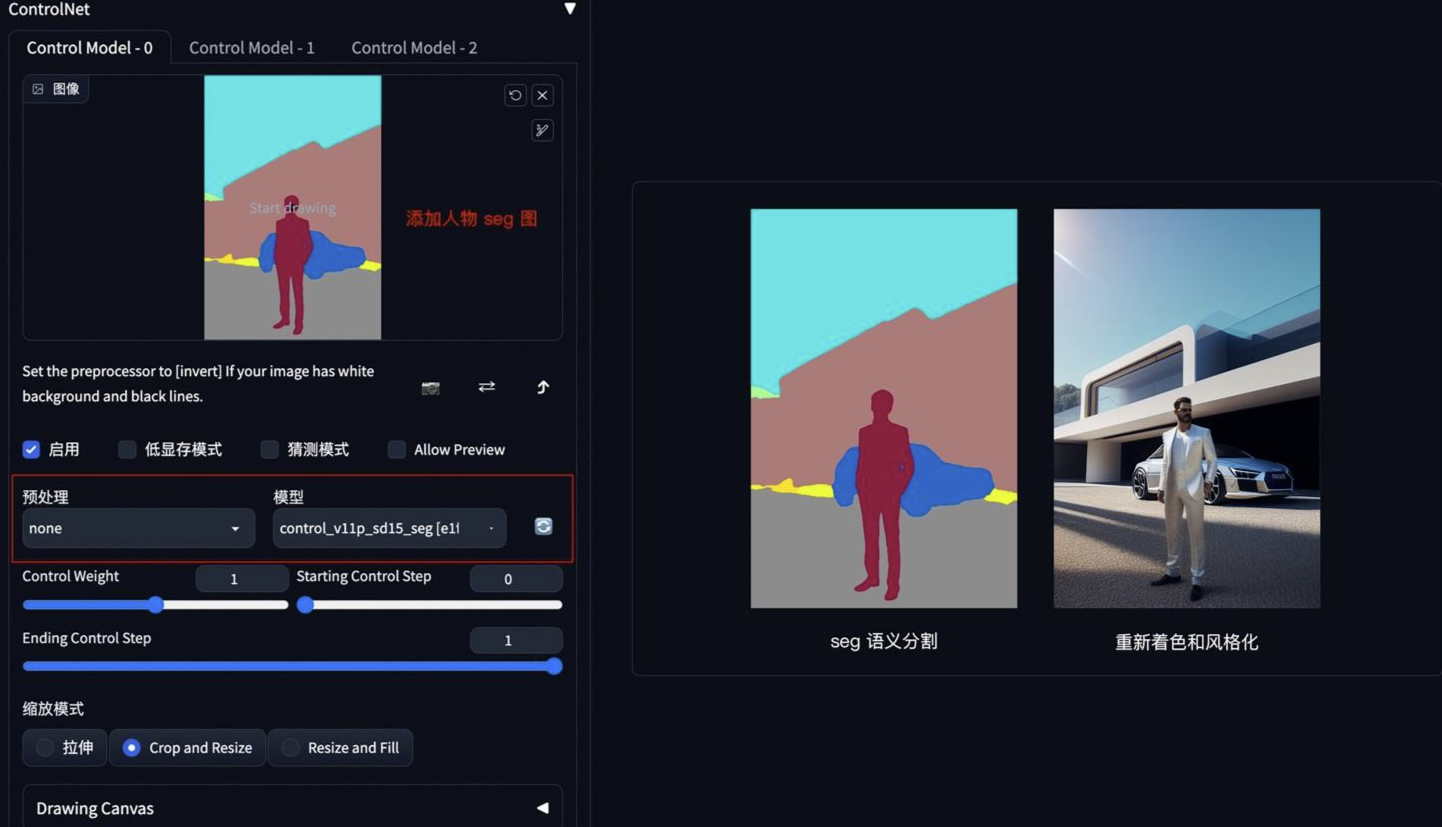


背景替换
方法:在 img2img 图生图模式中,通过 ControlNet 的 Depth_leres 模型中的 remove background 功能移除背景,再通过提示词更换想要的背景。
应用模型:Depth,预处理器 Depth_leres。
要点:如果想要比较完美的替换背景,可以在图生图的 Inpaint 模式中,对需要保留的图片内容添加蒙版,remove background 值可以设置在 70-80%。
Depth
用深度图控制绘画
模型文件: control_v11f1p_sd15_depth.pth
配置文件:control_v11f1p_sd15_depth.yaml
训练数据: Midas深度(分辨率256/384/512)+ Leres深度(分辨率256/384/512)+ Zoe深度(分辨率256/384/512)。在多个分辨率下的多个深度图生成器作为数据增量。
可接受的预处理程序: Depth_Midas, Depth_Leres, Depth_Zoe
这个模型可以在渲染引擎的真实深度图上工作
leres 测试:替换了衣服和远景,大致相似,小幅度替换
leres++
Midas 测试:替换了背景
zoe 测试:大幅度替换
示例:
将原图背景替换为办公室背景

Depth1.1的改进
以前的cnet 1.0的训练数据集有几个问题,包括
(1)一小部分灰度人类图像重复了数千次,导致以前的模型有点可能生成灰度人类图像
(2)一些图像质量不高,非常模糊,或者有明显的JPEG伪影
(3)一小部分图像有错误的配对提示,这是我们数据处理脚本中的一个错误造成的。新的模型修复了训练数据集的所有问题,在许多情况下应该是更合理的。
新的深度模型是一个相对无偏见的模型。它不是通过某种特定的深度估计方法来训练某种特定类型的深度。它没有对一个预处理器进行过度拟合。这意味着这个模型在不同的深度估计、不同的预处理器分辨率,甚至是由3D引擎创建的真实深度下会有更好的效果。
一些合理的数据增强被应用于训练,比如随机的左右翻转。
模型从深度1.0开始恢复,在所有深度1.0工作良好的情况下,它应该工作良好。如果不是,请用图像打开一个问题,我们会看一下你的情况。深度1.1在深度1.0的许多失败案例中工作得很好。
如果你使用Midas深度(webui插件中的 “深度”)和384的预处理器分辨率,深度1.0和1.1之间的差异应该是最小的。然而,如果你尝试其他预处理器分辨率或其他预处理器(如leres和zoe),深度1.1预计会比1.0好一点。
图片指令
方法:通过 ControlNet 的 Pix2Pix 模型(ip2p),可以对图片进行指令式变换。
应用模型:ip2p,预处理器选择 none。
要点:采用指令式提示词(make Y into X),如下图示例中的 make it snow,让非洲草原下雪。
Instruct Pix2Pix
模型文件: control_v11e_sd15_ip2p.pth
配置文件:control_v11e_sd15_ip2p.yaml这个模型 无预处理器
这个模型是用50%的指令提示和50%的描述提示来训练的。
例如,”一个可爱的男孩 “是一个描述提示,而 “让这个男孩变得可爱 “是一个指令提示。
因为这是一个控制网,你不需要为原来的关键词调整而烦恼,而且,这个模型可以适用于任何基础模型。
另外,像 “把它变成X “这样的指令似乎比 “把Y变成X “效果更好。
示例:(让非洲草原下雪)
指令make it winter
指令make it winter
我们把这个模型标记为 “实验性”,因为它有时需要樱桃采摘。
指令:make he iron man
风格迁移
方法:通过 ControlNet 的 Shuffle 模型提取出参考图的风格,再配合提示词将风格迁移到生成图上。
应用模型:Shuffle
Shuffle
模型文件: control_v11e_sd15_shuffle.pth
配置文件:control_v11e_sd15_shuffle.yaml
该模型被训练来重组图像。
我们用一个随机流来洗刷图像,并控制稳定扩散来重新组合图像。
用随机种子12345(”hong kong”)进行批量测试:
根据魔兽道具风格,重新生成一个宝箱道具
在右边的6幅图像中,左上角的是 “洗牌 “的图像。其他的都是输出。
事实上,由于该控制网被训练成可以重新组合图像,我们甚至不需要对输入进行洗牌—有时我们可以直接使用原始图像作为输入。
这样一来,这个控制网可以在提示或其他控制网的引导下改变图像风格。
请注意,这种方法与CLIP视觉或其他一些模型没有关系。
这是一个纯粹的控制网。iron man
spider man
色彩继承
方法:通过 ControlNet 的 t2iaColor 模型提取出参考图的色彩分布情况,再配合提示词和风格模型将色彩应用到生成图上。
应用模型:Color
Color

角色三视图
方法:通过 ControlNet 的 Openpose 模型精准识别出人物姿态,再配合提示词和风格模型生成同样姿态的图片。
应用模型:OpenPose。
在 ControlNet1.1 版本中,提供了多种姿态检测方式,包含:openpose 身体、openpose_face 身体+脸、openpose_faceonly 只有脸、openpose_full 身体+手+脸、openpose_hand 手,可以根据实际需要灵活应用。
OpenPose 姿势检测
模型文件: control_v11p_sd15_openpose.pth
配置文件:control_v11p_sd15_openpose.yaml
该模型经过训练,可以接受以下组合:
- Openpose身体
- Openpose的手
- 开放式脸部
- Openpose身体+Openpose手
- 开放式身体 + 开放式脸部
- 开放式的手 + 开放式的脸
- 开放式身体 + 开放式手部 + 开放式脸部
然而,提供所有这些组合是太复杂了。我们建议只为用户提供两种选择:
“Openpose” = Openpose body
“Openpose Full” = Openpose body + Openpose hand + Openpose face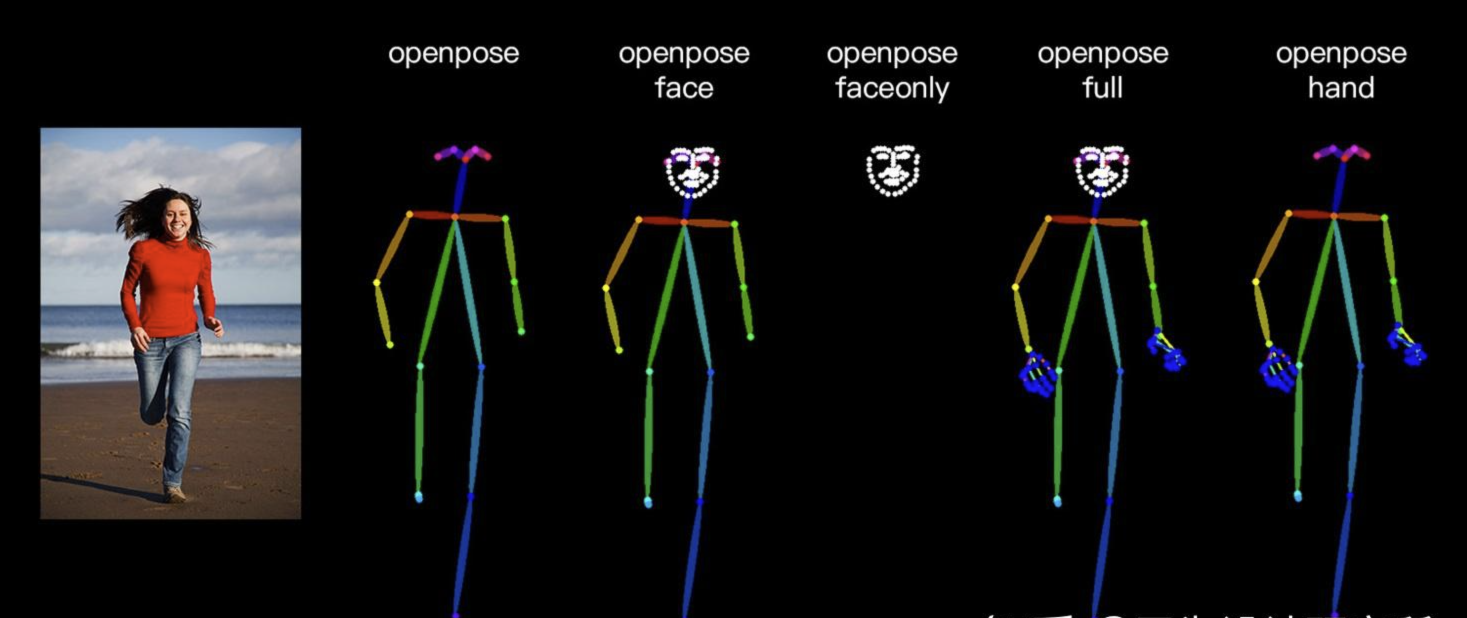
OpenPose 角色三视图示例:
要点:上传 openpose 三视图,加载 charturner 风格模型( https://civitai.com/?query=charturner )
添加提示词保持背景干净 (simple background, white background:1.3), multiple views
穿西装的人

Openpose 1.1中的改进:
这个模型的改进主要是基于我们对OpenPose的改进实现。我们仔细审查了pytorch OpenPose和CMU的c++ openpose之间的差异。现在的处理器应该更准确,特别是对手。处理器的改进导致了Openpose 1.1的改进。
更多的输入被支持(手和脸)。
以前的cnet 1.0的训练数据集有几个问题,包括(1)一小部分灰度人类图像重复了数千次(!),导致以前的模型有点可能生成灰度人类图像;(2)一些图像质量低,非常模糊,或者有明显的JPEG伪影;(3)一小部分图像有错误的配对提示,这是我们数据处理脚本中的一个错误。新模型修复了训练数据集的所有问题,在许多情况下应该更加合理。
图片光源控制
方法:如果想对生成的图片进行打光,可以在 img2img 模式下,把光源图片上传到图生图区域,ControlNet 中放置需要打光的原图,ControlNet 模型选择 Depth。
应用模型:Depth
Depth
要点:图生图中的所有参数和提示词信息需要与原图生成时的参数一样,具体原图参数可以在 PNG Info 面板中查看并复制。
示例:
其他
Inpaint 局部替换
模型文件: control_v11p_sd15_inpaint.pth
配置文件:control_v11p_sd15_inpaint.yaml
一些注意事项:
这个intpainting ControlNet是用50%的随机掩码和50%的随机光流闭塞掩码训练的。这意味着该模型不仅可以支持intpainting的应用,还可以在视频光流扭曲上工作。也许我们会在未来提供一些例子(取决于我们的工作负载)。
这个gradio演示并不包括后期处理。理想情况下,你需要在每次扩散迭代中对潜像进行后处理,并在vae解码后对图像进行后处理,这样,未被掩盖的区域就会保持不变。然而,这实现起来很复杂,也许一个更好的主意是在a1111中进行处理。在这个gradio的例子中,输出只是扩散的原始输出,而你图像中的未遮盖区域可能会因为vae或扩散过程而发生变化。
ControlNet的inpaint不改变unmasked区域是在a1111中实现的。它支持任意的基础模型/LoRAa,并能与任意数量的其他ControlNets一起工作。
用随机种子(”一个英俊的男人”)进行批量测试
Tile 小图放大
模型文件: control_v11f1e_sd15_tile.pth
配置文件:control_v11f1e_sd15_tile.yaml
这个模型可以用很多方式来使用。总的来说,该模型有两种行为:
忽略图像中的细节,生成新的细节。
如果本地瓦片语义和提示不匹配,则忽略全局提示,用本地环境引导扩散。
因为该模型可以生成新的细节并忽略现有的图像细节,所以我们可以用这个模型来去除不好的细节并增加精致的细节。例如,去除由图像大小调整引起的模糊。
下面是一个8倍超分辨率的例子。这是一张64x64的狗图像。
用随机种子(”草原上的狗”)进行的批量测试:
请注意,这个模型不是一个超级分辨率模型。它忽略了图像中的细节并生成新的细节。这意味着你可以用它来修复图像中的不良细节。
例如,下面是一张被Real-ESRGAN破坏的狗图像。这是一个典型的例子,当源环境太小的时候,超级分辨率模型有时不能提高图像的比例。

如果你的图像已经有很好的细节,你仍然可以使用这个模型来替换图像的细节。请注意,Stable Diffusion’s I2I可以达到类似的效果,但这个模型使你更容易保持整体结构,即使去噪强度为1.0,也只能改变细节。
用随机种子(”银色盔甲”)进行批量测试
越来越多的人开始考虑用不同的方法在瓦片上进行扩散,这样图像就可以非常大(在4k或8k)。
问题是,在SD中,你的提示语总是会影响到每一块瓷砖。
例如,如果你的提示是 “一个美丽的女孩”,而你把一张图片分成4×4=16个块,并在每个块上做扩散,那么你将得到16个 “美丽的女孩”,而不是 “一个美丽的女孩”。这是一个众所周知的问题。
现在人们的解决方案是使用一些无意义的提示,如 “清晰,清晰,超级清晰 “来扩散块。但你可以预料到,如果去噪强度高,结果会很糟糕。而且由于提示不好,内容也相当随机。
ControlNet Tile可以解决这个问题。对于一个给定的瓦片,它能识别瓦片内的内容,并增加该识别语义的影响,如果内容不匹配,它也会减少全局提示的影响。
用随机种子(”一个英俊的男人”)进行批量测试
你可以看到,提示是 “一个英俊的男人”,但模型并没有在树叶上画出 “一个英俊的男人”。
相反,它认识到树叶的绘画是相应的。
通过这种方式,ControlNet能够改变任何稳定扩散模型的行为,在瓷砖上进行扩散。
ControlNet 多模型组合应用
ControlNet 还支持多个模型的组合使用,从而对图像进行多条件控制。ControlNet 的多模型控制可以在设置面板中的 ControlNet 模块中开启
人物和背景分别控制
方法:设置 2 个 ControlNet,第一个 ControlNet 通过 OpenPose 控制人物姿态,第二个 ControlNet 通过 Seg 或 Depth 控制背景构成。调整 ControlNet 权重,如 OpenPose 权重高于 Depth 权重,以确保人物姿态被正确识别,再通过提示词和风格模型进行内容和风格控制。
应用模型:OpenPose、Seg(自定义背景内容和结构)、Depth
示例:
三维重建
方法:通过 Depth 深度检测和 Normalbae 法线贴图模型,识别三维目标。再配合提示词和风格模型,重新构建出三维物体和场景。
应用模型:Depth、Normalbae
示例:
更精准的图片风格化
方法:在 img2img 图生图中,通过叠加 Lineart 和 Depth 模型,可以更加精准的提取图像结构,最大程度保留原图细节,再配合提示词和风格模型重新生成图像。
应用模型:Lineart、Depth
示例:
更精准的图片局部重绘
方法:在 img2img 图生图的局部重绘中,通过叠加 Canny 和 Inpaint 模型,可以更加精准的对图像进行局部重绘。
应用模型:Canny、Inpaint
示例:

若有收获,就点个赞吧
0 人点赞
