本书地址 https://learning.oreilly.com/library/view/sql-cookbook-2nd/9781492077435/
https://oreil.ly/sql-ckbk-2e
涉及到的表
MySQL-SQL-CookBook.sql
1 检索记录
1.10 从表中随机返回n行数据
MySQL
结合使用内置函数RAND,LIMIT和ORDER BY。
select ename,jobfrom emporder by rand() limit 5
Oracle
结合使用(内置包DBMS_RANDOM中的)内置函数VALUE、ORDER BY子句和内置函数ROWNUM。
select *
from (
select ename, job
from emp
order by dbms_random.value()
)
where rownum <= 5
1.12 将NULL转换为实际值
使用COALESE将NULL值替换为实际值
select comm,coalesce(comm,0)
from emp;
COALESCE可以将一个或多个值作为参数,并返回参数列表中的,第一个非NULL值。
2 查询结果排序
2.3 按子串排序
返回EMP表中的员工姓名和职位,并按JOB列的最后两个字符排序。
DB2 MySQL Oracle PostgreSQL
select ename
from emp
order by substr(job,length(job)-1)
2.5 排序时处理NULL值
DB2 MySQL PostgreSQL SQLServer
使用CASE表达式来创建一个指出列值是否为NULL的标志。这个标志有两个可能的值,一个表示列值为NULL,另一个表示列值不为NULL。创建这个标识后,只需要在ORDER BY子句中指定根据它进行排序。这能够轻松地将列值为NULL的行放在最前面还是最后面,同时不影响值不为NULL的行。
/* 按照升序排列 COMM 列不为 NULL 的行,并将 COMM 列为 NULL 的行放在最后面 */
select ename,sal,comm
from (
select ename,sal,comm,
case when comm is null then 0 else 1 end as is_null
from emp
) x
order by is_null desc,comm;
Oracle
Oracle可以使用上面方案,也可以使用Oracle特有的解决方案。该解决方案利用ORDER BY子句扩展NULLS FIRST 和 NULLS LAST,来分别确保将列值为NULL的行放在最前面和最后面,而不管列值不为NULL的行是如何排序的。
/* 按照升序排列 COMM 列不为 NULL 的行,并将 COMM 列为 NULL 的行放在最后面 */
select ename,sal,comm
from emp
order by comm nulls last
/* 按照升序排列 COMM 列不为 NULL 的行,并将 COMM 列为 NULL 的行放在最前面 */
select ename,sal,comm
from emp
order by comm nulls first
/* 按照降序排列 COMM 列不为 NULL 的行,并将 COMM 列为 NULL 的行放在最前面 */
select ename,sal,comm
from emp
order by comm desc nulls first;
2.6 根据依赖于数据库的键进行排序
如果JOB列为SALESMAN,就根据COM排序,否则根据SAL排序。
select ename,sal,job,comm
from emp
order by case when job = 'SALESMAN' then comm else sal end
可以使用CASE表达式动态地修改结果排序方式。传递ORDER BY子句中的值。
select ename,sal,job,comm,
case when job = 'SALESMAN' then comm else sal end as ordered
from emp
order by 5
3 使用多张表
3.4 从一张表中检索没有出现在另一张表中的值
找出 DEPT 表中都有哪些部门没有出现在 EMP 表中
DB2、postgresql、SQL Server
使用集合运算
select deptno from dept
except
select deptno from emp
Oracle
使用集合运算MINUS
select deptno from dept
minus
select deptno from emp
MySQL
使用子查询将EMP表中所有的DEPTNO都返回给外部查询,而外部查询在DEPT表中查询DEPTNO没有出现在子查询返回结果中的行。
select deptno
from dept
where deptno not in (select deptno from emp)
注意
DB2、PostgreSQL 、SQL Server 差集函数让这种操作易如反掌。EXCEPT运算符会将出现在第一个结果集中但属于第二个结果集的行都删除。
对于EXCEPT在内的集合运算符,存在一定的限制:在两个SELECT子句中,指定的列数量和数据类型必须匹配。另外,EXCEPT会剔除重复的行,同时不同于使用NOT IN的子查询,NULL不会给它带来麻烦。
MySQL,子查询会返回EMP表中所有的DEPTNO,而外部查询会返回DEPT表中未出现在子查询返回的结果集中的所有DEPTNO。
在使用MySQL解决方案中,必须考虑消除重复行的问题,基于EXCEPT和MINUS的解决方案中会消除结果集中的重复行,确保每个DEPTNO都只报告一次。
使用NOT IN时,务必注意NULL值。
create table new_dept(deptno integer);
insert into new_dept values (10);
insert into new_dept values (50);
insert into new_dept values (null);
执行以下SQL,不会返回任何值
select deptno
from dept
where deptno not in (select deptno from new_dept)
deptno 的值20 30 40都未出现在NEW_DEPT表中,但上述查询并没有返回它们。原因是NEW_DEPT表中包含NULL值。子查询返回了3行,它们的DEPTNO值分别是10 50 null。
如下是真值表
OR | T | F | N |
+----+---+---+----+
| T | T | T | T |
| F | T | F | N |
| N | T | N | N |
+----+---+---+----+
NOT |
+-----+---+
| T | F |
| F | T |
| N | N |
+-----+---+
AND | T | F | N |
+-----+---+---+---+
| T | T | F | N |
| F | F | F | F |
| N | N | F | N |
+-----+---+---+---+
在SQL中,TRUE or NULL结果为TRUE ,但FALSE or Null结果为NULL!
为了避免NULL给not in带来的问题,可以结合使用关联子查询和NOT EXISTS。
-- 这是一种不受NULL值影响的解决方案
select d.deptno
from dept d
where not exists (
select 1
from emp e
where d.deptno = e.deptno
)
3.9 同时使用连接和聚合
查询将返回部分编号为10的所有员工的薪水和奖金。EMP_BONUS.TYPE决定了奖金额:1 类奖金为员工薪水10%,2 类奖金为员工薪水的20%,3类奖金为员工薪水的30%。
drop table IF EXISTS emp_bonus ;
create table emp_bonus(
`empno` int not null,
`recevied` date not null,
`type` smallint not null);
insert into emp_bonus value (7934,'2005-03-17',1);
insert into emp_bonus value (7934,'2005-02-15',2);
insert into emp_bonus value (7839,'2005-02-15',3);
insert into emp_bonus value (7782,'2005-02-15',1);
-- 查询奖金 emp_bonus.type决定了奖金(1 为10%,2为20%,3为30%)
select e.EMPNO,e.ENAME ,e.sal ,e.DEPTNO,
e.SAL* case when eb.type =1 then .1
when eb.type =2 then .2
else .3 end as bonus
from emp e ,emp_bonus eb
where e.EMPNO=eb.empno
and e.DEPTNO=10 ;

当试图连接到EMP_BOUNS表以计算奖金总额时,问题便出现了。
select deptno,
sum(sal) as total_sal,
sum(bonus) as total_bonus
from (
select e.empno,
e.ename,
e.sal,
e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10
) x
group by deptno;

TOTAL_BONUS是正确的,TOTAL_SAL则不正确,部分编号为10的所有员工工资为8750.
select e.ENAME,e.sal from emp e ,emp_bonus eb
where e.EMPNO =eb.empno and e.deptno=10;
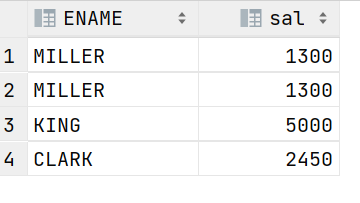
查询TOTAL_SAL不正确,是因为MILLER的薪水被计算了两次。
结局方案
同时使用连接和聚合时,必须非常小心。当连接导致相同的数据被返回多次,为了避免聚合函数执行错误的计算,通车有两种方法。一种方法是在调用聚合函数是使用关键字DISTINCT,这样计算是相同的值将只计算一次;另一种方法是在连接钱先执行聚合计算(在内嵌试图中),这样可用避免聚合函数执行错误的计算,因为聚合发生在了连接之前。
MySQL和 PostgreSQL 使用关键字DISTINCT避免重复计算薪水
select deptno,
sum(distinct sal) as total_sal,
sum(bonus) as total_bonus
from (
select e.empno,
e.ename,
e.sal,
e.deptno,
e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10
) x
group by deptno;
DB2 Oracle SQL Server 这些平台支持上面的解决方案,但也支持另一种解决方案,即使用窗口函数SUM OVER.
select distinct deptno,total_sal,total_bonus
from (
select e.empno,
e.ename,
sum(distinct e.sal) over
(partition by e.deptno) as total_sal,
e.deptno,
sum(e.sal*case when eb.type = 1 then .1
when eb.type = 2 then .2
else .3 end) over
(partition by deptno) as total_bonus
from emp e, emp_bonus eb
where e.empno = eb.empno
and e.deptno = 10
) x
3.10 同时使用外连接和聚合
与上面相同,但对EMP_BONUS表进行修改,使得非部门编号为10的每位员工都有奖金。下面列出了修改后的EMP_BONUS表的内容,以及一个错误的查询,该查询视图计算部门编号为10的所有员工的薪水总额以及奖金总额。
select * from emp_bonus ;


若有收获,就点个赞吧
0 人点赞
