1 G1GC是什么
1.1.4 G1GC中的实时性
G1GC具有软实时性。为了实现软实时性,它具备以下两个功能。
- 设置期望暂停时间(最后期限)
- 可预测性
①是支持用户自定义mutator暂停时间的功能,G1GC具有软实时性,因此会尽力保证处理不超过该暂停时间
②是用来预测下次GC导致mutator暂停多长时间的功能。根据预测出来的结果,G1会通过延迟执行GC,拆分GC目标对象手段来遵守①中设置的期望暂停时间。通过这种方式,能够尽量减少超出用户期望暂停时间的频率,从而实现实时性。
1.2 堆结构
G1GC中的堆结构和列出GC中的堆结构非常相似。
堆的内部被划分出大小相等的区域,所有区域排列成一排,G1GC以区域为单位进行GC。用户可以随意设置区域大小,但是内部会将用户设置的值向上调整为2的指数幂,并以该正数作为区域的大小。
如果正在分配对象的某个区域已经满了,GC线程会寻找下一个空闲的区域来继续分配。空闲区域是通过链表进行管理的,因此查找的时间复杂度是固定的O(1)。
1.3 执行过程
G1GC主要有下面两个功能。
① 并发标记(concurrent marking)
② 转移(evacuation)
①并发标记 基本能和mutator并发执行,会针对区域内所有的存活对象进行标记。
②转移负责释放堆中死亡对象所占的内存空间。
首先,从众多区域中选择一个进行GC操作。如果该区域中有存活对象,则将其复制到其他空闲区域中。
当选择的空闲区域也满了的时候,GC线程会再次选择其他空闲区域来存放存活对象。对象复制完成之后,只剩下死亡对象②的区域会被重置为空闲区域以便复用。
转移其实也起到了压缩的作用,因此G1GC中的区域不会发生碎片化。
死亡对象:已死亡的对象,即不可能被程序使用的对象 压缩:将存活对象挤到内存中同一侧的操作。因为压缩之后对象没有空隙,所以区域不会有碎片化的问题。
1.4 并发标记和转移
G1GC的主要功能是并发标记和转移。其中并发标记由并发标记线程来执行。
并发标记的作用是在尽量不暂停mutator的情况下标记出存活对象。而且,还需要在并发标记结束之后记录下每个其余内存活对象的数量。这个信息在转移时会用到。
转移的作用是将带回收区域内的存活对象复制到其他的空闲区域,然后将待回收区域重置为空闲状态。这很像复制GC算法,只不过是以区域为单位进行的。
需要注意的是,并发标记和转移在处理上是相互独立的。并发标记的结果信息对于转移来说并不是必须的。因此,转移可能发生在并发标记开始之前,也可能发生在并发标记的过程中。
2 并发标记
在简单标记中,所有可从跟直接触达的对象都会被添加标记。带标记的是存活对象,不带标记的是死亡对象。
在并发标记中,存活对象的标记和mutator的运行几乎是并发进行的。
并发标记其实并不是直接在对象上添加标记,而是在标记位图上添加标记。
2.3 执行步骤
并发标记过程包括以下5个步骤。
- 初始化标记阶段
- 并发标记阶段
- 最终标记阶段
- 存活对象计数
- 收尾工作
以下简单介绍各个步骤:
- ① 暂停mutator的运行,标记可由跟直接引用的对象。
- 标记 ①中的对象所引用的对象。本步骤开启并发标记线程标记,这个过程和mutator的运行时并发进行的。
- 暂停处理。本步骤会扫描②中没有标记的对象。在本步骤结束之后,堆内多有存活的对象都会被标记。
- 对每个区域中没有被标记的对象进行计数。这个过程也是mutator并发进行的。
- 暂停处理。本步骤主要进行一些收尾工作,并为下次标记做准备。在本步骤结束之后,整个并发标记过程全部结束。
2.4 步骤①——初始化标记阶段
3 转移
3.1 什么是转移
通过转移,所选区域内的所有存活对象都会被转移到空闲区域。这样一来,被转移的区域内只剩下死亡对象。重置之后,该区域就会变为空闲区域,能够再次利用。
下图表示了转移开始前和结束后的状态。转移结束后,可从根触达的存活对象a b c 会被转移到空闲区域C,而死亡对象d e不会被转移,整个区域就会编程空闲区域,能够再次利用。
3.2 转移专用记忆集合
除了可以从根和并发标记的结果发现存活对象之外,转移功能还能通过转移专用记忆集合来发现对象。
转移专用记忆集合则用来记录区域之间的引用关系。通过使用转移专用集合,在转移是即使不扫描所有区域的对象,也可以查到待转移对象所在区域内的对象被其他区域引用的情况,从而简化单个区域的转移处理。
G1GC是通过卡表来实现转移专用记忆集合的。
3.2.1 卡表
卡表是由元素大小为1B的数组实现的。卡表里的元素称为卡片。堆中大小适当的一段存储空间会对应卡表中的1个元素(卡片)。在当前的JDK中,这个大小被定为512B。因此堆的大小是1GB时,可以计算出卡表的大小就是2MB。
堆中的对象所对应的卡片在表中的索引值可以通过以下公式快速计算出来。
(对象的地址 - 堆的头部地址)/512
因为卡片的大小是1B,所以可以用来表示很多状态。卡片的种类很多,本书主要关注以下两种。
① 净卡片
② 脏卡片
3.2.2 转移专用记忆集合的构造

每个区域中都有一个转移专用记忆集合,它是通过散列表实现的。散列表的键是引用本区域的其他区域的地址,而散列表的值是一个数组,数组的元素是引用方的对象所对应的卡片索引。
在上图中,区域B中的对象b引用了区域A中的对象a。因为对象b不是区域A中的对象,所以必须记录下这个引用关系。而在转移专用集合A中,以区域B的地址为键的值中记录了卡片的索引2048。因为对象b所对应的卡片索引就是2048,所以对象b对对象a的引用被准确地记录了下来。
由此,区域间对象的引用关系是由转移专用记忆集合以卡片为单位粗略记录的。因此,在转移是必须扫描记录的卡片所对用的全部对象的引用。
3.3 转移专用写屏障
当对象的域被修改时,被修改的对象所对应的卡片会被转移专用写屏障记录到转移专用集合中。
3.4 转移专用记忆集合维护线程
转移专用记忆集合维护线程是和mutator并发执行的线程,它的作用是基于转移专用记忆集合日志的集合,来维护转移专用记忆集合。
具体来说,转移专用记忆集合维护线程主要进行下列处理。
① 从转移专用集合日志的集合中取出专用记忆集合日志,从头开始扫描。
② 将卡片变成净卡片
③ 检查卡片所对应存储空间内所有对象的域。
④ 往域中地址所指向的区域的记忆集合中添加卡片。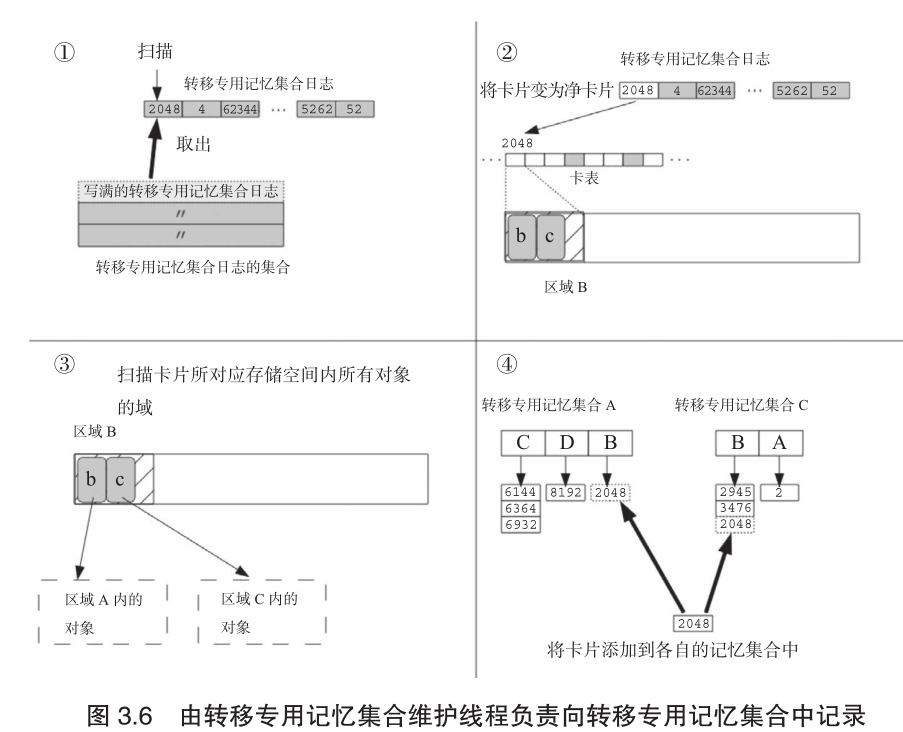
如果卡片在③和④的处理过程中被mutator修改了,那么又变成了脏卡片,然后再次被添加到专用记忆集合日志中。
在转移专用记忆集合日志的集合中,当转移专用记忆集合日志的数量超过阀值(默认为5个)时,转移专用记忆集合维护线程就会启动,然后一直处理到数量降至阀值的1/4以下。
3.5 热卡片
频繁发生修改的存储空间所对应的卡片称为热卡片。热卡片可能会多次被转移专用记忆集合维护线程处理成脏卡片,从而加重转移专用记忆集合维护线程的负担,因此需要特别处理。
要想发现热卡片,需要用到卡片计数表,它记录了卡片变成脏卡片的次数。卡片计数表记录了自上次转移依赖哪个卡片变成了脏卡片,以及变成脏卡片的次数,其内容会在下次转移时被清空。
变成脏卡片的次数超过阀值(默认是4)的卡片会被当成热卡片,在被处理为脏卡片后添加到热队列尾部。热队列的大小是固定的(默认是1KB)。如果队列满了,则从队列头部取出老的卡片,给新的卡片腾出位置。取出的卡片由转移专用记忆集合维护线程当做普通卡片处理。
热队列中的卡片不会被转移专用记忆集合维护线程处理,因此即使处理了,它也有可能马上变成脏卡片。因此,热队列中的卡片会被留到转移的时候在处理。
3.6 执行步骤
转移的执行步骤为以下3个。
① 选择回收集合
② 根转移
③ 转移
①是指参考并发标记提供的信息来选择被转移的区域。被选中的区域称为回收集合。
②是指将回收集合由根直接引用的对象,以及被其他区域引用的对象转移到空闲区域中。
③是指以②中转移的对象为起点扫描其子孙对象,将所有存活对象一并转移。当③结束之后,回收集合内所有的存活对象就转移完成了。
这三个步骤都是暂停处理。在转移开始后,即使并发标记正在进行也会先中断,而优先进行转移处理。
3.7 步骤①——选择回收集合
选择标准简单来说有两个。
① 转移效率高
② 转移的预测暂停时间在用户的容忍范围内
在选择回收集合时,堆中的区域已经按照转移效率降序排列了。
接下来,按照排好的顺序依次计算各个区域的预测暂停时间,并选择回收区域。当所有已选区域预测暂停时间的总和快要超过用户的容忍范围时,后续区域的区域就会停止,所有已选的区域已成为一个回收集合。
回收集合的选择,会以转移效率由高到底的顺序进行。在多数情况下,死亡对象越多,区域的转移效率就越高,因此G1GC会优先选择垃圾多的区域进行回收集合。
3.8 步骤②——根转移
根转移的转移对象包括以下3类。
- 由根直接引用的对象
- 并发标记处理中的对象
- 由其他区域对象直接引用的回收集合内的对象
3.9 步骤③——转移
完成跟转移之后,那些被转移队列的对象就会依次转移。直到转移队列被清空,转移就完成了。此次,回收集合内的所有存活对象都被成功转移了。
3.10 标记信息的作用
只有被死亡对象引用的对象是不会被转移的。这正是并发标记中标记信息的意义所在。
4 软实时性
4.1 用户的需求
在G1GC中,用户可以设置如下3个值。
① 可用内存上限
② GC暂停时间上限
③ GC单位时间
设置①是为了避免内存被过度占用。就算是为了实现软件实时性,也不能让GC完全占用内存。
②指定的是执行GC所导致的mutator的最大暂停时间。这个最大暂停时间并不包括G1GC并发处理时间。在多数处理器环境下,G1GC的并发处理时间可以理解成平均分配给mutator的负载。
有一个权宜之计可以避免GC暂停时间超过指定上限,那就是频繁地执行暂停时间较短的GC。虽然这样做确实可以缩短GC暂停时间,但是mutator的执行也会频繁地被GC打断,从而导致mutator几乎无法正常执行,要想避免这个问题,需要执行③的GC单位时间,指定该想后,G1GC将在每个单位时间内遵守GC的暂停时间上限。如果GC暂停时间上限是1秒,而GC单位时间是3秒,就意味着任意3秒的时间段内,GC的暂停时间不可用超过1秒。
4.2 预测转移时间
要想在GC暂停时间上限之内完成转移,就需要旋转可以在这个时间范围内完成转移的回收集合。在往回收集合中添加区域时,要先预测一下该区域的转移时间,如果超过了GC暂停时间上限,就不再添加该区域,并终止回收集合的选择。
在G1GC中,由GC导致的mutator的暂停时间称为消耗。转移回收集合的消耗,等于扫描转移专用记忆集合中的卡片是的消耗与对象转移是的消耗之和。
5 分代G1GC模式
G1GC中存在“纯G1GC模式”和“分代G1GC模式”两种模式。
OpenJDK虽然实现了纯G1GC模式,但是并没有将这种模式开放给用户。用户使用的都是分代G1GC模式。
5.1 不同点
和纯G1GC模式相比,分代G1GC模式主要有以下两个不同点。
- 区域是分代的。
- 回收集合的选择是分代的
在分代G1GC模式中,区域被分成新生代区域和老年代区域两类。和其他分代GC算法一样,分代G1GC的对象也保存了自身在各自转移中存活下来的次数,新生代区域用来存放新生代对象,老年代余区域用来存放老年代对象。
另外,分代G1GC模式也分成新生代GC和老年代GC。G1GC中的新生代GC称为完全新生代GC,老年代GC称为部分新生代GC。
完全新生代GC和部分新生代GC的主要区别在于回收集合的选择。完全新生代GC将所有新生代区域选入回收集合,而部分新生代GC将所有新生代,以及一部分老年代区域选入回收集合。
所有的新声代区域都会被选入回收集合。
5.2 新生代区域
新生代区域可以进一步分为以下两类
- 创建区域
- 存活区域
创建区域用来存放刚刚生成、一次也没有被转移过的对象,存活区域用来存放被转移过至少一次的对象。
另外,转移专用写屏障不会应用在新生代区域的对象上。一次你,即使新生代区域的对象存在其他区域对象的引用,被引用区域的转移专用集合中也不会记录引用方的卡片。
5.3 分代对象转移
存活对象保存了自己被转移的次数,这个次数称为对象的年龄。转移时对象的年龄如果低于阀值,对象就会被转移到存活区域,否则就会被转移到老年代的区域。将对象转移到老年代区域的行为称为晋升。
如果转移的目标区域满了,垃圾回收器就会选择一个空闲的区域,把它修改成存活区域或者老年代区域之后,作为转移的目标区域使用。
对象被转移到存活区域之后,即使该对象引用了回收集合意外的区域,也不需要记录在转移专用记忆集合中。
5.4 执行过程简述
完全新生代GC不会选择老年代区域,而是将所有新生代区域都选入回收集合,然后转移回收集合孽的存活对象。晋升的对象会被转移到老年代区域,其余对象则被转移到存活区域。
部分新生代GC则是除了所有新生代区域外,还会选择一部分老年代区域进入回收集合。除了回收集合的选择方式,部分新生代GC和完全新生代GC的执行过程是一样的。
5.5 分代选择回收集合
分代GC的理论基础是大多数对象是“朝生夕死”的。因此,分代G1GC模式也是通过选择回收集合的方式来确保总是优先转移新生代区域,从而积极地释放年轻对象的内存空间。
不过,选择全部新生代区域的做法可能会打破软实时性。如果新生代区域数太多,就有可能无法遵守用户设置的GC暂停时间上限。要想避免这个问题,分代G1GC模式就需要计算出合理的最大新生代区域数。
5.6 设置最大新生代区域数
完全新生代GC和部分新生代GC关于最大新生代区域数的计算方法是不一样的。
完全新生代GC的最大新生代区域数是遵守GC暂停时间上限的前提下,尽量设置较大的值。即根据过去的转移时间记录,预测出单个新生代区域转移所需的大概时间,然后基于这个时间计算出刚好不超过GC暂停时间上限的最大新生代区域数。
而部分新生代GC的最大新生代区域数是在遵守GC单位时间的前提下,尽量设置较小的值。首先,计算出下次能够进行GC暂停处理的时机。然后,预测出这个“时机”之前大概能回收多少个区域,并以此作为新生代区域的最大数目。当预测值命中时,达到最大新生代区域的时机,刚好是下次能够进行GC暂停处理的时机,因此能够遵守GC单位时间。另外,因为最大新生代区域数设置的是最小值,所以被选入回收集合的新生代区域数也是最小的。这样一样来,距离GC暂停时间上限很有可能还有一段时间,就可以往回收集合里添加一些老年代区域。
最大新生代区域的设置发生在并发标记结束之后。
5.7 GC的切换
垃圾回收器在选择GC算法时,通常会选择部分新生代GC,只有在使用完全新生代GC效率更高时才会切换为完全新生代GC。切换的时间点和设置最大新生代区域数时一样,都是在并发标记结束之后。
首先,参考并发标记中标记出的死亡对象的个数,并预测出下次部分新生代GC的转移效率。然后,根据过去的完全新生代GC的转移效率,预测出下次完全新生代GC的转移效率。如果预测出完全新生代GC的转移效率更高,则切换为完全新生代。
5.8 GC执行的时机
当新生代区域数达到上限时,会触发转移的执行,换句话说,通过调节最大新生代区域书,可以控制转移执行的时机。
当转移完成并通过以下4项检查之后,会开始执行并发标记。
- 不会在并发标记执行过程中
- 并发标记的结果已被上一次转移使用完
- 已经使用了一定量的堆内存(默认是全部堆内存的45%以上)
- 相比上次转移完成之后,对内存的使用量有所增加
6 算法总结
6.2 优点
首先,G1GC具备软实时性,这是一个很大的优点。对于要求软实时性的应用程序,可以用用户控制GC暂停时间。
其次,它能够充分发挥高配置机器的性能,大幅度缩减GC暂停时间。虽然考虑到算法,总有一些必须要暂停的阶段,但这些阶段也可以通过尽可能地并行执行,来进一步缩短暂停时间。
再次,它通过写屏障的处理粒度由对象粒度改为更粗的卡片粒度,降低了写屏障发生的评率。这也是缩短暂停时间的一个手段。
另外,因为有转移,所以区域内不会产生内存碎片。由此可以提高引用的局部性和对象存储空间分配的速度。
与其他具备软实时性的GC相比,G1GC的吞吐量保存在较高水平。近年,很多具备软实时性的GC会通过频繁地执行“以对象为单位进行复制”这种更细粒度的暂停处理来缩短GC暂停时间,从而达成软件实时性。因此,无论如何它们的吞吐量都是下降的。另外,这些GC中死亡对象的回收处理可能存在延迟,因此内存的使用效率也不高。
而G1GC以区域这种较粗的粒度来频繁地执行用户指定时间内的暂停处理,所以暂停时间会稍微长一点,它的吞吐量也会高一些。此外,通过在转移选择时选择合适的回收集合,还能更高效地回收死亡对象。
6.3 缺点
G1GC的适用对象被限定为“搭载多核处理器、拥有大容量内存的机器”。在大多数环境下,我们并不能发挥出他们的性能。适用环境受限可以说是它的一个缺点。
另外在转移时,尽管区域内不会出现碎片化,但是会出现以区域为单位(整个堆)的碎片化。和普通GC复制算法相比,这一点算是缺点。

若有收获,就点个赞吧
0 人点赞
