1-6
查询重叠的时间区间
-- 查询重叠的时间区间CREATE TABLE Reservations(reserver VARCHAR(30) PRIMARY KEY,start_date DATE NOT NULL,end_date DATE NOT NULL);INSERT INTO Reservations VALUES('木村', '2006-10-26', '2006-10-27');INSERT INTO Reservations VALUES('荒木', '2006-10-28', '2006-10-31');INSERT INTO Reservations VALUES('堀', '2006-10-31', '2006-11-01');INSERT INTO Reservations VALUES('山本', '2006-11-03', '2006-11-04');INSERT INTO Reservations VALUES('内田', '2006-11-03', '2006-11-05');INSERT INTO Reservations VALUES('水谷', '2006-11-06', '2006-11-06');-- 山本的入住日期为4日时DELETE FROM Reservations WHERE reserver = '山本';INSERT INTO Reservations VALUES('山本', '2006-11-04', '2006-11-04');

上图是酒店和旅客的预约情况。其中有重叠部分,
日期重叠的类型

满足类型1 和类型2 中至少一个条件。
/* 求重叠的住宿期间 */SELECT reserver, start_date, end_dateFROM Reservations R1WHERE EXISTS(SELECT *FROM Reservations R2WHERE R1.reserver <> R2.reserver /* 与自己以外的客人进行比较 */AND ( R1.start_date BETWEEN R2.start_date AND R2.end_date /* 条件(1):自己的入住日期在他人的住宿期间内 */OR R1.end_date BETWEEN R2.start_date AND R2.end_date)); /* 条件(2):自己的离店日期在他人的住宿期间内 */
1-7 用SQL进行集合运算
SQL语言的基础之一是集合论。
比较表和表:检查集合相等值基础篇
/* 比较表和表:检查集合相等性 */CREATE TABLE Tbl_A(keycol CHAR(1) PRIMARY KEY,col_1 INTEGER,col_2 INTEGER,col_3 INTEGER);CREATE TABLE Tbl_B(keycol CHAR(1) PRIMARY KEY,col_1 INTEGER,col_2 INTEGER,col_3 INTEGER);/* 表相等的情况 */DELETE FROM Tbl_A;INSERT INTO Tbl_A VALUES('A', 2, 3, 4);INSERT INTO Tbl_A VALUES('B', 0, 7, 9);INSERT INTO Tbl_A VALUES('C', 5, 1, 6);DELETE FROM Tbl_B;INSERT INTO Tbl_B VALUES('A', 2, 3, 4);INSERT INTO Tbl_B VALUES('B', 0, 7, 9);INSERT INTO Tbl_B VALUES('C', 5, 1, 6);/* B行不同的情况 */DELETE FROM Tbl_A;INSERT INTO Tbl_A VALUES('A', 2, 3, 4);INSERT INTO Tbl_A VALUES('B', 0, 7, 9);INSERT INTO Tbl_A VALUES('C', 5, 1, 6);DELETE FROM Tbl_B;INSERT INTO Tbl_B VALUES('A', 2, 3, 4);INSERT INTO Tbl_B VALUES('B', 0, 7, 8);INSERT INTO Tbl_B VALUES('C', 5, 1, 6);/* 包含NULL的情况(相等) */DELETE FROM Tbl_A;INSERT INTO Tbl_A VALUES('A', NULL, 3, 4);INSERT INTO Tbl_A VALUES('B', 0, 7, 9);INSERT INTO Tbl_A VALUES('C', NULL, NULL, NULL);DELETE FROM Tbl_B;INSERT INTO Tbl_B VALUES('A', NULL, 3, 4);INSERT INTO Tbl_B VALUES('B', 0, 7, 9);INSERT INTO Tbl_B VALUES('C', NULL, NULL, NULL);/* 包含NULL的情况(C行不同) */DELETE FROM Tbl_A;INSERT INTO Tbl_A VALUES('A', NULL, 3, 4);INSERT INTO Tbl_A VALUES('B', 0, 7, 9);INSERT INTO Tbl_A VALUES('C', NULL, NULL, NULL);DELETE FROM Tbl_B;INSERT INTO Tbl_B VALUES('A', NULL, 3, 4);INSERT INTO Tbl_B VALUES('B', 0, 7, 9);INSERT INTO Tbl_B VALUES('C', 0, NULL, NULL);
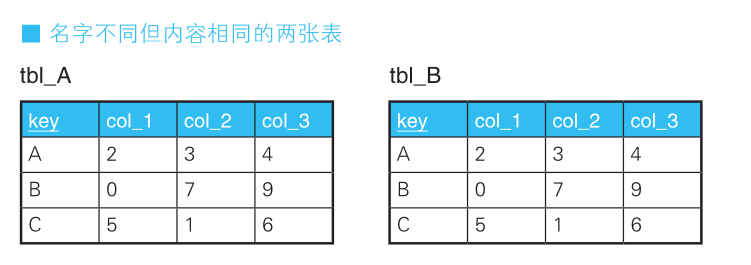
如果这个查询的结果与tbl_A及tbl_B的行数一致,则两张表是相等的。
/* 比较表和表:基础篇 */SELECT COUNT(*) AS row_cntFROM ( SELECT *FROM tbl_AUNIONSELECT *FROM tbl_B ) TMP;
key列为B的一行数据不同:结果变为4

比较表和表:检查集合相等性之进阶篇
/* 比较表和表:进阶篇(在Oracle中无法运行) */SELECT DISTINCT CASE WHEN COUNT(*) = 0THEN '相等'ELSE '不相等' END AS resultFROM ((SELECT * FROM tbl_AUNIONSELECT * FROM tbl_B)EXCEPT(SELECT * FROM tbl_AINTERSECTSELECT * FROM tbl_B)) TMP;
用差集实现关系除法运算
为了进行除法运算,必须自己实现,具有代表性的方法如下面三个
- 嵌套使用NOT EXISTS
- 使用HAVING子句转换成一对一的关系
- 把除法变成减法
/* 用差集实现关系除法运算 */CREATE TABLE Skills(skill VARCHAR(32),PRIMARY KEY(skill));CREATE TABLE EmpSkills(emp VARCHAR(32),skill VARCHAR(32),PRIMARY KEY(emp, skill));INSERT INTO Skills VALUES('Oracle');INSERT INTO Skills VALUES('UNIX');INSERT INTO Skills VALUES('Java');INSERT INTO EmpSkills VALUES('相田', 'Oracle');INSERT INTO EmpSkills VALUES('相田', 'UNIX');INSERT INTO EmpSkills VALUES('相田', 'Java');INSERT INTO EmpSkills VALUES('相田', 'C#');INSERT INTO EmpSkills VALUES('神崎', 'Oracle');INSERT INTO EmpSkills VALUES('神崎', 'UNIX');INSERT INTO EmpSkills VALUES('神崎', 'Java');INSERT INTO EmpSkills VALUES('平井', 'UNIX');INSERT INTO EmpSkills VALUES('平井', 'Oracle');INSERT INTO EmpSkills VALUES('平井', 'PHP');INSERT INTO EmpSkills VALUES('平井', 'Perl');INSERT INTO EmpSkills VALUES('平井', 'C++');INSERT INTO EmpSkills VALUES('若田部', 'Perl');INSERT INTO EmpSkills VALUES('渡来', 'Oracle');
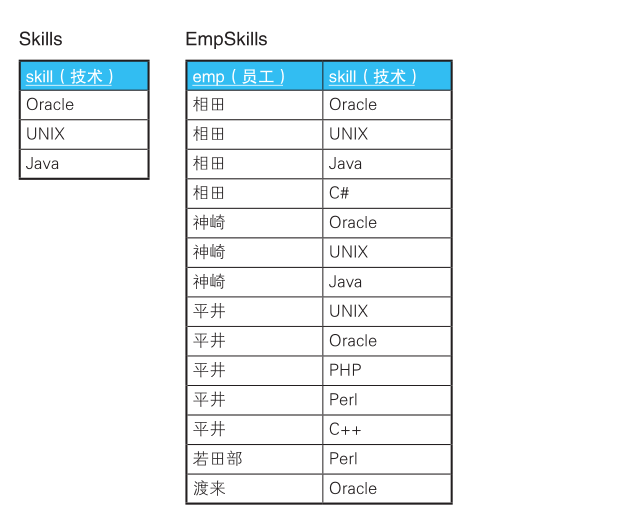
从表EmpSkills中找出精通表Skills中所有技术的员工
/* 用求差集的方法进行关系除法运算(有余数) */SELECT DISTINCT empFROM EmpSkills ES1WHERE NOT EXISTS(SELECT skillFROM SkillsEXCEPTSELECT skillFROM EmpSkills ES2WHERE ES1.emp = ES2.emp);
关联子查询建立在表EmpSkills上,这是因为,我们要针对每个员工进行集合运算。如果集合为空表明该员工具备所有技术。
寻找相等的子集
/* 4.寻找相等的子集 */CREATE TABLE SupParts(sup CHAR(32) NOT NULL,part CHAR(32) NOT NULL,PRIMARY KEY(sup, part));INSERT INTO SupParts VALUES('A', '螺丝');INSERT INTO SupParts VALUES('A', '螺母');INSERT INTO SupParts VALUES('A', '管子');INSERT INTO SupParts VALUES('B', '螺丝');INSERT INTO SupParts VALUES('B', '管子');INSERT INTO SupParts VALUES('C', '螺丝');INSERT INTO SupParts VALUES('C', '螺母');INSERT INTO SupParts VALUES('C', '管子');INSERT INTO SupParts VALUES('D', '螺丝');INSERT INTO SupParts VALUES('D', '管子');INSERT INTO SupParts VALUES('E', '保险丝');INSERT INTO SupParts VALUES('E', '螺母');INSERT INTO SupParts VALUES('E', '管子');INSERT INTO SupParts VALUES('F', '保险丝');

首先,生成供应商的全部组合。
-- 生成供应商的全部组合SELECT SP1.sup AS s1, SP2.sup AS s2FROM SupParts SP1, SupParts SP2WHERE SP1.sup < SP2.supGROUP BY SP1.sup, SP2.sup;
检查一下这些供应组合是否满足如下
- 条件1:两个供应商都经营同类型的零件
- 条件2:两个供应商经营的零件种类相同
/* 寻找相等的子集 */SELECT SP1.sup, SP2.supFROM SupParts SP1, SupParts SP2WHERE SP1.sup < SP2.sup /* 生成供应商的全部组合 */AND SP1.part = SP2.part /* 条件1:经营同种类型的零件 */GROUP BY SP1.sup, SP2.supHAVING COUNT(*) = (SELECT COUNT(*) /* 条件2:经营的零件种类数相同 */FROM SupParts SP3WHERE SP3.sup = SP1.sup)AND COUNT(*) = (SELECT COUNT(*)FROM SupParts SP4WHERE SP4.sup = SP2.sup);
用于删除重复行的高效SQL
/* 5.用于删除重复行的高效SQL *//* 在PostgreSQL中,需要把“with oids”添加到CREATE TABLE语句的最后 */CREATE TABLE Products(name CHAR(16),price INTEGER);INSERT INTO Products VALUES('苹果', 50);INSERT INTO Products VALUES('橘子', 100);INSERT INTO Products VALUES('橘子', 100);INSERT INTO Products VALUES('橘子', 100);INSERT INTO Products VALUES('香蕉', 80);

-- 删除重复行 :使用关联子查询
select * FROM Products
WHERE rowid < ( SELECT MAX(P2.rowid)
FROM Products P2
WHERE Products.name = P2. name
AND Products.price = P2.price ) ;
这种做法不算太差,只是关联子查询的性能问题是难点。
上面思路是,按照“商品名,价格”的组合汇总后,求出每个组合的最大rowid,然后把其余的行都删除掉。直接求删除的行比较困难,所以先求出留下的行。然后将他们从全部的组合中提取出来,把剩下的删除。
假设给表中加上rowid列。如下
/* 用于删除重复行的高效SQL语句(1):通过EXCEPT求补集 */
DELETE FROM Products
WHERE rowid IN ( SELECT rowid
FROM Products
EXCEPT
SELECT MAX(rowid)
FROM Products
GROUP BY name, price);
使用EXCEPT求补集的逻辑如下
使用EXCEPT后,可以轻松求得补集,把EXCEPT改写成NOT IN也是可以实现的。
/* 删除重复行的高效SQL语句(2):通过NOT IN求补集 */
DELETE FROM Products
WHERE rowid NOT IN ( SELECT MAX(rowid)
FROM Products
GROUP BY name, price);
第二个方法有个有点,就是不支持EXCEPT的数据也可以使用
像这样实现了行ID的数据库只有Oracle和PostgreSQL。PostgreSQL里的相应名字是oid,如果要使用,需要事先在CREATE TABLE的时候执指定可选项WITH OIDS,如果其他数据库想使用这些SQL,则需要在表中创建类似的具有唯一性的“ID列”
1-8 EXISTS谓词的用法
在EXISTS的子查询里,SELECT子句的列表key有下面三种写法:
- 通配符 SELECT *
- 常量 SELECT ‘任意内容’
- 列名 SELECT COL
不管采用哪种写法,得到的结果都是一样的。
查询表中“不”存在的数据

/* 查询表中“不”存在的数据 */
CREATE TABLE Meetings
(meeting CHAR(32) NOT NULL,
person CHAR(32) NOT NULL,
PRIMARY KEY (meeting, person));
INSERT INTO Meetings VALUES('第1次', '伊藤');
INSERT INTO Meetings VALUES('第1次', '水岛');
INSERT INTO Meetings VALUES('第1次', '坂东');
INSERT INTO Meetings VALUES('第2次', '伊藤');
INSERT INTO Meetings VALUES('第2次', '宫田');
INSERT INTO Meetings VALUES('第3次', '坂东');
INSERT INTO Meetings VALUES('第3次', '水岛');
INSERT INTO Meetings VALUES('第3次', '宫田');
求“某次会议没有参加的人”
这里并不是根据存在的数据查询“满足这样那样条件”的数据,而是要查询“数据是否存在”。从阶层上来说,这是更高一阶的问题。即所谓的“二阶查询”。这种情况正是EXISTS谓词大显身手的好时机。思路是先加锁所有人都参加了全部会议,并以此生成一个集合,然后减去实际产假会议的人,这样就能得到缺席会议的人。
-- 所有参加会议的人
SELECT DISTINCT M1.meeting, M2.person
FROM Meetings M1 CROSS JOIN Meetings M2 ;
结果是3次X 4人=12行数据,然后减去实际参会者的集合、
/* 用于求出缺席者的SQL语句(1):存在量化的应用 */
SELECT DISTINCT M1.meeting, M2.person
FROM Meetings M1 CROSS JOIN Meetings M2
WHERE NOT EXISTS
(SELECT *
FROM Meetings M3
WHERE M1.meeting = M3.meeting
AND M2.person = M3.person);
还可以用集合的方式来解决。如下面的差集运算
/* 用于求出缺席者的SQL语句(2):使用差集运算 */
SELECT M1.meeting, M2.person
FROM Meetings M1, Meetings M2
EXCEPT
SELECT meeting, person
FROM Meetings;
通过上述对比,NOT EXISTS直接具备了差集运算的功能。
全程量化(1):习惯“肯定<=>双重否定”之间的转换
/* 全称量化(1):习惯“肯定<=>双重否定”之间的转换 */
CREATE TABLE TestScores
(student_id INTEGER,
subject VARCHAR(32) ,
score INTEGER,
PRIMARY KEY(student_id, subject));
INSERT INTO TestScores VALUES(100, '数学',100);
INSERT INTO TestScores VALUES(100, '语文',80);
INSERT INTO TestScores VALUES(100, '理化',80);
INSERT INTO TestScores VALUES(200, '数学',80);
INSERT INTO TestScores VALUES(200, '语文',95);
INSERT INTO TestScores VALUES(300, '数学',40);
INSERT INTO TestScores VALUES(300, '语文',90);
INSERT INTO TestScores VALUES(300, '社会',55);
INSERT INTO TestScores VALUES(400, '数学',80);

查询所有的科目分数都在50分以上的学生。
/* 全称量化(1):习惯“肯定<=>双重否定”之间的转换 */
SELECT DISTINCT student_id
FROM TestScores TS1
WHERE NOT EXISTS /* 不存在满足以下条件的行 */
(SELECT *
FROM TestScores TS2
WHERE TS2.student_id = TS1.student_id
AND TS2.score < 50); /* 分数不满50分的科目 */
查询满足下列条件的学生
1. 数学的分数在80分以上
2. 语文的分数在50分以上
这样的条件不太像是全称量化的命题了。如果转换一下,就能看出来它是全称量化的命题了。
“某个学生的所有行数据中,如果科学是数学,则分数在80分以上,如果科目是语文,则分数在50分一行**”
这是针对同一个集合内的行数据进行了条件分支后的全称量化。SQL语句本身是支持根据不同行表示条件分支的。可以通过下面这个具有两个条件分支的CASE表达式来表示条件分支。
CASE WHEN subject = ' 数学 ' AND score >= 80 THEN 1
WHEN subject = ' 语文 ' AND score >= 50 THEN 1
ELSE 0 END
/* 全称量化(1):习惯“肯定<=>双重否定”之间的转换 */
SELECT DISTINCT student_id
FROM TestScores TS1
WHERE subject IN ('数学', '语文')
AND NOT EXISTS
(SELECT *
FROM TestScores TS2
WHERE TS2.student_id = TS1.student_id
AND 1 = CASE WHEN subject = '数学' AND score < 80 THEN 1
WHEN subject = '语文' AND score < 50 THEN 1
ELSE 0 END);
上述查询无法排除没有语文分数的400号学生。学生必须两门科目都有分数才行,所以我们要加上用于判断行数的HAVING子句来实现。
/* 全称量化(1):习惯“肯定<=>双重否定”之间的转换 */
SELECT student_id
FROM TestScores TS1
WHERE subject IN ('数学', '语文')
AND NOT EXISTS
(SELECT *
FROM TestScores TS2
WHERE TS2.student_id = TS1.student_id
AND 1 = CASE WHEN subject = '数学' AND score < 80 THEN 1
WHEN subject = '语文' AND score < 50 THEN 1
ELSE 0 END)
GROUP BY student_id
HAVING COUNT(*) = 2; /* 必须两门科目都有分数 */
全称量化(2):集合VS谓词
EXISTS和HAVING有一个地方很像,都是以集合而不是以单位来操作数据。
如下的项目工厂管理表
/* 全称量化(2):集合VS谓词——哪个更强大? */
CREATE TABLE Projects
(project_id VARCHAR(32),
step_nbr INTEGER ,
status VARCHAR(32),
PRIMARY KEY(project_id, step_nbr));
INSERT INTO Projects VALUES('AA100', 0, '完成');
INSERT INTO Projects VALUES('AA100', 1, '等待');
INSERT INTO Projects VALUES('AA100', 2, '等待');
INSERT INTO Projects VALUES('B200', 0, '等待');
INSERT INTO Projects VALUES('B200', 1, '等待');
INSERT INTO Projects VALUES('CS300', 0, '完成');
INSERT INTO Projects VALUES('CS300', 1, '完成');
INSERT INTO Projects VALUES('CS300', 2, '等待');
INSERT INTO Projects VALUES('CS300', 3, '等待');
INSERT INTO Projects VALUES('DY400', 0, '完成');
INSERT INTO Projects VALUES('DY400', 1, '完成');
INSERT INTO Projects VALUES('DY400', 2, '完成');
/* 查询完成到了工程1的项目:面向集合的解法 */
SELECT project_id
FROM Projects
GROUP BY project_id
HAVING COUNT(*) = SUM(CASE WHEN step_nbr <= 1 AND status = '完成' THEN 1
WHEN step_nbr > 1 AND status = '等待' THEN 1
ELSE 0 END);
查询条件看做是下面这样的全称量化命题
“某个项目的所有行数据中,如果工厂编号是1以下,则该工厂已完成,如果工厂编号比1大,则该工程还在等待”
这个条件仍然可以用CASE表达式来描述
step_status = CASE WHEN step_nbr <= 1
THEN ' 完成 '
ELSE ' 等待 ' END
最终的SQL语句采用上面这个条件的否定形式
/* 查询完成到了工程1的项目:谓词逻辑的解法 */
SELECT *
FROM Projects P1
WHERE NOT EXISTS
(SELECT status
FROM Projects P2
WHERE P1.project_id = P2. project_id /* 以项目为单位进行条件判断 */
AND status <> CASE WHEN step_nbr <= 1 /* 使用双重否定来表达全称量化命题 */
THEN '完成'
ELSE '等待' END);
虽然两者都能表达全称量化,但是与HAVING相比,使用了双重否定的NOT EXISTS代码看起来不是那么容易理解,这是他的缺点。但是这种写法也有优点,第一个优点是性能好。只要有一行满足条件,查询就会终止,不一定需要查询所有的行数据。而且还能通过连接条件使用“project_id”列的索引,这样查询起来会更快。第二个优点是结果里能包含的信息量更大。如果使用HAVING,结果会被聚合,我们只能获取项目的ID,而如果使用EXISTS,则能把集合里的元素整体都获取到。
对列进行量化:查询全是1的行

/* 对列进行量化:查询全是1的行 */
CREATE TABLE ArrayTbl
(keycol CHAR(1) PRIMARY KEY,
col1 INTEGER,
col2 INTEGER,
col3 INTEGER,
col4 INTEGER,
col5 INTEGER,
col6 INTEGER,
col7 INTEGER,
col8 INTEGER,
col9 INTEGER,
col10 INTEGER);
-- 全为NULL
INSERT INTO ArrayTbl VALUES('A', NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
INSERT INTO ArrayTbl VALUES('B', 3, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
-- 全为1
INSERT INTO ArrayTbl VALUES('C', 1, 1, 1, 1, 1, 1, 1, 1, 1, 1);
-- 至少有一个9
INSERT INTO ArrayTbl VALUES('D', NULL, NULL, 9, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
INSERT INTO ArrayTbl VALUES('E', NULL, 3, NULL, 1, 9, NULL, NULL, 9, NULL, NULL);
使用这总模式数组的表是遇到的需求一般都是下面两种形式
- 查询都是1的行
- 查询 至少有一个9的行
EXISTS谓词主要用于优化“行方向”的量化,而对这个问题,我们需要进行“列方向”的量化。虽然不能用EXISTS,但是实际上可以像如下解答。
/* “列方向”的全称量化:不优雅的解答 */
SELECT *
FROM ArrayTbl
WHERE col1 = 1
AND col2 = 1
AND col3 = 1
AND col4 = 1
AND col5 = 1
AND col6 = 1
AND col7 = 1
AND col8 = 1
AND col9 = 1
AND col10 = 1;
优化的解答是
1-9 用SQL处理数列
生成连续编号
CONNECT BY (Oracle)、 WITH 子句(DB2、SQL Server)
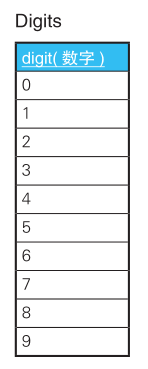
可以通过两个Digits集合求笛卡尔积得出0~99的数字。
/* 求连续编号(1):求0到99的数 */
SELECT D1.digit + (D2.digit * 10) AS seq
FROM Digits D1, Digits D2
ORDER BY seq;
同样地,通过追加D3,D4等集合,不论多少位的数都可以生成,而且,如果只想从1开始,或者到542结束的数,只需要在WHERE子句加入过滤条件就可以了。
/* 求连续编号(2):求1到542的数 */
SELECT D1.digit + (D2.digit * 10) + (D3.digit * 100) AS seq
FROM Digits D1, Digits D2, Digits D3
WHERE D1.digit + (D2.digit * 10) + (D3.digit * 100) BETWEEN 1 AND 542
ORDER BY seq;
/* 生成序列视图(包含0到999) */
CREATE VIEW Sequence (seq)
AS SELECT D1.digit + (D2.digit * 10) + (D3.digit * 100)
FROM Digits D1, Digits D2, Digits D3;
/* 从序列视图中获取1到100 */
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 100
ORDER BY seq;
求全部的缺失编号
-- 求全部的缺失编号
CREATE TABLE SeqTbl
(seq INTEGER PRIMARY KEY);
INSERT INTO SeqTbl VALUES (1);
INSERT INTO SeqTbl VALUES (2);
INSERT INTO SeqTbl VALUES (4);
INSERT INTO SeqTbl VALUES (5);
INSERT INTO SeqTbl VALUES (6);
INSERT INTO SeqTbl VALUES (7);
INSERT INTO SeqTbl VALUES (8);
INSERT INTO SeqTbl VALUES (11);
INSERT INTO SeqTbl VALUES (12);

/* 求所有缺失编号:EXCEPT版 */
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 12
EXCEPT
SELECT seq FROM SeqTbl;
/* 求所有缺失编号:NOT IN版 */
SELECT seq
FROM Sequence
WHERE seq BETWEEN 1 AND 12
AND seq NOT IN (SELECT seq FROM SeqTbl);
下面的做法可能会使性能有所下降,但是通过扩展BETWEEN谓词的参数,我们可以动态地指定目标表的最大值和最小值。如下
/* 动态地指定连续编号范围的SQL语句 */
SELECT seq
FROM Sequence
WHERE seq BETWEEN (SELECT MIN(seq) FROM SeqTbl)
AND (SELECT MAX(seq) FROM SeqTbl)
EXCEPT
SELECT seq FROM SeqTbl;
三个人能做得下吗
假设下面是一张火车座位预定情况
-- 三个人能坐得下吗?
CREATE TABLE Seats
( seat INTEGER NOT NULL PRIMARY KEY,
status CHAR(6) NOT NULL
CHECK (status IN ('未预订', '已预订')) );
INSERT INTO Seats VALUES (1, '已预订');
INSERT INTO Seats VALUES (2, '已预订');
INSERT INTO Seats VALUES (3, '未预订');
INSERT INTO Seats VALUES (4, '未预订');
INSERT INTO Seats VALUES (5, '未预订');
INSERT INTO Seats VALUES (6, '已预订');
INSERT INTO Seats VALUES (7, '未预订');
INSERT INTO Seats VALUES (8, '未预订');
INSERT INTO Seats VALUES (9, '未预订');
INSERT INTO Seats VALUES (10, '未预订');
INSERT INTO Seats VALUES (11, '未预订');
INSERT INTO Seats VALUES (12, '已预订');
INSERT INTO Seats VALUES (13, '已预订');
INSERT INTO Seats VALUES (14, '未预订');
INSERT INTO Seats VALUES (15, '未预订');
假设三个人一起去旅行,准备预定火车,问题是1~15的座位编号中,找出连续的3个空位的全部组合。我们把由连续的整数构成的集合,也就是连续编号的集合称为“序号”。这样序列中就不能出现缺失编号。

借助上图的表,我们可以知道,需要满足条件是,以n为起点, n+(3-1)为终点的座位全部都是未预定状态。
/* 找出需要的空位(1):不考虑座位的换排 */
SELECT S1.seat AS start_seat, '~' , S2.seat AS end_seat
FROM Seats S1, Seats S2
WHERE S2.seat = S1.seat + (:head_cnt -1) /* 决定起点和终点 */
AND NOT EXISTS
(SELECT *
FROM Seats S3
WHERE S3.seat BETWEEN S1.seat AND S2.seat
AND S3.status <> '未预订' )
ORDER BY start_seat;
“:head_cnt”是表示需要的空位个数的参数。
这条查询语句充分体现了SQL在处理有序集合时的原理,对于这个查询,分成两个步骤来理解更容易一些。
第一步:通过自连接生成起点和终点的组合
就在这条SQL语句而言,具体指的是S2.seat = S1.seat + (:head_cnt -1) 这个条件排除了1~8 \2~3这样长度不是3的组合。从而保证结果中出现的只有起点和终点刚好包含3个空位的序列。
第二步:描述起点和终点之间所有的点需要满足的条件
决定了起点和终点以后,我们需要描述一下内部各个点需要满足的条件,为此,我们增加一个起点和终点之间移动的所有点的集合。
-- 考虑座位的折返
CREATE TABLE Seats2
( seat INTEGER NOT NULL PRIMARY KEY,
row_id CHAR(1) NOT NULL,
status CHAR(6) NOT NULL
CHECK (status IN ('未预订', '已预订')) );
INSERT INTO Seats2 VALUES (1, 'A', '已预订');
INSERT INTO Seats2 VALUES (2, 'A', '已预订');
INSERT INTO Seats2 VALUES (3, 'A', '未预订');
INSERT INTO Seats2 VALUES (4, 'A', '未预订');
INSERT INTO Seats2 VALUES (5, 'A', '未预订');
INSERT INTO Seats2 VALUES (6, 'B', '已预订');
INSERT INTO Seats2 VALUES (7, 'B', '已预订');
INSERT INTO Seats2 VALUES (8, 'B', '未预订');
INSERT INTO Seats2 VALUES (9, 'B', '未预订');
INSERT INTO Seats2 VALUES (10,'B', '未预订');
INSERT INTO Seats2 VALUES (11,'C', '未预订');
INSERT INTO Seats2 VALUES (12,'C', '未预订');
INSERT INTO Seats2 VALUES (13,'C', '未预订');
INSERT INTO Seats2 VALUES (14,'C', '已预订');
INSERT INTO Seats2 VALUES (15,'C', '未预订');

考虑以下情况,即发生换排的情况,假设这列火车每一排有5个座位,如表中的行编号row_id列
这种情况下,即使不考虑换排,属于连续编号的序号(9,10,11)也不符合条件,这是因为,坐在11号座位的人其实是一个人坐在一排了。
要解决换排的问题,除了要求序列内的所有座位全部都是空位,还需要加入“全部都在一排”这样一个条件,如下
/* 找出需要的空位(2):考虑座位的换排 */
SELECT S1.seat AS start_seat, '~' , S2.seat AS end_seat
FROM Seats2 S1, Seats2 S2
WHERE S2.seat = S1.seat + (:head_cnt -1) -- 决定起点和终点
AND NOT EXISTS
(SELECT *
FROM Seats2 S3
WHERE S3.seat BETWEEN S1.seat AND S2.seat
AND ( S3.status <> '未预订'
OR S3.row_id <> S1.row_id))
ORDER BY start_seat;
最多能做下多少人
查询按照现在的空位状况,最多能做下多少人,换而言之,就是求最长的序列。
-- 最多能坐下多少人?
CREATE TABLE Seats3
( seat INTEGER NOT NULL PRIMARY KEY,
status CHAR(6) NOT NULL
CHECK (status IN ('未预订', '已预订')) );
INSERT INTO Seats3 VALUES (1, '已预订');
INSERT INTO Seats3 VALUES (2, '未预订');
INSERT INTO Seats3 VALUES (3, '未预订');
INSERT INTO Seats3 VALUES (4, '未预订');
INSERT INTO Seats3 VALUES (5, '未预订');
INSERT INTO Seats3 VALUES (6, '已预订');
INSERT INTO Seats3 VALUES (7, '未预订');
INSERT INTO Seats3 VALUES (8, '已预订');
INSERT INTO Seats3 VALUES (9, '未预订');
INSERT INTO Seats3 VALUES (10, '未预订');
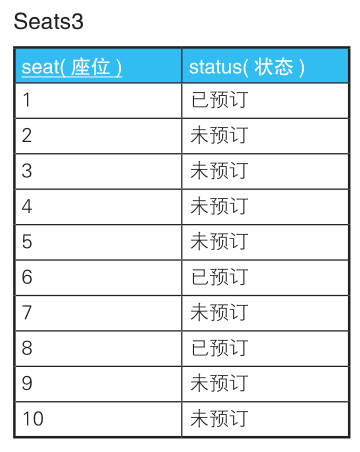
要想保证从座位A到座位B是一个序列,则下面的3个条件必须全部满足
1. 起点到终点之间的所有座位状态都是“未预定”
2 起点之前的座位为状态不是“未预定”
3 终点之后的座位状态不是“未预定”
分两步解决,先生成一张视图
/* 第一阶段:生成存储了所有序列的视图 */
CREATE VIEW Sequences (start_seat, end_seat, seat_cnt) AS
SELECT S1.seat AS start_seat,
S2.seat AS end_seat,
S2.seat - S1.seat + 1 AS seat_cnt
FROM Seats3 S1, Seats3 S2
WHERE S1.seat <= S2.seat /* 第一步:生成起点和终点的组合 */
AND NOT EXISTS /* 第二步:描述序列内所有点需要满足的条件 */
(SELECT *
FROM Seats3 S3
WHERE ( S3.seat BETWEEN S1.seat AND S2.seat
AND S3.status <> '未预订') /* 条件1的否定 */
OR (S3.seat = S2.seat + 1 AND S3.status = '未预订' ) /* 条件2的否定 */
OR (S3.seat = S1.seat - 1 AND S3.status = '未预订' )); /* 条件3的否定 */
然后从视图中找出作为最大的一行
/* 第二阶段:求最长的序列 */
SELECT start_seat, '~', end_seat, seat_cnt
FROM Sequences
WHERE seat_cnt = (SELECT MAX(seat_cnt) FROM Sequences);
单调递增和单调递减
-- 单调递增和单调递减
CREATE TABLE MyStock
(deal_date DATE PRIMARY KEY,
price INTEGER );
INSERT INTO MyStock VALUES ('2007-01-06', 1000);
INSERT INTO MyStock VALUES ('2007-01-08', 1050);
INSERT INTO MyStock VALUES ('2007-01-09', 1050);
INSERT INTO MyStock VALUES ('2007-01-12', 900);
INSERT INTO MyStock VALUES ('2007-01-13', 880);
INSERT INTO MyStock VALUES ('2007-01-14', 870);
INSERT INTO MyStock VALUES ('2007-01-16', 920);
INSERT INTO MyStock VALUES ('2007-01-17', 1000);

上表反映类 某公司的动态股价。
求一下股价单调递增的时间区间。
这里需要排除掉像2007-01-08~2007-01-09这样股价持平的区间。然后按照之前的方法,首先第一步——通过自连接生成起点和终点的组合。
-- 生成起点和终点的组合SQL
SELECT S1.deal_date AS start_date,
S2.deal_date AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date < S2.deal_date ;
/* 求单调递增的区间的SQL语句:子集也输出 */
SELECT S1.deal_date AS start_date,
S2.deal_date AS end_date
FROM MyStock S1, MyStock S2
WHERE S1.deal_date < S2.deal_date /* 第一步:生成起点和终点的组合 */
AND NOT EXISTS /* 第二步:描述区间内所有日期需要满足的条件 */
( SELECT *
FROM MyStock S3, MyStock S4
WHERE S3.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S4.deal_date BETWEEN S1.deal_date AND S2.deal_date
AND S3.deal_date < S4.deal_date
AND S3.price >= S4.price)
ORDER BY start_date, end_date;
1-10 HAVING子句
having子句处理对象是集合而不是记录。
各队,全体点名
-- 各队,全体点名!
CREATE TABLE Teams
(member CHAR(12) NOT NULL PRIMARY KEY,
team_id INTEGER NOT NULL,
status CHAR(8) NOT NULL);
INSERT INTO Teams VALUES('乔', 1, '待命');
INSERT INTO Teams VALUES('肯', 1, '出勤中');
INSERT INTO Teams VALUES('米克', 1, '待命');
INSERT INTO Teams VALUES('卡伦', 2, '出勤中');
INSERT INTO Teams VALUES('凯斯', 2, '休息');
INSERT INTO Teams VALUES('简', 3, '待命');
INSERT INTO Teams VALUES('哈特', 3, '待命');
INSERT INTO Teams VALUES('迪克', 3, '待命');
INSERT INTO Teams VALUES('贝斯', 4, '待命');
INSERT INTO Teams VALUES('阿伦', 5, '出勤中');
INSERT INTO Teams VALUES('罗伯特', 5, '休息');
INSERT INTO Teams VALUES('卡根', 5, '待命');

检查可以出勤的队伍(处于“待命”状态)
上表中,可以出勤的队伍是3队和4队。
“所有队员都处于‘待命’状态”这个条件是全称量化命题,所以可以用NOT EXISTS来表达。
/* 用谓词表达全称量化命题 */
SELECT team_id, member
FROM Teams T1
WHERE NOT EXISTS
(SELECT *
FROM Teams T2
WHERE T1.team_id = T2.team_id
AND status <> '待命' );
**所有队员都处于待命状态= 不存在不处于待命状态的队员**
上述查询性能很好,而且结果中能体现队员信息,因为使用了双重否定,所以易于理解。以下是使用HAVING子句。
/* 用集合表达全称量化命题(1) */
SELECT team_id
FROM Teams
GROUP BY team_id
HAVING COUNT(*) = SUM(CASE WHEN status = '待命'
THEN 1
ELSE 0 END);
上面HAVING 语句是一个肯定句,理解起来更直观,而且代码简洁。分析如下,GROUP BY子句将Teams集合以队伍为单位划分成几个子集。
目标集合是S3和S4,那么只有两个集合拥有而其他集合没有的特征是:处于待命状态的行数与集合中数据总函数相等,这个条件可以用CASE表达式来表示。状态为待命的情况下返回1,其他情况返回0,。这里使用的是特征函数的方法。
根据是否满足条件分别在表里的每一行数据标记1或0,更直观。
HAVING子句的条件还可以这样写
/* 用集合表达全称量化命题(2) */
SELECT team_id
FROM Teams
GROUP BY team_id
HAVING MAX(status) = '待命'
AND MIN(status) = '待命';
/* 列表显示各个队伍是否所有队员都在待命 */
SELECT team_id,
CASE WHEN MAX(status) = '待命' AND MIN(status) = '待命' /* 如果最大值和最小值相等,那么这个集合中就一种元素 */
THEN '全都在待命'
ELSE '队长!人手不够' END AS status
FROM Teams
GROUP BY team_id;
需要注意的是,条件移到SELECT子句后,查询可能不会被数据库优化了,所以性能上相比HAVVING子句的写法会差一下。
单重集合和多重集合
如下是一个生产地材料库存表
-- 单重集合与多重集合
CREATE TABLE Materials
(center CHAR(12) NOT NULL,
receive_date DATE NOT NULL,
material CHAR(12) NOT NULL,
PRIMARY KEY(center, receive_date));
INSERT INTO Materials VALUES('东京' ,'2007-4-01', '锡');
INSERT INTO Materials VALUES('东京' ,'2007-4-12', '锌');
INSERT INTO Materials VALUES('东京' ,'2007-5-17', '铝');
INSERT INTO Materials VALUES('东京' ,'2007-5-20', '锌');
INSERT INTO Materials VALUES('大阪' ,'2007-4-20', '铜');
INSERT INTO Materials VALUES('大阪' ,'2007-4-22', '镍');
INSERT INTO Materials VALUES('大阪' ,'2007-4-29', '铅');
INSERT INTO Materials VALUES('名古屋', '2007-3-15', '钛');
INSERT INTO Materials VALUES('名古屋', '2007-4-01', '钢');
INSERT INTO Materials VALUES('名古屋', '2007-4-24', '钢');
INSERT INTO Materials VALUES('名古屋', '2007-5-02', '镁');
INSERT INTO Materials VALUES('名古屋', '2007-5-10', '钛');
INSERT INTO Materials VALUES('福冈' ,'2007-5-10', '锌');
INSERT INTO Materials VALUES('福冈' ,'2007-5-28', '锡');
需要查找重复的材料生产地。
目标集合是锌重复的东京。以及钛和钢 名古屋。
/* 选中材料存在重复的生产地 */
SELECT center
FROM Materials
GROUP BY center
HAVING COUNT(material) <> COUNT(DISTINCT material);
可以将上述HAVING改写成EXISTS的方式。
/* 存在重复的集合:使用EXISTS */
SELECT center, material
FROM Materials M1
WHERE EXISTS
(SELECT *
FROM Materials M2
WHERE M1.center = M2.center
AND M1.receive_date <> M2.receive_date
AND M1.material = M2.material);
用EXISTS改写成SQL语句也能够查出重复的具体是哪一种材料。而且使用EXISTS后的性能很好。如果想要查出不存在重复材料,将EXISTS改写成NOT EXISTS就可以了。
**
寻找确实的编号:升级版
-- 如果有查询结果,说明存在缺失的编号
SELECT '存在缺失的编号' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq);
这条SQL的前提条件,即数列的起始值必须是1。如果起始值值不是1,如果数列的最小值和最大值之间没有缺失编号,它们之间包含的元素个数应该是“最大值-最小值+1”,因此
/* 如果有查询结果,说明存在缺失的编号:只调查数列的连续性 */
SELECT '存在缺失的编号' AS gap
FROM SeqTbl
HAVING COUNT(*) <> MAX(seq) - MIN(seq) + 1;
/* 不论是否存在缺失的编号都返回一行结果 */
SELECT CASE WHEN COUNT(*) = 0
THEN '表为空'
WHEN COUNT(*) <> MAX(seq) - MIN(seq) + 1
THEN '存在缺失的编号'
ELSE '连续' END AS gap
FROM SeqTbl;
查找最小的缺失编号
/* 查找最小的缺失编号:表中没有1时返回1 */
SELECT CASE WHEN MIN(seq) > 1 /* 最小值不是1时→返回1 */
THEN 1
ELSE (SELECT MIN(seq +1) /* 最小值是1时→返回最小的缺失编号 */
FROM SeqTbl S1
WHERE NOT EXISTS
(SELECT *
FROM SeqTbl S2
WHERE S2.seq = S1.seq + 1))
END AS min_gap
FROM SeqTbl;
为集合设置详细的条件
以下是记录学生考试成绩
-- 为集合设置详细的条件
CREATE TABLE TestResults
(student CHAR(12) NOT NULL PRIMARY KEY,
class CHAR(1) NOT NULL,
sex CHAR(1) NOT NULL,
score INTEGER NOT NULL);
INSERT INTO TestResults VALUES('001', 'A', '男', 100);
INSERT INTO TestResults VALUES('002', 'A', '女', 100);
INSERT INTO TestResults VALUES('003', 'A', '女', 49);
INSERT INTO TestResults VALUES('004', 'A', '男', 30);
INSERT INTO TestResults VALUES('005', 'B', '女', 100);
INSERT INTO TestResults VALUES('006', 'B', '男', 92);
INSERT INTO TestResults VALUES('007', 'B', '男', 80);
INSERT INTO TestResults VALUES('008', 'B', '男', 80);
INSERT INTO TestResults VALUES('009', 'B', '女', 10);
INSERT INTO TestResults VALUES('010', 'C', '男', 92);
INSERT INTO TestResults VALUES('011', 'C', '男', 80);
INSERT INTO TestResults VALUES('012', 'C', '女', 21);
INSERT INTO TestResults VALUES('013', 'D', '女', 100);
INSERT INTO TestResults VALUES('014', 'D', '女', 0);
INSERT INTO TestResults VALUES('015', 'D', '女', 0);

1 查询75%以上的学生分数都在80分以上的班级。
/* 75%以上的学生分数都在80分以上的班级 */
SELECT class
FROM TestResults
GROUP BY class
HAVING COUNT(*) * 0.75
<= SUM(CASE WHEN score >= 80
THEN 1
ELSE 0 END) ;
2 查询分数在50分以上的男生人数比分数在50分以上的女生人数多的班级
/* 分数在50分以上的男生的人数比分数在50分以上的女生的人数多的班级 */
SELECT class
FROM TestResults
GROUP BY class
HAVING SUM(CASE WHEN score >= 50 AND sex = '男'
THEN 1
ELSE 0 END)
> SUM(CASE WHEN score >= 50 AND sex = '女'
THEN 1
ELSE 0 END) ;
3查询女生平均分比男生平均分高的班级
/* 比较男生和女生平均分的SQL语句(1):对空集使用AVG后返回0 */
SELECT class
FROM TestResults
GROUP BY class
HAVING AVG(CASE WHEN sex = '男'
THEN score
ELSE 0 END)
< AVG(CASE WHEN sex = '女'
THEN score
ELSE 0 END) ;
以上写法有问题,空集合使用AVG函数时,结果会返回NULL。
/* 比较男生和女生平均分的SQL语句(2):对空集求平均值后返回NULL */
SELECT class
FROM TestResults
GROUP BY class
HAVING AVG(CASE WHEN sex = '男'
THEN score
ELSE NULL END)
< AVG(CASE WHEN sex = '女'
THEN score
ELSE NULL END);
1-11 让SQL飞起来
使用高效的查询
参数是子查询,使用EXISTS代替IN
使用EXISTS时更快的原因有两个。
- 如果连接的列(id)上建立索引,那么查询不用查询实际的表,可以只查询索引就可以
- 如果使用EXISTS,那么只需要查到一行数据满足条件就会终止查询,不用像使用IN时一样扫描全表,在这一点上NOT EXISTS也一样。
参数是子查询时,使用连接代替IN
避免排序
会进行排序的代表性的运算有下面这些
- GROUP BY子句
- ORDER BY子句
- 聚合函数(SUM COUNT AVG MAX MIN)
- DISTINCT
- 集合运算(UNION INTERSECT EXCEPT)
- 窗口函数(RAND ROW_NUMBER等)

若有收获,就点个赞吧
0 人点赞
