- 1 JVM
- 2 Java基础
- 3 Java并发编程
- 3.1 Java线程的创建方式
- 3.2 线程池的工作原来
- 3.3 5种常用的线程池
- 3.4 线程的生命周期
- 3.5 线程的基本方法
- 3.5.1 线程等待:wait方法
- 3.5.2 线程睡眠:sleep
- 3.5.3 线程让步:yield
- 3.5.4 线程中断:interrupt
- 3.5.5 线程加入:join
- 3.5.6 线程唤醒:notify
- 3.5.7 手台守护线程:setDaemon方法
- 3.5.8 sleep方法与wait方法的区别
- 3.5.9 start方法与run方法的区别
- 3.5.10 终止线程的4种方式
- 3.6.5 synchronized和ReentrantLock的比较
- 3.6.7 Semaphore
- 3.6.8 AtomicInteger
- 3.6.9 可重入锁
- 3.6.10 公平锁和非公平锁
- 3.6.11 读写锁:ReadWriteLock
- 3.6.12 共享锁和独山锁
- 3.6.13 重量级锁和轻量级锁
- 3.6.14 偏向锁
- 3.6.15 分段锁
- 3.6.16 同步锁与死锁
- 3.6.16 如何进行锁优化
- 3.7 线程上下文切换
- 3.8 Java阻塞队列
- 3.9 Java并发关键字
- 3.10 多线程如何共享数据
- 3.11 ConcurrentHashMap并发(JDK1.7及之前的版本)
- 3.12 Java中的线程调度
- 3.14 什么是CAS
- 3.15 ABA问题
- 3.16 什么是 AQS
- 4 数据结构
- 5 Java中的常用算法
- 6 网络与负载均衡
1 JVM
1.1 JVM的运行机制
JVM是用于运行JAVA字节码的虚拟机,包括一套字节码指令集、一组程序寄存器、一个虚拟机栈、一个虚拟机堆、一个方法区和一个垃圾回收器。JVM运行在操作系统之上,不予硬件设备直接交互。JVM每个版本的实现均有不同,下面内容基于JDK1.7
Java程序的具体运行过程如下。
- Java源文件被编译器编译成字节码文件
- JVM将字节码文件编译成相应操作系统的机器码
- 机器码调用相应操作系统的本地方法库执行相应的方法。
Java虚拟机包括一个类加载子系统(Class loader subsystem)、运行时数据区(Runtime Data Area)、执行引擎和本地接口库(Native Interface Library)。本地接口库通过调用本地方法库与操作系统交互。如下图
其中:
- 类加载子系统用于将编译好的.Class文件加载到JVM中
- 运行时数据区用于存储在JVM运行时产生的数据,包括程序计数器、方法区、本地方法区、虚拟机栈和虚拟机堆
- 执行引擎包括即时编译器和垃圾回收器。即时编译器用于将Java字节码编译成具体的机器码,垃圾回收器用于回收在运行过程中不再使用的对象。
- 本地接口库用于调用操作系统的本地方法库完成具体的指令操作
1.2 多线程
在多核操作系统上,JVM允许在一个进程内同时并发执行多个线程。JVM的线程与操作系统中的线程是相互对立的。在JVM线程的本地存储、缓冲区分配、同步对象、栈、程序计数器等准备工作都完成时,JVM会调用操作系统的接口创建一个与之对应的原生线程;在JVM线程运行结束时,原生线程随之被回收。操作系统赋值调度所有线程,并为其分配CPU时间片,在原生线程初始化完毕时,就会调用Java线程的run执行该线程;在线程结束时,会释放原生线程和Java线程所对应的资源。
在JVM后台运行的线程主要有以下几个
- 虚拟机线程(JVM Thread):虚拟机线程在JVM达到安全点(SafePoint)时出现
- 周期性任务线程:通过定时器调度线程来实现周期性任务的执行
- GC线程:GC线程支持JVM中不同的垃圾回收活动
- 编译器线程:编译器线程在运行时将字节码动态编译成本地平台机器码,是JVM跨平台的具体实现
- 信号分发线程:接受发送到JVM的信号并调用JVM方法
1.3 JVM内存区域
JVM的内存区域分为线程私有区域(程序计数器、虚拟机栈、本地方法区)、线程共享区(堆、方法区)和直接内存。如下图
线程私有区域的生命周期与线程相同,随线程的启动而创建,随线程的结束而销毁。在JVM内部,每个线程都与操作系统的本地线程直接映射,因此线程私有内存区域的存在与否和本地线程的启动和销毁对应。
线程共享区随虚拟机的启动而创建,随虚拟机的关闭而销毁。
直接内存也叫堆外内存,它并不是JVM运行时数据区域的一部分,但在并发编程中被频繁使用。JDK的NIO模块提供的基于Channel与Buffer的I/O操作方式是基于堆外内存实现的,NIO模块通过调用Native函数库直接在操作系统上分配堆外内存,然后使用DirectBytrBuffer对象作为这块内存的引用对内存进行操作,Java进程可以通过堆外内存技术避免在Java堆和Native堆中来回复制数据带来的资源浪费和性能消耗,因此堆外内存在高并发应用场景下被广泛使用(Netty Flink Hbase Hadoop都有用到堆外内存)。
1.3.1 程序计数器:线程私有,无内存溢出问题
程序计数器是一块很小的内存空间,用于存储当前运行的线程所执行的字节码的行号指示器。每个运行中的线程都有一个独立的程序计数器,在方法正在执行时,该方法的程序计数器记录的是实时虚拟机字节码指令的地址;如果该方法执行的是Native方法,则程序计数器的值为空。
程序计数器属于“线程私有”的内存区域,它是唯一没有内存溢出(Out of Memory)的区域。
1.3.2 虚拟机栈:线程私有,描述方法的执行过程
虚拟机栈是描述Java方法的执行过程的内存模型,它在当前栈帧(Stack Frame)中存储了局部变量表、操作数栈、动态链接、方法出口等信息。同时,栈帧用来存储部分运行时数据以及数据结构,处理动态链接方法的返回值和异常分派。
栈帧用来记录方法的执行过程,在方法被执行时虚拟机会为其创建一个与之相对应的栈帧,方法的执行和返回对应栈帧在虚拟机栈中的入栈和出栈。无论方法是正常运行完成还是异常完成(抛出了在方法内未被捕获的异常),都视为方法运行结束。下图展示了线程运行及栈帧变化的过程。线程1在CPU1上运行,线程2在CPU2上运行,在CPU资源不足是其他线程将处于等待状态(如图中的等待线程N),等待获取CPU时间片。而线程内部,每个方法的执行和返回都对应一个栈帧的入栈和出栈,每个运行中的线程当前只有一个栈帧处于活动状态。

1.3.3 本地方法区:线程私有
本地方法区和虚拟机栈的作用类似,区别是虚拟机栈为执行Java方法服务,本地方法为Native方法服务。
1.3.4 堆:也叫作运行时数据区域,线程共享
在JVM运行过程中创建的对象和产生的数据都被存储在堆中,堆是被线程共享的内存区域,也是垃圾收集器进行垃圾回收的最主要内存区域。由于现代JVM采用分代收集算法,因此Java堆从GC 的角度还可以细分为:新生代、老年代、永久代。
1.3.5 方法区:线程共享
方法区也被称为永久代,用于存储常量、静态变量、类信息、即时编译器编译后的机器码、运行时常量池等数据。
JVM把GC分代收集扩展至方法区,即使用Java堆的永久代来实现方法区,这样JVM的垃圾收集器就可以像管理Java堆一样管理这部分内存。永久代的内存回收主要针对常量池的回收和类的卸载,因此可回收的对象很少。
常量被存储在运行时常量池(Runtime Constant Pool)中,是方法区的一部分。静态变量也属于方法区的一部分。在类信息(Class文件)中不但保存了类的版本、字段、方法、接口等描述信息还保存了常量信息。
1.4 JVM的运行时内存
JVM的运行时内存也叫作JVM堆,从GC角度可以将JVM堆分为新生代、老年代和永久代。其中新生代默认占1/3堆内存空间,老年代默认占2/3堆内存空间,永久代占非常少的堆内存空间。新生代有分为Eden区,SurvivorFrom区和SurvivorTo区。
1.5 垃圾回收与算法
1.5.1 如何确定垃圾
Java采用引用计数法和可达性分析来确定对象是否应该被回收。其中,引用计算法容器产生循环引用的问题,可达性分析通过根据搜索算法(GC Roots Tracing)来实现。根据搜索算法以一系列GC Roots的点作为起点向下搜索,在一个对象到任何GC Roots都没有引用链相连时,说明其已经死亡。搜索算法主要针对栈中的引用、方法区中的静态引用,和JNI中的引用展开分析。
1 引用计数法
在Java中如果要操作对象,就必须先获取该对象的引用,因此可以通过引用计数法来判断一个对象是否可以被回收。在为对象添加一个引用时,计数器加1;在为对象删除一个引用时,引用计数器减1;如果一个对象的引用计数器为0,则表示此刻该对象没有被引用,可以被回收。
引用计数法容易产生循环引用问题。循环引用指两个对象相互依赖,导致他们的引用一直存在,而不能被回收。
2可达性分析
为了解决引用计数法的循环引用问题,Java采用了可达性分析来判断对象是否可以被回收。具体做法是首先定义一些GC Roots对象,然后以这些GC Roots对象作为起点向下搜索,如果在GC Roots和一个对象之间没有可达路径,则称这些对象是不可达的。不可达对象要经过至少两次标记才能判定其是否可以被回收,如果在两次标记之后该对象仍然是不可达的,则将被垃圾回收器回收。
1.5.3 Java中常用的垃圾回收算法
常用的回收算法有:标记清除、复制、标记整理和分代收集这四种算法。
1 标记清除算法
其过程分为标记和清除两个阶段。在标记阶段标记所有需要回收的对象,在清除阶段清除可回收的对象并释放其所占用的内存空间。
由于标记清除算法在清理对象所占用的内存空间后并没有重新整理可用的的内存空间。因此如果内存中可被回收的小对象过多,则会引起内存碎片化的问题,继而引起大对象无法获取连续可用内存空间的问题。
2复制算法
复制算法是为了解决标记清除算法内存碎片化的问题而设计的,复制算法首先将内存划分为两块大小相等的内存区域,即区域1和区域2,新生代的对象都被存放在区域1,在区域1内的对象存储满后会对区域1进行一次标记,并将标记后仍然存活的对象全部复制到区域2,这时区域1将不存在任何存活的对象,直接清理整个区域1的内存即可。
复制算法的内存清理效率高且易于实现,但由于同一时刻只有一个内存区域可用,即可用的内存空间被压缩到原来的一半,因此存在大量的内存浪费。同时,系统中有大量长时间存活的对象,这些对象将在内存区域1和内存区域2之间来回复制而影响系统的运行效率。因此,该算法只在对象为“朝生夕死”状态时运行效率较高。
3 标记整理算法
标记整理算法结合了标记清除算法和复制算法的优点,其标记阶段和标记清除算法的标记相同,在标记完成后将存活的对象移动到内存的另一端,然后清除该端的对象并释放内存。
4 分代收集算法
无论是标记清除算法、复制算法还是标记整理算法,都无法对所有类型(长生命周期、短生命周期、大对象、小对象)的对象都进行垃圾回收,因此,针对不同的对象类型,JVM采用了不同的垃圾回收算法,该算法被称为分代收集算法。
分代收集算法根据对象的不同类型将内存划分为不同的区域,JVM将堆划分为新生代和老年代。新生代主要存放新生代的对象,其特点是对象数量多但是生命周期短,在每次进行垃圾回收时都要大量的对象被回收;老年代主要存放大对象和生命周期长的对象,因此可回收的对象相对较小。因此,JVM根据不同的区域的对象特点选择了不同的算法。
目前,大部分JVM在新生代都采用了复制算法,因此在新生代中每次进行垃圾回收时都有大量的对象被回收,需要复制的对象(存活的对象)较少,不存在大量的对象在内存中被来回复制的问题,因此采用复制算法能安全、高效地回收新生代大量的短生命周期的对象并释放内存。
JVM将新生代进一步划分为一块较大的Eden区和两块较小的Survivor区,Survivor区又分为SurvivorFrom和SurvivorTo区。JVM在运行过程中主要使用Eden区和SurvivorFrom区,进行垃圾回收时会将在Eden区和SurvivorFrom区中存活的对象复制到SurvivorTo区,然后清理Eden区和SurvivorFrom区的内存空间。
老年代主要存放生命周期较长的对象和大对象,因而每次只有少量非存活的对象被回收,因而老年代采用标记清除算法。
在JVM中还有一个区域,即方法区的永久代,永久代用来存储Class类,常量、方法描述等,在永久代主要回收废弃的常量和无用的类。
JVM内存中的对象主要分配到新生代的Eden区和SurvivorFrom区,在少数情况下会被直接分配到老年代。在新生代的Eden区和SurvivorFrom区的内存空间不足时会触发一次GC,该过程被称为MinorGC。在MinorGC后,在Eden区和SurvivorFrom区中存活的对象会被复制到SurvivorTo区,然后Eden区和SurvivorFrom区被清理。如果此时在SurvivorTo区无法找到连续的内存空间存储某个对象,则将这个对象直接存储到老年代。若Survivor区的对象经过一次GC后仍然存活,则其年龄加1,在默认情况下,对象在年龄达到15后,将被移到老年代。
1.6 Java中的4种引用类型
在Java中对象的操作是通过该对象的引用实现的,Java中的引用类型有4种,分别为强引用、软引用、弱引用和虚引用。
- 强引用:在Java中最常见的就是强引用。在把一个对象赋给一个引用变量时,这个引用变量就是一个强引用。有强引用的对象一定是可达性状态,所以不会被垃圾回收机制回收。因此,强引用是造成Java内存泄漏的主要原因。
- 软引用:软引用通过SoftReference类实现。如果一个对象只有软引用,则在系统内存空间不足是该对象将被回收。
- 弱引用:弱引用通过WeakReference类实现,如果一个对象只有弱引用,则在垃圾回收过程中一定会被回收。
- 虚引用:虚引用通过PhantomReference类实现,虚引用和引用队列联合使用,主要用于跟踪对象的垃圾回收状态。
1.10 JVM的类加载机制
1.10.1 JVM的类加载机制
JVM的类加载分为5个阶段:加载、验证、准备、解析、初始化。在初始化完成后就可以使用该类的信息,在一个类不在被需要时可以从JVM中卸载。
1 加载
指JVM读取class文件,并且根据Class文件描述创建java.lang.Class对象的过程。类加载过程包括将Class文件读取到运行时区域的方法区内,在堆中创建java.lnag.Class对象,并封装类在方法区的数据结构的过程,在读取Class文件时既可以通过文件的形式读取,也可以通过jar包、war包读取,还可以通过代理自动生成Class或其他方法读取。
2 验证
主要用于确保Class文件符合当前虚拟机的要求,保障虚拟机自身的安全,只有通过验证的Class文件才能被JVM加载。
3 准备
只要工作是在方法区中为类变量分内内存空间并设置类中变量的初始值。初始值指不同数据类型的默认值,这里需要注意final类型和非final类型的变量在准备阶段的数据初始化过程不同。
public static long value=1000;
以上代码中,静态变量value在准备阶段的初始化值是0,将value设置为10000的动作是在对象初始化时完成的,因为JVM在编译阶段会将静态变量的初始化操作定义在构造器中。但是将value声明为final类型。
public static final int value = 1000;
则JVM在编译阶段后会为final类型的变量value生成器对应的ConstantValue属性,虚拟机在准备阶段会根据ConstantValue属性将value赋值为1000;
4解析
JVM会将常量池中的符号引用替换为直接引用。
5 初始化
主要通过执行构造器
在发生以下几种情况时,JVM不会执行类的初始化流程。
- 常量在编译时会将其常量存入该常量的类的常量池中,该过程不需要调用类常量所在的类,因此不会触发该常量类的初始化。
- 在子类引用父类的静态字段时,不会触发子类的初始化,只会触发父类的初始化。
- 定义对象数组,不会触发该类的初始化。
- 在使用类名获取class对象是不会触发类的初始化
- 在使用Class.forName加载指定的类时,可以通过initialize参数设置是否需要对类进行初始化。
- 在使用ClassLoader默认的loadClass方法加载时不会触发该类的初始化。
1.10.2 类加载器
Java提供了三种类加载器,分别是启动类加载器、扩展类加载器和应用程序类加载器。

- 启动类加载器:负责加载java_home/lib目录中的类库,或通过-Xbootclasspath参数指定路劲中被虚拟机认可的类库。
- 扩展类加载器:负责加载java_HOME/lib/ext目录中的类库,或通过java.ext.dirs系统变量加载指定路劲中的类库。
- 应用程序类加载器:负责加载用户路劲(classpath)上的类库。
除了上述三种类加载器,还可通过继承java.lang.ClassLoader实现自定义的类加载器。
1.10.3 双亲委派机制
JVM通过双亲委派机制对类进行加载。双亲委派机制指一个类在收到类加载请求后不会尝试自己加载这个类,而是把该类加载向上委托给父类去完成,其父类在接收到该类加载请求后又会将 其委托给自己的父类,以此类推,这样所有的类加载请求都被向上委托到启动类加载器中。若父类加载器在接受到类加载请求后发现自己也无法加载该类(通常原因是该类的Class文件在父类的类加载路劲中不存在),则父类会将该信息反馈给子类并向下委托子类加载器加载该类,直到该类被成功加载,若找不到该类,JVM会抛出ClassNotFound异常。
双亲委派机制的核心是保障类的唯一性和安全性。例如在加载rt.jar包中的java.lang.Object类时,无论是哪个类加载器加载,最终都将类加载请求委托给启动类加载器,这样就保证了类加载的唯一性。如果在JVM中存在包名和类名相同的两个类,则该类加载器无法被加载,JVM也无法完成类加载流程。
2 Java基础
2.1 集合
2.1.1 list 可重复
List是费油常用的数据类型:有序的Collection,一共三个实现 ArrayList Vector LinkedList
1 ArrayList 基于数组实现,增删慢,查询快,线程不安全
2 Vector 基于数组实现,增删慢,查询快,线程安全
3 LinkedList 基于双向链表实现,增删快,查询慢,线程不安全
2.1.2 Queue
java中常用的队列:
- ArrayBlockingQueue:基于数组结构实现的有界阻塞队列
- LinkedBlockingDeque:基于链表数据结构实现的有界阻塞队列
- PriorityBlockiingQueue:支持优先级排序的无界阻塞队列
- DelayQueue:支持延迟操作的无界阻塞队列
- SynchronousQueue:用于线程同步的阻塞队列
- LinkedTransferQueue:基于链表结构实现的无界阻塞队列
- LinkedBlockingDeque:基于链表数据结构实现的双向阻塞队列
2.1.3 Set 不可重复
1 HashSet : HashMap实现,无序
2 TreeSet:二叉树实现
3 LinkHashSet :继承HashSet HashMap 实现数据存储,双向链表记录顺序
2.1.4 Map
1 HashMap:数组+链表存储数据,线程不安全
HashMap基于键的HashCode值唯一标识一条数据,同时基于键的HashCode进行数据的存取,因此可以快速地更新和查询数据,但其每次遍历的顺序无法保证相同。HashMap的key 和value允许为null。
HashMap是非线程安全的。如果需要满足线程安全的条件,则可以使用Collections的synchronizedMap方法使HashMap具有线程安全能力。或者使用ConcurrentHashMap、
HashMap数据结构,其内部是一个数组,数组中每一个元素都是一个单向链表。链表中的每个元素都是嵌套类的Entry实例,Entry实例包含4个属性:key、value、hash值和用于指向单向链表下一个元素的next、
HashMap在查找数据时,根据HashMap的Hash值可以快速定位到数组的具体下标,但是在找到数组的下标后需要对链表进行顺序遍历直到找到需要的值,时间复杂度为O(n)。
为了减少链表遍历的开销,Java8对HashMap进行了优化,将数据结构修改为数组+链表或红黑树。在链表中的元素超过8个之后,HashMap会将链表结构转换为红黑树结构以提高查询效率。
2 JDK1.7及之前的ConcurrentHashMap:分段锁实现 ,线程安全
JDK1.7及以前的ConcurrentHashMap由多个Segment组成(Segment的数量也是锁的并发度)。每个Segment均继承至ReentrantLock并单独加锁,所以每次进行加锁操作锁住的都是一个Segment,这样只要保证每个Segment都是线程安全的,也就实现了全局的线程安全。
JDK1.8以后的版本中,ConcurrentHashMap弃用了Segment分段锁,改用了Synchronized+CAS实现对多线程的安全操作。同时JDK1.8在ConcurrentHashMap中引入了红黑树。
3HashTable 线程安全
4 TreeMap
5 LinkedHashMap :继承HashMap,使用链表保存插入顺序
2.2 异常分类及处理

在Java中,Throwable是所有错误或异常的父类,Throwable 又可分为Error和Exception,常见的Error有 AWTError,ThreadDeath,Exception又可分为RuntimeException和CkeckedException。
Error指Java程序运行错误,如果程序在启动时出现Error。则启动失败;如果程序在运行过程中出现Error,则系统将退出进程。出现Error通常是因为系统的内部错误耗尽,Error不能在运行时被动态处理。如果出现Error,则系统能做的工作也只是记录错误的成因和安全终止。
Exception指Java程序运行异常,即运行中的程序发生了不期望发生的时间,可以被Java异常处理机制处理。Exception也是程序开发中异常处理的核心,可以分为RuntimeException(运行时异常)和 CheckedException(检查异常)
- RuntimeException:指在Java虚拟机正常运行期间抛出的异常,RuntimeException可以被捕获并处理,如果出现RuntimeException,一定是程序发生错误导致。我们通常需要抛出异常或者捕获并处理异常
- CheckedException :指编译阶段Java编译器会检查CheckedException异常并强制程序捕获和处理此类异常。常见的CheckedException是由于I/O错误导致的,IOException,SQLException ClassNotFoundException 等,该异常一般是由于打开错误的文件,SQL语法异常,类不存在引起的。
3 Java并发编程
3.1 Java线程的创建方式
常见的Java线程的4种创建方式分别为:继承Thread、实现Runnable接口、通过ExecutorService和Callable
3.1.3 通过ExecutorService和Callable实现有返回值的线程
有时,我们需要在主线程中开启多个子线程并发执行一个任务,然后收集各个线程执行返回的结果并最终将结果汇总起来,这是就要用到Callable接口。具体的实现方法为:创建一个类并实现Callable接口,在call方法中实现具体的运算逻辑并返回计算结果。具体的调用过程为:创建一个线程池、一个用于接受返回结果的Futur List及 Callable线程实例,使用线程池提条任务并将线程执行之后的结果保存在Future中,在线程执行结束后遍历Future List的Future对象,在该对象上调用get方法就可以获取Callable线程任务返回的数据并汇总结果。
//step 1 通过实现Callable 接口创建MyCallable 线程public class MyCallable implements Callable<String> {private String name;//通过构造函数,以定义线程的名称public MyCallable(String name) {this.name = name;}@Overridepublic String call() throws Exception {return name;}public static void main(String[] args) throws ExecutionException, InterruptedException {// step 2 创建一个固定大小为5的线程池ExecutorService pool = Executors.newFixedThreadPool(5);//step 3 创建多个有返回值的任务列表listList<Future> list = new ArrayList<Future>();for (int i = 0; i < 5; i++) {//step 4 创建一个有返回值的线程实例final MyCallable c = new MyCallable(i + " ");//step5 提交任务,获取future 对象并将其保存到 Future list中。final Future<String> future = pool.submit(c);System.out.println("submit a callable thread " + i);list.add(future);}//step 6 关闭线程池,等待线程执行结束pool.shutdown();//step 7 遍历所有线程的运行结果for (Future future : list) {//从future中取出结果System.out.println("get the result from callable thread :" + future.get().toString());}}}
3.2 线程池的工作原来
Java线程池主要用于管理线程组以及其运行状态,以便Java虚拟机更好地利用CPU资源。Java线程池的工作原理为:JVM先根据用户的参数创建一定数量的可运行的线程任务,并将其放入队列中,在线程创建后启动这些任务,如果正在运行的线程数据超过了最大线程数量(用户设置的线程池大小),则超出数量的线程排队等候,在有任务执行完毕后,线程池调度器会发现有可用的线程,进而再次从队列中取出任务并执行。
线程池的主要作用是线程复用,线程资源管理、控制操作系统的最大并发,以保证系统高效(通过线程资源的复用实现)且安全(通过控制最大线程并发数实现)地运行。
3.2.1 线程复用
在Java中,每个Thread类都有一个start方法。在程序调用start方法启动线程时,Java虚拟机会调动该类的run方法。在Thread类的run方法中其实调用了Runnable对象的run方法,因此可以继承Thread类,在start方法中不断循环调用传递进来的Runnable对象,程序就不断执行runn方法中的代码。可以将在循环方法中不断获取的Runnable对象存放在Queue中,当前线程在获取下一个Runnable对象之前可以是阻塞的,这样既能有效控制正在执行的线程个数,又能保证系统中正在等待执行的其他线程有序执行,这样就简单实现了一个线程池,达到了线程复用的效果。
3.2.3 Java线程池的工作原理
Java线程池的工作流程为:线程池刚被创建时,只是向系统申请一个用于执行线程队列和管理线程池的线程资源。在调用execute添加一个任务时,线程池会按照以下流程执行任务。
- 如果正在运行的线程数量少于corePoolSize(用户定义的核心线程数),线程池就会立刻创建线程并执行该线程任务。
- 如果正在运行的线程数量大于等于corePoolSize,该任务就将被放入阻塞队列中。
- 在阻塞队列已满且正在运行的线程数量少于maximumPoolSize时,线程池会创建非核心线程立刻执行该线程任务。
- 在阻塞队列已满且正在运行的线程数量大于等于maximumPoolSize时,线程池将拒绝执行该线程并抛出RejectExcuionException异常。
- 在线程任务执行完毕后,该任务将从线程池队列中移除,线程池从队列中取出下一个线程任务继续执行。
- 在线程处于空闲状态的时间超过keepAliveTime时间时,正在运行的线程数量超过corePoolSize,该线程将会被认定为空闲线程并停止,因此在线程池中所有线程都执行完毕后,线程池会收缩到corePoolSize大小。
3.2.4 线程池的拒绝策略
若线程池中的核心线程数被用完且阻塞队列已排满,则此时线程资源已经耗尽,线程池没有足够的线程资源执行新的任务。为了保证操作系统的安全,线程池将通过拒绝策略处理新添加的任务。JDK内置的拒绝策略。AbortPolicy、CallerRunsPolicy(new ThreadPoolExecutor.CallerRunsPolicy())、DiscardOldestPolicy、DiscardPolicy这四种,默认的拒绝策略在ThreadPoolExecutor 中作为内部类提供。在默认的拒绝策略不能满足需求时,可以自定义拒绝策略。
- AbortPolicy
直接抛出异常,阻止小线程正常运行。
- CallerRunsPolicy
如果被丢弃的线程任务未关闭,则执行线程任务。
- DiscardOldestPolicy
移除线程队列中最早的一个线程任务,并尝试提交当前任务。
- DiscardPolicy
丢弃当前的线程任务而不做任何处理。如果系统允许在资源不足的情况下丢弃部分任务,则这将是保障系统安全、稳定的一种很好的方案。
- 自定义拒绝策略
public class DiscardOldestPolicy implements RejectedExecutionHandler {
//自定义拒绝策略:尝试丢弃最古老的N个线程,以便在出现异常时释放更多的资源,保障后续线程任务整体、稳定地运行。
private int discardNumber = 5;
private List<Runnable> discardList = new ArrayList<>();
public DiscardOldestPolicy(int discardNumber) {
this.discardNumber = discardNumber;
}
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (e.getQueue().size() > discardNumber) {
//step 1 批量移除线程队列的 discardNumber 个线程任务。
e.getQueue().drainTo(discardList, discardNumber);
//step 2 清空 discardList
discardList.clear();
if (!e.isShutdown()) {
//step 3 尝试提交当前任务
e.execute(r);
}
}
}
}
3.3 5种常用的线程池
| 名称 | 说明 |
|---|---|
| newCachedThreadPool | 可缓存的线程池 |
| newFixedThreadPool | 固定大小的线程池 |
| newScheduledThreadPool | 可做任务调度的线程池 |
| newSingleThreadExecutor | 单个线程的线程池 |
| newWorkStealingPool | 足够大小的线程池,JDK1.8新增 |
3.3.1 newCachedThreadPool
用于创建一个缓存线程池。之所以叫做缓存线程池,是因为它在创建新线程是如果有可重用的线程,则重用它们,否则重新创建一个新的线程并将其添加到线程池中。对于执行任务很短的任务而言,newCachedThreadPool线程池能很大程度地重用线程进而提高系统的性能。
在创建线程是需要执行申请CPU和内存、记录线程状态、控制阻塞等多项工作,复杂且耗时。因此,在有执行时间很短的大量任务需要执行的情况下,newCachedThreadPool能够很好地复用运行中的线程资源来提供运行效率。
final ExecutorService threadPool = Executors.newCachedThreadPool();
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
3.3.2 newFixedThreadPool
用于创建固定线程的线程池,并将线程资源存放在队列中循环使用。在该线程池中,若处于动动状态的线程数量大于等于核心线程的数量,则新提交的任务将在阻塞队列中排队,直到有可用的线程资源。
Executors.newFixedThreadPool(5);
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
3.3.3 newScheduledThreadPool
创建一个可定时调度的线程池,可设置在给定的延迟时间后执行或者定期执行某个线程任务
//任务调度
final ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
//1 创建一个延迟3秒执行的线程
scheduledThreadPool.schedule(new Runnable() {
@Override
public void run() {
System.out.println("delay 3 seconds exec.");
}
}, 3, TimeUnit.SECONDS);
//2 创建一个 延迟1 秒执行 且每 3秒执行一次的线程
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println("delay 1 second,repeat execute every 3 seconds");
}
},1,3,TimeUnit.SECONDS);
3.3.4 newSingleThreadExecutor
该线程池会保证永远有且只有一个可用的线程,在该线程停止或发生异常是,该线程池会启动一个新的线程来代替该线程继续执行任务。
3.3.5 newWorkStealingPool
创建保持足够线程的线程池来达到快速计算的目的,在内部通过多个队列来减少各个线程调度产生的竞争。这里所说的有足够的线程JDK根据当前线程的运行需求想操作系统申请足够的线程,以保障线程的快速执行,并最大程度地使用系统资源,提供并发计算的效率,省去用户根据CPU资源估算并行度的过程。
3.4 线程的生命周期
线程的的生命周期分为新建、就绪、运行、阻塞、死亡这5种状态。在系统运行过程中不断有新的线程被创建,就线程执行完毕后被清理,线程在排队获取共享资源或锁时被阻塞,因此运行中的线程会在就绪、阻塞、运行状态之间来回切换。
流程如下
- 调用new 方法创建一个线程,这时线程处于新建状态
- 调用start方法启动一个线程,这时线程处于就绪状态。
- 处于就绪状态的线程等待线程获取CPU资源,在等待期获取CPU资源后线程会执行run方法进入运行状态。
- 正在运行的线程在调用了yield方法或失去处理器资源时,会再次进去就绪状态。
- 正在执行的线程执行了sleep方法、I/O阻塞,等待同步锁,等待通知,调用suspend方法等操作后,会挂起并进去阻塞状态,进入Blocked池。
- 阻塞状态的线程由于出现sleep时间已到,I/O方法返回,获得同步锁、收到通知,调用resume方法等情况,会再次进入就绪状态,等待CPU时间片的轮询。该线程在获取CPU资源后,会再次进入运行状态。
- 处于运行状态的线程,在调用run方法或call方法正常执行完成,调用stop方法停止或程序执行错误导致异常退出,会进入死亡状态。
3.4.1 新建状态:new
使用new关键字创建一个线程,新创建的线程将处于新建状态。在创建线程是主要是分配内存并初始化器成员变量的值。
3.4.2 就绪状态 Runnable
新建的线程对象在调用start方法之后将转化为就绪状态,此时JVM完成了方法调用栈和程序计数器的创建,等待该线程的调度和运行。
3.4.3 运行状态 Running
就绪状态的线程在竞争到CPU的使用权并开始执行run方法的线程执行体,会转为运行状态,处于运行状态的线程的主要任务就是执行run方法中的逻辑代码。
3.4.4 阻塞状态:Blocked
运行中的线程会主动或被动地放弃CPU使用权限并暂停运行,此时该线程将转化为阻塞状态,直到再次进入可运行状态。,才有机会再次竞争到CPU使用权并转为运行状态。阻塞的状态分为以下三种。
- 等待阻塞:在运行状态的线程调用o.wait方法时,JVM会把该线程放入等待队列(waitting Queue)中,线程转为阻塞状态。
- 同步阻塞:在运行状态的线程尝试获取正在被其他线程占用的对象同步锁时,JVM会把该线程池放入锁池(Lock Pool)中,此时线程转为阻塞状态。
- 其他阻塞:运行状态的线程在执行Thread.sleep、Thread.join 或者发出I/O请求时,JVM会把该线程转为阻塞状态。直到sleep状态超时,Thread.join等待线程终止或超时,或者I/O处理完毕,线程才重新转为可运行状态。
3.4.5 线程死亡:Dead
线程在以下三种方式结束后转为死亡状态
- 线程正常结束:run方法或call方法执行完成
- 线程异常退出:运行中的线程抛出一个error或者未捕获的Exception,线程异常退出
- 手动结束:调用线程对象的stop方法手动结束运行中的线程(该方式会瞬间释放线程占用的同步对象锁,导致锁混乱和死锁,不推荐使用)
3.5 线程的基本方法
3.5.1 线程等待:wait方法
调用wait方法的线程会进入WAITING转态,只有等到其他线程的通知或被中断后才会返回。需要注意的是,在调用wait方法后会释放对象的锁,因此wait 方法一般被用于同步方法或同步代码块中。
3.5.2 线程睡眠:sleep
调用sleep方法会导致当前线程休眠。与wait不同的是,sleep方法不会释放点前对象的锁,会导致线程进去TIMED-WATING状态,而wait方法会导致当前线程进入waiting状态。
3.5.3 线程让步:yield
调用yield方法会使当前线程让出(释放)CPU执行时间片,与其他线程一起重新竞争CPU时间片。
3.5.4 线程中断:interrupt
interrupt方法用于向线程发送一个终止通知信号,会影响该线程内部的一个中断标识位,线程本身并不会因为调用了interrupt方法而改变状态(阻塞,终止等)。线程的具体变化需要等待接受到中断标识的程序最终处理结果来判定。对应interrupt的理解需要注意以下4个核心点:
- 调用interrupt方法并不会中断一个正在运行的线程,也就是说处于running状态的线程并不会因为调用了interrupt方法而终止,仅仅改变了内部维护的中断标识位而已。
- 若因为调用sleep方法而是线程处于TIMED-WATING状态,则这时调用interrupt方法会抛出InterruptedException,使线程提前结束TIMED-WATING状态。
- 许多声明抛出InterruptedException的方法如Thread.sleep,在抛出异常钱都会清除中断标识,所以在抛出异常后调用interrupted方法会返回false。
中断状态是线程固有的一个标识位,可以通过次标识位安全终止线程。比如:想终止一个线程时,可以先调用线程的interrupt方法,然后在线程的run方法中根据线程isInterrupted方法的返回状态值安全终止线程。
public class SafeInterruptThread extends Thread { @Override public void run() { if (!Thread.currentThread().isInterrupted()) { try { //1 这里处理正常的线程业务逻辑 sleep(1000); } catch (InterruptedException e) { //重新设置中断标识 System.out.println("重新设置中断标识"); Thread.currentThread().interrupt(); } } if (Thread.currentThread().isInterrupted()) { //2 处理线程结束前必要的一些资源释放和清理工作,比如释放锁,存储数据到持久化、发出异常通知,用于实现线程安全退出 // sleep(10); } } public static void main(String[] args) throws InterruptedException { //3 定义一个可安全退出的线程 final SafeInterruptThread thread = new SafeInterruptThread(); thread.start(); TimeUnit.MILLISECONDS.sleep(500); thread.interrupt(); } }
3.5.5 线程加入:join
join方法用于等待其他线程终止,如果在当前线程中调用一个线程join方法,则当前线程会转化为阻塞状态,等到另一个线程结束,当前线程再由阻塞状态转为就绪状态,等待获取CPU使用权。在很多情况下,主线程生成并启动了子线程,需要等到子线程返回结果并收集和处理再退出,这时就用到了join方法。
3.5.6 线程唤醒:notify
这时Object 上的方法,用于唤醒再次对象监视器上等待的一个线程,如果所有线程都在此对象上等待,则会选择唤醒其中一个线程,唤醒是选择是任意的。
我们通常调用其中一个对象的wait方法在对象的监视器上等待,直到当前线程放弃次对象上的锁定。才能继续执行被唤醒的线程,被唤醒的线程将以常规方式与在该对象上主动同步的其他线程竞争。类似的方法还有notifyAll,用于唤醒在监视器上等待的所有线程。
3.5.7 手台守护线程:setDaemon方法
3.5.8 sleep方法与wait方法的区别
- sleep方法属于Thread类,wait方法属于Object类
- sleep方法暂停执行指定时间,让出CPU给其他线程,但其监控状态依然保持,在指定的时间过后又自动恢复运行状态
- 在调用sleep方法的过程时,线程不会释放对象锁。
- 在调用wait方法时,线程会放弃对象锁,进入等待次对象的等待锁池,只有针对次对象调用notify方法后,该线程才能进入对象锁池获取对象锁,并进入运行状态。
3.5.9 start方法与run方法的区别
- start方法用于启动线程,真正实现了多线程运行。在调用线程的start方法后,线程会在后台执行,无需等待run方法体的代码执行完毕,就可以继续执行下面的代码。
- 在通过调用Thread类的start方法启动一个线程时,此线程就是就绪状态,并没有运行。
- run方法也叫作线程体。包含了要执行的线程的逻辑代码,在调用run方法后,线程会进入运行状态,开始运行run方法中的代码。在run方法运行结束后,该线程终止。CPU再次调度其他线程。
3.5.10 终止线程的4种方式
- 正常运行结束
- 使用退出标志退出线程
比如设置一个Boolean类型的标志
- 使用interrupt方式终止线程
使用interrupt方法终止线程有以下两种情况。
- 线程处于阻塞状态。例如在使用sleep、调用锁的wait或者调用socket的receiver accpet等方法,会使线程处于阻塞状态。在调用线程的interrupt方法时,会抛出InterruptedException异常。我们通过在代码中捕获异常,然后通过break跳出状态检测循环,结束这个线程的执行。通常我们很多人认为只要调用interrupt方法就会结束线程,这实际上理解有误,一定要想捕获InterruptedException异常再通过break跳出循环,才能正常结束run方法。 ```java import org.joda.time.DateTime; import java.util.concurrent.TimeUnit;
public class ThreadSafe extends Thread { @Override public void run() { //在非阻塞过程中判断中断标志来退出 while (!isInterrupted()) { try { //在阻塞过程中捕获中断异常来退出 TimeUnit.SECONDS.sleep(1); System.out.println(new DateTime().toString(“yyyy-MM-dd HH:mm:ss”)); } catch (InterruptedException e) { e.printStackTrace(); //捕获到异常后执行break跳出循环 break; } } }
public static void main(String[] args) throws InterruptedException {
final ThreadSafe safe = new ThreadSafe();
safe.start();
TimeUnit.MILLISECONDS.sleep(500);
safe.interrupt();
}
}
2. 线程处于阻塞状态。此时,使用isInterrupted方法判断线程的中断标识来退出循环,在调用interrupt方法时,中断标识会被设置为true。此时并不能立刻退出线程,而是需要执行终止前的资源释放操作,等待资源释放完毕后方可安全退出线程。
<a name="F4ruH"></a>
## 3.6 Java中的锁
保障同一个时刻只有一个线程持有该对象的锁并修改对象,从而保障了数据的安全。<br />锁从乐观和悲观的角度可以分为乐观锁和悲观锁,从后去资源的公平性角度可以分为公平锁和非公平锁,从是否共享资源的角度可以分为共享锁和独占锁,从锁的状态角度可以分为偏向锁、轻量级锁和重量级锁。同时JVM还巧妙设计了自旋锁以更快地使用CPU资源。
<a name="i1Omq"></a>
### 3.6.1 乐观锁
乐观锁采用乐观的思想处理数据,在每次读取数据时都任务别人不会修改数据,所以不用加锁,但在更新时会判断再次期间别没有更新该数据,通常采用在写时先读出当前版本号然后加锁的方法。具体过程为:比较当前版本号与上一次的版本号,如果版本号一致,则更新,如果版本号不一致,则重复进行读取,比较、写操作。<br />Java中的乐观锁大部分是通过CAS操作实现的,CAS是一种原子更新操作,在对数据操作之前首先会比较当前值跟传入的值是否一样,如果一样则更新,否则不执行更新操作,直接返回失败状态。
<a name="hAkRZ"></a>
### 3.6.2 悲观锁
采用悲观思想处理数据,在每次读取数据是都认为别人会修改数据,所以每次在读写数据时都会加锁,这样别人想读写这个数据时都会阻塞,等到直到获取锁。
Java悲观锁大部分基于AQS(Abstract Queued Synchronized,抽象的队列同步器)结构实现。AQS定义了一套多线程访问共享资源的同步框架,许多同步类的实现都依赖于它,例如常用synchronized、ReentrantLock、Semaphore、CountDownLatch等。该框架的锁先尝试以CAS乐观锁去获取锁,如果获取不到,则会转为悲观锁(如 RetreenLock)
<a name="E1dj0"></a>
### 3.6.3 自旋锁
自旋锁认为:如果持有锁的线程能够在很短的时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞、挂起状态。只需要等一等(也叫作自旋),在等待持有锁的线程释放锁后即可立即获取锁,这样避免了用户线程在用户态和内核态之间的频繁切换而导致的时间消耗。
线程在自旋时会占用CPU,在线程长时间自旋获取不到锁,将会产生CPU的浪费,甚至有时线程永远无法获取锁而导致CPU资源永久占用,所以需要设定一个自旋等待的最大时间。在线程执行的时间超过自旋等待的最大时候后,线程会退出自旋模式并释放其持有的锁。
<a name="KIGCr"></a>
#### 1 自旋锁的优缺点
- 优点:可以减少CPU上下文切换,对于占用锁的时间非常短或锁竞争不激烈的代码块来说性能大幅度提升,因为自旋锁的CPU耗时明显少于线程阻塞、挂起,再唤醒时两次CPU上下文切换所用的时间。
- 缺点:在持有锁的线程占用锁时间过长或锁竞争过于激烈是,线程在自旋过程中长时间获取不到锁资源,因此CPU的浪费。所以系统中有复杂锁依赖的情况下不适合采用自旋锁。
<br />
<a name="uvkg3"></a>
#### 2 自旋锁的时间阀值
自旋锁用于使用当前线程占着CPU的资源不释放,等到下次自旋锁获取锁资源后立即执行相关操作,但是如何选择自旋的执行时间呢?如果自旋的执行时间太长,则会有大量的线程处于自旋锁状态占用CPU资源,造成系统资源浪费,因此,对自旋的周期选择将直接影响到系统的性能。<br />JDK的不同版本采用的自旋锁周期不同,JDK1.5为固定时间,JDK1.6引入了适用性自旋锁。适应性自旋锁的自旋时间不再是固定值,而是由上一次在同一个锁的自旋时间以及锁的拥有者状态来决定。基本上可以认为一个线程上下文切换的时间就是也给自旋锁的最佳时间。
<a name="C4Jqa"></a>
### 3.6.4 synchronized
synchronized关键字用于Java对象、方法、代码块提供线程安全的操作。synchronized属于独占式的悲观锁,同时属于可重入锁。在使用synchronized修饰方法,代码块时,同一时刻只能有一个线程执行该方法体和代码块,其他线程只有等待当前线程执行完毕并释放锁资源后才能访问该对象或执行同步代码块。
<a name="ihS2p"></a>
#### 1 synchronized的作用范围
作用范围如下
- 作用于成员变量和非静态方法时,锁住的是对象的实例,即this对象
- 作用于静态方法时,锁住的是Class实例,因为静态方法属于Class而不属于对象
- 所用与一个代码块时,锁住的是所有代码块中配置的对象。
<a name="6ZPMm"></a>
#### 3 synchronized实现原理
在synchronized内部包括包括了ContentionList、EntryList、WaitSet、OnDeck、Owner 、!Owner 六个区域,每个区域都代表锁的不同状态。
- ContentionList:锁竞争队列,所有请求锁,所有请求锁的线程都放在竞争队列中。
- EntryList:竞争候选队列,在Contention List 中有资格成为候选者来竞争锁资源的线程被移动到了Entry List中
- WaitSet:等待集合,调用wait方法后阻塞的线程被放在waitset中。
- OnDeck:竞争候选者,在同一时刻最多只有一个线程在竞争锁资源,该线程的状态被称为OnDeck。
- Owner:竞争到锁资源的线程被称为Owner状态线程
- !Owner:在Owner线程释放锁后,会从Owner的状态变为!Owner
synchronized在收到新的锁请求时首先自旋,如果通过自旋也没有获取锁资源,则将被放入锁竞争队列中。<br />为了防止锁竞争是ContentionList尾部的元素被大量的并发线程进行CAS访问而影响性能,Owner线程会在释放锁资源时将ContentionList中的部分线程移动到EntryList中,并指定EntryList中的某个线程为OnDeck线程,Owner线程并没有直接把锁传递给OnDeck线程,而是把锁竞争的权利交给OnDeck,让OnDeck,线程重新竞争锁。在Java中把该行为称为“竞争切换”,该行为牺牲了公平性,但提高了性能。<br />获取到锁资源的OnDeck线程为变为Owner线程,而为获取到锁资源的线程仍然停留在EntryList中。<br />Owner线程在被wait方法阻塞后,会被转移到WaitSet队列中,直到某个时候被notify方法或者notifyAll方法唤醒,会再次进入EntryList中,COntentionList EntryList WaitSet中的线程均为阻塞状态,该阻塞是由操作系统来完成的。
synchronized是一个重量级操作,需要调用操作系统的相关接口,性能较低,给线程加锁的时候可能超过获取锁后具体逻辑代码的操作时间。<br />JDK1.6对synchronized做了很多优化,引入了适应自旋,锁消除,锁粗化,轻量级锁以及偏向锁等提高锁的效率。锁可以从偏向锁升级到轻量级锁,在升级到重量级锁,这种升级过程叫做锁膨胀。
<a name="vu0UT"></a>
### 3.6.5 ReentrantLock
ReentrantLock继承了Lock并实现了在接口同定义的方法,是一个可重入的独占锁,ReentrantLock通过自定义队列同步器(Abstract Queued Synchronized。AQS) 来实现锁的获取与释放。<br />独占锁指该锁在同一时刻只能被一个线程获取,而获取锁的其他线程只能在同步队列中等待;可重入锁指的是该锁支持一个线程对同一个资源执行多次加锁操作。<br />ReentrantLock支持公平锁和非公平锁。公平指线程竞争锁的机制是公平的。<br />ReentrantLock不但提供了synchronized对锁的操作功能,还提供了诸如可响应中断锁,可轮训锁请求,定时锁等避免多线程死锁的方法。
<a name="DpSuz"></a>
#### 1 ReentrantLock用法
```java
public class ReentrantLockDemo implements Runnable {
//step 1 定义一个 ReentrantLock
private static final ReentrantLock lock = new ReentrantLock();
private static int i = 1;
@Override
public void run() {
for (int j = 0; j < 10; j++) {
//step 2 加锁
lock.lock();
// 可重入锁
// lock.lock();
try {
i++;
} finally {
//step 3 释放锁
lock.unlock();
// 可重入锁
// lock.unlock();
}
}
}
public static void main(String[] args) throws InterruptedException {
final ReentrantLockDemo lockDemo = new ReentrantLockDemo();
final Thread thread = new Thread(lockDemo);
thread.start();
thread.join();
System.out.println(i);
}
}
ReentrantLock之所以被称为可重入锁,是因为ReentrantLock锁可以反复进入,即允许连续两次获得同一把锁,两次释放同一把锁。注意:获取锁和释放锁的次数要相同,如果释放锁的次数多余获取锁的次数,Java会抛出IllegalMonitorStateException异常;如果释放锁的次数少于获取锁的次数,该线程就会一直持有该锁,其他线程将无法获取锁资源。
2 ReentrantLock如何避免死锁:响应中断、可轮训锁,定时锁
- 响应中断:在synchronized中如果有一个线程尝试获取一把锁,则其结果是要么获取锁继续执行,要么保持等待,ReentrantLock还提供了可响应中断的可能,即在等待锁的过程中,线程可以根据需要取消对锁的请求。 ```java import java.util.concurrent.TimeUnit; import java.util.concurrent.locks.ReentrantLock;
public class InterruptiblyLock { //step 1 第一把锁1 private static final ReentrantLock lock1 = new ReentrantLock(); //step2 第二把锁2 private static final ReentrantLock lock2 = new ReentrantLock();
public Thread lock1() {
final Thread t = new Thread(() -> {
try {
//step 3 如果当前线程未被中断,则获取锁
lock1.lockInterruptibly();
// step 4 执行具体业务逻辑
TimeUnit.MILLISECONDS.sleep(500);
lock2.lockInterruptibly();
System.out.println(Thread.currentThread().getName() + " 执行完毕!");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//step 5 在业务逻辑执行结束后 检查当前线程是否持有该锁,如果持有则释放该锁
if (lock1.isHeldByCurrentThread()) {
lock1.unlock();
}
if (lock2.isHeldByCurrentThread()) {
lock2.unlock();
}
System.out.println(Thread.currentThread().getName() + " 退出");
}
});
t.start();
return t;
}
public Thread lock2() {
final Thread t = new Thread(() -> {
try {
//step 3 如果当前线程未被中断,则获取锁
lock2.lockInterruptibly();
// step 4 执行具体业务逻辑
TimeUnit.MILLISECONDS.sleep(500);
lock1.lockInterruptibly();
System.out.println(Thread.currentThread().getName() + " 执行完毕!");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//step 5 在业务逻辑执行结束后 检查当前线程是否持有该锁,如果持有则释放该锁
if (lock1.isHeldByCurrentThread()) {
lock1.unlock();
}
if (lock2.isHeldByCurrentThread()) {
lock2.unlock();
}
System.out.println(Thread.currentThread().getName() + " 退出");
}
});
t.start();
return t;
}
public static void main(String[] args) {
final long time = System.currentTimeMillis();
final InterruptiblyLock interruptiblyLock = new InterruptiblyLock();
final Thread thread1 = interruptiblyLock.lock1();
final Thread thread2 = interruptiblyLock.lock2();
//自旋一段时间,如果等待时间过长,则可能发生了死锁等问题,主动中断并释放锁
while (true) {
if (System.currentTimeMillis() - time >= 3000) {
thread2.interrupt();//中断线程1
}
}
}
}
以上代码,线程thread1 和线程thread2启动后,thread1先占用lock1,在占用lock2,thread2则先占用lock2,后占用lock1,这便形成了thread1和thread2之间的相互等待,在两个线程都启动时便处于死锁状态,在while循环中,如果等待时间过长(这里设定了3s),则可能发生了死锁等问题,thread2就会中断中断(interrupt),释放锁lock1的申请,同时释放以获得的lock2,让thread1顺利获得lock2,继续执行下去,输出结果如下:
```java
java.lang.InterruptedException
……
Thread-1 退出
Thread-0 执行完毕!
Thread-0 退出
- 可轮训锁:通过boolean tryLock()获取锁,如果有可用锁,则获取该锁并返回true,如果无可用锁,则立即返回false。
- 定时锁:通过
boolean tryLock(long timeout, TimeUnit unit) throws InterruptedException获取定时锁,如果在给定时间内获取到了可用锁,且当前线程未被中断,则获取该锁并返回true,如果在给定时间内获取不到可用锁,将禁用当前线程,并且发生一下三种情况之前,该线程一直处于休眠状态。
- lock:给对象加锁,如果锁未被其他线程使用,则当前线程将获取该锁;如果锁正在被其他线程使用,则将阻塞等待,直到当前线程获取该锁。
- tryLock:和lock的区别只是“试图”获取锁,如果没有可用锁,就会立即返回,lock在锁不可用时会一直等待。
- tryLock_(_long timeout, TimeUnit unit):创建锁时,如果在给定的等待时间内有可用锁,则获取该锁。
- unlock:释放当前线程所持有的锁。锁只能由持有者释放。如果当前线程并不持有该锁却执行此方法,则抛出异常
- newCondition:创建条件对象,获取等待通知组件。该组件和当前锁绑定,当前线程只有获取了锁才能调用该组件的await,在调用后当前线程将释放锁。
- getHoldCount:查询当前线程保持次锁的次数,也就是线程执行了lock方法的次数。
- getQueuedThreads:返回等待获取次锁的线程估计数,比如启动5个线程,1个线程获取锁,此时返回4。
- getWaitQueueLength:返回在Condition条件下等待该锁的线程数量。
- isHeldByCurrentThread:查询当前线程是否持有该锁,
- lockInterruptibly:如果当前线程未被中断,则获取该锁。
4 公平锁和非公平锁
公平锁指所得分配和竞争机制是公平的,遵循先到先得原则。非公平锁指JVM遵循随机、就近原则分配锁的机制。
ReentrantLock默认是非公平锁,这是因为,非公平锁虽然放弃了锁的公平性,但是执行效率明显高于公平锁。
5 tryLock、lock、lockInterruptibly
三者的区别如下
- tryLock若有可用锁,则获取该锁并返回true,否则返回false,不会有延迟或等待,
- lock 若有可用锁则获取该锁并返回true,否则会一直等待直到获取可用锁。
在锁中断时lockInterruptibly会抛出异常,lock不会。
3.6.5 synchronized和ReentrantLock的比较
两者共同点:
都用于控制多线程对共享对象的访问
- 都是可重入锁
- 都保证了可见性和互斥性
不同点如下:
- ReentrantLock显示获取锁和释放锁;synchronized隐式获取和释放锁。为了避免程序出现异常而无法正常释放锁,在使用ReentrantLock时必须在finally语句块中执行释放锁操作。
- ReentrantLock 可响应中断,可轮回,为处理所提供了更多的灵活性
- ReentrantLock是API级别的,synchronized是JVM级别的。
- ReentrantLock可以定义为公平锁
- ReentrantLock通过Condition可以绑定多个条件
- 二者的底层实现不一样:synchronized是同步阻塞,采用的是悲观并发策略;lock是同步非阻塞,采用的是乐观并发策略
- lock是一个接口,而synchronized是Java中的关键字,synchronize是由内置的语言实现的。
- 我们通过Lock可以知道有没有成功获取锁,通过synchronized却无法做到。
- Lock可以通过分别定义读写锁提高多个线程读操作的效率。
3.6.7 Semaphore
Semaphore 是一种基于计数的信号量,在定义信号量对象时可以设定一个阀值,基于该阀值,多个线程竞争获取许可信号,线程竞争到许可静好后开始执行具体的业务逻辑,业务逻辑在执行完成后释放许可信号。在许可信号的竞争队列超过阀值后,新加入的申请许可信号的线程将被阻塞,直到有其他许可信号被释放。基本用法如下
public void demo(){
// step 1 创建一个计数阀值为5的信号量对象,即只能有5个线程同时访问
final Semaphore semp = new Semaphore(5);
try {
//step 2 申请许可
semp.acquire();
try {
// step 3 执行业务逻辑
}catch (Exception e){
}finally {
//step 4 释放许可
semp.release();
}
}catch (InterruptedException e){
}
}
Semaphore对锁的申请和释放和ReentrantLock类似,通过acquire方法和release方法来获取和释放许可信号资源。Semaphore.acquire方法默认和ReentrantLock.lockInterruptibly方法的效果一样,为可响应中断锁。也就是说等待许可信号资源的过程可以被Thread.interrupt方法中断而取消对许可信号的申请。
此外,Semaphore也实现了可轮询的锁请求,定时锁的功能。以及公平锁与非公平锁的机制。
Semaphore锁的释放操作也需要手动执行,因此,为了避免线程因执行异常而无法正常释放锁,释放锁的操作必须在finally代码块中完成。
3.6.8 AtomicInteger
在多线程中,诸如++i,i++等运算不具有原子性,因此不是安全的线程操作。我们可以通过synchronized或ReentrantLock将该操作变成一个原子操作,但是synchronized和ReentrantLock均属于重量级锁。因此JVM为此原子操作提供了一些原子操作同步类,使得同步操作更加方便,高效,它便是AtomicInteger.
AtomicInteger性能通常是synchronized和ReentrantLock的好几倍
3.6.9 可重入锁
可重入锁也叫递归锁,指在同一个线程中,在外层函数获取到该锁后,内层的递归函数仍然可以继续获取该锁。在Java环境下,ReentrantLock和synchronized都是可重入锁。
3.6.10 公平锁和非公平锁
- 公平锁:指在分配锁前检查是否线程在排队等待获取锁,优先将锁分配给排队时间最长的线程。
- 非公平锁:在分配锁时不考虑线程排队等待的情况,尝试直接获取锁,在获取不到锁时再排队队尾等待。
因为公平锁需要在多线程的情况下维护一个锁线程等待队列,基于该队列进行锁的分配,因此效率比非公平锁低很多。
3.6.11 读写锁:ReadWriteLock
在Java中通过Lock接口以及对象方便地为对象加锁和释放锁,但是这种锁不区分读写,叫做普通锁。为了提高性能,Java提供了读写锁。读写锁分为读锁和写锁两种,多个读锁不互斥,读锁与写锁互斥。在读的地方使用读锁,在写的地方使用写锁,在没有写锁的情况下,读是无阻塞的。
如果系统要求共享数据可以支持很多线程并发读,但不能支持很多线程并发写,那么使用读锁能很大程度地提高效率;如果系统要求共享数据在同一时刻只能有一个线程在写,且在写的过程中不能读取该共享数据,则需要使用写锁。
一般的做法是分别定义一个读锁和一个写锁,在读取共享数据时使用读锁,在使用完成后释放读锁,在写共享数据时使用写锁,在使用完成后完成释放写锁。
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class SafeCache {
private final Map<String, Object> cache = new HashMap<>();
private final ReentrantReadWriteLock rw = new ReentrantReadWriteLock();
// step 1 定义读锁
private final Lock readLock = rw.readLock();
// step 2 定义写锁
private final Lock writeLock = rw.writeLock();
//step 3 在读数据时加读锁
public Object get(String key) {
readLock.lock();
try {
return cache.get(key);
} finally {
readLock.unlock();
}
}
// step 4 在写数据时加写锁
public Object put(String key, Object value) {
writeLock.lock();
try {
return cache.put(key, value);
} finally {
writeLock.unlock();
}
}
}
3.6.12 共享锁和独山锁
Java并发包提供的加锁模式分为独占锁和共享锁。
- 独占锁:也叫作互斥锁,每次只允许一个线程持有个该锁,ReentrantLock为独占锁的实现
- 共享锁:允许多个线程同时获取该锁,并发访问共享资源,ReentrantReadWriteLock中的读锁为共享锁的实现。
ReentrantReadWriteLock 的加锁和解锁操作最终都调用内部类Sync提供的方法。Sync对象通过继承AQS(Abstract Queued Synchronized)实现。AQS的内部类Node定义了两个常量EXCLUSIVE SHARED,分别标识AQS队列中等待线程的锁获取模式。
独占锁是一种悲观的加锁策略,同一时刻只允许一个读线程读取锁资源,限制了读操作的并发性;因为并发读并不会影响数据的一致性,因此共享锁采用了乐观的加锁策略,允许多个执行读操作的线程同时访问共享数据。
3.6.13 重量级锁和轻量级锁
重量级锁是基于操作系统的互斥量(Mutex Lock)而实现的锁,会导致进程在用户态和内核态之间切换,相对开销较大。
synchronized在内部基于监视器锁(Monitor)实现,监视器锁基于底层的操作系统的Mutex Lock实现,因此synchronized属于重量级锁。重量级锁需要在用户态和和心态之间做切换,所以synchronized的效率不高。
JDK在1.6版本以后,为了减少获取锁和释放锁带来的性能消耗以及提高性能,引入了轻量级锁和偏向锁。
轻量级锁是相对重量级锁而言的。轻量级锁的核心设计是在没有多线程竞争的前提下,减少重量级锁的使用以提高系统性能。轻量级锁适用于线程交替执行同步代码块的情况(即互斥操作)。如果同一时刻有多个线程访问同一个锁,则将会导致轻量级锁膨胀为重量级别。
3.6.14 偏向锁
除了在多线程之间存在竞争获取锁的情况,还会经常出现同一个锁被同一个线程多次获取的情况。偏向锁用于在某个线程获取某个锁之后,消除这个线程锁重入的开销,看起来似乎是这个线程得到了该锁的偏向。
偏向锁的主要目的是在同一个线程多次获取某个锁的情况下尽量减少轻量级锁的执行路劲,因为轻量级锁的获取以及释放需要多次CAS原子操作,而偏向锁只需要在切换ThreadID时执行一次CAS原子操作,因此可以提高锁的运行效率。
在出现多线程竞争锁的情况下,JVM会自动撤销偏向锁,因此偏向锁的撤销操作的耗时必须少于节省下来的CAS原子操作的耗时。
综上所述,轻量级锁用于提高多个线程交替执行同步块时的性能,偏向锁则在某个线程交替执行同步块时进一步提高性能。
锁的状态总共4种:无锁,偏向锁、轻量级锁、和重量级锁。随着锁竞争越来越激烈,锁可能从偏向锁升级到轻量级锁,在升级到重量级锁,但在Java中锁只单向升级不会降级。
3.6.15 分段锁
分段锁并非一种实际的锁,而是一种锁设计思想,用于将数据分段并在每个分段上单独加锁,把锁进一步细粒度化,以提高并发效率。JDK1.7及以前版本的ConcurrentHashMap在内部就是使用分段锁实现的。
3.6.16 同步锁与死锁
在有多个线程同时被阻塞时,它们之间若相互等待对方释放锁资源,就会出现死锁,为了避免死锁,可以为锁添加超时时间,在线程持有锁超时后自动释放该锁。
3.6.16 如何进行锁优化
1 减少锁持有的时间
减少所锁持有的时间只有在线程安全要求的程序上加锁来尽量减少同步代码块对锁的持有时间。
2 减少锁粒度
减少锁粒度最典型的案例就是JDK1.7以及之前版本的ConncurentHashMap的分段锁
3 锁分离
常见的锁分离的思想就是读写锁。
操作分离思想可以进一步延伸为只要操作互补影响,就可以进一步拆分,比如LinkedBlockingQueue 从头部取出数据,并从尾部插入数据。
4 锁粗化
锁粗化指为了保证性能,会要求尽可能将锁的操作细化以减少线程持有锁的时间,但是如果锁分得太细,就会导致系统频繁获取锁和释放锁,反而影响性能的提升。在这种情况下,建议将关联性强的锁操作集中起来处理,以提高系统整体的效率。
5 锁消除
开发过程中会出现不需要使用锁的情况下误用了锁操作而引起性能下降。
3.7 线程上下文切换
CPU利用时间片轮询来为每个任务都服务一定的时间,然后把当前任务状态保存下来,继续服务下一个任务。任务的状态保存以及再加载的过程叫作线程的上下文切换。
- 进程:指一个运行中的程序的实例。正一个进程内部可以有多个线程同时运行,并与创建它的进程共享同一地址空间(一段内存区域)和其他资源。
- 上下文:指线程切换时CPU寄存器和程序计数器锁保存的当前线程的信息。
- 寄存器:指CPU 内部容量较小但速度很快的内存区域(与之对应的是CPU外部相对 较慢的RAM主内存)。寄存器通过对常用值(通常是运算的中间值)的快速访问来加快计算机程序的运行速度。
- 程序计数器:是一个专用的寄存器,用于表明指令序列中CPU正在执行的位置。存储的值为正在执行的指令的位置或下一个将被执行的和指令的位置,这依赖于特定的系统。
3.7.1 上下文切换
上下文切换指的是内核(操作系统的核心)在CPU上对进程或者线程进行切换。上下文切换过程的信息被保存在进程控制块中(PCB-Process Control BLock)。PCB又被称作切换帧。上下文切换的信息会一直被保存到CPU的内存中,直到再次使用,上下文切换的流程如下:
- 挂起一个线程,将这个线程在CPU中的状态(上下文信息)存储于内存的PCB中。
- 在PCB中检索下一个线程的上下文并将其在CPU寄存器中恢复。
- 跳转到程序计数器所指向的位置(即跳转到线程被中断时的代码行),并恢复该线程
3.7.2 引起上下文切换的原因
引起上下文切换的原因如下:
- 当前正在执行的任务完成,系统CPU正常调度下一个任务。
- 当前正在执行的任务遇到I/O等阻塞操作,调度器挂起次任务,继续调度下一个任务。
- 多个任务并发抢占锁资源,当前任务么有抢到锁资源,被调度器挂起,继续调度下一个任务。
- 用户的代码挂起当前任务,比如线程执行SLEEP方法,让出CPU
- 硬件中断。
3.8 Java阻塞队列
队列是一种只允许在表的前端进行的删除操作,而在表的后端进程插入操作的线性表。阻塞队列和一般队列不同之处在于阻塞队列是“阻塞”的,这里的阻塞指的是操作队列的线程的一种状态。在阻塞队列中,线程阻塞有如下两种情况:
- 消费者阻塞:在队里为空,消费者的线程都会被自动阻塞(挂起),直到有数据放入队列,消费者线程会被自动唤醒并消费数据。
- 生产者阻塞:在队列已满且没有可用空间时,生产者端的线程都会被自动阻塞(挂起),直到队列有空的位置腾出,线程会被自动唤醒并生成数据。
3.8.1 阻塞队列的主要操作
阻塞队列的主要操作有插入和移除。插入操作有add offer put ,移除操作有remove poll take
1 插入操作
(1)boolean add(E e)
将指定的元素插入队列中,在成功时返回true,如果当前没有可用的空间,则抛出IllegalStateException 如果元素是null,则抛出空指针异常。
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
(2)boolean offer(E e)
将指定的元素插入队列中,成功时返回true,如果没有可用的空间,则返回false.
public boolean offer(E e) {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
if (count == items.length)
return false;
else {
enqueue(e);
return true;
}
} finally {
lock.unlock();
}
}
(3)boolean offer(E e, long timeout, TimeUnit unit)
将指定的元素插入队列中,可用设定等待的时间,如果在等待的时间仍不能向队列中加入元素,则返回false。
(4)put(E e)
将指定的元素插入队列中,如果队列满了,则阻塞,等待可用的队列空间的释放,直到有可用的队列空间释放并且插入成功为止。
public void put(E e) throws InterruptedException {
Objects.requireNonNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
//阻塞等待可用空间的释放
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
2 获取队列
(1) poll
取走队列队首的对象,如果取不到数据,则返回null,
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
(2)poll(long timeout, TimeUnit unit)
取走队列队首的对象,如果在指定时间内队列有数据可获取,则返回队列中的元素,否则等待一段时间,在等待超时并且没有数据刻获取时,返回null.
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0) {
if (nanos <= 0L)
return null;
nanos = notEmpty.awaitNanos(nanos);
}
return dequeue();
} finally {
lock.unlock();
}
}
(3)take
取走队列队首的对象,如果队列为空,则进入阻塞状态等待,知道队列有新的数据被加入,在及时取出新加入的数据。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
(4)drainTo
一次性从队列中批量获取所有可用的数据对象,同时可用指定获取数据的个数,通过该方法可以提升获取数据的效率,避免多次频繁操作引起队列锁定。
3.8.2 Java中的阻塞队列实现
| 序号 | 名称 | 说明 |
|---|---|---|
| 1 | ArrayBlockingQueue | 基于数组结构实现的有界阻塞队列 |
| 2 | LinkedBlockingQueue | 基于链表结构实现的有界阻塞队列 |
| 3 | PriorityBlockingQueue | 支持优先级排序的无界阻塞队列 |
| 4 | DelayQueue | 基于优先级时点的无界阻塞队列 |
| 5 | SynchronousQueue | 用于控制互斥操作的阻塞队列 |
| 6 | LinkedTransferQueue | 基于链表结构实现的无界阻塞队列 |
| 7 | LinkedBlockingDeque | 基于链表结构实现的双向阻塞队列 |
1 ArrayBlockingQueue
ArrayBlockingQueue 是基于数组实现的有界阻塞队列,ArrayBlockingQueue队列按照先进先出原则对元素进行排序,在默认情况下不保证元素操作的公平性
队列操作的公平性指在生产者线程或消费者线程发生阻塞后再次被唤醒时,按照阻塞的先后顺序操作队列,即先阻塞的生产者优先向队列中插入元素,先阻塞的消费者线程先从队列中获取元素。因为保证公平性会降低吞吐量,所以如果要处理的数据没有先后顺序,则对其使用非公平处理的方式,
//大小为100 的公平队列
ArrayBlockingQueue fair = new ArrayBlockingQueue(100, true);
//大小为100 的非公平队列
ArrayBlockingQueue Nofair = new ArrayBlockingQueue(100, false);
2 LinkedBlockingQueue
LinkedBlockingQueue 是基于链表实现的阻塞队列,同ArrayListBlockingQueue类似,次队列按照先进先出原则对元素进行排序;LinkedBlockingQueue 对生产者端和消费者端分别采用了两个独立的锁来控制数据同步,我们可以将队列头部的锁理解为写锁,将队列尾部的锁理解为读锁。因此生产者和消费者可以基于各种独立的锁并行地操作队列中的数据,LinkedBlockingQueue队列的并发性能较高。
LinkedBlockingQueue linkedBlockingQueue = new LinkedBlockingQueue(100);
3 PriorityBlockingQueue
PriorityBlockingQueue是一个支持优先级的无界队列。元素在默认情况下采用自然顺序升序排列。可以自定义实现compareTo方法来指定元素进行排序规则,或者在初始化PriorityBlockingQueue时指定构造参数Comparator来实现对元素的排序。注意,如果两个元素的优先级相同,则不能保证元素的存储和访问顺序
public class Data implements Comparable<Data> {
private String id;
//排序字段
private Integer number;
public Integer getNumber() {
return number;
}
public void setNumber(Integer number) {
this.number = number;
}
@Override
public int compareTo(Data o) {
return this.number.compareTo(o.getNumber());
}
public void demo() {
//TODO 定义可排序的阻塞队列,根据data的number属性大小排序
final PriorityBlockingQueue<Data> data = new PriorityBlockingQueue<>();
}
}
4 DelayQueue
DelayQueue是一个支持延时获取元素的无界阻塞队列,底层采用PriorityQueue实现,DealyQueue队列中的元素必须实现Delayed接口,该接口定义了在创建元素时该元素的延迟时间,在内部通过为每个元素的操作加锁来保障数据的一致性,只有在延迟时间到后才能从队列中提取元素。可以将DelayQueue运用以下场景中。
- 缓存系统的设计:可以用DealyQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素,则表示缓存元素的有效期到了。
- 定人任务调度:使用DelayQueue保存即将执行的任务和任务时间,一旦从DelayQueue中获取元素,就表示任务开始执行,Java中的TimerQueue就是使用DelayQueue实现的。
在具体使用时,延迟对象必须先实现Delayed类并实现其getDelay方法和compareTo方法,才可以在延迟队列中使用。
public class DelayData implements Delayed {
//延迟队列排序字段
private Integer number;
// 设置队列5s延迟获取
private long delayTime;
public Integer getNumber() {
return number;
}
public void setNumber(Integer number) {
this.number = number;
}
@Override
public long getDelay(TimeUnit unit) {
return this.delayTime;
}
@Override
public int compareTo(Delayed o) {
DelayData compare = (DelayData) o;
return this.number.compareTo(compare.getNumber());
}
public static void main(String[] args) {
// 创建延迟队列
final DelayQueue<DelayData> queue = new DelayQueue<>();
// 实时添加数据
queue.add(new DelayData());
while (true) {
try {
final DelayData take = queue.take();
} catch (InterruptedException e) {
}
}
}
}
5 SynchronousQueue
SynchronousQueue是一个不存储元素的阻塞队列。SynchronousQueue 中的每个put操作必须等待take操作完成,否则不能继续向队列中添加元素。可以将SynchronousQueue看做一个“快递员”,它负责把生产者线程的数据直接传递给消费者,非常适用于传递场景,比如将一个线程中使用的数据传递给另一个线程使用。SynchronousQueue的吞吐量高于LinkedBlockingQueue和ArrayBlockingQueue。具体使用如下
public class SynchronousQueueDemo {
public static void main(String[] args) {
final SynchronousQueue<Integer> queue = new SynchronousQueue<>();
new Producter(queue).start();
new Customer(queue).start();
}
//生产者线程
static class Producter extends Thread {
SynchronousQueue<Integer> queue;
public Producter(SynchronousQueue<Integer> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
final int product = new Random().nextInt(1000);
queue.put(product);
System.out.println("product a data " + product);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(queue.isEmpty());
}
}
}
//消费者线程
static class Customer extends Thread {
SynchronousQueue<Integer> queue;
public Customer(SynchronousQueue<Integer> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
final Integer data = queue.take();
System.out.println("customer a data:" + data);
} catch (InterruptedException e) {
}
}
}
}
}
6 LinkedTransferQueue
LinkedTransferQueue是基于链表结构的无界阻塞TransferQueue队列,相对于其他阻塞队列,LinkedTransferQueue多了transfer tryTransfer 等方法
7 LinkedBlockingDeque
LinkedBlockingDeque是基于链表结构的双向阻塞队列,可以在队列的两端分别插入和移出元素操作。这样,在多线程同时操作队列时,可以减少一半的锁资源竞争,提高队列的操作效率。
在初始化LinkedBlockingDeque时,可以设置队列的大小以防止内存溢出,双向队列也常被用于工作窃取模式。
3.9 Java并发关键字
3.9.1 CountDownLatch
CountDownLatch位于java.util.concurrent包下,是也给同步工具类,允许一个或多个线程一起等待其他线程的操作执行完后在执行相关操作。
CountDownLatch基于线程计数器来实现并发访问控制,主要用于线程等待其他子线程都完毕后执行相关操作。
public static void main(String[] args) {
// step 1 定义大小为2的CountDownLatch
final CountDownLatch latch = new CountDownLatch(2);
new Thread(() -> {
try {
System.out.println("子线程1正在执行");
TimeUnit.SECONDS.sleep(3);
System.out.println("子线程1执行完毕");
//step 2 在子线程调用countDown 方法
latch.countDown();
} catch (Exception e) {
}
}).start();
new Thread(() -> {
try {
System.out.println("子线程2正在执行");
TimeUnit.SECONDS.sleep(3);
System.out.println("子线程2执行完毕");
//step 2 在子线程调用countDown 方法
latch.countDown();
} catch (Exception e) {
}
}).start();
System.out.println("等待两个子线程执行完毕");
try {
//step 3 等待子线程执行完毕
latch.await();
// step 4 子线程执行完毕,开始执行主线程
System.out.println("两个子线程执行完毕,继续执行主线程");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
3.9.2 CyclicBarrier
CyclicBarrier(循环屏障)是一个同步工具,可以实现让一组线程等待至某个状态 之后在全部同时执行。在所有的等待被释放之后,CyclicBarrier可以被重用。CyclicBarrier的运行状态叫做Barrier,在调用await方法后,线程就处于Barrier状态。
CyclicBarrier中最重要的方法是await方法,它有两种实现。
- public int await
- public int await_(_long timeout, TimeUnit unit) 设置一个超时时间,在超时时间后,如果还有未达到Barrier状态,则不再等待,让达到Barrier状态的线程继续执行后续操作。
CyclicBarrier的具体用法:
public static void main(String[] args) {
int N = 4;
// 定义 Cycicbarrier
final CyclicBarrier barrier = new CyclicBarrier(N);
for (int i = 0; i < N; i++) {
new BusinessThread(barrier).start();
}
}
static class BusinessThread extends Thread {
private CyclicBarrier cycicbarrier;
public BusinessThread(CyclicBarrier cycicbarrier) {
this.cycicbarrier = cycicbarrier;
}
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(5);
System.out.println("线程执行前准备工作完成,等待其他线程准备工作完成");
cycicbarrier.await();
System.out.println("所有线程准备工作均完成,执行下一项任务");
} catch (InterruptedException | BrokenBarrierException e) {
}
}
}
3.9.3 Semaphore
Semaphore指信号量,用于控制同时访问某些资源的线程个数,具体做法为通过调用acquire获取一个许可,如果没有许可,则等待,在许可使用完毕后通过release释放该许可,以便其他线程继续使用。
Semaphore常被用于多个线程需要共享有限资源的情况,比如办公室的打印机。
public static void main(String[] args) {
// step 1 设置线程数
int printNumber = 5;
// step 2 设置并发数
Semaphore semaphore = new Semaphore(2);
for (int i = 0; i < printNumber; i++) {
new Worker(i, semaphore).start();
}
}
static class Worker extends Thread {
private int num;
private Semaphore semaphore;
public Worker(int num, Semaphore semaphore) {
this.num = num;
this.semaphore = semaphore;
}
@Override
public void run() {
try {
//step 3 线程申请资源,
semaphore.acquire();
System.out.println("员工" + this.num + " 占用一个打印机");
TimeUnit.SECONDS.sleep(2);
System.out.println("员工" + this.num + " 打印完成,释放出打印机");
} catch (InterruptedException e) {
} finally {
// step 4 线程释放资源
semaphore.release();
}
}
}
CountDownLatch CyclicBarrier Semaphore区别
- CownDownLatch和CyclicBarrier都用于实现多线程之间的相互等待,但二者的关注点不同,CownDownLatch主要用于主线程等待其他子线程任务均执行完毕后在执行接下来的业务逻辑单元,而CyclicBarrier主要用于一组线程相互等待大家都到达某个状态后,再同时执行接下来的业务逻辑单元。此外,CountDownLatch是不可重用的,而CyclicBarrier是可以重用的
- Semaphore和Java中的锁功能类似,主要用于控制资源的并发访问。
3.9.4 volatile关键字的作用
3.10 多线程如何共享数据
在Java中进行多线程通信主要通过共享内存来实现的。共享内存主要有三个关注点:可见性、原子性、有序性。Java内存模型解决了可见性和有序性的问题。而锁解决了原子性的问题。在理想的情况下,我们希望做到同步和互斥来实现数据在多线程环境下的一致性和安全性。常用的实现多线程数据共享的方式有将数据抽象成一个类,并将这个数据的操作封装在类的方法中;将runnnable对象作为一个类的内部类,将共享数据作为这个类的成员变量。
3.10.1 将数据抽象成一个类,并将这个数据的操作封装在类的方法中
这种方式只需要在方法上加synchronized关键字即可做到数据的同步,具体的代码实现如下:
public class MyData {
//step 1 将数据抽象成Mydata,并将数据的操作(add dec)作为类的方法
private int j = 0;
public synchronized void add() {
j++;
System.out.println("线程" + Thread.currentThread().getName() + " j为:" + j);
}
public synchronized void dec() {
j--;
System.out.println("线程" + Thread.currentThread().getName() + " j为:" + j);
}
public int getData() {
return j;
}
static class AddRunnable implements Runnable {
MyData data;
// step 2 线程使用该类的对象并调用类的方法对数据进行操作
public AddRunnable(MyData data) {
this.data = data;
}
@Override
public void run() {
data.add();
}
}
static class DecRunnable implements Runnable {
MyData data;
public DecRunnable(MyData data) {
this.data = data;
}
@Override
public void run() {
data.dec();
}
}
public static void main(String[] args) {
final MyData myData = new MyData();
final AddRunnable addRunnable = new AddRunnable(myData);
final DecRunnable decRunnable = new DecRunnable(myData);
for (int i = 0; i < 2; i++) {
new Thread(addRunnable).start();
new Thread(decRunnable).start();
}
}
}
3.11 ConcurrentHashMap并发(JDK1.7及之前的版本)
在JDK1.7 以及之前版本中,ConcurrentHashMap和HashMap的实现方式类似,不同的是采用分段锁的思想支持并发操作,所以是线程安全的。
3.11.1 减小锁粒度
减小锁粒度指通过缩小锁定对象的范围来减少锁冲突的可能性,最终提高系统的并发能力。减小粒度是一种削弱多线程锁竞争的有效方法。ConcurrentHashMap并发下安全机制就是基于该方法实现的。
ConcurrentHashMap是线程安全的Map,对应HashMap而言,最重要的方法是get和set方法,如果为了线程安全对整个HashMap加锁,则可以得到线程安全的对象,但是加锁粒度太大,意味着同时只能有一个线程操作HashMap,在效率上会大打折扣,而ConcurrentHashMap在内部使用多个Segment,在操作数据时会给每个Segment都加锁,这样就通过减少锁粒度提高了并发性。
3.11.2 ConcurrentHashMap的实现
ConcurrentHashMap在内部细分为若干个小的HashMap,叫做数据段(Segment)。在默认情况下,一个ConcurrentHashMap被细分为16个数据段,对每个数据段的数据单独进行加锁操作,Segment的个数为锁的并发度。
ConcurrentHashMap是由Segment数组和HashEntry数组组成的,Segment继承了可重入锁(ReentrantLock),它在ConcurrentHashMap里扮演锁的角色。HashEntry则用于存储键值对数据。
在每一个ConcurrentHashMap里面包含一个Segment数组,Segment的结构和HashMap类似,是数组和链表结构。在每个Segment里都包含一个HashEntry数组,每个HashEntry都是一个链表结构,每个Segment都守护一个HashEntry数组里面的元素,再对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
在操作ConcurrentHashMap时,如果需要在其中添加一个新的数据,则并不是将整个HashMap加锁,而是先根据HashCode查询到该数据在应该被保存在哪个段,然后对应该段数据加锁并完成put操作,在多线程环境下,如果多个线程同时进行put操作,则只要加入的数据存放在不同的段中,在线程间就可以做到并行的线程安全。
3.12 Java中的线程调度
3.12.1 抢占式调度
抢占式调度是指每个线程都以抢占的方式获取CPU资源并快速执行,在执行完毕后立即释放CPU资源,具体哪些线程能抢占到CPU资源由操作系统控制,在抢占式调度模式下,每个线程对CPU资源的申请地址是相等,从概率上讲每个线程都有机会获得同样的CPU执行时间片并发执行。抢占式调度适用于多线程并发执行的情况,在这种机制下一个线程的阻塞不会导致整个进程性能的下降。
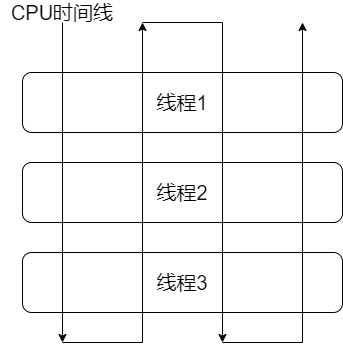
3.12.1 协同式调度
协同式调度指某一个线程在执行完主动通知操作系统将CPU资源切换到另一个线程上执行。线程对CPU的持有时间由线程自身控制,线程切换更加透明,更适合多个线程交替执行某些任务的情况。
协同式调度有一个缺点:如果其中一个线程因为外部原因(可能是磁盘I/0阻塞、网络I/O阻塞,请求数据库等待)运行阻塞,那么可能导致整个系统阻塞甚至奔溃。具体流程如下。

3.12.3 Java调度的实现:抢占式
Java采用抢占式调度的方式实现内部的线程调度,Java会为每个线程都按照优先级高低分配不同的CPU时间片,且优先级高的线程优先执行。优先级低的线程只是获取CPU时间片的优先级被降低,但不会永久分配不到CPU时间片。Java 的线程调度在保障效率的前提下尽可能保障线程调度的公平性。
3.12.4 线程让出CPU的情况
线程让出CPU的情况如下:
- 当前运行的线程主动放弃CPU,例如运行中的线程调动yield()放弃CPU的使用权
- 当前运行的线程进入阻塞状态,例如调用文件读取I/0操作、锁等待Socket等待
- 当前线程运行结束,即运行完run里面的任务。
3.14 什么是CAS
3.14.1 CAS的概念:比较并交换
CAS(Compare and Swap)指比较并交换。CAS(V,E,N)算法包含三个参数,V表示要更新的变量,E表示预期的值,N表示新值。在且仅在V值等于E值时,才会将V值设置为N,如果V值和E值不同,说明已经有其它线程做了更新,当前线程什么都不做。最后,CAS返回当前V的真实值。
3.14.2 CAS的特性:乐观锁
CAS操作采用了乐观锁的思想。总是认为自己可以成功完成操作。在有多个线程同时使用CAS操作一个变量时,只有一个会胜出并成功更新,其余均会失败。失败的线程不会被挂起,仅被告知失败,并且允许再次尝试。当然,也允许失败的线程放弃操作,基于这样的原理,CAS操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行切当的处理。
3.14.3 CAS自旋等待
在JDK的原子包java.util.concurrent.atomic里面提供了一组原子类,这些原子类的基本特性是在多线程环境下,在有多个线程同时执行这些类的实例包含的方法时,会有排他性。其内部便是基于CAS算法实现的,即在某个线程进入方法中执行其中的指令是,不会被其他线程打断;而别的线程就像自旋锁一样,一直等到该方法执行完成才由JVM从等待的队列中选择另一个线程进入。
相对于synchronized阻塞算法,CAS是非阻塞算法的一种常见的实现。由于CPU上下文切换比CPU指令集的操作更加耗时,所以CAS的自旋操作在性能上有了很大的提升。
3.15 ABA问题
对CAS算法的实现有一个重要的前提:需要取出内存中某时刻的数据,然后在下一个时刻进行比较、替换,在这个时间差内可能数据已经发生了变化,导致产生了ABA问题。
ABA问题指第1个线程从内存V的位置取出A,这是第二个线程也从内存取出A,并将V位置的数据首先修改为B,接着又将V位置的数据修改为A,这时第一个线程在进行CAS操作时会发现内存中仍然是A,然后第一个线程操作成功。尽管从第一个线程的角度来说,CAS操作是成功的,但是在该过程中其实V位置的数据发生了变化,只是第一个线程没有感知到罢了,这在某些应用场景下可能出现过程数据不一致性的情况。
部分乐观锁是通过版本号(version)来解决ABA问题的,具体操作是乐观锁每次在执行数据修改的操作时带上上一个版本号,在预期的版本号和数据的版本号一致时就可以执行修改操作,并对版本号加1操作。否则执行失败。因为每次操作的版本号都会随之增加,所以不会出现ABA问题,因为版本号只会增加,不会减少。
3.16 什么是 AQS
AQS(Abstract Queued Synchronized)是一个抽象的队列同步器,通过维护一个共享资源状态和一个先进先出(FIFO)的线程等待队列来实现一个多线程共享访问资源的同步框架。
3.16.1 AQS的原理
AQS为每个共享资源都设置一个共享资源锁,线程在需要访问共享资源时首先需要获取共享资源锁,如果获取到了共享资源锁,便可以在当前线程中使用该共享资源,如果获取不到,则将该线程放入线程队列等待,等待下一次资源调度,具体流程如下图。许多同步类的实现都依赖于AQS。例如常用的ReentrantLock、Semaphore和CountDownLatch

3.16.2 state状态
Abstract Queued Synchronizer维护了一个volatile int类型的变量,用于表示当前的同步状态,volatile虽然不能保证操作的原子性,但是能保证当前变量state的可见性。
state的访问方式有三种:getSatate setState compareAndSetState,均是原子操作。
3.16.3 AQS共享资源的方式:独占式和共享式
AQS定义了两种资源共享方式:独占式(Exclusive)和共享式(Share)
- 独占式:只有一个线程能执行,具体的Java实现有ReentrantLock
- 共享式:多个线程可同时执行,具体的Java实现有Semaphore和CountDownLatch。
4 数据结构
| 数据结构 | 优点 | 缺点 |
|---|---|---|
| 栈 | 顶部元素插入和取出 | 除顶部元素外,存起其他元素都很慢 |
| 队列 | 顶部元素插入和尾部元素取出快 | 存取其他元素很慢 |
| 链表 | 插入和删除都快 | 查找慢 |
| 二叉树 | 插入、删除、查找都快 | 删除算法复杂 |
| 红黑树 | 插入、删除、查找都快 | 算法复杂 |
| 散列表 | 插入、删除、查找都快 | 数据散列,对存储空间有浪费 |
| 位图 | 节省存储空间 | 不方便描述复杂的数据关系 |
4.1 栈及其Java实现
栈(Stack)又名栈堆,是允许同一端进行插入和删除的特殊线性表。插入的过程叫做进栈(Push),删除的过程叫做退栈(Pop)。栈也叫做先进先出的线性表。
要实现一个栈,需要以下几个核心方法
- push 向栈压入一个书,先入栈的数据在最下面
- pop 弹出栈顶数据,即移除栈顶数据
- peek 返回当前栈顶数据
/**
* 数据结构-栈
* 基于数组实现
*/
public class Stack<E> {
private Object[] data;
//栈的容量
private int maxSize = 0;
//栈顶的指针
private int top = -1;
public Stack(int initialSize) {
if (initialSize >= 0) {
this.maxSize = initialSize;
data = new Object[initialSize];
top = -1;
} else {
throw new RuntimeException("初始化大小不能小于0->" + initialSize);
}
}
/**
* 压入元素
* 进栈,第一个元素top=0
*/
public boolean push(Object e) {
if (top == maxSize - 1) {
throw new RuntimeException("栈已满,无法将元素入栈");
} else {
data[++top] = e;
return true;
}
}
/**
* 弹出栈顶元素
*/
public E pop() {
if (top == -1) {
throw new RuntimeException("栈为空!");
} else {
return (E) data[top--];
}
}
/**
* 查询数据
*/
public E peek() {
if (top == -1) {
throw new RuntimeException("栈为空!");
} else {
return (E) data[top];
}
}
}
4.2 队列及其Java实现
一种只允许在表的前端进行删除操作并且在表的后端进行插入操作的线性表。
先进先出(FIFO)
public class ArrayQueue {
private int maxSize;
private int front;
private int rear;
//用于存放队列
private int[] arr;
public ArrayQueue(int maxSize) {
this.maxSize = maxSize;
arr = new int[maxSize];
front = -1;//指向队列头部,指向第一个队列前一个位置
rear = -1;//指向队列尾。包含队列尾(队列最后一个数字)
}
/**
* 判断是否为空
*/
public boolean isFull() {
return rear == maxSize - 1;
}
/**
* 判断是否空
*/
public boolean isEmpty() {
return rear == front;
}
public void addQueue(int n) {
if (isFull()) {
System.out.println("队列满");
return;
}
rear++;
arr[rear] = n;
}
public int getQueue() {
if (isEmpty()) {
System.out.println("队列为空");
throw new RuntimeException("队列为空");
}
//后移
front++;
return arr[front];
}
//显示队列的所有数据
public void showQueue() {
if (isEmpty()) {
System.out.println("队列为空");
return;
}
for (int i = 0; i < arr.length; i++) {
System.out.printf("arr[%d]=%d\n", i, arr[i]);
}
}
//显示队列的头数据(不取出书)
public int headQueue() {
if (isEmpty()) {
System.out.println("队列空没有数据");
throw new RuntimeException("为空");
}
return arr[front + 1];
}
public static void main(String[] args) {
final ArrayQueue arrayQueue = new ArrayQueue(5);
for (int i = 0; i < 10; i++) {
arrayQueue.addQueue(i * 2);
}
arrayQueue.showQueue();
System.out.println(arrayQueue.getQueue());
System.out.println(arrayQueue.getQueue());
System.out.println(arrayQueue.getQueue());
arrayQueue.showQueue();
}
}
5 Java中的常用算法
5.1二分查找算法
/**
* 二分查找算法
*/
public static int binarySearch(int[] array, int a) {
int low = 0;
int high = array.length - 1;
int mid;
while (low <= high) {
mid = (low + high) / 2;
if (a == array[mid]) {
return mid;
} else if (a > array[mid]) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return -1;
}
5.2 冒泡排序法
/**
* 冒泡排序法
*/
public static int[] bubblSort(int arr[]) {
//外层循环控制排序趟数
for (int i = 0; i < arr.length - 1; i++) {
//内存循环控制每一趟排序多少次
for (int j = 0; j < arr.length - i; j++) {
if (arr[j] > arr[j + 1]) {
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
return arr;
}
5.3 插入排序
.
public static int[] insertSort(int array[]) {
for (int index = 1; index < array.length; index++) {
int temp = array[index];
int leftindex = index - 1;
while (leftindex >= 0 && array[leftindex] > temp) {
// while (leftindex >= 0 && array[leftindex] > temp) {
array[leftindex + 1] = array[leftindex];
leftindex--;
}
array[leftindex + 1] = temp;
}
return array;
}
5.4 快速排序
快速排序(Quick Sort)是对冒泡排序的一种改进,通过一趟排序将要排序的数据序列分成独立的两部分,其中一部分的所有数据比另一个部分的所有数据都要小,然后按此方法对两部分数据分别进行快速排序,整个排序过程递归进行,最终是整个数据序列变成有序的数据序列。
5.4.1 快速排序算法的原理
快速排序算法的原理是:选择一个关键值作为基准值(一般选择第一个元素为基准元素),将比基准值大的都放在右边的序列,将比基准值小的都放在左边的序列中,具体的循环过程如下。
- 从后向前比较,用基准值和最后一个值进行比较。如果比基准值小,则交换位置;如果比基准值大,则继续比较下一个值,直到找到第一个比基准值小的才交换位置。
- 在后向前找到第一个比基准值小的值交换位置后,从前向后开始比较。如果有比基准值大的,则交换位置;如果没有,则继续比较下一个,直到找到第一个比基准值大的值才交换位置。
- 重复执行以上过程,直到从前向后比较的索引大于等于从后向前比较的索引,则结束一次循环。这时对于基准值来说,左右两边都是有序的数据序列。
- 重复循环以上过程,分别比较左右两边的序列,直到整个数据序列有序。
韩顺平排序
/**
* 快速排序
*/
public static void quickSort(int arr[], int left, int right) {
int l = left;
int r = right;//右下标
int pivot = arr[(left + right) / 2];//中轴值
//循环目的是让 比 pivot小的值 放到左边,比pivot大的值放到右边
while (l < r) {
//在pivot的左边一直找,找到大于等于pivot的值才退出
while (arr[l] < pivot) {
l += 1;
}
//在pivot的右边 找比 pivot 小的值。
while (arr[r] > pivot) {
r -= 1;
}
//如果l>r ,说明 pivot左右两边的值,已经全部按照 左边小于pivot,右边大有pivot排序了
if (l >= r) {
break;
}
//交换
int temp = arr[l];
arr[l] = arr[r];
arr[r] = temp;
//交换之后 发现 arr[l]==pivot ,前移一下
if (arr[l] == pivot) {
r -= 1;
}
//l后移
if (arr[r] == pivot) {
l += 1;
}
}
//上述代码第一次移动完毕。
//如果l==r 必须加一 ,否则会出现栈溢出
if (l == r) {
l += 1;
r -= 1;
}
//向左递归
if (left < r) {
quickSort(arr, left, r);
}
//向右递归
if (right > l) {
quickSort(arr, l, right);
}
}
5.5 希尔排序
韩顺平希尔排序
public class ShellSort {
//希尔排序
public static void main(String[] args) {
int[] arr = {8, 9, 1, 7, 2, 3, 5, 4, 6, 0};
shellSort(arr);
System.out.println(Arrays.toString(arr));
}
public static void shellSort(int[] arr) {
int temp = 0;
//使用循环处理
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
for (int i = gap; i < arr.length; i++) {
for (int j = i - gap; j >= 0; j -= gap) {
//如果当前元素大于加上 步长的那个元素,说明交换
if (arr[j] > arr[j + gap]) {
temp = arr[j];
arr[j] = arr[j + gap];
arr[j + gap] = temp;
}
}
}
}
/*for (int i = 5; i < arr.length; i++) {
for (int j = i - 5; j >= 0; j -= 5) {
//如果当前元素大于加上 步长的那个元素,说明交换
if (arr[j] > arr[j + 5]) {
temp = arr[j];
arr[j] = arr[j + 5];
arr[j + 5] = temp;
}
}
}
System.out.println("第一轮排序" + Arrays.toString(arr));
//第二轮排序 5/2=2组
for (int i = 2; i < arr.length; i++) {
for (int j = i - 2; j >= 0; j -= 2) {
//如果当前元素大于加上 步长的那个元素,说明交换
if (arr[j] > arr[j + 2]) {
temp = arr[j];
arr[j] = arr[j + 2];
arr[j + 2] = temp;
}
}
}
System.out.println("第2轮排序" + Arrays.toString(arr));
//第二轮排序 5/2=2组
for (int i = 1; i < arr.length; i++) {
for (int j = i - 1; j >= 0; j -= 1) {
//如果当前元素大于加上 步长的那个元素,说明交换
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
System.out.println("第3轮排序" + Arrays.toString(arr));*/
}
}
//希尔排序-移位
public static void shellSort2(int[] arr) {
//使用循环处理
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
//从 gap个元素,逐个对其所在的元素进行直接插入排序
for (int i = gap; i < arr.length; i++) {
int j = i;
int temp = arr[j];
if (arr[j] < arr[j - gap]) {
while (j - gap >= 0 && temp < arr[j - gap]) {
//移动
arr[j] = arr[j - gap];
j -= gap;
}
//当退出 while之后,就该temp找到插入的位置
arr[j] = temp;
}
}
}
}
5.6 归并排序算法
6 网络与负载均衡
6.1 网络
6.1.1 OSI七层网络模型
七层架构从上到下主要分为:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层
- 物理层主要定义物理设备标准,它的主要作用是传输比特流,具体做法是在发送端将0,1码转化为电流强弱来进行传输,在达到目的地后在将电流转为为1、0码,也就是常说的模数转换与数模转换,这一层的数据叫做比特。
- 数据链路层主要用于对数据包中的MAC地址进行解析和封装。这一层的数据叫做帧。在这一层的设备是网卡,网桥,交换机。
- 网络层主要用于对数据包中的IP地址进行封装和解析,这一层的数据叫做数据包。在这一层工作的设备有路由器、交换机、防火墙等
- 传输层定义了传输数据的协议和端口号,主要用于数据的分段、传输和重组。在这一层工作的协议有TCP和UDP等,TCP是传输控制协议,传输效率低,可靠性强,用于传输对可靠性要求高,数据量小的数据。UDP是用户数据报协议,用于传输可靠性要求不高,数据量大的数据。
- 会话层在传输层的基础上连接和管理会话,具体包括登录 验证、断电续传、数据粘包与分包等。在设备之间需要相互识别的可以是IP,也可以是MAC或者主机名。
- 表示层主要对接受的数据进行解释、加密、解密、压缩、解压缩等,即把计算机能够识别的内容转换成人能够识别的内容(图片,文字等)
- 应用层基于网络构建具体应用,例如FTP文件上传下载,HTTP服务,DNS服务,SNMP邮件服务等。
6.1.2 TCP/IP四层网络模型
TCP/IP不是指TCP和IP这两个协议的合称,而是指因特网的整个TCP/IP协议簇。从协议分层模型方面来讲,TCP/IP由4个层次组成:网络接口层,网络词、传输层和应用层。
6.1.3 TCP三次握手/四次挥手
TCP数据在传输之前首先需要建立连接,建立连接需要进行3次通信,一般称为“三次握手”,在数据传输完成后断开连接的时候需要进行4次通信,一般被称为“四次挥手”。
6.2 负载均衡
负载均衡建立在现有网络结构上,提供了一种廉价、有效,透明的方法来扩展网络设备和服务器的宽带,增加了吞吐量,加强了网络数据处理能力,并提高了网络的灵活性和可用性。项目中最常用的负载均衡有四层负载均衡和七层负载均衡。
6.2.1 四层负载均衡与七层负载均衡的对比
四层负载均衡基于IP和端口的方式实现网络的负载均衡,具体实现为对外提供了一个虚拟IP地址和端口接受所有用户的请求,然后根据负载均衡配置和负载均衡策略将请求发送给真实的服务器。
七层负载均衡基于URL等资源来实现应用层基于内容的负载均衡,具体实现为通过虚拟的URL或主机名接受所有用户的请求,然后将请求发送给真实的服务器。
四层负载均衡和七层负载均衡的最大差别是:四层负载均衡只能针对IP和端口上的数据做统一分发,而七层负载均衡能根据消息的内容做更加详细的有针对性的负载均衡。我们通常说使用LVS等技术实现基本Socket的四层负载均衡,使用nginx等技术实现基于内容分发的七层负载均衡,比如将“/user/**”开头的URL请求负载到单点登录服务器上,而将“/business/”开头的URL请求负载到具体的业务服务器上。
1 四层负载均衡
四层负载均衡主要通过修改报文中的目标地址和端口来实现报文的分发和负载均衡。以TCP为例,负载均衡设备在接收到第一个来自客户端的SYN请求后,会根据负载均衡配置和负载均衡策略选择一个最佳的服务器。,并将报文中的目标IP地址修改为该服务器的IP地址直接转发给该服务器。TCP连接的建立(即三次握手过程)是在客户端和服务器之间完成的,负载均衡设备只起到路由器的转发功能。
四层负载均衡的软件件如下:
- F5:硬件负载均衡器,功能完备,价格昂贵。
- LVS:基于IP+端口实现的四层负载软件,常好Keepalive配合使用
- Nginx:同时实现四层负载和七层负载均衡,带缓存功能,可以基于正则表达灵活转发
2 七层负载均衡
七层负载均衡又叫作“内容负载均衡”,主要通过解析报文中真正有意义的应用内容,并根据负载均衡配置和负载均衡策略选项一个最佳的服务器响应用户的请求。
七层负载均衡可以使整个网络更智能化,七层负载均衡根据不同的数据类型将数据存储在不同的服务器上来提高网络的整体负载能力。比如将客户端的基本信息存储在内存较大的缓存服务器上,将文件信息存储在磁盘较大的文件服务器上,将图片视频存储在网络I/O能力较强的流媒体服务器上。在接受到不同的客户端的请求时从不同的服务器上获取数据并将其返回给客户端,以提高客户端的访问效率。
七层负载常用的软件如下:
- HAproxy: 支持七层代理,会话保持、标记、路劲转移等
- Nginx:同时实现四层负载和七层负载均衡,在HTTP和Mail协议上功能比价好,性能和HAproxy相当
- Apache:使用简单,性能较差
6.2.2 负载均衡算法
1 轮询请求(Round Robin)
轮询请求指将客户端请求轮流分配到1至N台服务器上,每台服务器军备均等的分配一定数量的客户端请求。轮询均衡算法适用于集群中所有服务器都有相同的软硬件配置和服务能力的情况下。
2 权重轮询请求(Wgighted Round Robin)
权重轮询均衡指根据每台服务器的不同配置以及服务能力,为每台服务器都设置不同的权重值,然后按照设计的权重值轮询地将请求分配到不同的服务器上。
权重轮询均衡算法主要用于服务器配置不均等的环境中。
3随机均衡(Random)
随机均衡指将来自网络的请求随机分配给内部的多台服务器,不考虑服务器的配置和负载情况。
4 权重随机均衡(Weighted Random)
权重随机均衡算法类似于权重轮询算法,只是在分配请求时不再轮询发送,而是随机选择某个权重的服务器发送。
5 响应速度均衡(Response Time)
响应速度均衡指根据服务器设备响应速度的不同将客户端请求发送到响应速度最快的服务器上。对响应速度的获取是通过负载均衡设备定时为每台服务器都发出一个探测请求(例如 ping)实现的。响应速度均衡能够为当前的每台服务器根据不同的负载情况分配不同的客户端请求,这有效避免了某台服务器单点请求过高的情况。但需要注意的是,这里探测到的响应速度是负载均衡设备到各个服务器之间的响应速度,并不完全代表客户端到服务器的响应速度,因此存在一定偏差。
6 最小连接数均衡(Least Connection)
最小连接数均衡指在负载均衡器内部记录当前每台服务器正在处理的连接数量,在有新的请求时,将该请求分配给连接数最小的服务器。这种均衡算法适用于网络连接和宽带有限、CPU处理任务简单的请求服务,例如FTP。
7 处理能力均衡
处理能力均衡算法将服务器请求分配给内部负荷最轻的服务器,负荷时根据服务器的CPU型号,CPU数量,内存大小以及当前连接数等换算而成的。处理能力均衡算法由于考虑到了内部服务器的处理能力以及当前网络的运行状况,所以相对来说更加精确,尤其适用七层负载均衡的场景。
8 DNS响应均衡(Flash DNS)
DNS响应均衡算法指分布在不同中心机房的负载均衡设备都收到同一个客户端的域名解析请求时,所有负载均衡设备均解析次域名并将解析后的服务器IP返回给客户端,客户端收到第一域名解析后的IP地址发起请求服务,而忽略其他负载均衡设备的响应。这种均衡算法适用于全局负载均衡的场景。
9 散列算法均衡
散列算法均衡指通过一致性散列算法和虚拟节点技术将相同参数的请求总是发送到同一台服务器,该服务器将长期、稳定地为某些客户提供服务。在某个服务器被移除或异常宕机后,该服务器的请求基于虚拟节点技术均衡摊到其他服务器,而不会响应响应集群的稳定性。
10 IP地址散列
TP地址散列指在负载均衡器内部维护了不不同链接上客户端和服务器的IP对应对应表,将来之同一个客户端的请求统一转发给相同的服务器。该算法能够以会话为单位,保证一客户端的请求能够一直在同一台服务器上处理。主要用于客户端和服务器需要保持长连接的场景,比如基于TCP长连接应用。
11 URL散列
URL散列指通过管理客户端请求URL信息的散列表,将相同URL的请求转发给同一台服务器。该算法主要适用于七层负载中心根据用户请求类型的不同将其转发给不同类型的应用服务器。
6.2.4 Nginx反向代理与负载均衡
一般的负载均衡软件如LVS实现的功能只是对请求数据包的转发和传递,从负载均衡下的节点服务器来看,接受到的请求还是来自访问负载均衡器的客户端的真实用户;而反向代理服务器在接收到用户的请求后,会代理用户重新想节点服务器发起请求,反向代理服务器和节点服务器进行具体的数据交互,最大把数据返回给客户端用户。在节点服务器看来,访问的节点服务器的客户端就是反向代理服务器,而非真实的网站访问用户。具体如下
1 upstream_module
ngx_http_upstream_module是nginx的负载均衡模块,可以实现完整的负载均衡功能即节点健康检查。upstream模块允许nginx定义一组或多组节点服务器,在使用时可通过proxy_pass代理方式把网站的请求发送到事先预先定义好的对应的Upstream组的名字上。
upstream restLVSServer {
server 191.168.1.10:9000 weight=5;
server 191.168.1.11:9000 ;
server example.com:9000 max_fails=2 fail_timeout=10s backup;
}
上述定义了restLVSServer的upstream。并在其中定义了三个服务地址,在用户请求restLVSServer服务时,Nginx会根据权重将请求转发到具体的服务器,常用的upstream配置如下。
- weight:服务器权重
- max_fails:Nginx尝试连接后端服务器的最大失败次数,如果失败次数大于max_fails,则认为该服务器不可用
- fail_timeout: fail_max和fail_timeout一般会关联使用,如果某台服务器在fail_timeout时间内出现了max_fail次连接失败,那么nginx会认为其已经挂掉。从而在fail_timeout时间内不再去请求它,fail_timeout默认是10s,fail_max默认是1,即在默认情况下只要发生错误就认为服务器挂了。如果将max_fails设置为-,则表示取消这项检查。
- backup:表示当前服务器是备用服务器,只有其他非bakckup后端服务器都挂掉或很忙时,才会分配请求到backup服务器。
- down:表示服务器永远不可用。
2 proxy_pass
proxy_pass指令属于ngx_http_proxy_module模块,次模块可以将请求转发到另一台服务器,在实际的反向代理工作中,会通过location功能匹配指定的URL,然后把接受到的服务器匹配URL的请求通过proxy_pass抛给定义的upstream。

若有收获,就点个赞吧
0 人点赞
