数据库中的数据一般是放在磁盘里面,存取数据的时候就要访问磁盘,物理访问过程:盘片旋转,磁臂移动 两个过程。盘片旋转到指定位置之后,移动磁臂开始进行数据的存取。如果使用顺序查找,查询数据的时候就要从头到尾查询一遍,如果所查询的数据靠近数据尾端,效率久会很低,当然,这种方式也是最低效率的。因此,出现了二叉树。
二叉树
二叉树是一种非常重要的数据结构,它同时具有数组和链表各自的特点:它可以像数组一样快速查找,也可以像链表一样快速添加。但是它也有自己的缺点:删除操作复杂。
定义:每个节点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且,二叉树的子树有左右之分,其次序不能任意颠倒。
二叉树在插入数据时也存在一个很大的缺点:
在使用二叉树插入节点时:一个节点的左节点的关键值必须小于此节点,右节点必须大于或者等于此节点。
通过上面定义可以发现:如果插入的数据是有序的,二叉树就会形成一个分支的树结构,远远增加了树的深度。因而为了提高效率稳定性,形成了平衡二叉树
**
二叉查找树
1、若它的左子树不为空,则左子树上所有的节点值都小于它的根节点值。
2、若它的右子树不为空,则右子树上所有的节点值均大于它的根节点值。
3、它的左右子树也分别可以充当为二叉查找树。
例如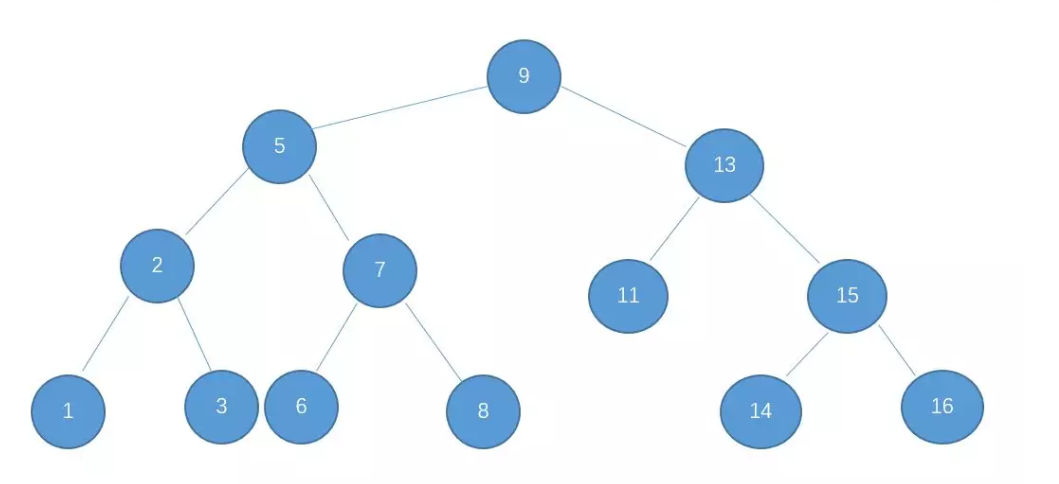
这种数据结构的优点:
如果想查14,首先和根节点9比较,比9大,在9的右边;查看右孩子13,比13大,在13的右边;查看右孩子15,比15小,在15的左边;查看左孩子14,命中。
这种查找二叉树的查找正是二分查找的思想,可以很快着找到目的节点,查找所需的最大次数等同于二叉查找树的高度。
在插入的时候也是一样,通过一层一层的比较,最后找到适合自己的位置。
这种数据结构的缺点:
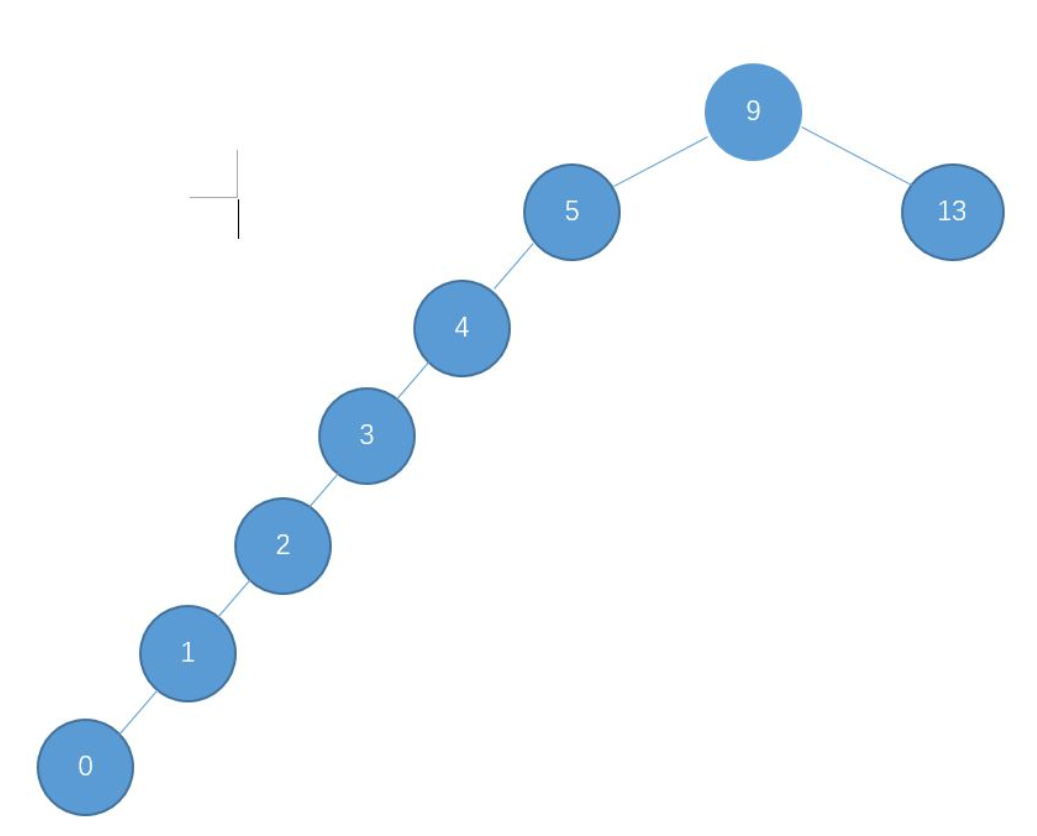
在这种情况下几乎所有的节点都倾向一边,性能会大打折扣,几乎变成了线性。
怎么解决?AVL出现了。
平衡二叉树(AVL)
这种树就可以帮助我们解决二叉查找树刚才的那种所有节点都倾向一边的缺点的。具有如下特性:
- 具有二叉查找树的全部特性。
- 每个节点的左子树和右子树的高度差至多等于1。
平衡因子:一般定义一个结点的左子树与右子树的高度之差,为该结点的平衡因子;即 结点平衡因子 = 左子树高度 - 右子树高度。
平衡二叉树用平衡因子差值来判断是否平衡,并旋转二叉树平衡二叉树里平衡因子不能超过1,否则旋转。
左-左型:右旋:顺时针旋转两个节点,使得父节点被自己的左孩子取代,而自己成为自己的右孩子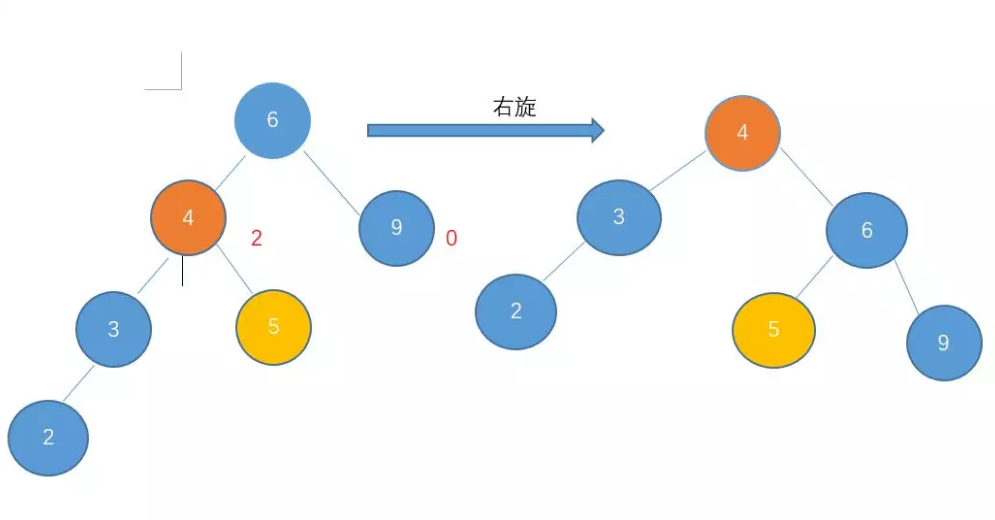
右-右型:左旋:左旋和右旋一样,就是用来解决当大部分节点都偏向右边的时候,通过左旋来还原。
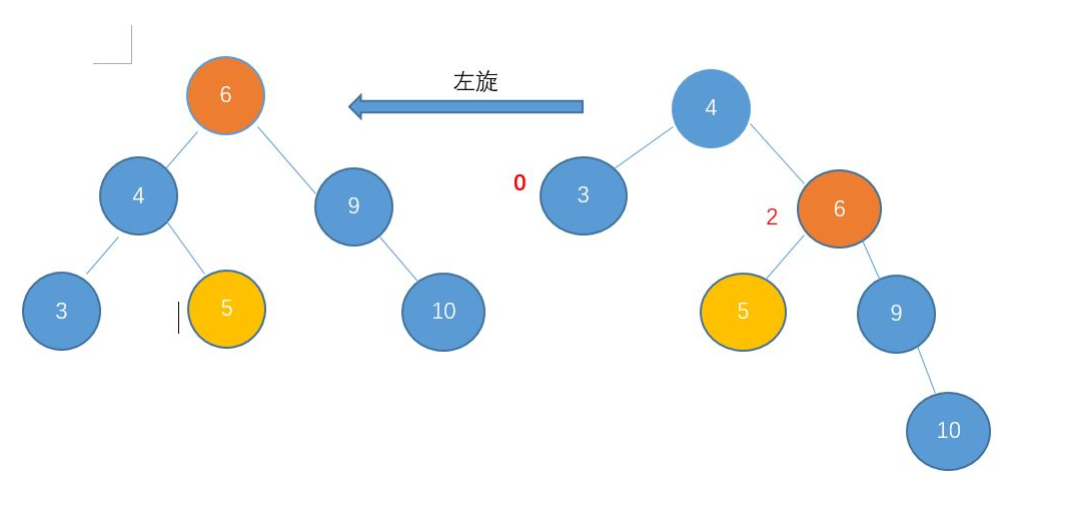
平衡二叉树插入举例:
**
初始状态如下:
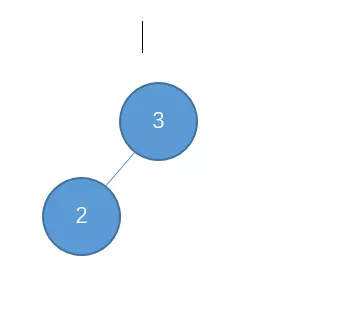
然后我们主键插入如下数值:1,4,5,6,7,10,9,8
插入 1
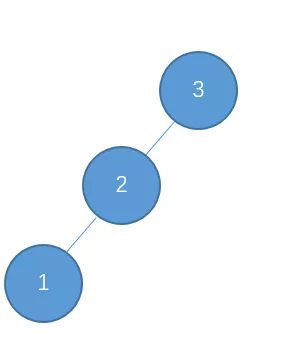
左-左型,需要右旋调整。
插入4

继续插入 5
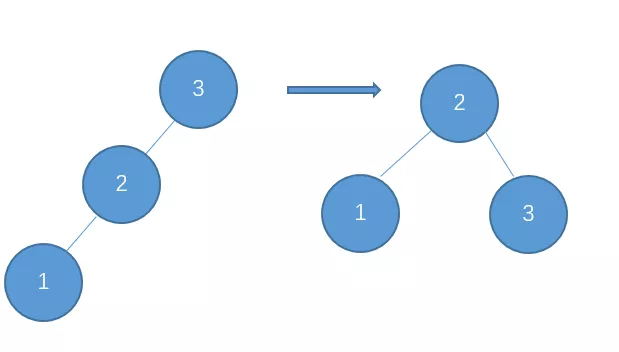
右-右型,需要左旋转调整。
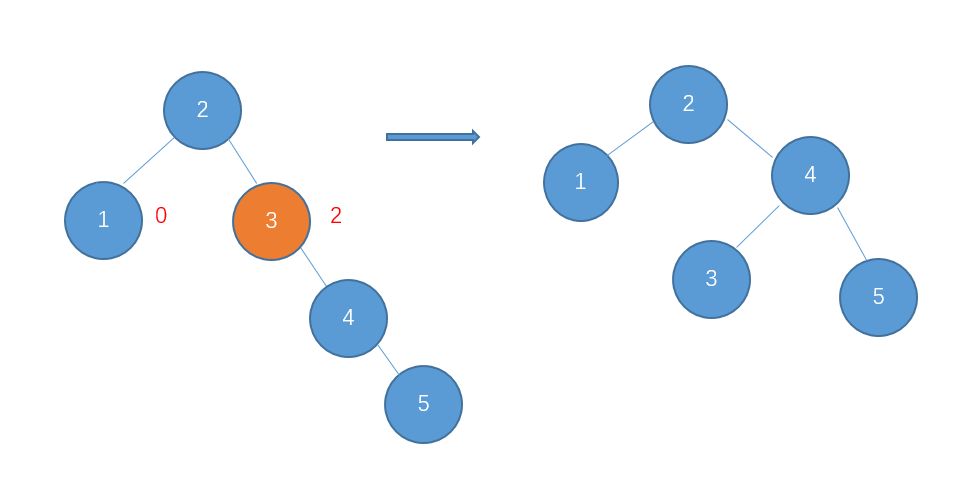
继续插入6
右-右型,需要进行左旋
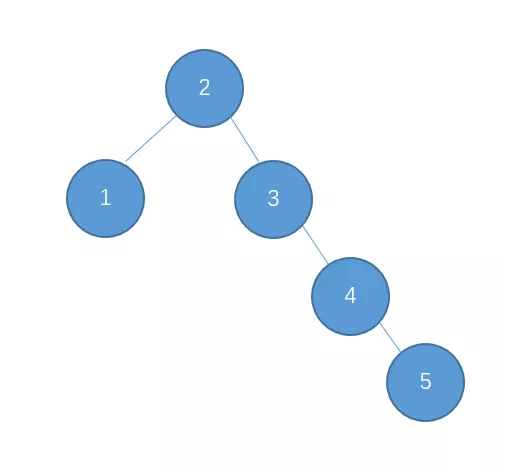
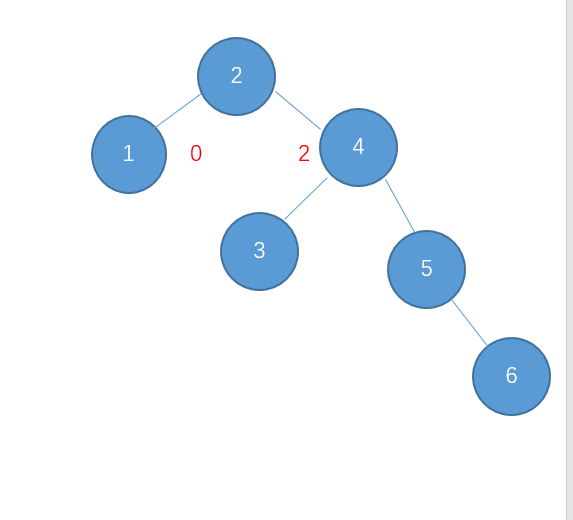
继续插入7
右-右型,需要进行左旋
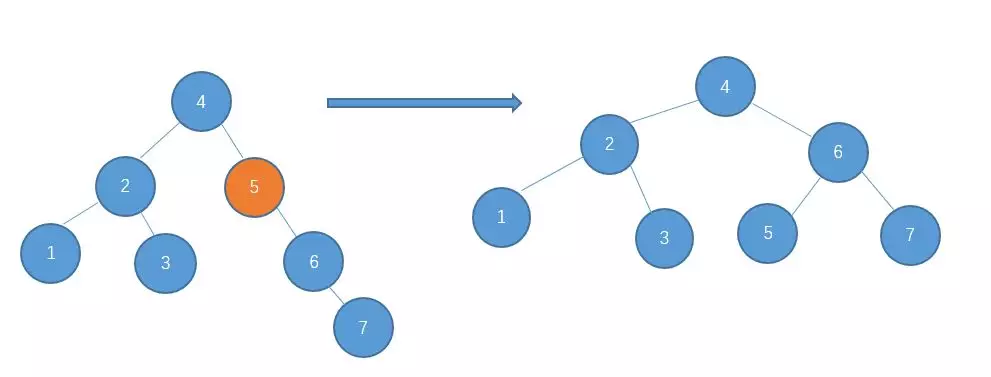
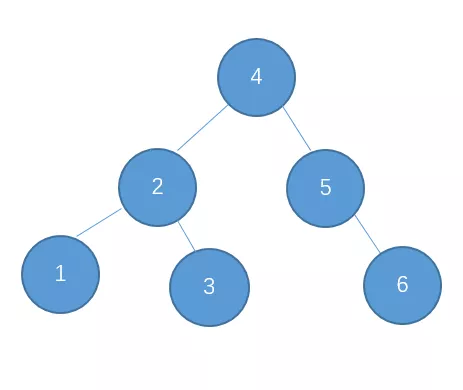
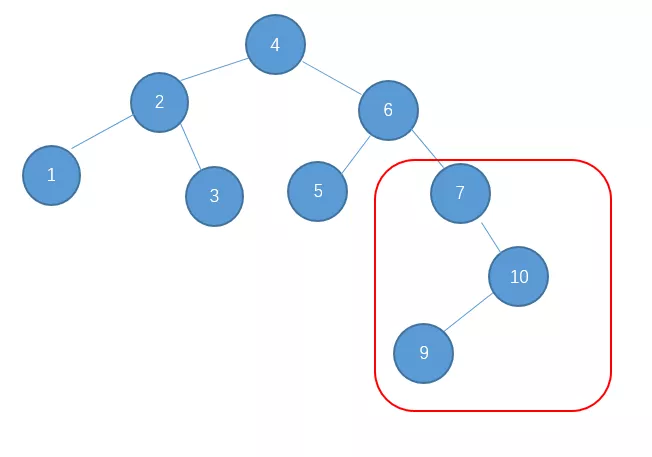
继续插入10
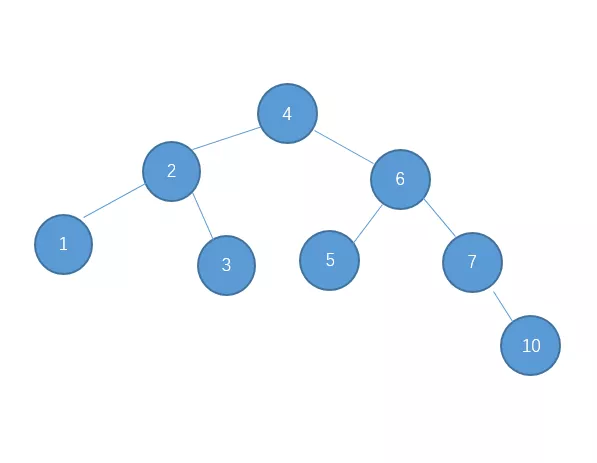
继续插入9
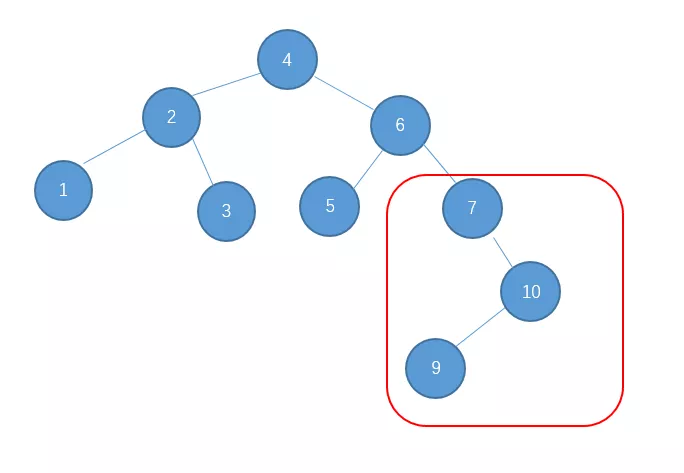
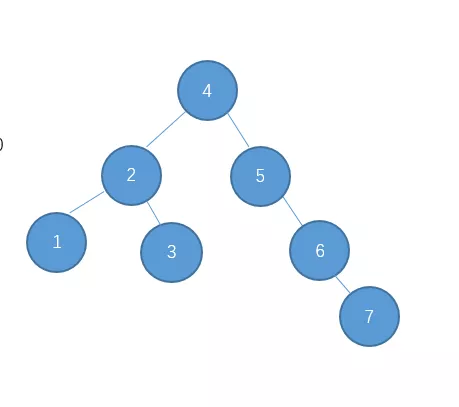
出现了这种情况怎么办呢?对于这种 右-左型 的情况,单单一次左旋或右旋是不行的,下面我们先说说如何处理这种情况。
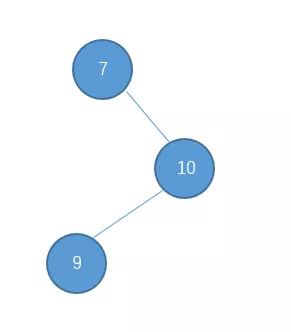
这种我们就把它称之为 右-左 型吧。处理的方法是先对节点10进行右旋把它变成右-右型。
**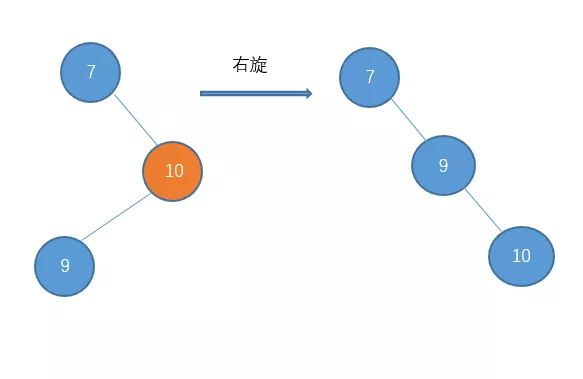
然后在进行左旋。
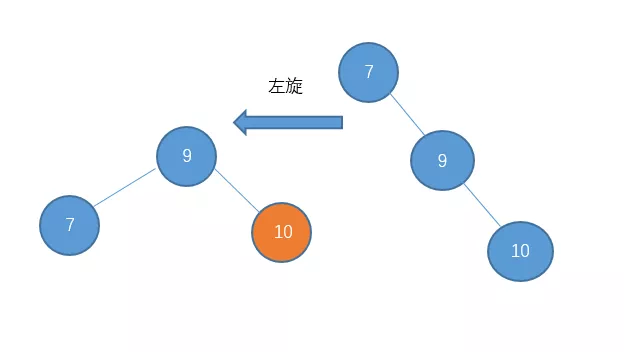
所以对于这种 右-左型的,我们需要进行一次右旋再左旋。
同理,也存在 左-右型的,例如:
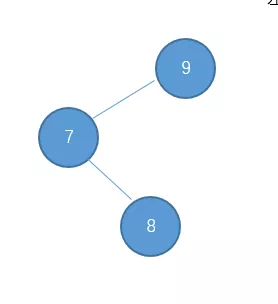
对于左-右型的情况和刚才的 右-左型相反,我们需要对它进行一次左旋,再右旋。
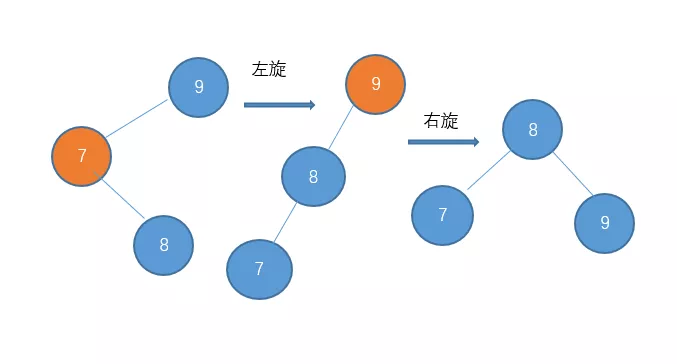
回到刚才那道题
对它进行右旋再左旋。
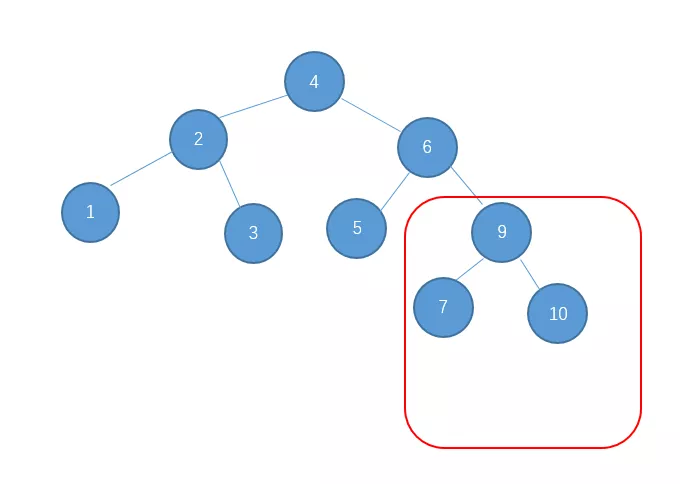
到此,我们的插入就结束了。
规律:**
在插入的过程中,会出现一下四种情况破坏AVL树的特性,我们可以采取如下相应的旋转。
1、左-左型(子节点和孙节点都在左边):做右旋。
2、右-右型:做左旋。
3、左-右型:先做左旋,后做右旋。
4、右-左型:先做右旋,再做左旋。
缺点:
平衡二叉树虽然达到了稳定,但是由于不停的旋转,时间方面浪费了很多,从而效率又降了下来。
那么怎样才能稳定的同时,旋转的次数少? 再次升级—>红黑树
红黑树
定义:
1、每个节点要么是红色,要么是黑色。 2、根节点必须是黑色。 3、红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色)。 4、对于每个节点,从该点至null(树尾端)的任何路径,都含有相同个数的黑色节点。
红黑树旋转的关键逻辑是:确保任何一个节点的左右子树的高度差不会超过二者中较低那个的一倍。例如:节点A,左子树高度X,右子树高度Y, X-Y<=min(X,Y);如果当 X-Y > min(X,Y),然后开始旋转。
在java中TreeSet的数据结构底层就是用的红黑树
红黑树虽然解决了稳定、时间浪费的问题,但是,我们一开始就说了,数据库中的数据一般是存在磁盘上的,如果考虑到磁盘IO的影响,当数据量过大,就有可能不能一次性读取到内存中;反复的从磁盘到内存,效率就又会降低!
读取磁盘次数过多,读取浪费就太多,这也是MySql不使用红黑树作为索引的原因
B树
多路存储能力
考虑到磁盘IO,内存的影响,所以产生了B树。B树:每个节点上都存有key和value,所以每次读取数据时,只需把相应的节点读取到内存中即可,而不需把整个树都读取到内存。等价于有关键字的二分查找,所以B树解决了红黑树存在的问题。
问题:
B树虽然解决了磁盘读取到内存效率降低的问题,但是由于B树的每一个节点上都存有数据,那么就会造成空间浪费,范围查找还是没有解决。那应该怎么解决呢?再次升级—>B+树!
B+树
B+树中所有的数据都存在叶子节点中,并且叶子节点中还加了指针形成了链表,其他的都是索引,增加了系统的稳定性以及遍历以及查找效率。
MySql索引采用B+树 为什么MySql中索引采用B+树?
通过应用场景,我们可以知道。再通过MySql查询数据时,我们通常查询的不只是一条数据,大多数情况下都是多条数据。如果采用B树,查询多条时,可能需要跨层获取数据,所以,B+树中叶子节点之间增加了指针形成了链表结构,查询多条数据时更加的快速,因此MySql中索引采用了B+树,提高了效率!
hash比B+树更快,为什么MySql没有采用hash?
如果查询一条数据的话,hash确实比B+树快。但是正如我们上面所说,我们查询数据时通常是多条的,这时候由于B+树索引有序并且还有链表相连,而且数据库中的索引一般在磁盘,数据量大的时候,B+树可以允许数据分批,同时树的高度比较低,也提高了查询效率,所以多数据时B+树会更快。

若有收获,就点个赞吧
0 人点赞
