一、线性表

散列表(哈希表)
特点:不在意元素的顺序,能够快速的查找元素的数据
链表+数组=散列表
散列表为每个对象计算出一个整数,称为散列码。根据这些计算出来的整数(散列码)保存在对应的位置上!
在Java中,散列表用的是链表+数组实现的,每个列表称之为桶。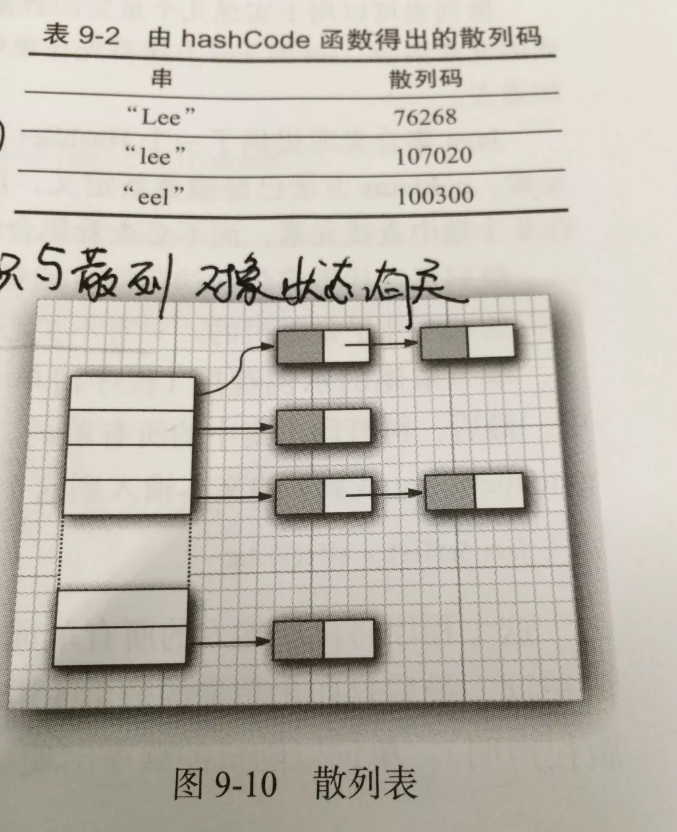
一个桶上可能会遇到被占用的情况(hashCode散列码相同,就存储在同一个位置上),这种情况是无法避免的,这种现象称之为:散列冲突
- 此时需要用该对象与桶上的对象进行比较,看看该对象是否存在桶子上了~如果存在,就不添加了,如果不存在则添加到桶子上
- 当然了,如果hashcode函数设计得足够好,桶的数目也足够,这种比较是很少的~
- 在JDK1.8中,桶满时会从链表变成平衡二叉树
如果散列表太满,是需要对散列表再散列,创建一个桶数更多的散列表,并将原有的元素插入到新表中,丢弃原来的表~
- 装填因子(load factor)决定了何时对散列表再散列~
- 装填因子默认为0.75,如果表中超过了75%的位置已经填入了元素,那么这个表就会用双倍的桶数自动进行再散列
二、Stack,Collection和Map
Stack:堆只能在栈顶操作,先进后出
List
Queue:队列只能在队头或队尾操作,先进先出
Set
Map
三、串、数组、广义表
字符串KMP算法,
四、树
二叉树
二叉树特点是每个结点最多只能有两棵子树,且有左右之分二叉查找树
满二叉树
除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
完全二叉树
若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
参考:https://zhuanlan.zhihu.com/p/152285749
平衡二叉树(AVL)
平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
应用:最早的平衡二叉树之一。应用相对其他数据结构比较少。windows对进程地址空间的管理用到了AVL树。
二叉查找树(BST)
二叉查找树的特点:
- 若任意节点的左子树不空,则左子树上所有结点的 值均小于它的根结点的值;
- 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意节点的左、右子树也分别为二叉查找树;
没有键值相等的节点(no duplicate nodes)。
红黑树
红黑树特点:
每个节点非红即黑;
- 根节点总是黑色的;
- 每个叶子节点都是黑色的空节点(NIL节点);
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
红黑树的应用:
TreeMap、TreeSet以及JDK1.8的HashMap底层都用到了红黑树。
b树(就是b-树)
B-树(或B树)是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance)。
B+树

若有收获,就点个赞吧
0 人点赞
