1. Interface Collection
集合和数组的区别:
- 数组的长度都是固定的,集合长度是可变的
- 数组中存储的是同一类型的而元素,可以存储基本数组类型值。集合存储的都是对象,而且对象的类型可以不一致,在开发中一般当对象多时,使用集合进行存储。
java.util.Collection接口是所有单列集合的最顶层接口,定义了所有单列集合共性的方法。
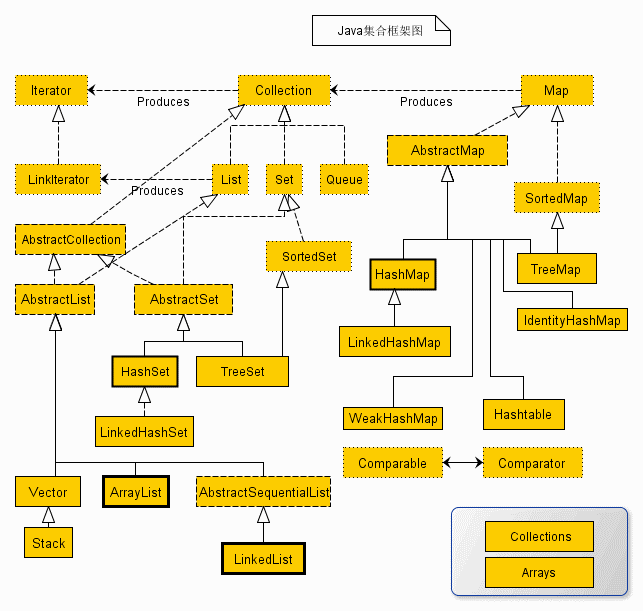
任意的单列集合都可以使用Collection接口中的方法。
常用的方法:
boolean add(E e)·:把给定的对象添加到当前集合中void clear():清空集合中所有的元素boolean remove(E e):把给定的对象在当前集合中删除boolean contains(E e):判断当前集合中是否包含给定的对象boolean isEmpty():判断当前集合是否为空int size():返回集合中元素的个数Object[] toArray():把集合中的元素,存储到数组中
import java.util.ArrayList;import java.util.Arrays;import java.util.Collection;public class CollectionMain {public static void main(String[] args) {Collection<String> array = new ArrayList<>();System.out.println(array); // []array.add("Forlogen");array.add("James");System.out.println(array); // [Forlogen, James]System.out.println(array.contains("Forlogen")); // trueSystem.out.println(array.contains("kobe")); // falseSystem.out.println(array.isEmpty()); //falseSystem.out.println(array.size()); // 1Object[] arr = array.toArray();System.out.println(arr); // [Ljava.lang.Object;@1b6d3586System.out.println(Arrays.toString(arr)); // [Forlogen, James]System.out.println(array); // [Forlogen, James]boolean b = array.remove("Forlogen");System.out.println(b); // truearray.clear();System.out.println(array); // []}}
2. Collection源码
package java.util;
import java.util.function.Predicate;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
public interface Collection<E> extends Iterable<E> {
// Query Operations
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
// Modification Operations
boolean add(E e);
// Bulk Operations
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
default boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
boolean removed = false;
final Iterator<E> each = iterator();
while (each.hasNext()) {
if (filter.test(each.next())) {
each.remove();
removed = true;
}
}
return removed;
}
boolean retainAll(Collection<?> c);
void clear();
// Comparison and hashing
boolean equals(Object o);
int hashCode();
@Override
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
}
3. 重要子接口
3.1 List
List是一个抽象接口,它是一个有序的集合,即存储元素和取出元素的顺序是一致的;有索引;允许存储重复的元素。主要方法有:
void add(int index,Object element):在指定位置上添加一个对象boolean addAll(int index,Collection c):将集合c的元素添加到指定的位置Object get(int index):返回List中指定位置的元素int indexOf(Object o):返回第一个出现元素o的位置.Object remove(int index):删除指定位置的元素Object set(int index,Object element):用元素element取代位置index上的元素,返回被取代的元素void sort():排序
List中有两个主要的实现类:
- ArrayList:集合数据存储的结构为数组,所以查询快、增删慢 ```java import java.util.ArrayList; import java.util.List;
public class ListMain {
public static void main(String[] args) {
List
// add
list.add(1);
list.add(2);
list.add(3);
System.out.println(list); // [1, 2, 3]
list.add(1, 24);
System.out.println(list); // [1, 24, 2, 3]
// addAll
ArrayList<Integer> list2 = new ArrayList<>();
list2.addAll(0, list);
System.out.println(list2); // [1, 2, 3]
// remove
System.out.println(list.get(1)); // 24
System.out.println(list.remove(1)); // 24
System.out.println(list); // [1, 2, 3]
// set
list.set(0, 10);
System.out.println(list); // [10, 2, 3]
// indexOf
System.out.println(list.indexOf(2)); // 1
for(Integer ele: list){
System.out.println(ele);
}
}
}
> [**浅理解Java中的ArrayList**](https://blog.csdn.net/Forlogen/article/details/105610989)
- **LinkedList**:集合数据存储的结构为链表,方便元素的增删,但查询相对较慢。因为基于链表的底层实现,LinkedList中包含了大量直接操作首尾元素的方法。
```java
import java.util.LinkedList;
public class LinkedListMain {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
// 添加元素
list.add(1);
list.add(2);
list.add(3);
System.out.println(list); //[1, 2, 3]
list.addFirst(10);
list.addLast(24);
System.out.println(list); // [10, 1, 2, 3, 24]
list.push(11);
System.out.println(list ); // [11, 10, 1, 2, 3, 24]
// 获取元素
System.out.println(list.getFirst()); // 11
System.out.println(list.getLast()); // 24
// 移除元素
System.out.println(list.removeFirst()); // 11
System.out.println(list.removeLast()); // 24
System.out.println(list); // [10, 1, 2, 3]
list.pop();
System.out.println(list); // [1, 2, 3]
// 判空
System.out.println(list.isEmpty()); // false
}
}
- Vector:使用上了ArrayList类似,不同之处在线程的使用中有所区别
3.2 Set
Set接口的实现类中不允许存储重复的元素,而且没有索引。Set接口主要的实现类有:
- HashSet:它的特点是:
- 不允许存储重复的元素
- 没有索引,没有带索引的方法
- 无序集合
- 底层实现是哈希表,因此查询非常快 ```java import java.util.HashSet; import java.util.Iterator;
public class SetMain {
public static void main(String[] args) {
HashSet
// 遍历元素
Iterator<Integer> iter = set.iterator();
while (iter.hasNext()){
System.out.println(iter.next());
}
for(Integer ele : set){
System.out.println(ele );
}
}
}
> 哈希值:系统随即给出的一个十进制的整数(对象的逻辑地址,而不是数据实际存储的物理地址)。在Object类中可以通过`int hashCode()`方法得到对象的哈希值
> ```java
public native int hashCode(){};
```java public class Hash { public static void main(String[] args) { String s1 = “Forlogen”; String s2 = “kobe”;
System.out.println(s1.hashCode()); // 538205156
System.out.println(s2.hashCode()); // 3297447
}
}
HashSet存储数据的结构为哈希表:
- JDK1.8之前哈希表通过数组 + 链表实现
- JDK1.8之后哈希表通过数组 + 红黑树实现
其中数组存储数据的哈希值,链表和红黑树存储相同哈希值的数据。
<br />HashSet如何实现存储的数据不重复呢?原理是HashSet重写了`hashCode()`和`equals()`。例如String重写了`hashCode()`:
```java
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
以及equals():
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
示意图:

如上所示,list中包含有三个元素,那么在将其添加到HashSet中会有如下过程:
- 添加第一个”Forlogen”:调用
hashCode()计算它对应的哈希值538205156,在数组找发现没有这个值,那么将其存储到链表中 - 添加第二个”Forlogen”:调用
hashCode()计算它对应的哈希值538205156,在数组找发现已经这个值,然后是使用equals()判断它和相应哈希值存储的元素是否相同,发现相同,那么不存储 - 添加”kobe”:调用
hashCode()计算它对应的哈希值3297447,在数组找发现没有这个值,那么将其存储到链表中 - 添加”重地”:调用
hashCode()计算它对应的哈希值1179395,在数组找发现没有这个值,那么将其存储到链表中 - 添加”通话”:调用
hashCode()计算它对应的哈希值1179395,在数组找发现已经这个值,然后是使用equals()判断它和相应哈希值存储的元素是否相同,发现不相同,故将其存储到链表中
源码分析:HaseSet底层依赖于HashMap
public HashSet() {
map = new HashMap<>();
}
HashSet中的add()使用了HashMap中的put()
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
我们找到HashMap中的put(),发现它又调用了putval()方法进行判断
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
putval()的源码为:
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
如何利用HashSet来存储不重复的自定义类数据呢?同样我们需要重写hashCode()和equals(),假设现有Person类如下所示,如果我们不重写hashCode()和equals():
package Set;
import java.util.Objects;
public class Person{
private int age;
private String name;
public Person() {
}
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
那么在往HashSet中添加元素时就无法去重:
import java.util.HashSet;
public class SetMain {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person(18, "Forlogen"));
set.add(new Person(20, "kobe"));
set.add(new Person(20, "kobe"));
System.out.println(set); // [Person{age=20, name='kobe'}, Person{age=20, name='kobe'}, Person{age=18, name='Forlogen'}]
}
}
而如果我们重写hashCode()和equals():
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return getAge() == person.getAge() &&
Objects.equals(getName(), person.getName());
}
@Override
public int hashCode() {
return Objects.hash(getAge(), getName());
}
那么HashSet就可以正常的进行重复元素的去除:
import java.util.HashSet;
public class SetMain {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<>();
set.add(new Person(18, "Forlogen"));
set.add(new Person(20, "kobe"));
set.add(new Person(20, "kobe"));
System.out.println(set); // [Person{age=20, name='kobe'}, Person{age=18, name='Forlogen'}]
}
}
- LinkedhashSet:它的底层实现是哈希表(数组 + 链表/红黑树) + 链表,多加的链表用于记录元素的添加顺序,从而保证元素有序
- TreeSet
- 能够保证元素唯一性(根据返回值是否是0来决定的),并且按照某种规则排序
- 自然排序,无参构造方法(元素具备比较性)
- 按照compareTo()方法排序,让需要比较的元素所属的类实现自然排序接口Comparable,并重写compareTo()
- 底层是自平衡二叉树结构
- 二叉树有前序遍历、后序遍历、中序遍历
- TreeSet类是按照从根节点开始,按照从左、中、右的原则依此取出元素
- 当使用无参构造方法,也就是自然排序,需要根据要求重写compareTo()方法,这个不能自动生成

若有收获,就点个赞吧
0 人点赞
