 1. 概念
1. 概念
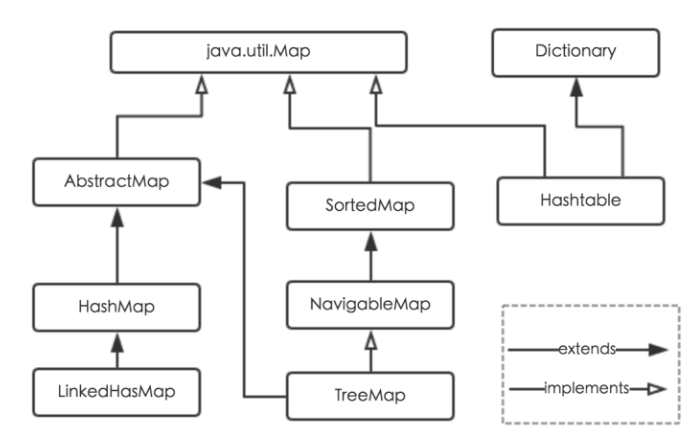
之前所学习的Collections接口下个不同的实现类,如Arrays、ArrayList、Stack、Queue、HaashSet等都属于单列集合的范畴,集合中的元素都是孤立存在的,当向集合中存储元素时只能一个个的存储。而Map接口下的各个集合类属于双列集合,即集合中的元素是以键值对的形式存在的。类似于Python中的dict,键和值一一对应且键不允许重复。
Map集合的特点有:
- Map集合是双列集合
- Map集合中的而元素,key和value的数据类型可以相同也可以不同
- Map集合中的元素,key不允许重复,value可以重复
- Map集合中的元素,key和value是一一对应的
在使用Map接口的实现类时需要注意如下事项:
- 给定一个键和一个值,你可以将该值存储在一个Map对象. 之后,你可以通过键来访问对应的值。
- 当访问的值不存在的时候,方法就会抛出一个NoSuchElementException异常.
- 当对象的类型和Map里元素类型不兼容的时候,就会抛出一个 ClassCastException异常。
- 当在不允许使用Null对象的Map中使用Null对象,会抛出一个NullPointerException 异常。
- 当尝试修改一个只读的Map时,会抛出一个UnsupportedOperationException异常。
2. Map的实现类
2.1 HashMap
2.1.1 获取和判断方法
Map接口下常使用有HashMap、LinkedHashMap和TreeMap等,下面我们通过代码来看下Map集合中常用的一些方法:
V put(K key, V value):把指定的键和值添加到Map集合中,存储键值对的时候,如果key不重复返回值为null;否则会用新的value覆盖掉之前的value,返回被替换后的valueV remove(Object key):指定的键所对应的键值对元素从Map集合中删除,返回被删除的值,如果key存在则返回被删除的值,否则返回nullV get(Object key):如果key存在则返回对应的value值,否则返回nullboolean containsKey(Object key):判断集合中是否包含指定的键boolean containsValue(Object value):判断集合中是否包含指定的值int hashCode( ):返回此映射的哈希码值boolean isEmpty( ):如果map未包含键-值映射关系,则返回 trueint size( ):返回此map中的键-值映射关系数boolean equals(Object obj):比较指定的对象与此映射是否相等
import java.util.HashMap;import java.util.Map;import java.util.Set;public class MapMain {public static void main(String[] args) {Map<Integer,String> m = new HashMap<>();/*public V put(K key, V value):把指定的键和值添加到Map集合中存储键值对的时候,如果key不重复返回值为null;否则会用新的value覆盖掉之前的value,返回被替换后的value*/m.put(10, "Forlogen");m.put(23, "James");System.out.println(m.put(24, "kobe")); // nullSystem.out.println(m); // {23=James, 24=kobe, 10=Forlogen}/*public V remove(Object key):把指定的键所对应的键值对元素从Map集合中删除,返回被删除的值如果key存在则返回被删除的值,否则返回null*/System.out.println(m.remove(1)); // nullSystem.out.println(m.remove(10)); // ForlogenSystem.out.println(m); // {23=James, 24=kobe}/*public V get(Object key):如果key存在则返回对应的value值,否则返回null*/System.out.println(m.get(23)); // JamesSystem.out.println(m.get(10)); // null/*public boolean containsKey(Object key):判断集合中是否包含指定的键*/System.out.println(m.containsKey(10)); // falseSystem.out.println(m.containsKey(23)); // true}}
2.1.2 集合遍历方法
Set<K> keySet():返回map中包含的所有键组成的Set视图Set entrySet():把Map集合内部得多个Entry对象取出来存储到一个Set集合中Map.Entry
是Map接口中的一个内部接口,当Map集合一创建,就会在Map集合中创建一个Entry对象用来记录键和值(键值对对象、键与值得映射关系)
上面的两个方法提供了两种用于遍历Map的方法,首先第一种是使用Set<K> keySet()方法,步骤如下:
- 使用Map集合的
keySet()把集合中所有的key取出来,存储到一个Set集合中 - 遍历set集合,获取Map集合中的每一个key
- 通过
get(key)获取key对应value
import java.util.HashMap;import java.util.Map;import java.util.Set;public class MapMain {public static void main(String[] args) {Map<Integer,String> m = new HashMap<>();m.put(10, "Forlogen");m.put(23, "James");m.put(24, "kobe");System.out.println(m); // {23=James, 24=kobe, 10=Forlogen}Set<Integer> keys = m.keySet();System.out.println(keys); // [23, 24]for(Integer ele : keys){System.out.println(m.get(ele));}}}
第二种方法是使用Map集合内部的Entry对象来进行遍历,具体步骤为:
- 使用Map集合中的
entrySet()把Map集合中得多个Entry对象取出来存储到一个Set集合中 - 遍历Set集合获取每一个Entry对象
- 使用Entry对象中的
getKey()和getValue()获取键和值
import java.util.HashMap;import java.util.Map;import java.util.Set;public class MapMain {public static void main(String[] args) {Map<Integer,String> m = new HashMap<>();m.put(23, "James");m.put(24, "kobe");System.out.println(m); // {23=James, 24=kobe}Set<Map.Entry<Integer, String>> entries = m.entrySet();System.out.println(entries); // [23=James, 24=kobe]for (Map.Entry ele: entries) {System.out.println(ele.getKey() + " = " + ele.getValue()); // 23 = Jame 24 = kobe}}}
default void forEach(BiConsumer<? super K,? super V> action):参数列表中传递BiConsumer接口的实例,通常可以传入一个Lambda表达式,表示对key和value要执行的一系列逻辑。如果执行遍历集合,简单的输出即可。 ```java import java.util.HashMap; import java.util.Map; import java.util.Set;
public class MapMain {
public static void main(String[] args) {
Map
m.forEach((k, v) -> System.out.println("key is: " + k + " and value is: " + v));/*key is: 23 and value is: Jameskey is: 24 and value is: kobe*/}
}
<a name="47da7408"></a>
##### 2.1.3 更新方法
如果使用`Map<String, Integer> m = new HashMap<>();`创建了map之后,使用`m.put(key, m.get(key) + 1)`更新给定键的值,并规则新的值是旧值 + 1:
- 如果map中存在key,则可以添加成功
- 如果map中没有指定的key,则会抛出空指针异常
一种改进方法是先使用`default V putIfAbsent(K key, V value)`,然后再使用上面的`put()`。如果key不存在,则首先将其设为`putIfAbsent()`传入的值,否则不执行操作。这样执行`put()`时就不会抛出异常了。
更好的方法是使用`default V merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)`方法进行操作。`merge()`的实现原理为:
```java
V oldValue = map.get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if (newValue == null)
map.remove(key);
else
map.put(key, newValue);
因此,当执行m.merge(key, 1, Integer::sum);时,如果当前key对应的值为空,则将其设置为1;否则将当前值加1作为新的值。加1的操作通过BiFunction()函数式接口完成,merge()中传入的是Integer的sum()的方法引用表达式。
package Map;
import java.util.HashMap;
import java.util.Map;
public class MapUpdate {
public static void main(String[] args) {
Map<String, Integer> m = new HashMap<>();
m.put("Forlogen", 10);
m.put("James", 23);
m.put("kobe", 24);
m.forEach((k, v) -> System.out.println("key is: " + k + " and value is: " + v));
System.out.println("-----------------");
// gengxin
String key = "Forlogen";
System.out.println("old value is: " + m.get(key));
m.put(key, m.get(key) + 1);
System.out.println("new value is: " + m.get(key));
System.out.println("-----------------");
// m.put("bill" , m.get("bill") + 1); // Exception in thread "main" java.lang.NullPointerException
// m.putIfAbsent("bill", 0);
// m.put("bill" , m.get("bill") + 1);
// m.forEach((k, v) -> System.out.println("key is: " + k + " and value is: " + v));
m.merge("bill", 1, Integer::sum);
m.forEach((k, v) -> System.out.println("key is: " + k + " and value is: " + v));
System.out.println("-----------------");
}
}
2.1.4 应用
HashMap中的键和值的数据类型可以是任意的,因此HashMap同样可以存储自定义的数据类型的数据:
- 如果自定义类型的数据作为map中的value存在,那么可以保证key是不重复的
- 如果自定义类型的数据作为key存在,那么自定义的类就必须重写
hashCode()和equals()方法来保证key的唯一性
假设现有有一个Person类,定义如下,类内部我们重写了hashCode()和equals()方法:
import java.util.Objects;
public class Person {
private int age;
private String name;
public Person() {
}
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return getAge() == person.getAge() &&
Objects.equals(getName(), person.getName());
}
@Override
public int hashCode() {
return Objects.hash(getAge(), getName());
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
当类定义完毕后,我们就可以使用hashMap进行存储:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapMain {
public static void main(String[] args) {
Map<String, Person> map = new HashMap<>();
map.put("China", new Person(10, "Forlogen"));
map.put("US", new Person(20, "kobe"));
System.out.println(map); // {China=Person{age=10, name='Forlogen'}, US=Person{age=20, name='kobe'}}
Set<String> set1 = map.keySet();
for (String ele: set1) {
System.out.println(map.get(ele)); // Person{age=10, name='Forlogen'} Person{age=20, name='kobe'}
}
Set<Map.Entry<String, Person>> entries1 = map.entrySet();
System.out.println(entries1); // [China=Person{age=10, name='Forlogen'}, US=Person{age=20, name='kobe'}]
for (Map.Entry ele: entries1) {
System.out.println(ele.getKey() + " = " + ele.getValue()); // China = Person{age=10, name='Forlogen'} US = Person{age=20, name='kobe'}
}
}
}
在HashMap之前使用的是HashTable,它也实现了Map接口,HashTable和HashMap的区别在于:
- HashTable底层实一个哈希表,是一个线程安全的集合,是单线程集合,速度慢;不能存储null值、null键
- HashMap底层也是哈希表,是一个线程不安全的集合,是多线程集合,速度快;可以存储null值、null键
2.2 LinkedHashMap
类似于Set接口中的HashSet和LinkedHashSet,HashMap对应的也有一个LinkedHashMap来使得Map中的元素是有序的。它的底层实现也是哈希表+链表,通过多加的链表来记录存储元素的顺序,从而实现Map中元素的有序性。
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapMain {
public static void main(String[] args) {
Map<Integer, String> m = new LinkedHashMap<>();
m.put(10, "Forlogen");
m.put(23, "James");
m.put(24, "kobe");
System.out.println(m); // {10=Forlogen, 23=James, 24=kobe}
}
}
对于HashMap更深入的讲解可阅读以下文章: Java 集合系列10之 HashMap详细介绍(源码解析)和使用示例 Java 8系列之重新认识HashMap

若有收获,就点个赞吧
0 人点赞
