函数式编程
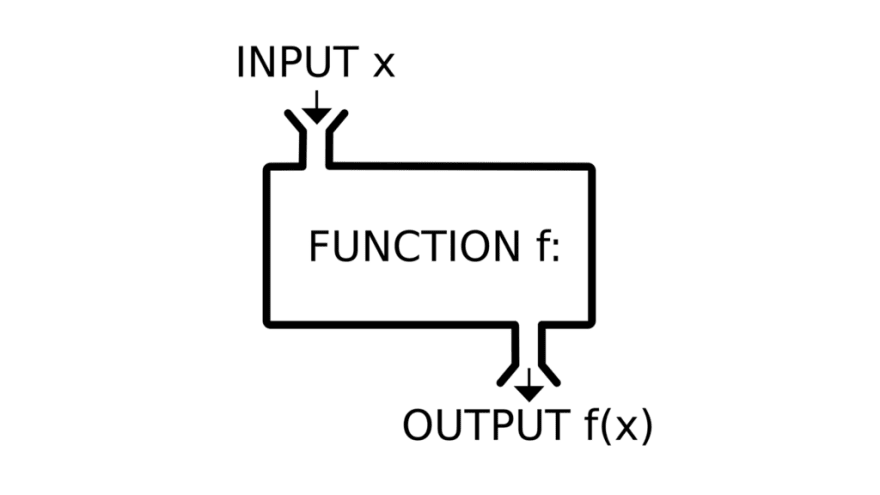
函数式编程,是指忽略(通常是不允许)可变数据(以避免它处可改变的数据引发的边际效应),忽略程序执行状态(不允许隐式的、隐藏的、不可见的状态),通过函数作为入参,函数作为返回值的方式进行计算,通过不断的推进(迭代、递归)这种计算,从而从输入得到输出的编程范式
虽然 functional 并不易于泛型复用,但在具体类型,又或者是通过 interface 抽象后的间接泛型模型中,它是改善程序结构、外观、内涵、质量的最佳手段。
所以你会看到,在成熟的类库中,无论是标准库还是第三方库,functional 模式被广泛地采用
下面介绍几种关于使用函数式编程的编程模式
算子
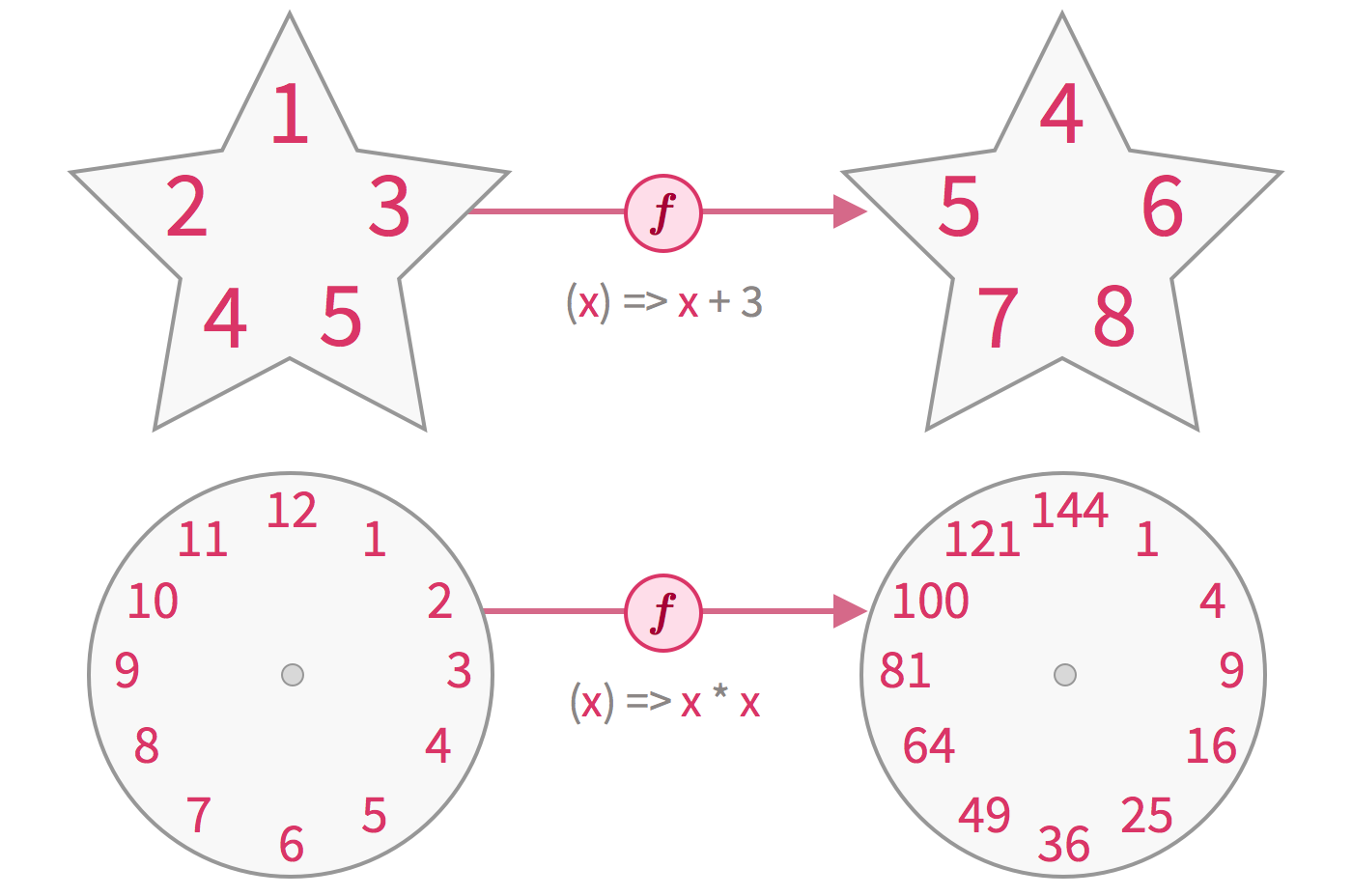
算子是一个函数空间到函数空间上的映射O:X→X, 简单说来就是进行某种“操作“,动作。与之对应的,就是被操作的对象,称之为操作数, 业务中 往往将可变部分抽象成算子,方便业务逻辑的替换
1.(x) -> x + 3
func main() {op := []int{1, 2, 3, 4, 5}target := AddThree(op, func(x int) int {return x + 3})fmt.Println(target)}type Functor func(x int) intfunc AddThree(operand []int, fn Functor) (target []int) {for _, v := range operand {target = append(target, fn(v))}return}
应用案例:
Map-Reduce

这是解耦数据结构和算法最常见的方式
Map
模式:
item1 --map func--> new1item2 --map func--> new2item3 --map func--> new3...
比如 我们写一个Map函数来将所有的字符串转换成大写
func TestMap(t *testing.T) {list := []string{"abc", "def", "fqp"}out := MapStrToUpper(list, func(item string) string {return strings.ToUpper(item)})fmt.Println(out)}func MapStrToUpper(data []string, fn func(string) string) []string {newData := make([]string, 0, len(data))for _, v := range data {newData = append(newData, fn(v))}return newData}
Filter
模式:
item1 -- reduce func --> xitem2 -- reduce func --> itme2item3 -- reduce func --> x
func TestFilter(t *testing.T) {list := []string{"abc", "def", "fqp", "abc"}out := ReduceFilter(list, func(s string) bool {return strings.Contains(s, "f")})fmt.Println(out)}func ReduceFilter(data []string, fn func(string) bool) []string {newData := []string{}for _, v := range data {if fn(v) {newData = append(newData, v)}}return newData}
Reduce
模式:
item1 --|item2 --|--reduce func--> new itemitem3 --|
比如写一个Reduce函数用于求和
func TestReduce(t *testing.T) {list := []string{"abc", "def", "fqp", "abc"}// 统计字符数量out1 := ReduceSum(list, func(s string) int {return len(s)})fmt.Println(out1)// 出现过ab的字符串数量out2 := ReduceSum(list, func(s string) int {if strings.Contains(s, "ab") {return 1}return 0})fmt.Println(out2)}func ReduceSum(data []string, fn func(string) int) int {sum := 0for _, v := range data {sum += fn(v)}return sum}
应用案例: 班级统计
通过上面的一些示例,你可能有一些明白,Map/Reduce/Filter只是一种控制逻辑,真正的业务逻辑是在传给他们的数据和那个函数来定义的。是的,这也是一种将数据和控制分离经典方式
比如我们有这样一个数据集合:
type Class struct {Name string // 班级名称Number uint8 // 班级编号Students []*Student // 班级学员}type Student struct {Name string // 名称Number uint16 // 学号Subjects []string // 数学 语文 英语Score []int // 88 99 77}
1.统计有多少学生数学成绩大于80
2.列出数学成绩不及格的同学
2.统计所有同学的数学平均分
修饰器

这种模式很容易的可以把一些函数装配到另外一些函数上,可以让你的代码更为的简单,也可以让一些“小功能型”的代码复用性更高,让代码中的函数可以像乐高玩具那样自由地拼装,
比如我们有Hello这样一个函数
func main() {Hello("boy")}func Hello(s string) {fmt.Printf("hello, %s\n", s)}
需求1: 打印函数执行时间
应用案例: HTTP中间件
package mainimport ("fmt""net/http")func main() {http.ListenAndServe(":8848", http.HandlerFunc(hello))}func hello(w http.ResponseWriter, r *http.Request) {fmt.Fprintf(w, "hello, http: %s", r.URL.Path)}
需求1: 打印AccessLog
需求2: 为每个请求设置RequestID
需求3: 添加BasicAuth
优化: 多个修饰器的Pipeline
在使用上,需要对函数一层层的套起来,看上去好像不是很好看,如果需要 decorator 比较多的话,代码会比较难看了。嗯,我们可以重构一下
重构时,我们需要先写一个工具函数——用来遍历并调用各个 decorator
type HttpHandlerDecorator func(http.HandlerFunc) http.HandlerFuncfunc Handler(h http.HandlerFunc, decors ...HttpHandlerDecorator) http.HandlerFunc {// A, B, C, D, E// E(D(C(B(A))))for i := range decors {d := decors[len(decors)-1-i] // iterate in reverseh = d(h)}return h}
Functional Options

若有收获,就点个赞吧
0 人点赞
