Go语言Map
map 的设计也被称为 “The dictionary problem”,它的任务是设计一种数据结构用来维护一个集合的数据,并且可以同时对集合进行增删查改的操作
Go里的map用于存放key/value对,在其它地方常称为hash、dictionary、关联数组,这几种称呼都是对同一种数据结构的不同称呼,它们都用于将key经过hash函数处理,然后映射到value,实现一一对应的关系
映射是存储一系列无序的 key/value 对,通过 key 来对 value 进行操作(增、删、改、查)。
声明与初始化
1.声明
map 声明需要指定组成元素 key 和 value 的类型,在声明后,会被初始化为 nil,表示
暂不存在的映射
var m map[string]int // *hmapfmt.Printf("%p\n", m)
2.初始化
可以通过make()创建map,它会先创建好底层数据结构,然后再创建map,并让map指向底层数据结构。
var m map[string]intm = make(map[string]int)fmt.Printf("%p\n", m)
3.声明并初始化
也可以直接通过大括号创建并初始化赋值
m := map[string]int{"Tony": 22, "Andy": 55}fmt.Println(m)
4.限制
Go 语言中只要是可比较的类型都可以作为 key。除开 slice,map,functions 这几种类型,其他类型都是 OK 的。
具体包括:布尔值、数字、字符串、指针、通道、接口类型、结构体、只包含上述类型的数组。
这些类型的共同特征是支持 == 和 != 操作符,k1 == k2 时,可认为 k1 和 k2 是同一个 key。
如果是结构体,则需要它们的字段值都相等,才被认为是相同的 key
var m1 map[string]stringvar m2 map[int]intvar m3 map[float64]stringvar m4 map[string]AddFunc
nil map和空map
空map是不做任何赋值的map:
a := map[int]string
nil map,它将不会做任何初始化,不会指向任何数据结构:
var a map[int]string
如何map没初始化,直接赋值会报空指针
var a map[int]stringvar b []stringfmt.Printf("%p, %p\n", a, b)// a[0] = "a"// b[0] = "a"a = map[int]string{0: "a"}b = []string{"a"}fmt.Printf("%p, %p\n", a, b)
所以,map类型实际上就是一个指针, 具体为 *hmap
元素访问
1.访问key的值, 格式 key_value = map_var[key_value]
检索map中key对应的value值。如果key不存在,则value返回值对应数据类型的0。例如int为数值0,布尔为false,字符串为空””
a := map[int]string{}fmt.Println(a[0])
2.判断key是否存在, 格式: key_value, is_exist = map_var[key_value]
当key存在时,value为对应的值,is_exist为true;当key不存在,value为0(同样是各数据类型所代表的0),is_exist为false。
a := map[int]string{}fmt.Println(a[0])a[100] = "t1"v1, ok1 := a[100]fmt.Println(ok1, v1)v2, ok2 := a[0]fmt.Println(ok2, v2)
3.测试map中元素是否存在
a[100] = "t1"if v, ok := a[100]; ok {fmt.Println(v)}
元素删除
通过使用delete内置函数 用删除map中的元素
a := map[int]string{100: "t1"}delete(a, 100)fmt.Println(a)
注意: 删除不存在的元素, 是不会有任何保存, 如果需要判断key是否存在,请自己判断
a := map[int]string{100: "t1"}delete(a, 99)
len
len()函数用于获取map中元素的个数,即有多个少key。delete()用于删除map中的某个key
元素迭代
因为map是key/value类型的数据结构,key就是map的index,所以range关键字对map操作时,将返回key和value
1.迭代key和value
2.只迭代key
map作为函数参数
map是一种指针,所以将map传递给函数,仅仅只是复制这个指针,所以函数内部对map的操作会直接修改外部的map
a := map[int]string{1: "a", 2: "b", 3: "c"}func(map[int]string) {delete(a, 1)}(a)fmt.Println(a)
map值为函数
op := map[string]func(x, y int) int{"+": func(x, y int) int {return x + y},"-": func(x, y int) int {return x - y},"*": func(x, y int) int {return x * y},"/": func(x, y int) int {return x / y},}fmt.Println(op["+"](1, 2))fmt.Println(op["-"](1, 2))
扩展
以下为Go Map源码相关解读, 源码位置: src/runtime/map.go,
更详细的内容可以参考 曹大的笔记: map
内存模型
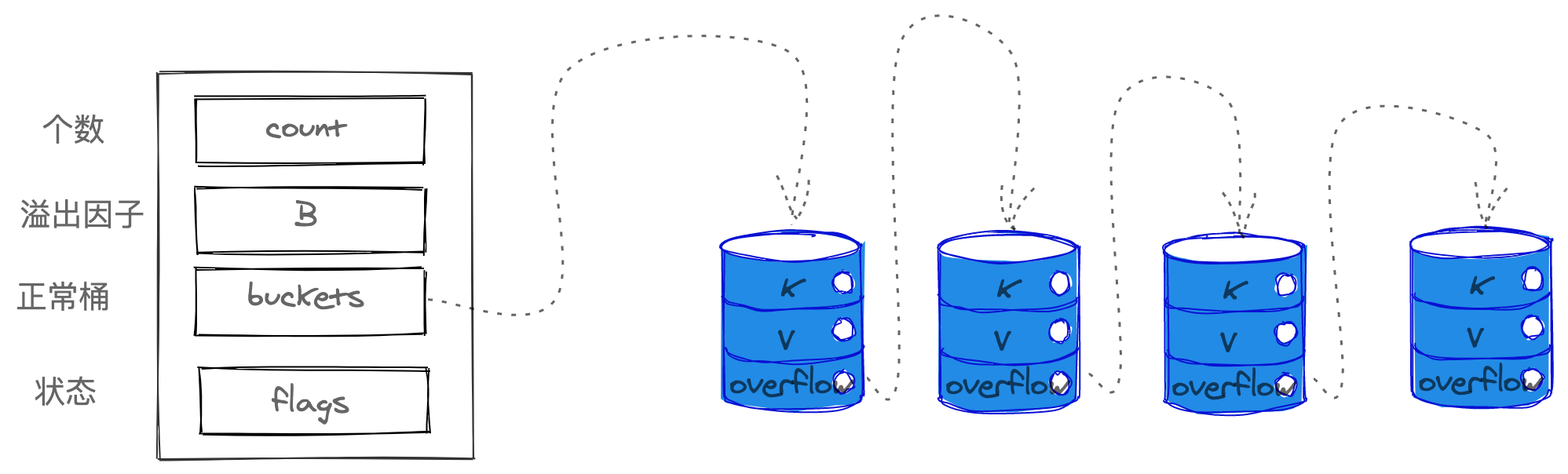
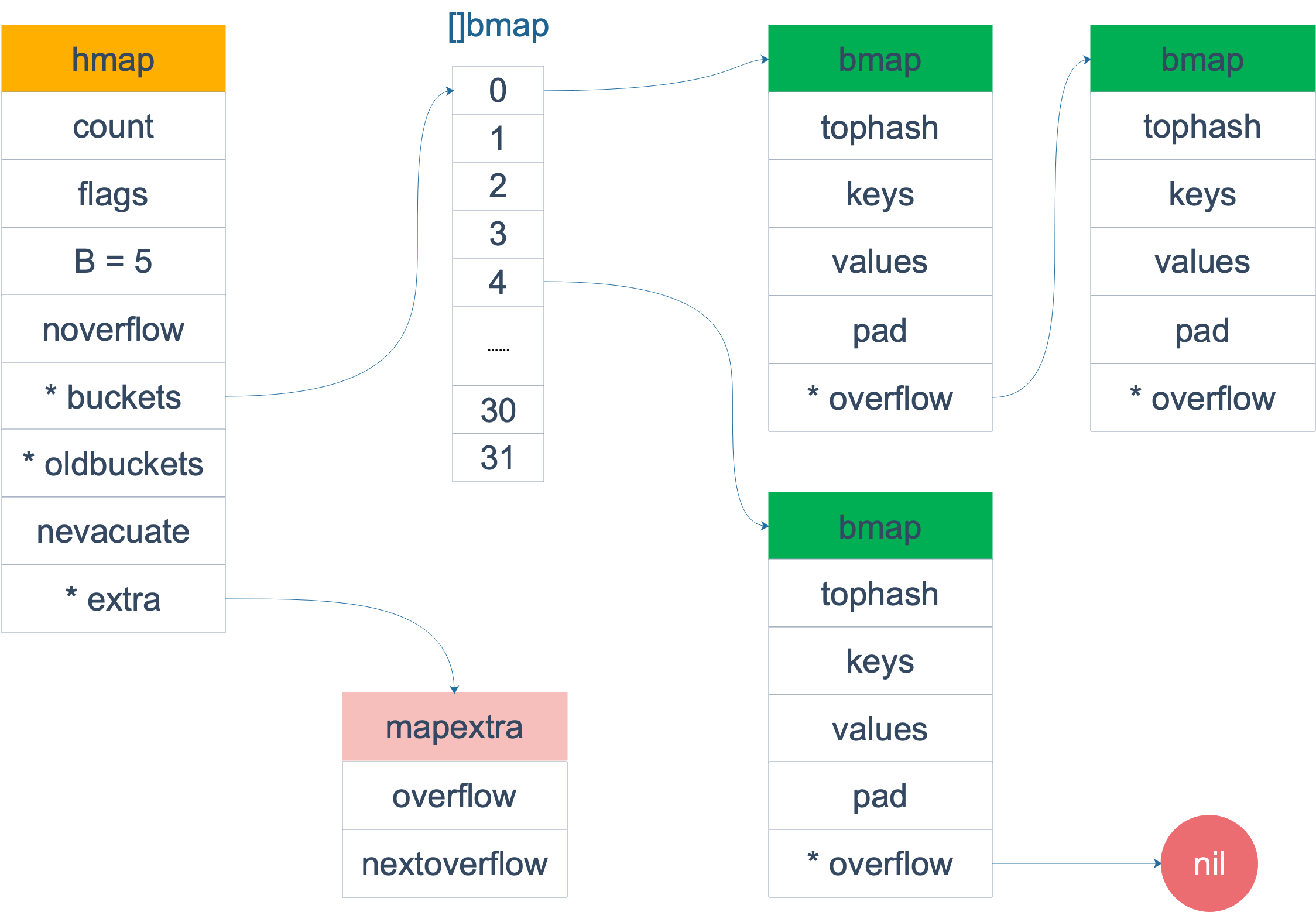
源码中,表示 map 的结构体是 hmap,它是 hashmap 的“缩写”
// A header for a Go map.type hmap struct {// 元素个数,调用 len(map) 时,直接返回此值count intflags uint8// buckets 的对数 log_2B uint8// overflow 的 bucket 近似数noverflow uint16// 计算 key 的哈希的时候会传入哈希函数hash0 uint32// 指向 buckets 数组,大小为 2^B// 如果元素个数为0,就为 nilbuckets unsafe.Pointer// 扩容的时候,buckets 长度会是 oldbuckets 的两倍oldbuckets unsafe.Pointer// 指示扩容进度,小于此地址的 buckets 迁移完成nevacuate uintptrextra *mapextra // optional fields}
该结构中用于存储key value的数据结构是 buckets([]bmap), 其中bmap就是我们常说的“桶”,桶里面最多装 8 个元素(key-value)
如果有第 9 个 元素 落入当前的 bucket,那就需要再构建一个 bucket ,通过 overflow 指针连接起来
下面是一张全局图
创建过程
m1 := make(map[string]int)// 指定 map 长度m2 := make(map[string]int, 8)
我们可以看到创建的核心是 根据用户提供的map大小,计算出需要初始化的bucket, 计算bucket数量的核心指标是 装载因子
装载因子:用于衡量bucket的装载情况, 计算公式: loadFactor := count / (2^B)
- count: map 的元素个数
- 2^B :bucket 数量
装载因子超过阈值,源码里定义的阈值是 6.5, 就需要分配一个扩展了(B++), 一次计算逻辑: count / 2^B < 6.5
// loadFactorNum 13// overLoadFactor reports whether count items placed in 1<<B buckets is over loadFactor.func overLoadFactor(count int, B uint8) bool {return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)}
下面是makemap的具体过程:
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {// 省略各种条件检查...// 找到一个 B,使得 map 的装载因子在正常范围内B := uint8(0)for ; overLoadFactor(hint, B); B++ {}// 初始化 hash table// 如果 B 等于 0,那么 buckets 就会在赋值的时候再分配// 如果长度比较大,分配内存会花费长一点buckets := bucketvar extra *mapextraif B != 0 {var nextOverflow *bmapbuckets, nextOverflow = makeBucketArray(t, B)if nextOverflow != nil {extra = new(mapextra)extra.nextOverflow = nextOverflow}}// 初始化 hampif h == nil {h = (*hmap)(newobject(t.hmap))}h.count = 0h.B = Bh.extra = extrah.flags = 0h.hash0 = fastrand()h.buckets = bucketsh.oldbuckets = nilh.nevacuate = 0h.noverflow = 0return h}
元素存取过程
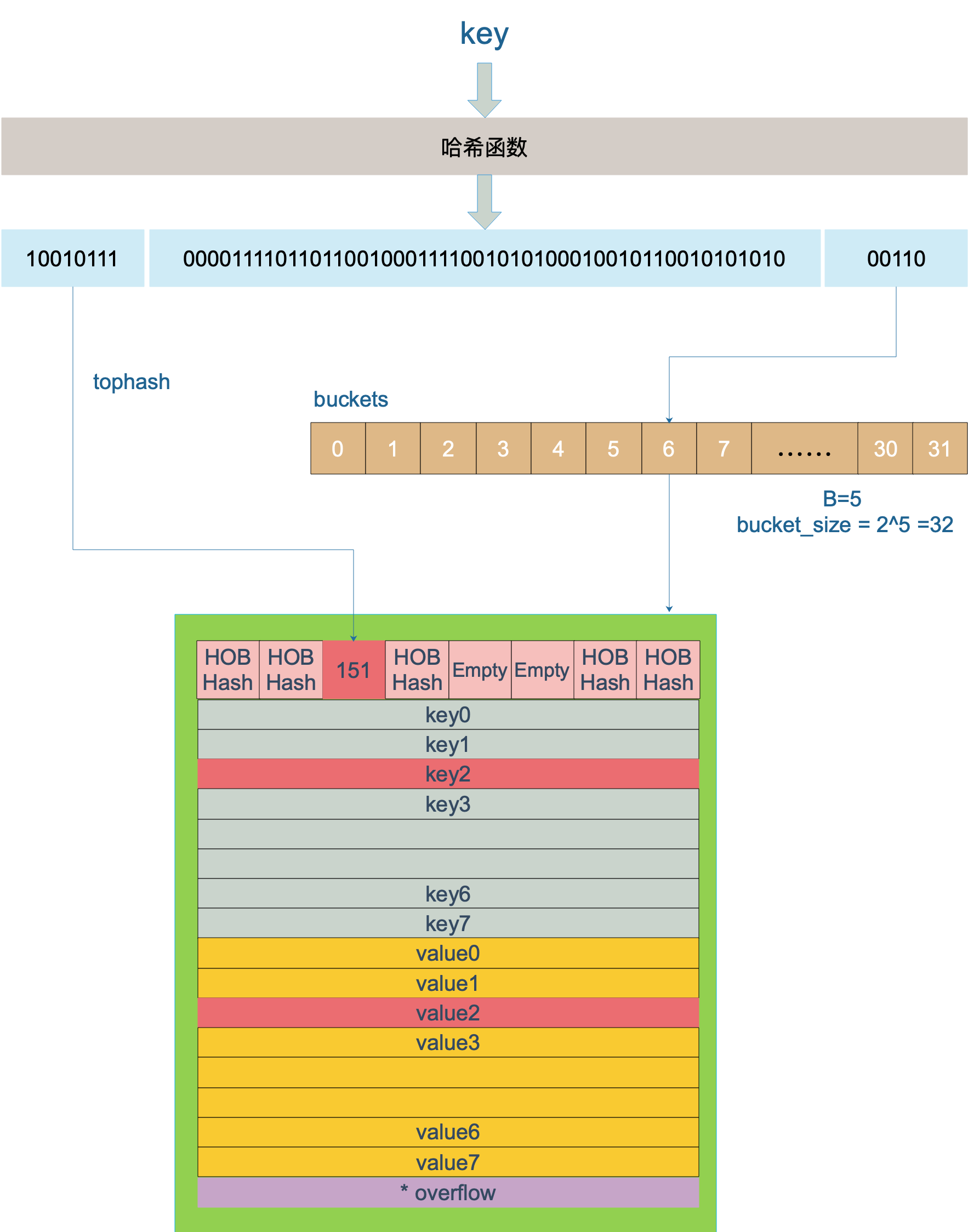
key 经过哈希计算后得到哈希值,共 64 个 bit 位, 然后通过这个hash来决定我们元素放那个桶的那个槽
- bucket编号: 用最后的5个bit位作为bucket的编号
- key放置槽: 用哈希值的高 8 位(top hash)标识存放的槽的位置, 最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入
如何进行扩容
1.触发条件
在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容
- 装载因子超过阈值,源码里定义的阈值是 6.5,表明很多 bucket 都快要装满了,查找效率和插入效率都变低了。在这个时候进行扩容是有必要的
- overflow 的 bucket 数量过多,即 map 里元素总数少,但是 bucket 数量多,导致 key 会很分散,查找插入效率都变低了, 这就像是一座空城,房子很多,但是住户很少,都分散了,找起人来很困难
- 当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B
- 当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15
2.扩容策略:
- 装载因子超过阈值的扩容策略:将 B 加 1,bucket 最大数量(2^B)直接变成原来 bucket 数量的 2 倍。于是,就有新老 bucket 了。注意,这时候元素都在老 bucket 里,还没迁移到新的 bucket 来。而且,新 bucket 只是最大数量变为原来最大数量(2^B)的 2 倍(2^B * 2)
- overflow 的 bucket 数量过多扩展策略: 开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密, 这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升
3.元素搬迁
经过上面的扩容, 但是元素并没有迁移
由于 map 扩容需要将原有的 key/value 重新搬迁到新的内存地址,如果有大量的 key/value 需要搬迁,会非常影响性能。因此 Go map 的扩容采取了一种称为“渐进式”地方式,原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket
因此搬迁时(插入或修改、删除 key 的时候), 都会尝试进行搬迁 buckets 的工作, 根据bucketmask, 进行重新hash, 然后再次均衡
所谓的 bucketmask,作用就是将 key 计算出来的哈希值与 bucketmask 相与,得到的结果就是 key 应该落入的桶。比如 B = 5,那么 bucketmask 的低 5 位是 11111,其余位是 0,hash 值与其相与的意思是,只有 hash 值的低 5 位决策 key 到底落入哪个 bucket

若有收获,就点个赞吧
0 人点赞
