字符串

字符串是 Go 语言中的基础数据类型,虽然字符串往往被看做一个整体,但是它实际上是一片连续的内存空间,我们也可以将它理解成一个由字符组成的数组
a := "hello"fmt.Println([]byte(a)) // [104 101 108 108 111]
unicode与UTF8
a := "hello"b := []byte(a)fmt.Println(b, len(a), len(b))
像上面一个byte就是代表一个字符, 所以字符长度也是5
我们看看下面这个例子:
fmt.Println(len("谷歌中国"), []byte("谷歌中国")) // 12 [232 176 183 230 173 140 228 184 173 229 155 189]
这就涉及到unicode与utf8的理解
unicode: 又称为unicode字符集或者万国码, 就是将全球所有语言的字符 通过编码, 比如 104 -> h , 101 ->e (兼容assicc码), 本质就是一张大的码表
utf8: unicode的一种具体实现, 理论上unicode是没有范围限制的, 只要有想收录进去 都可以, 但是我们在传输过程中 如何表示他却是一个问题
- 1个Byte肯定不够
- 10个Byte 对于101 这种比较小的说又太浪费
所以utf8使用变长字节编码, 来表示这些unicode码, 编码规则如下:
如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的位数,其余各字节均以10开头。UTF-8最多可用到6个字节。
如表:
1字节 0xxxxxxx // assicc码 本来就是7个bit表示,所以完全兼容2字节 110xxxxx 10xxxxxx3字节 1110xxxx 10xxxxxx 10xxxxxx4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
我们再来看看这个byte数字的二进制表示
for _, v := range []byte("谷歌中国") {fmt.Printf("%b\n", v)}// 11101000// 10110000// 10110111 1 1000 110000 110111// 11100110// 10101101// 10001100 2// 11100100// 10111000// 10101101 3// 11100101// 10011011// 10111101 4fmt.Printf("%c\n", 0b1000110000110111) // 谷
如何通过程序解出来, 只要涉及到一些位运算
data := []byte{232, 176, 183}for i, v := range data {if i == 0 {fmt.Printf("%b\n", v&0b1111)continue}fmt.Printf("%b\n", v&0b111111)}code := 0b1000<<12 + 0b110000<<6 + 0b110111fmt.Printf("%b -> %c\n", code, code)// 1000// 110000// 110111// 1000110000110111 -> 谷
字符串的本质
字符串是由字符组成的数组。数组会占用一片连续的内存空间,而内存空间存储的字节共同组成了字符串,Go 语言中的字符串只是一个只读的字节数组
数据结构定义位置runtime/string.go
type stringStruct struct {str unsafe.Pointerlen int}
所以上面的该结构在内存中的存储结构为:
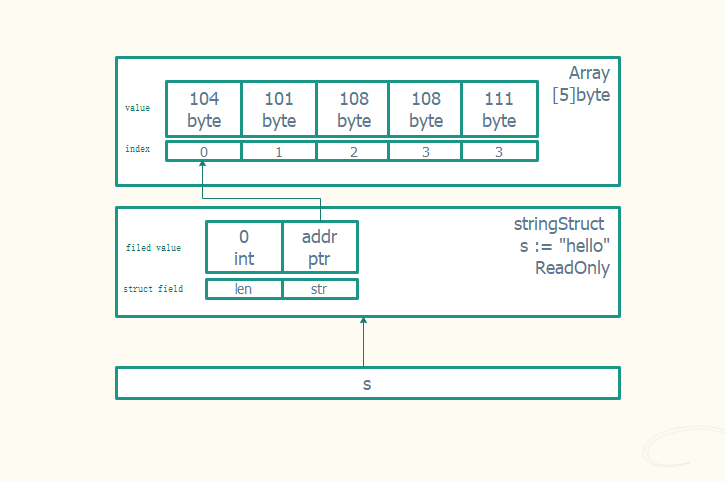
在Golang语言规范里面,string数据是禁止修改的,试图通过&s[0], &b[0]取得string和slice数据指针地址也是行不通的, 因为编译器读到字符串,会将其标记成只读数据 SRODATA,只读意味着字符串会分配到只读的内存空间, 这些值不能修改
我们可以通过汇编看到这个过程:
go tool compile -S ./day3/main/main.go...go.string."hello" SRODATA dupok size=50x0000 68 65 6c 6c 6f hello...
但是我们可以转换为byte数组,这个可以修改的
a := "hello"b := []byte(a)b[0] = 'x'fmt.Println(string(b)) // 但是这个过程涉及到3次数据拷贝
但是除了切片的修改操作,其他操作都可以用
a := "hello"fmt.Println(len(a), a[0], a[1:3])
但是仅仅这些操作也太捉襟见肘了, 因此Go标准库提供了strings包,用于实现字符串的一些常规操作
字符串比较
// Compare 函数,用于比较两个字符串的大小,如果两个字符串相等,返回为 0。如果 a 小于 b ,返回 -1 ,反之返回 1 。不推荐使用这个函数,直接使用 == != > < >= <= 等一系列运算符更加直观。func Compare(a, b string) int// EqualFold 函数,计算 s 与 t 忽略字母大小写后是否相等。func EqualFold(s, t string) bool
fmt.Println(strings.Compare("ab", "cd"))fmt.Println(strings.EqualFold("ab", "AB"))
是否存在某个字符或子串
// 子串 substr 在 s 中,返回 truefunc Contains(s, substr string) bool// chars 中任何一个 Unicode 代码点在 s 中,返回 truefunc ContainsAny(s, chars string) bool// Unicode 代码点 r 在 s 中,返回 truefunc ContainsRune(s string, r rune) bool
子串出现次数
在 Go 中,查找子串出现次数即字符串模式匹配, Count 函数的签名如下
func Count(s, sep string) int
fmt.Println(strings.Count("cheese", "e"))fmt.Println(len("谷歌中国"))fmt.Println(strings.Count("谷歌中国", ""))
字符切分
通过分隔符来切割字符串提供了这样一组函数
func Split(s, sep string) []string { return genSplit(s, sep, 0, -1) }func SplitAfter(s, sep string) []string { return genSplit(s, sep, len(sep), -1) }func SplitN(s, sep string, n int) []string { return genSplit(s, sep, 0, n) }func SplitAfterN(s, sep string, n int) []string { return genSplit(s, sep, len(sep), n) }
这4个函数都是通过genSplit内部函数来实现的, 通过 sep 进行分割,返回[]string。如果 sep 为空,相当于分成一个个的 UTF-8 字符,如 Split(“abc”,””),得到的是[a b c]
func genSplit(s, sep string, sepSave, n int) []string
1.Split 和 SplitAfter区别:
str := "abc,DEF,MQP"fmt.Println(strings.Split(str, ","))fmt.Println(strings.SplitAfter(str, ","))// [abc DEF MQP]// [abc, DEF, MQP]
Split 会将 s 中的 sep 去掉,而 SplitAfter 会保留 sep
2.SplitN 和 Split的却别
str := "abc,DEF,MQP"fmt.Println(strings.Split(str, ","))fmt.Println(strings.SplitN(str, ",", 2))
带 N 的方法可以通过最后一个参数 n 控制返回的结果中的 slice 中的元素个数
- 当 n < 0 时,返回所有的子字符串;
- 当 n == 0 时,返回的结果是 nil;
- 当 n > 0 时,表示返回的 slice 中最多只有 n 个元素,其中,最后一个元素不会分割
判断前缀和后缀
// s 中是否以 prefix 开始func HasPrefix(s, prefix string) bool// s 中是否以 suffix 结尾func HasSuffix(s, suffix string) bool
字符串拼接
将字符串数组(或 slice)连接起来可以通过 Join 实现,函数签名如下:
func Join(a []string, sep string) string
计算子串位置
查询子串的开始Index的函数有:
func Index(s, sep string) int // 在 s 中查找 sep 的第一次出现,返回第一次出现的索引func IndexByte(s string, c byte) int // 在 s 中查找字节 c 的第一次出现,返回第一次出现的索引func IndexAny(s, chars string) int // chars 中任何一个 Unicode 代码点在 s 中首次出现的位置func IndexRune(s string, r rune) int // Unicode 代码点 r 在 s 中第一次出现的位置func IndexFunc(s string, f func(rune) bool) int // 查找字符 c 在 s 中第一次出现的位置,其中 c 满足 f(c) 返回 true
str := "abc,DEF,MQP,abc,DEF,MQP"fmt.Println(strings.Index(str, "DEF"))
查找字串的结束Index的函数有:
// 有三个对应的查找最后一次出现的位置func LastIndex(s, sep string) intfunc LastIndexByte(s string, c byte) intfunc LastIndexAny(s, chars string) intfunc LastIndexFunc(s string, f func(rune) bool) int
str := "abc,DEF,MQP,abc,DEF,MQP"fmt.Println(strings.LastIndex(str, "DEF"))
子串Count
func Repeat(s string, count int) string
字符和子串替换
字符替换: Map
func Map(mapping func(rune) rune, s string) string
Map 函数,将 s 的每一个字符按照 mapping 的规则做映射替换,如果 mapping 返回值 <0 ,则舍弃该字符。该方法只能对每一个字符做处理,但处理方式很灵活,可以方便的过滤,筛选汉字等
str := "hello"new := strings.Map(func(c rune) rune {if c == 'h' {return 'm'}return c}, str)fmt.Println(new)
字符串替换:
func Replace(s, old, new string, n int) string // 用 new 替换 s 中的 old,一共替换 n 个。 如果 n < 0,则不限制替换次数,即全部替换func ReplaceAll(s, old, new string) string // 该函数内部直接调用了函数 Replace(s, old, new , -1)
大小写转换
// ToLower,ToUpper 用于大小写转换func ToLower(s string) stringfunc ToUpper(s string) string// ToLowerSpecial,ToUpperSpecial 可以转换特殊字符的大小写func ToLowerSpecial(c unicode.SpecialCase, s string) stringfunc ToUpperSpecial(c unicode.SpecialCase, s string) string
剔除子串
func Trim(s string, cutset string) string // 将 s 左侧和右侧中匹配 cutset 中的任一字符的字符去掉func TrimLeft(s string, cutset string) string // 将 s 左侧的匹配 cutset 中的任一字符的字符去掉func TrimRight(s string, cutset string) string // 将 s 右侧的匹配 cutset 中的任一字符的字符去掉func TrimPrefix(s, prefix string) string // 如果 s 的前缀为 prefix 则返回去掉前缀后的 string , 否则 s 没有变化。func TrimSuffix(s, suffix string) string // 如果 s 的后缀为 suffix 则返回去掉后缀后的 string , 否则 s 没有变化。func TrimSpace(s string) string // 将 s 左侧和右侧的间隔符去掉。常见间隔符包括:'\t', '\n', '\v', '\f', '\r', ' ', U+0085 (NEL)func TrimFunc(s string, f func(rune) bool) string // 将 s 左侧和右侧的匹配 f 的字符去掉func TrimLeftFunc(s string, f func(rune) bool) string // 将 s 左侧的匹配 f 的字符去掉func TrimRightFunc(s string, f func(rune) bool) string // 将 s 右侧的匹配 f 的字符去掉

若有收获,就点个赞吧
0 人点赞
