Fastq格式文件储存了生物序列的信息及其质量信息。以电脑中的一个文件的为例$ zcat SRR8518347.fq.gz |head
每合成一个碱基,即可发出一个荧光信号,该信号可以被捕捉到,并生成是是轨迹数据。不同的碱基用不同颜色标记,检测相应峰值即可判断碱基。
而Phred通过计算相应波峰参数,去查询通过已知序列测序分析得到的一个表,即可把错误率转换为质量得分。也就是把波峰参数和质量得分对应起来。
碱基错误率与质量得分的关系如下
如果直接把Q值直接对应ASCII码,应该挺方便的,但是,Q值有时会有负值,再者,看ASCII码的0-31位都是控制字符,没法打印和保存,能打印的从要从32位的Space开始,所以就可以给实际的Q值加上一个固定值,这样就可以打印出来而保存在fastq文件中了。
所以下面就是固定值加多少的问题。phred33,就是加了33,也就是10变成43,查表是+。例子中很多F,Q值是70-33=37。而当时的solexa加的是64,这就是Phred64.他们与ASCII的对应关系如下
@SRR8518347.1 1 length=150GTATTTTCTAAGACGTAATGCTACTTTACACTTAACAGACTACAGTATAGTGTAAACGTAACGGTTATGTCCACTAGGAAACCAAAATATTCGTGTTACTTGCTTTACTGTACTTGTTTTATTTCAGTAGTCGGGAACTAAACTCACAGT+SRR8518347.1 1 length=150AAA,,F<F,FKKAFFF<FFFKF<FA,KKFFKKKKKKKKKF,AKFK,A7<FKK,AFFKKFKKKA,AFF,FKAKKKA<FFKAFKKKKKA,F<KKKKFFKKKKK,FKKAKAKKKKF7FFFAKFAFFKK7,,FF<F,,<,AA<KAFKKKKKAF,@SRR8518347.2 2 length=150CCAGCTAATTTTTGTATTACTAGTAGAGACGGGGTTTCACCAGGTTGGTCAGGATGGTCCTGAACTCCTGAGCTCAGGCGATCCACCCACCTCAGCCTCCCAAAGTGGTAGGATTACAGGCGTGAGATCGGAAGAGCACACGTCTGAACT+SRR8518347.2 2 length=150AAAFAAFFFKKFFKKKKKKKKKKKKFKKA7FKKK(FFFKKKFFFKK,A,7F,FFKK,FK7AKKFKKK,FKA,AFF7<AA<AAFFFKFK<KKK,FKFFKKKKKKKKA,,7FKKKFKKK7FAFKAA7,A7FF,FFAK7<FAAFKKKK7FFF7
1 格式说明
第一行:必须@开头,紧跟唯一的序列的ID标识符,后面可跟其他描述性内容,但序列ID与描述部分空格分开,这点很重要,是很多分析的基础
第二行:序列的顺序,基本不可能出现重复。这里是核酸。
第三行:必须+开头,后面可以跟描述信息,此处是跟了第一行的信息。但为了节约空间,很多时候这一行只有一个+,而不跟任何内容。
第四行:碱基或氨基酸(此处碱基)的质量字符,对应着第二行的碱基,反应的是该碱基的错误率,所以这一行的字符数和第二行要一一对应,否则就乱了。这里就引入了ASCII code。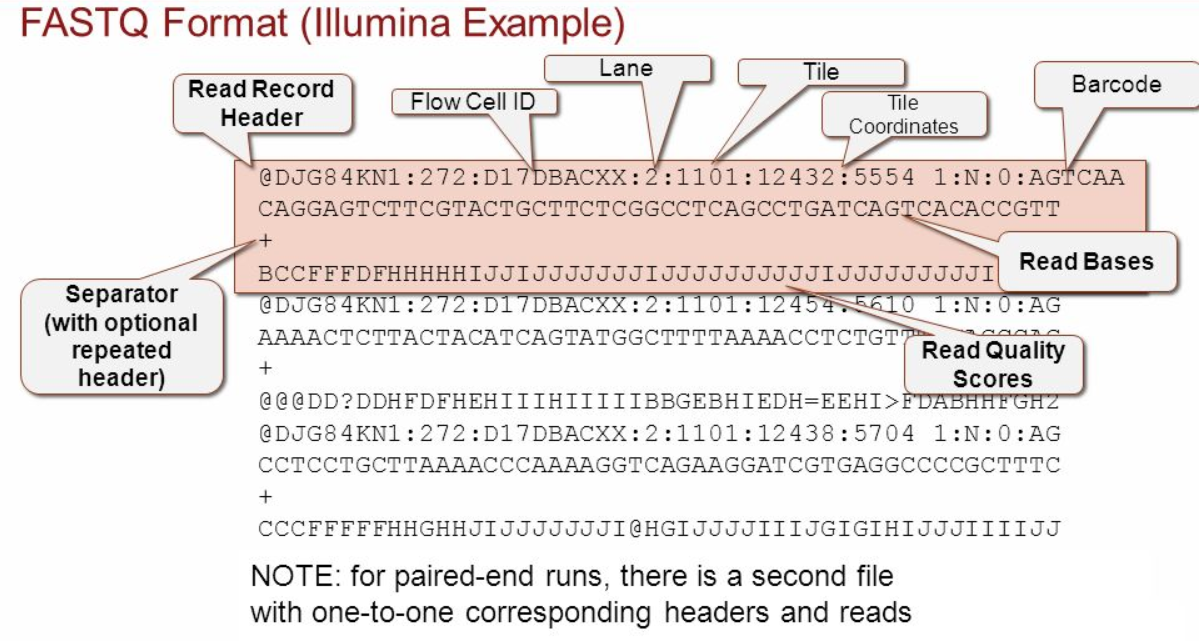
fastq format 1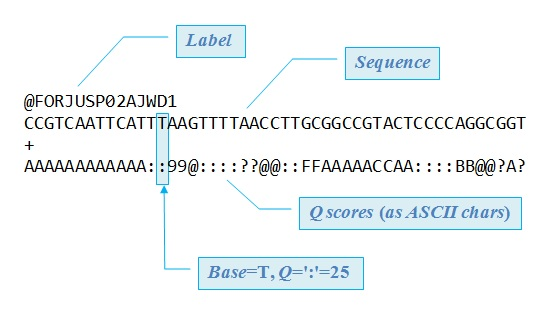
fastq format 2
所以引入下面,碱基质量值是什么,如何获得?怎么表示?如何转换?
2 碱基质量值Q值和ASCII码之间的关系
因为第四行的编码,开始由Phred程序开发者定义,所以一般称为Phred quality。那碱基质量得分怎么来的?

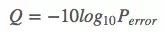
Phred quality score
也就是说,质量值Q是测序错误率的对数*-10。假如错误率是0.01,则Q值为20。可见,错误率越低,其Q值越高。即Q值越高越可靠。
Q10——0.1
Q20——0.01
Q30——0.001
Q40——0.0001
那就直接以上面这种Q值表示碱基质量不就行了吗?为什么要用ASCII码表示。
如果用数字表示,数字和数字之间需要有间隔符号以区分,再者会浪费存储空间,所以可以把质量值转变为相应的ASCII码,这样就完成了把质量数向ASCII码的转换,那现在看下ASCII码


数据处理时,有些软件会根据碱基质量得分的不同做不同处理,所以需要指定正确的编码方式,也就是需要对Phred33还是64正确判断。不过现在基本都33了,但如果下载以前的数据不一定。
下面是不同版本质量得分和质量字符ASCII的关系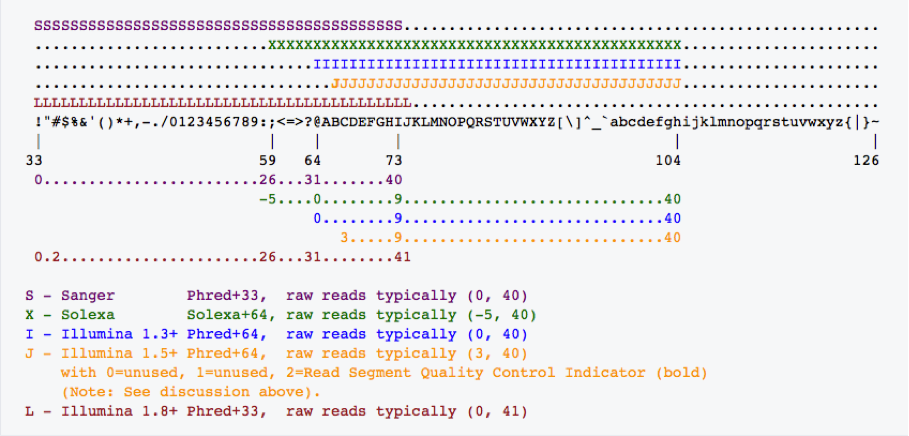
不同测序标记中的Phred的使用
从上面可以看出,Phred33的字符使用33-73,而+64使用包括59(包括)-104之间的ASCII码。所以,只要ASCII小于59的仅仅在Phred+33中使用,而+64的都大于59,而从表可以看到大于等于74的旨在Phred+74中使用,所以,如果软件没有自动判断,根据以上特点,就可以自行判断是Phred33还是Phred64。
3 如何判断是Phred33还是Phred64
默认读取1000条序列,在这1000条序列中:
- 如果有2个以上的质量字符ASCII值小于等于58(即有两个碱基的得分小于等于25),同时没有任何质量字符的ASCII值大于等于75,即判断是Phred+33。
- 如果有2个以上的质量字符ASCII值大于等于75(即有两个碱基的得分大于等于10),同时没有任何质量字符的ASCII值小于等于58,即判断是Phred+64。
- 如果所有质量字符的ASCII值介于59到74之间,即判断可能是Phred+33,但建议使用更多的序列做进一步测试(出现这种结果可能有两种情况:1, Phred+33编码,所有碱基质量得分介于26到42之间;2,Phred+64编码,所有碱基质量得分介于-5到10;是前者的可能性大)。
- 如果出现上述3种以外的情况,建议打印出质量字符的ASCII值人工判断。
脚本如下less $1 | head -n 1000 | awk '{if(NR%4==0) printf("%s",$0);}' \| od -A n -t u1 -v \| awk 'BEGIN{min=100;max=0;} \{for(i=1;i<=NF;i++) {if($i>max) max=$i; if($i<min) min=$i;}}END \{if(max<=126 && min<59) print "Phred33"; \else if(max>73 && min>=64) print "Phred64"; \else if(min>=59 && min<64 && max>73) print "Solexa64"; \else print "Unknown score encoding"; \
sh fq_qual_type.sh example.fq

若有收获,就点个赞吧
0 人点赞
