Zookeeper简单原理概述
Zookeeper = 文件系统 + 通知机制
旦这些被观察的数据状态发生变化,Zookeeper就负责通知已经在Zookeeper上注册的那些观察者让他们做出相应的反应。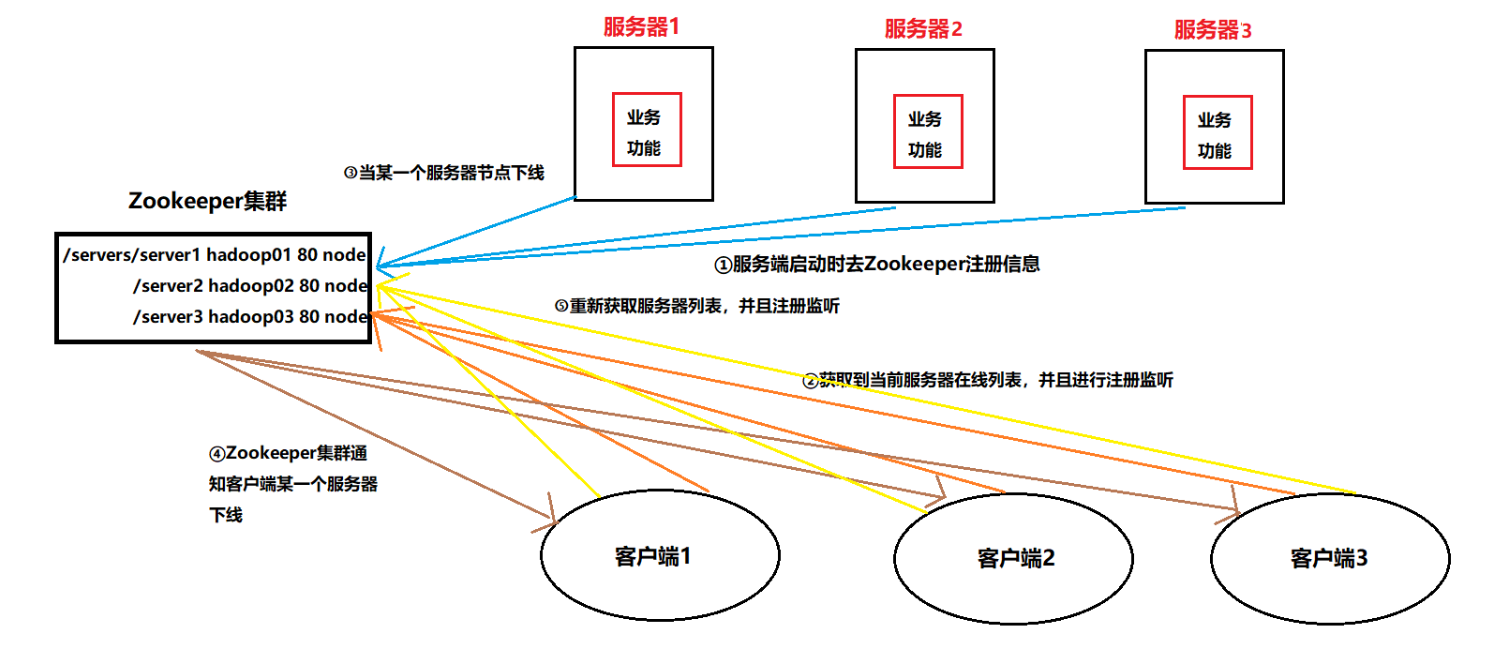
Zookeeper数据模型
理解ZooKeeper的一种方法是将其看做一个具有高可用性的文件系统。但这个文件系统中没有文件和目录,而是统一使用节点(node)的概念,称为znode。znode既可以保存数据(如同文件),也可以保存其他znode(如同目录)。所有的znode构成一个层次化的数据结构,。
Persistent Nodes: 永久有效地节点,除非client显式的删除,否则一直存在
Ephemeral Nodes: 临时节点,仅在创建该节点client保持连接期间有效,一旦连接丢失,zookeeper会自动删除该节点
Sequence Nodes: 顺序节点,client申请创建该节点时,zk会自动在节点路径末尾添加递增序号,这种类型是实现分布式锁,分布式queue等特殊功能的关键
zookeeper日志有三类:快照(虽然不是日志但是它是数据)、事务日志(记录每次操作)、zookeeper自己系统日志。第三个不属于数据类所以这里不做说明。
三、Zookeeper特点
【1】Zookeeper是存在一个领导者(Leader)和多个跟随者(Follower) 组成的集群。
【2】集群中若存在半数以上的(服务器存活数量必须大于一半,小于等于一半都不行)节点存活,就能正常工作。
【3】数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪一个Server获取的数据都是一样的。
【4】更新请求按发送的顺序依次执行。
【5】数据更新原子性原则,要么一次更新成功,要么失败。
【6】实时性,Client能够读取到最新的数据。
理解ZooKeeper的一种方法是将其看做一个具有高可用性的文件系统。但这个文件系统中没有文件和目录,而是统一使用节点(node)的概念,称为znode。znode既可以保存数据(如同文件),也可以保存其他znode(如同目录)。所有的znode构成一个层次化的数据结构.
4.1 数据发布于订阅
4.1.1 特性、用法
发布与订阅即所谓的配置管理,顾名思义就是将数据发布到zk节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如:全局的配置信息、地址列表等。
4.1.2 具体用法
索引信息和集群中机器节点状态放在zk的一些指定节点,供各个客户端订阅使用。
系统日志(经处理后)存储,这些日志通常2-3天后清除。
应用中用到的一些配置信息集中管理,在应用启动的时候主动来获取一次,并在节点上注册一个Watcher,以后每次配置有更新,实时通知到应用,获取最新的配置信息。
业务逻辑中需要用到的一些全局变量,比如一些消息中间件的消息队列通常有个offset,这个offset存放在zk上,这样集群中每个发送者都能知道当前的发送进度。
系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息。以前通常是暴露出接口,例如JMX接口,有了zk后,只要将这些信息存放到zk节点上即可。
4.3 分布通知/协调
4.3.1 特性、用法
ZooKeeper中特有的watcher注册于异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对zk上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点内容),其中一个系统update了znode,那么另一个系统能够收到通知,并做出相应处理。
使用ZooKeeper来进行分布式通知和协调能够大大降低系统之间的耦合。
4.4.1 特性、用法
分布式锁,主要得益于ZooKeeper保证数据的强一致性,即zk集群中任意节点(一个zk server)上系统znoe的数据一定相同。
锁服务可以分为两类:
保持独占锁:所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看做是一把锁,通过create znode的方式来实现。所有客户端都去创建/distribute_lock节点,最终成功创建的那个客户端也即拥有了这把锁。临时节点
控制时序锁:所有试图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。与保持独占锁的做法类似,不同点是/distribute_lock已经预先存在,客户端在它下面创建临时有序节点(可以通过节点控制属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而形成每个客户端的全局时序。
四、Zookeeper的选举机制
【1】半数机制:集群中半数以上的机器存活,集群就可以正常工作,所以Zookeeper适合安装奇数台服务器。
【2】ZooKeeper虽然在配置中没有指定Master和Slave,但是Zookeeper在工作时会有一个节点成为Leader,其他的则为Follower,Leader是通过内部的选举机制临时产生的。
六、监听器原理
【1】首先要有一个main()线程。
【2】在main()线程中创建一个Zookeeper客户端,这个时候机会创建两个线程,一个负责网络连接通信(Connect),另外一个负责监听(Listener)。
【3】通过Connect线程将注册的监听事件发送给Zookeeper集群。
【4】在Zookeeper的注册监听器列表中添加注册的监听事件。
【5】Zookeeper监听到有数据或者路径发生变化,就会把消息发送给Listener线程。
【6】Listener线程就会调用内部process()方法处理业务。
Zookeeper分布式锁的原理
Zookeeper分布式锁恰恰应用了临时顺序节点。具体如何实现呢?让我们来看一看详细步骤:
获取锁
首先,在Zookeeper当中创建一个持久节点ParentLock。当第一个客户端想要获得锁时,需要在ParentLock这个节点下面创建一个临时顺序节点 Lock1。
之后,Client1查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock1是不是顺序最靠前的一个。如果是第一个节点,则成功获得锁。
这时候,如果再有一个客户端 Client2 前来获取锁,则在ParentLock下载再创建一个临时顺序节点Lock2。 Client2查找ParentLock下面所有的临时顺序节点并排序,判断自己所创建的节点Lock2是不是顺序最靠前的一个,结果发现节点Lock2并不是最小的。
于是,Client2向排序仅比它靠前的节点Lock1注册Watcher,用于监听Lock1节点是否存在。这意味着Client2抢锁失败,进入了等待状态。 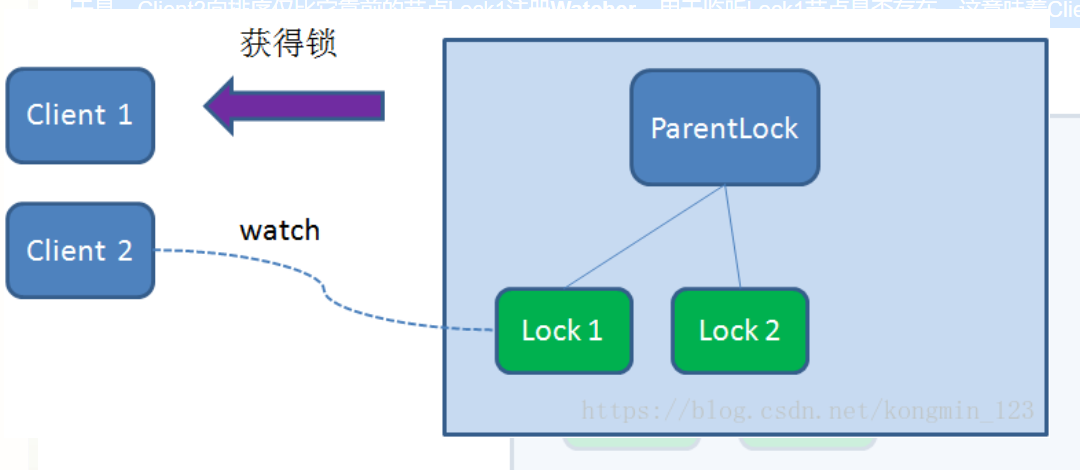
提出一个想法,当你面对双十一这种业务处理时,你是选择AP还是CP呢?
个人想法是在面对这种业务处理时,先保证可用性也就是AP原则(服务器不能瘫痪),在过了双十一高峰,再核对数据,保证数据一致性。
Zookeeper与Eureka区别

Zookeeper的设计理念就是分布式协调服务,保证数据(配置数据,状态数据)在多个服务系统之间保证一致性,这也不难看出Zookeeper是属于CP特性(Zookeeper的核心算法是Zab,保证分布式系统下,数据如何在多个服务之间保证数据同步)。Eureka是吸取Zookeeper问题的经验,先保证可用性。

若有收获,就点个赞吧
0 人点赞
