4 吐槽微服务
需求分析
采用SpringDataMongoDB框架实现吐槽微服务的持久层。
实现功能:
(1)基本增删改查API
2)根据上级ID查询吐槽列表
3)吐槽点赞
4)发布吐槽
1.1 吐槽和评论数据特点分析
吐槽和评论两项功能存在以下特点:
(1)数据量大
2)写入操作频繁
3)价值较低 允许有几个漏掉的,MongoDB没有事务,还有bug,数据结构稀散,规定不严格
对于这样的数据,我们更适合使用MongoDB来实现数据的存储
相当主键,名字设成下划线 _id
Use 数据库名字,直接创建并使用
数据结构很松散
Jpa与mybatis比较应用场景
可能我这么说大家还是不太理解什么时候用jpa什么时候用mybatis。我举个例子:现在业务上A,B,C,D四个表。如果你每个表都会在业务中用到,都需要有单独的增删改查,虽然有一定的关联关系,但是这种情况用jpa就比较合适。ABCD四个java实体不说,每个实体要对应一个repository。然后再repository层进行crud的编写。但是如果业务上A,B,C,D四个表。这四个是关联关系,你几乎不会单独对A,B,C进行操作,而且展现出来的也是D,那么这个时候jpa的使用就会很麻烦,因为你还是要四个实体四个repository。在一个接口中四个repository挨个调用一次。虽然也能完成业务逻辑,但是复杂又麻烦。还要考虑原子性什么的。所以这个时候用mybatis比较合适了。
Mybatis与jpa区别
hibernate是全自动,但mybatis是半自动。hibernate完全可以通过对象关系模型实现对数据库的操作,拥有完整的JavaBean对象与数据库的映射结构来自动生成sql,而mybatis仅有基本的字段映射,对象数据以及对象实际关系仍然需要通过手写sql来实现和管理。Mybatis可以配置动态SQL并优化SQL,通过配置决定SQL的映射规则,它还支持存储过程等。对于一些复杂的和需要优化性能的项目,使用Mybatis更加合适。
@Repository注解修饰哪个类,则表明这个类具有对对象进行CRUD(增删改查)的功能
由源码可知CrudRepository 中的save方法是相当于merge+save ,它会先判断记录是否存在,如果存在则更新,不存在则插入记录
实现增删改查有两种方法,一个是默认的findAll,findById,等等
但是如果要自己的定义,就要实现Repository接口,内部会动态解析名字生成特定动态的sql语句
例如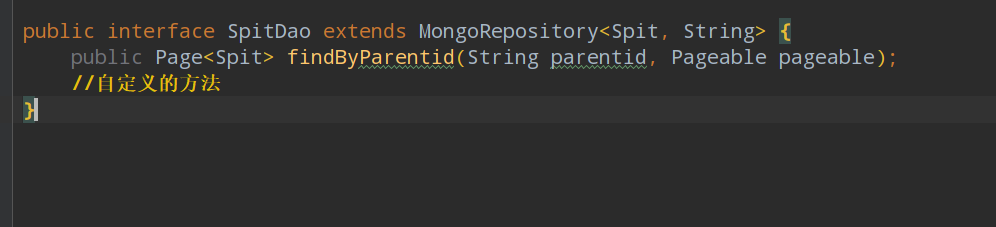
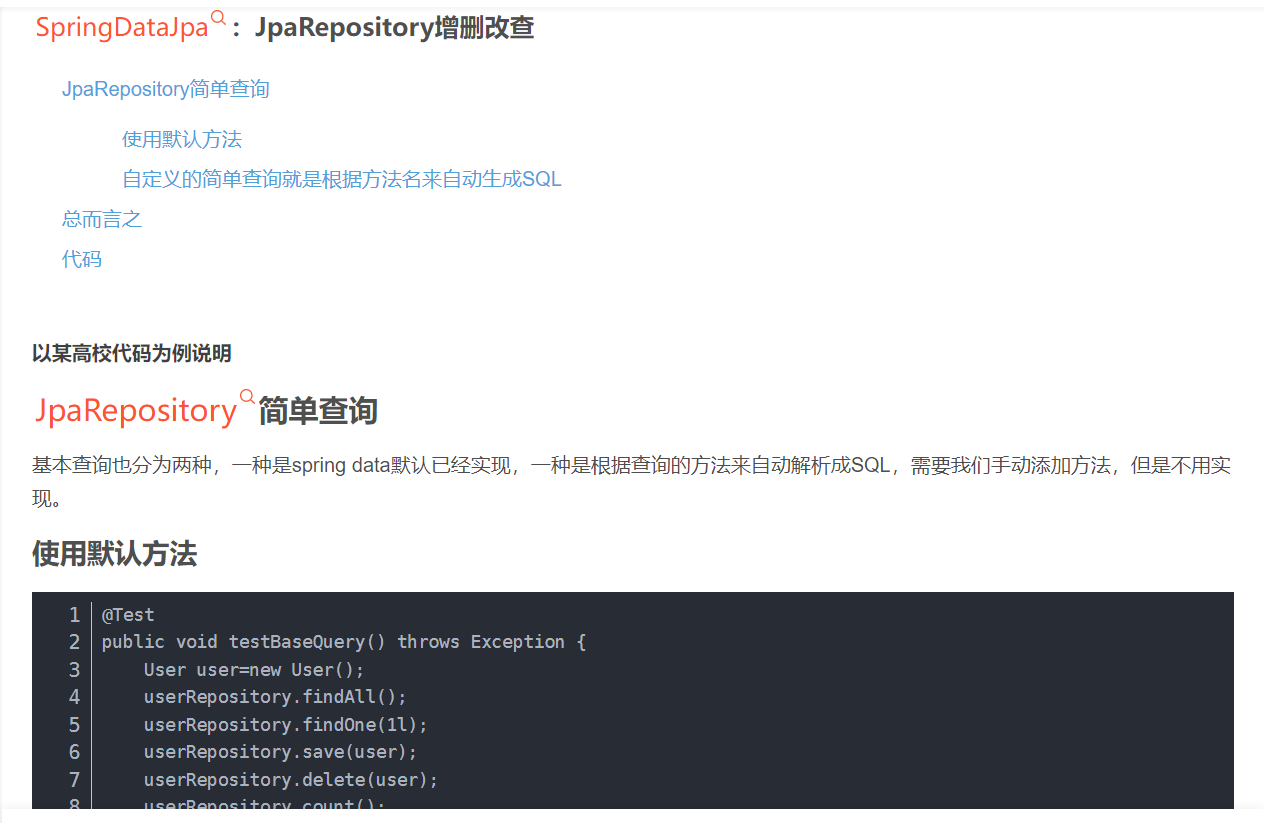
Jpa本质利用动态代理生成一个对象去生成SQL语句操作数据库,一般mybatis用的多,而且国内热,jpa语法学习成本高,国内会的人少。调试麻烦
Mybatis本质通过配置文件去与Java对象映射,解析配置文件中的SQL语句从而操作数据库
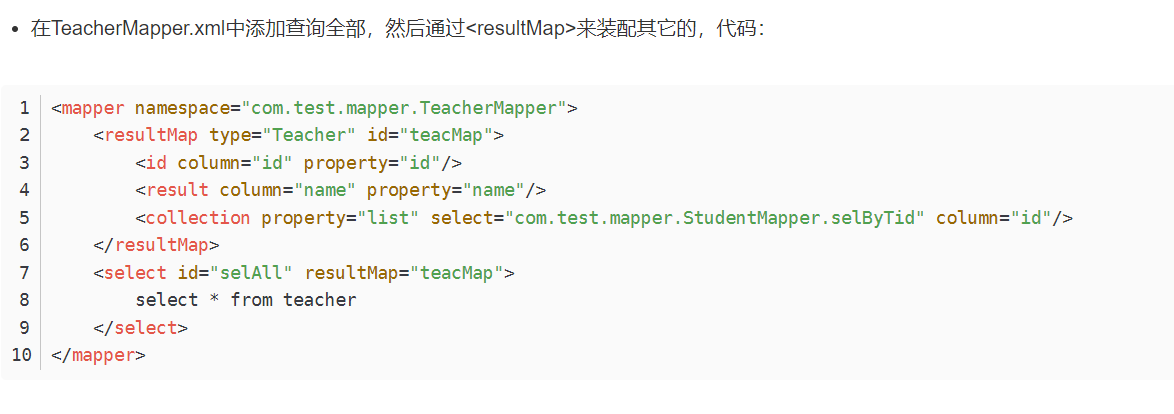
Mybatis实现多表查询
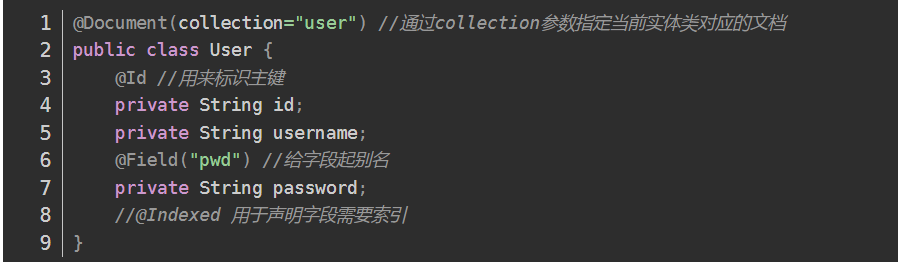
spring-data对MongoDB做了支持
使用spring-data-mongodb可以简化MongoDB的操作。 继承 MongoRepository
两种方法
SpringData为我们提供了两种方式对数据库进行操作,
第一种是继承Repository接口,
第二种是直接使用Template的方式对数据进行操作。
第一种方式,直接继承xxxRepository接口,其最终将会继承Repository标记接口,我们可以不必自己写实现类,轻松实现增删改查、分页、排序操作,但是对于比较复杂的查询,使用起来就比较费力。
第二种方式,直接使用xxxTemplate,这需要自己写实现类,但是这样增删改查可以自己控制,对于复杂查询,用起来得心应手。
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如 inc…)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是
false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条
记录全部更新。
writeConcern :可选,抛出异常的级别。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排
序的一种结构
#说明:1表示升序创建索引,-1表示降序创建索引。
#创建索引
> db.user.createIndex({‘age’:1})


新增save方法(相当于insert+update方法)
Insert在jpa里是add方法
insert和save方法均能用于新增操作,其区别在于,在使用insert时,如果主键存在,那么就会报异常,而对于save方法,如果主键存在,就会更新已经存在的数据。
MongoDB操作流程自己的理解
创建实体类pojo 加上id注解,加上Document注解,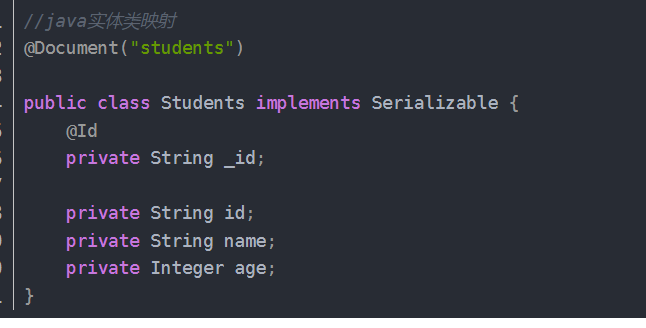
所以虽然我们这里定义的是接口,但是真正发挥作用的还是接口的实现类(在程序执行过程中,自动的帮助我们动态的生成了接口的实现类对象)
如何动态的生成实现类对象,就牵扯出来我们前面学过的动态代理(生成基于接口的实现类对象)
(1)通过JdkDynamicAopProxy的invoke方法创建了一个动态代理对象
(2)SimpleJpaRepository当中封装了JPA的操作(借助JPA的api完成数据库的CRUD)
(3)通过hibernate完成数据库操作(封装了jdbc)
首先Method类代表一个方法,所以invoke(调用)就是调用Method类代表的方法。它可以让你实现动态调用,例如你可以动态的传人参数。
控制不能重复点赞
我们可以通过redis控制用户不能重复点赞
判断缓存里是否有这条记录,有就返回false,没有就添加
如果存在上级id,评论数就加1
如果为0表示文章的顶级评论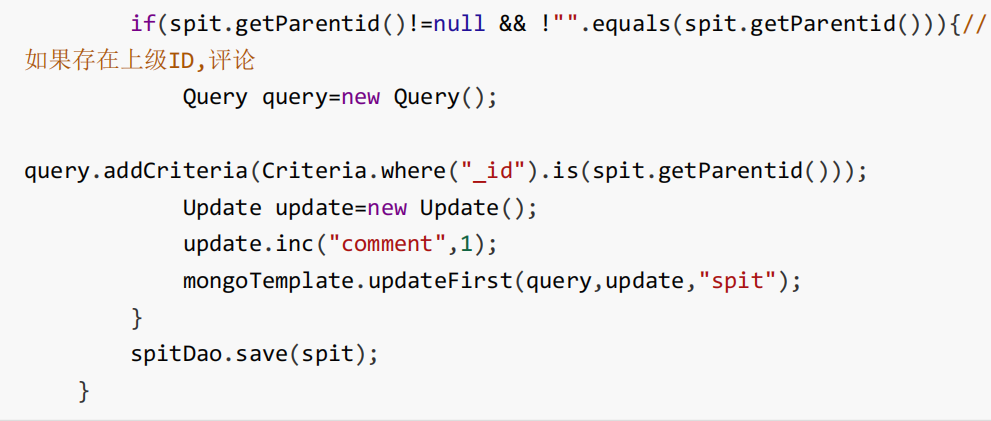
Springcloud分布式事务解决(LCN)
一、什么是LCN 框架
LCN: 锁定事务单元(lock)、确认事务模块状态(confirm)、通知事务(notify)
它的宗旨 : LCN 并不生产事务,LCN 只是本地事务的协调工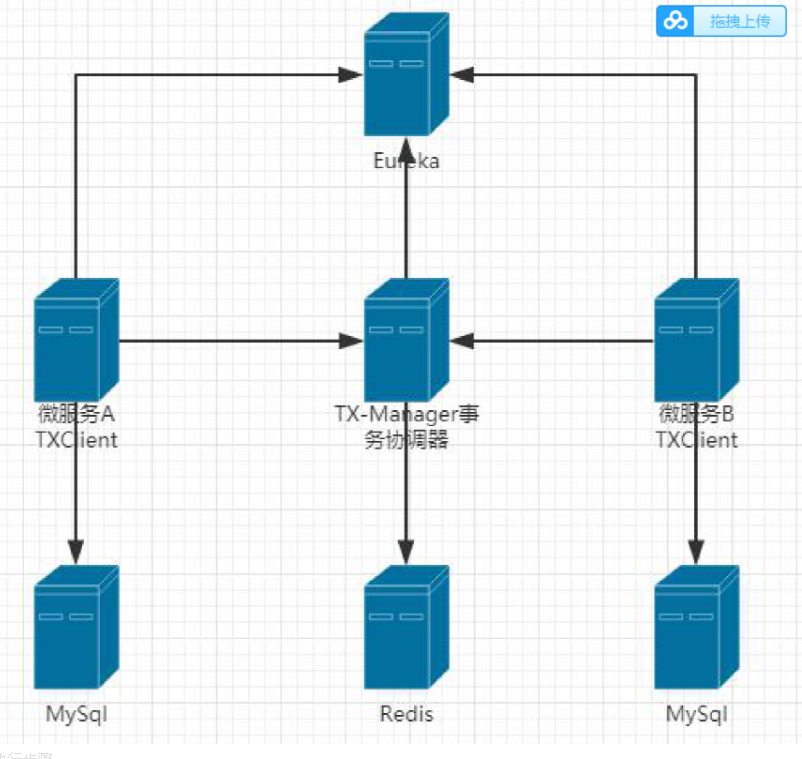
在上图中,微服务A,微服务B,TxManager 事务协调器,都需要去Eureka 中注册服务。
Eureka 是用于TxManager 与其他服务之间的相互服务发现。
redis 是用于存放我们事务组的信息以及补偿的信息。
然后微服务A 与微服务B 他们都需要去配置上我们TxClient 的包架构(代码的包架构)
LCN 执行步骤
创建事务组
事务组是指的我们在整个事务过程中把各个节点(微服务)单元的事务信息存储在一个固定单元里。
但这个信息并不是代表是事务信息,而是只是作为一个模块的标示信息。
创建事务组是指在事务发起方开始执行业务代码之前先调用TxManager 创建事务组对象,
然后拿到事务标示GroupId 的过程。
添加事务组
添加事务组是指参与方在执行完业务方法以后,将该模块的事务信息添加通知给TxManager 的操作。
关闭事务组
是指在发起方执行完业务代码以后,将发起方执行结果状态通知给TxManager 的动作。
当执行完关闭事务组的方法以后,TxManager 将根据事务组信息来通知相应的参与模块提交或回滚事务。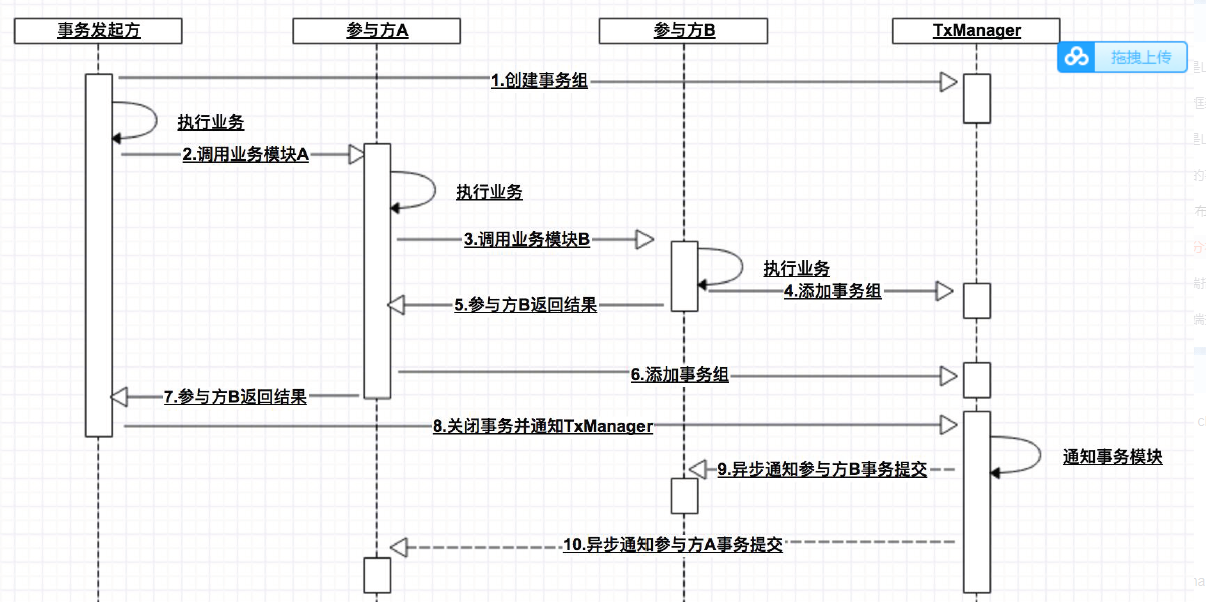
模式一:lcn
LCN模式是通过代理Connection的方式实现对本地事务的操作,然后在由TxManager统一协调控制事务。当本地事务提交回滚或者关闭连接时将会执行假操作,该代理的连接将由LCN连接池管理。
缺点:
该模式下的事务提交与回滚是由本地事务方控制,对于数据一致性上有较高的保障。
该模式缺陷在于代理的连接需要随事务发起方一共释放连接,增加了连接占用的时间。
假设服务已经执行到关闭事务组的过程,那么接下来作为一个模块执行通知给TxManager,
然后告诉他本次事务已经完成。那么如图中Txmanager 下一个动作就是通过事务组的id,
获取到本次事务组的事务信息;然后查看一下对应有那几个模块参与,
如果是有A/B/C 三个模块;那么对应的对三个模块做通知、提交、回滚。
那么提交的时候是提交给谁呢?
是提交给了我们的TxClient 模块。然后TxCliient 模块下有一个连接池,就是框架自定义的一个连接池(如图DB 连接池);这个连接池其实就是在没有通知事务之前一直占有着这次事务的连接资源,就是没有释放。
但是他在切面里面执行了close 方法。在执行close的时候。
如果需要(TxManager)分布式事务框架的连接。他被叫做“假关闭”,也就是没有关闭,
只是在执行了一次关闭方法。实际的资源是没有释放的。这个资源是掌握在LCN 的连接池里的。
当TxManager 通知提交或事务回滚的时候呢?
TxManager 会通知我们的TxClient 端。然后TxClient 会去执行相应的提交或回滚。
提交或回滚之后再去关闭连接。这就是LCN 的事务协调机制。
说白了就是代理DataSource 的机制;相当于是拦截了一下连接池,控制了连接池的事务提交。
RabbitMq**. 如何保证消息的可靠性?**
分三点:
- 生产者到RabbitMQ:事务机制和Confirm机制,注意:事务机制和 Confirm 机制是互斥的,两者不能共存,会导致 RabbitMQ 报错。
- RabbitMQ自身:持久化、集群、普通模式、镜像模式。
- RabbitMQ到消费者:basicAck机制、死信队列、消息补偿机制。
四、LCN 的事务补偿机制
什么是补偿事务机制?
LCN 的补偿事务原理是模拟上次失败事务的请求,然后传递给TxClient 模块然后再次执行该次请求事务。
简单的说:lcn 事务补偿是指在服务挂机和网络抖动情况下txManager
无法通知事务单元时。(通知不到也就两种原因服务挂了和网络出问题)在这种情况下TxManager 会做一个标示;然后返回给发起方。
告诉他本次事务有存在没有通知到的情况。那么如果是接收到这个信息之后,发起方就会做一个标示,
标示本次事务是需要补偿事务的。这就是事务补偿机制。
为什么需要事务补偿?
事务补偿是指在执行某个业务方法时,本应该执行成功的操作却因为服务器挂机或者网络抖动等问题
导致事务没有正常提交,此种场景就需要通过补偿来完成事务,从而达到事务的一致性。
补偿机制的触发条件?
当执行关闭事务组步骤时,若发起方接受到失败的状态后将会把该次事务识别为待补偿事务,
然后发起方将该次事务数据异步通知给TxManager。TxManager 接受到补偿事务以后
先通知补偿回调地址,然后再根据是否开启自动补偿事务状态来补偿或保存该次切面事务数据。
通过这个注解作为发起方
MongoDB与MySQL
索引
默认情况下,Mongo在一个集合(collection)创建时,自动地对集合的_id创建了唯一索引。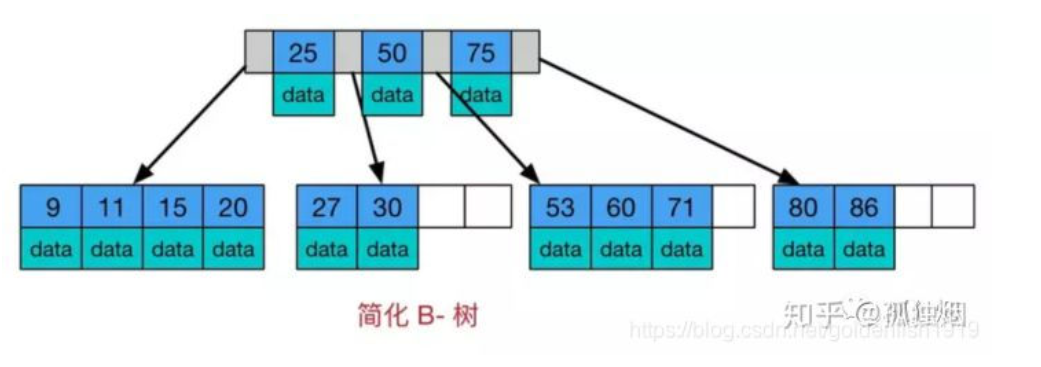
注意一下B树的两个明显特点
树内的每个节点都存储数据
叶子节点之间无指针相邻
(1)B树的树内存储数据,因此查询单条数据的时候,B树的查询效率不固定,最好的情况是O(1)。我们可以认为在做单一数据查询的时候,使用B树平均性能更好。但是,由于B树中各节点之间没有指针相邻,因此B树不适合做一些数据遍历操作。
(2)B+树的数据只出现在叶子节点上,因此在查询单条数据的时候,查询速度非常稳定。因此,在做单一数据的查询上,其平均性能并不如B树。但是,B+树的叶子节点上有指针进行相连,因此在做数据遍历的时候,只需要对叶子节点进行遍历即可,这个特性使得B+树非常适合做范围查询。
因此,我们可以做一个推论:没准是Mysql中数据遍历操作比较多,所以用B+树作为索引结构。而Mongodb是做单一查询比较多,数据遍历操作比较少,所以用B树作为索引结构。
四.索引属性
1.唯一索引(Unique Indexes)
索引的唯一属性导致MongoDB拒绝索引域值重复的文档。除了唯一约束,为索引功能上与其他索引可以交换。
2.部分索引(Partial Indexes)
部分索引最早在MongoDB 3.2版本引入。部分索引仅对集合中符合特定过滤表达式的文档进行索引。通过对集合中文档子集进行索引,部分索引降低了存储需求和索引创建和维护的成本。
部分索引提供稀疏索引(sparse indexes)功能的超集且比稀疏索引更受欢迎。
3.稀疏索引(Sparse Indexes)
索引的稀疏属性确保索引只包含有索引域的文档的索引项。索引跳过并不包含索引域的文档。
您可以将稀疏索引与唯一索引组合以阻止插入索引域有重复值的文档,并跳过没有索引域的文档。
4.TTL索引(TTL Indexes)
TTL索引是MongoDB能用来自动从集合删除超过某一时间的文档的特殊索引。这对类似机器产生的、只需在库中存在有限时间的事件数据、日志和会话信息等某种类型的信息是最理想的。
5.隐藏索引(Hidden Indexes)
隐藏索引最早出现于MongoDB4.4版本。隐藏索引对查询计划器是不可见的,不能用于支持查询。
通过对查询计划器隐藏一个索引,用户能评估删除一个索引带来的潜在影响而并没实际删除索引。如果删除索引有负面影响,用户还能让索引再变的可见而非必须重建删除的索引。因为索引隐藏期间会被完全维护,一旦变得可见将会立即可用。
除了_id索引,可以隐藏任何索引。
6.索引使用(Index Use)
索引能提高读操作的效率。Analyze Query Performance教程将提供有和没有索引时查询执行统计的例子。
7.索引和排序规则(Collation)
该特性最早出现于MongoDB 3.4版本。排序规则允许用户指定特定语言的字符比较规则,像字母大小写和重音符号的规则。
为了用索引进行字符比较,操作也必须确定同样的排序规则。即,一种排序规则的索引不能支持指定了不同排序规则的、在该索引域上进行的字符比较操作。
与mongodb对比
没有事务,偶尔有两个没有也无所谓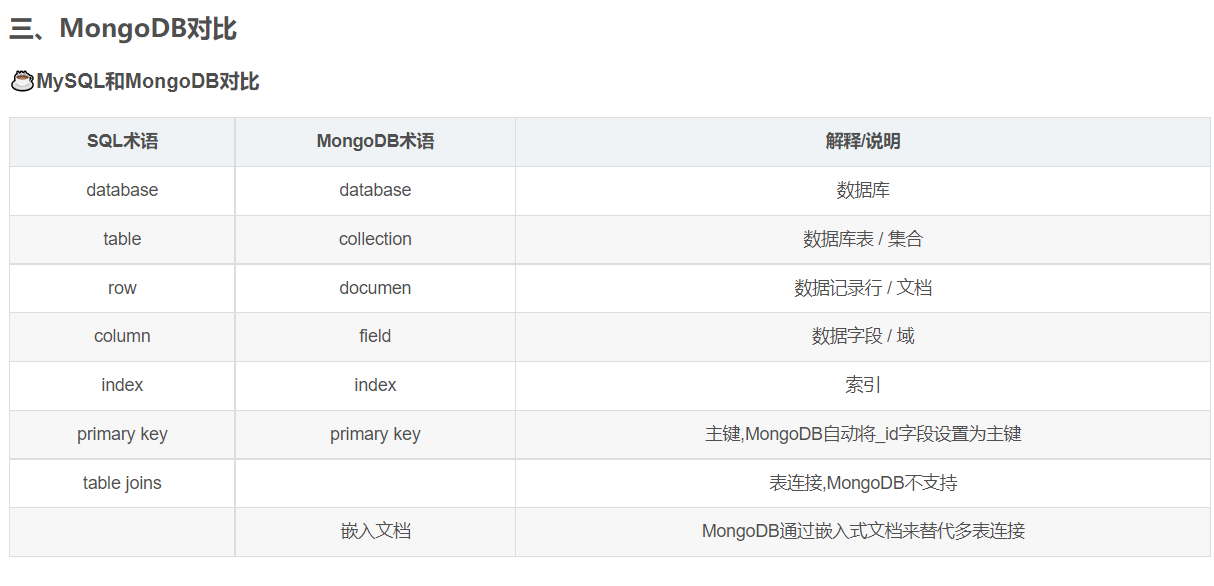
1.什么是MongoDB
MongoDB:是一个数据库 ,高性能、无模式、文档性,目前nosql中最热门的数据库
,开源产品,基于c++开发。是nosql数据库中功能最丰富,最像关系数据库的。
2.MongoDB特性:
面向集合文档的存储:适合存储Bson(json的扩展)形式的数据相当于比json多了些语法,可以类似于json;比如数值:shell默认使用64为浮点型数值。{“x”:3.14}或{“x”:3}。对于整型值,可以使用 NumberInt(4字节符号整数)或NumberLong(8字节符号整数{“x”:NumberInt(“3”)}{“x”:NumberLong(“3”)} 格式自由,数据格式不固定,生产环境下修改结构都可以不影响程序运行;
强大的查询语句,面向对象的查询语言,基本覆盖sql语言所有能力;
完整的索引支持,支持查询计划;
支持复制和自动故障转移;
支持二进制数据及大型对象(文件)的高效存储;
使用分片集群提升系统扩展性;
使用内存映射存储引擎,把磁盘的IO操作转换成为内存的操作;
向用户的,用户使用 MongoDB 开发应用程序使用的就是逻辑结构。
(1)MongoDB 的文档(document),相当于关系数据库中的一行记录。
2)多个文档组成一个集合(collection),相当于关系数据库的表。
(3)多个集合(collection),逻辑上组织在一起,就是数据库(database)。
4)一个 MongoDB 实例支持多个数据库(database)。
相当主键,名字设成下划线 _id
Use 数据库名字,直接创建并使用
数据结构很松散
文档(document)、集合(collection)、数据库(database)的层次结构如下图:
db.spit.insert({_id:”1”,content:”我还是没有想明白到底为啥出
错”,userid:”1012”,nickname:”小明”,visits:NumberInt(2020)});
db.spit.insert({_id:”2”,content:”加班到半夜”,userid:”1013”,nickname:”凯
撒”,visits:NumberInt(1023)});
db.spit.insert({_id:”3”,content:”手机流量超了咋
办?”,userid:”1013”,nickname:”凯撒”,visits:NumberInt(111)});
db.spit.insert({_id:”4”,content:”坚持就是胜利”,userid:”1014”,nickname:”诺
诺”,visits:NumberInt(1223)});
指定表名称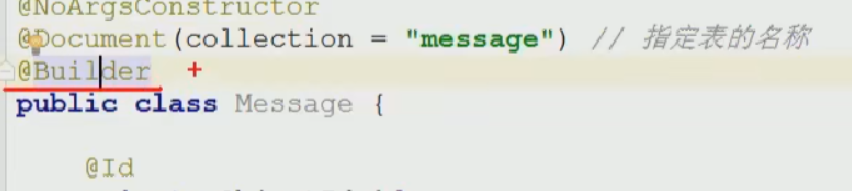
注意:
id主键 + 内容 + uerid:序号 +name:用户名 形成集合
注意要转成同一个类型 {“x”:NumberInt(“3”)}{“x”:NumberLong(“3”)}
Java封装的查询条件,大于就是 “$gt” : 1000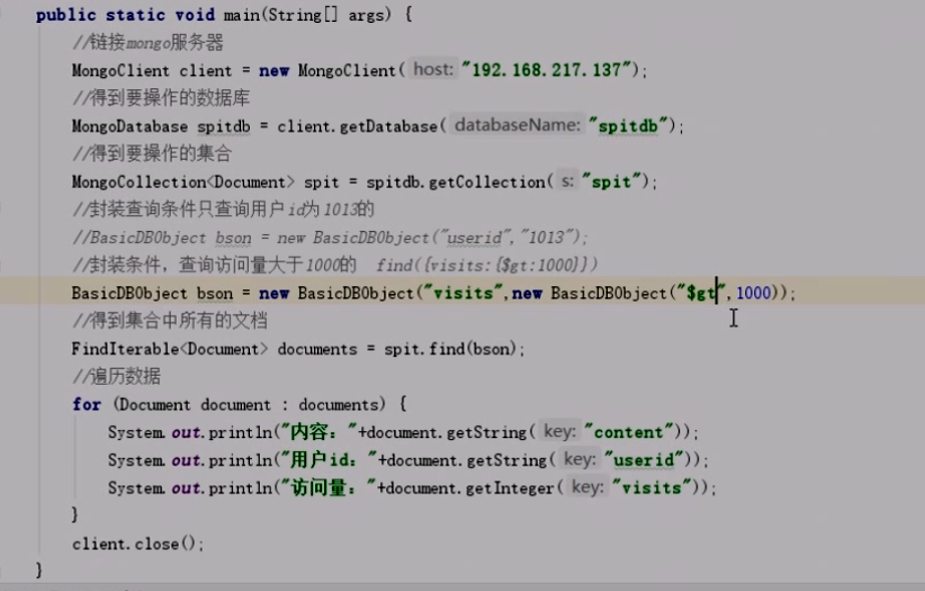
MongoDB 是一个跨平台的,面向文档的数据库,是当前 NoSQL 数据库产品中最热门的一种。
3.MongoDB的不足:
MongoDB对事物的支持较弱: 高度事务性系统,例如银行、财务等系统不适合。
涉及到复杂 的、高度优化的查询方式:传统的商业智能应用,特定问题的数据分析,多数据实体关联等不适合;
数据结构相对固定,使用关系型数据库更好合理,使用sql进行查询统计更加便利的 时候等不适合;
3.1 希望速度快的时候,选择mongodb或者redis
3.2 数据量过大的时候,选择频繁使用的数据存入redis,其他的存入mongodb
3.3 mongodb不需要提前建数据库建表,使用比较方便,字段数量不确定的时候使用mongodb
json格式的直接写入方便。(如日志之类) json的存储格式。mongodb的json与bson格式很适合文档格式的存储与查询。
文档是mongoDB中数据的基本单元,类似关系数据库的行,多个键值对有序地放置在一起便是文档,语法有点类似javascript面向对象的查询语言,它是一个面向集合的,模式自由的文档型数据库
数据处理:
数据是存储在硬盘上的,只不过需要经常读取的数据会被加载到内存中,将数据存储在物理内存中,从而达到高速读写。
缺点:
不支持事务,而且开发文档不是很完全,完善
MongoDB持久化
mongodb与mysql不同,mysql的每一次更新操作都会直接写入硬盘**,但是mongo不会,做为内存型数据库,数据操作会先写入内存,然后再会持久化到硬盘中去,那么mongo是如何持久化的呢**
mongodb在启动时,**专门初始化一个线程不断循环(除非应用crash掉),用于在一定时间周期内来从defer队列中获取要持久化的数据并写入到磁盘的journal(日志)和mongofile(数据)处,当然因为它不是在用户添加记录时就写到磁盘上,所以按mongodb开发者说,它不会造成性能上的损耗,因为看过代码发现,当进行CUD操作时,记录(Record类型)都被放入到defer队列中以供延时批量(groupcommit)提交写入,**但相信其中时间周期参数是个要认真考量的参数,系统为90毫秒,如果该值更低的话,可能会造成频繁磁盘操作,过高又会造成系统宕机时数据丢失过。
Journaling日志机制
运行MongoDB如果开启了journaling日志功能,MongoDB先在内存保存写操作,并记录journaling日志到磁盘,然后才会把数据改变刷入到磁盘上的数据文件。为了保证journal日志文件的一致性,写日志是一个原子操作。本文将讨论MongoDB中journaling日志的实现机制。
Journal日志文件
如果开启了journal日志功能,MongoDB会在数据目录下创建一个journal文件夹,用来存放预写重放日志。同时这个目录也会有一个last-sequence-number文件。如果MongoDB安全关闭的话,会自动删除此目录下的所有文件,如果是崩溃导致的关闭,不会删除日志文件。在MongoDB进程重启的过程中,journal日志文件用于自动修复数据到一个一致性的状态。
journal日志文件是一种往文件尾不停追加内容的文件,它命名以j._开头,后面接一个数字(从0开始)作为序列号。如果文件超过1G大小,MongoDB会新建一个journal文件j._1。只要MongoDB把特定日志中的所有写操作刷入到磁盘数据文件,将会删除此日志文件。因为数据已经持久化,不再需要用它来重放恢复数据了。journal日志文件一般情况下只会生成两三个,除非你每秒有大量的写操作发生。
如果你需要的话,你可以使用storage.smallFiles参数来配置journal日志文件的大小。比如配置为128M。
Journaling存储以下原始操作:
文档插入或更新
索引修改
命名空间文件元数据的修改
创建和者删除数据库或关联的数据文件
当发生写操作,MongoDB首先写入数据到内存中的private视图,然后批量复制写操作到journal日志文件。写个journal日志实体来用描述写操作改变数据文件的哪些字节。
2、journal刷新频率
journal除了故障恢复的作用之外,还可以提高写入的性能,批量提交(batch-commit),journal一般默认100ms刷新一次,在这个过程中,所有的写入都可以一次提交,是单事务的,全部成功或者全部失败。
关于刷新时间,它是可以更改,范围是2-300ms,但是这并不是绝对的。mongodb提供了journal延迟测试的函数,
启用journaling功能后,如果mongod意外停止,则程序可以恢复journal 里的所有内容。 MongoDB将在重新启动时重新应用写入操作,并保持一致状态。默认情况下,最严重的丢失写操作(即未写入journal的操作)是最近100毫秒内进行的写操作,加上执行写入journal操作所花费的时间
1.系统日志
系统日志在Mongdb数据中很中重要**,它记录mongodb启动和停止的操作,以及服务器在运行过程中发生的任何异常信息;配置系统日志也非常简单,在运行mongod时候增加一个参数logpath,就可以设置;
2. Journal日志
Jouranl日志通过预写入的redo日志为mongodb增加了额外的可靠性保障。开启该功能时候,数据的更新就先写入Journal日志,定期集中提交(目前是每100ms提交一次) ,然后在正式数据执行更改。启动数据库的Journal功能非常简单,只需在mongod后面指定journal参数即可
3. Oplog主从日志
Mongodb的高可用复制策略有一个叫做Replica Sets.ReplicaSet复制过程中有一个服务器充当主服务器,而一个或多个充当从服务器,**主服务将更新写入一个本地的collection中,这个collection记录着发生在主服务器的更新操作。并将这些操作分发到从服务器上。这个日志是Capped Collection。利用如下命令可以配置
4. 慢查询日志
慢查询记录了执行时间超过了所设定时间阀值的操作语句。慢查询日志对于发现性能有问题的语句很有帮助,建议开启此功能并经常分析该日志的内容。
要配置这个功能只需要在mongod启动时候设置profile参数即可。例如想要将超过5s的操作都记录,可以使用如下语句:
mongod —profile=1 —slowms=5
MongoDB高性能原因,存储海量数据原因?
优点:
1)社区活跃,用户较多,应用广泛。
2)MongoDB在内存充足的情况下数据都放入内存且有完整的索引支持,查询效率较高。
3)MongoDB的分片机制,支持海量数据的存储和扩展。
分片 是将数据分布在多台机器的方法。MongoDB 使用分片来提供海量数据的部署和高吞吐操作 .
MongoDB 优点:
1.性能优越:快速!在适量级的内存的 MongoDB 的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快,热数据:**如果出现这个情况可以只将访问比较频繁的集合加载到内存中**
2文档结构的存储方式,能够更便捷的获取数据: json 的存储格式 1.占带宽小(格式是压缩的)
缺点:1)不支持事务
2)不支持join、复杂查询
不适用的场景1)MongoDB不支持事务操作,需要用到事务的应用建议不用MongoDB。
2)MongoDB目前不支持join操作,需要复杂查询的应用也不建议使用MongoDB。
2、关系型数据库和非关系型数据库的应用场景对比
关系型数据库适合存储结构化数据,如用户的帐号、地址:
1)这些数据通常需要做结构化查询,比如join,这时候,关系型数据库就要胜出一筹
2)这些数据的规模、增长的速度通常是可以预期的
3)事务性、一致性
NoSQL适合存储非结构化数据,如文章、评论:1)这些数据通常用于模糊处理,如全文搜索、机器学习2)这些数据是海量的,而且增长的速度是难以预期的,3)根据数据的特点,NoSQL数据库通常具有无限(至少接近)伸缩性4)按key获取数据效率很高,但是对join或其他结构化查询的支持就比较差
非关系型数据库
1 关系数据库:
是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。简单说来就是关系型数据库用了选择、投影、连接、并、交、差、除、增删查改等数学方法来实现对数据的存储和查询。可以用SQL语句方便的在一个表及其多个表之间做非常复杂的数据查询。安全性高。
其中server层包括连接池、查询缓存、分析器、优化器等部分,
重点:表与表之间有关系,1对多(靠主外键),多对多(靠中间表)
2.非关系型数据库:
简称NOSQL,是基于键值对的对应关系,并且不需要经过SQL层的解析,所以性能非常高。但是不适合用在多表联合查询和一些较复杂的查询中。NoSQL用于超大规模数据的存储。
重点:表与表之间无关系,比如Redis,key,value
RabbitMq架构
答:在项目中,针对评论、点赞、关注我们可以定义三类不同的主题,一旦当事情发生时我们就能将这个消息发送到队列里,然后就不用再去关注后面的操作,后续由专门的消费者去获取消息队列里面的消息,这个过程实际上是异步的,是一个并发的过程,保证了系统的性能。
阿里云短信过程
4.3.2 准备工作
(1)在阿里云官网 www.alidayu.com 注册账号
2)手机下载”阿里云“APP,完成实名认证
3)登陆阿里云,产品中选择”短信服务“
4)申请签名
(5)申请模板
(6)创建 accessKey (注意保密!)
7)充值 (没必要充太多,1至2元足矣,土豪请随意~)
RocketMq如何做测试,丢失,重试
可视化工具整体功能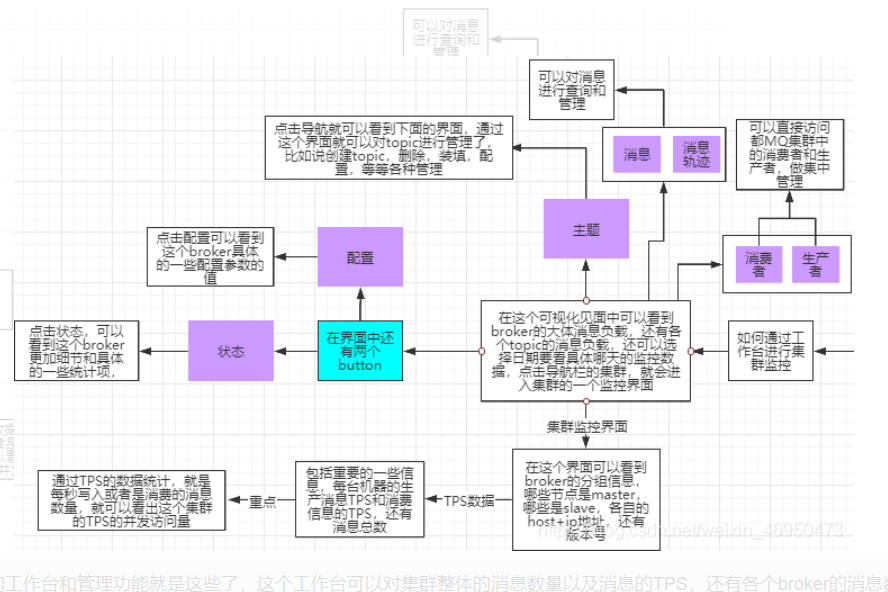
4 短信微服务
4.1 需求分析
开发短信发送微服务,从rabbitMQ中提取消息,调用阿里大于短信接口实现短信发送 。(关于短信阿里大于,我们在前面的电商项目中已经讲解过,故账号申请等环节略过)
我们这里实际做的就是消息的消费者.
4.2 提取队列中的消息
4.2.2 消息监听类
(1)创建短信监听类,获取手机号和验证码
3)创建短信工具类SmsUtil (资源已提供,直接拷贝即可)
直接去官网下载代码
// TODO 此处需要替换成开发者自己的AK(在阿里云访问控制台寻找)
String accessKeyId =env.getProperty(“aliyun.sms.accessKeyId”); String accessKeySecret=env.getProperty(“aliyun.sms.accessKeySecret”);
RabbitMq存的是手机号和验证码
RabbitMq的可靠性适合存这种验证码,吞吐量不高,因为几乎很少同一时间去接收短信,而且收到后,输入的时间可能也不用,但是一定要保证信息准确
RabbitMq用的直接模式,sms,交换器上邦的也是sms,就够了,别的模式用不上
遇到的问题,如何保证100%消息不丢失,RabbitMq
项目中使用RabbitMQ来作为消息队列,遇见过消息丢失的情况,特此记录一下。
写在前面
先来说下MQTT协议中的3种语义,这个非常重要。
在MQTT协议中,给出了三种传递消息时能够提供的服务质量标准,这三种服务质量从低到高依次是:
At most once:至多一次。消息在传递时,最多会被送达一次。也就是说,没什么消息可靠性保证,允许丢消息。
At least once:至少一次。消息在传递时,至少会被送达一次。也就是说,不允许丢消息,但是允许有少量重复消息出现。
Exactly once:恰好一次。消息在传递时,只会被送达一次,不允许丢失也不允许重复,这个是最高的等级 这个服务质量标准不仅适用于MQTT,对所有的消息队列都是适用的。现在常用的绝大部分消息队列提供的服务质量都是 At least once,包括RocketMQ、RabbitMQ和Kafka都是这样。也就是说,消息队列很难保证消息不重复。
At least once+幂等消费=Exactly once
幂等性下回再讲,这篇先说下消息丢失的问题。
如何保证消息100%不丢失
消息从生产端到消费端消费要经过3个步骤:
生产端发送消息到RabbitMQ;
RabbitMQ发送消息到消费端;
消费端消费这条消息;
也就是说只要保证生产端和消费段的消息可靠性,理论上就能够保证消息100%不丢失。
(当然,这里的可靠并不是一定就100%不丢失了,磁盘损坏,机房爆炸等等都能导致数据丢失,当然这种都是极小概率发生,能做到99.999999%消息不丢失,就是可靠的了)
生产端可靠性投递
事务消息机制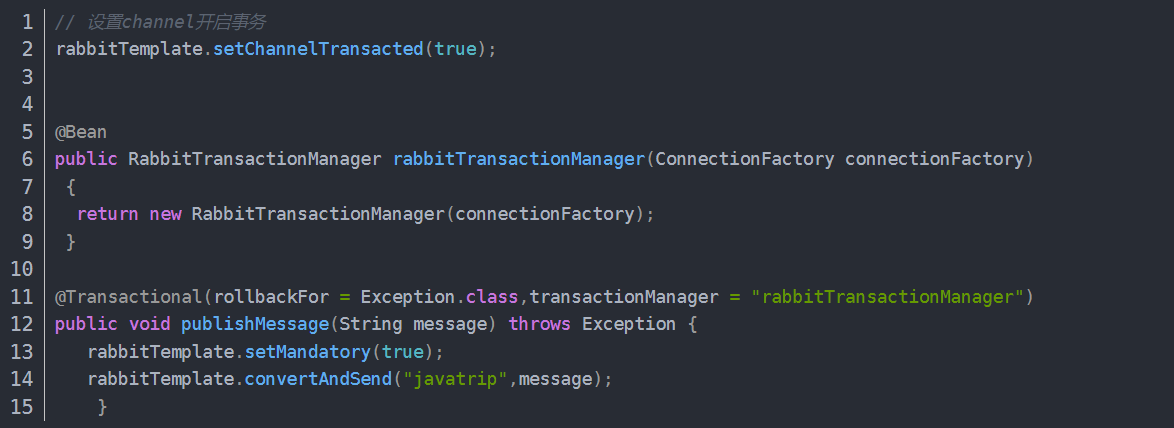
事务消息机制由于会严重降低性能,所以一般不采用这种方法,因为这是同步操作,一条消息发送之后会使发送端阻塞,以等待RabbitMQ-Server的回应,之后才能继续发送下一条消息,生产者生产消息的吞吐量和性能都会大大降低。
confirm消息确认机制
顾名思义,就是生产端投递的消息一旦投递到RabbitMQ后,RabbitMQ就会发送一个确认消息给生产端,让生产端知道我已经收到消息了,否则这条消息就可能已经丢失了,需要生产端重新发送消息了。
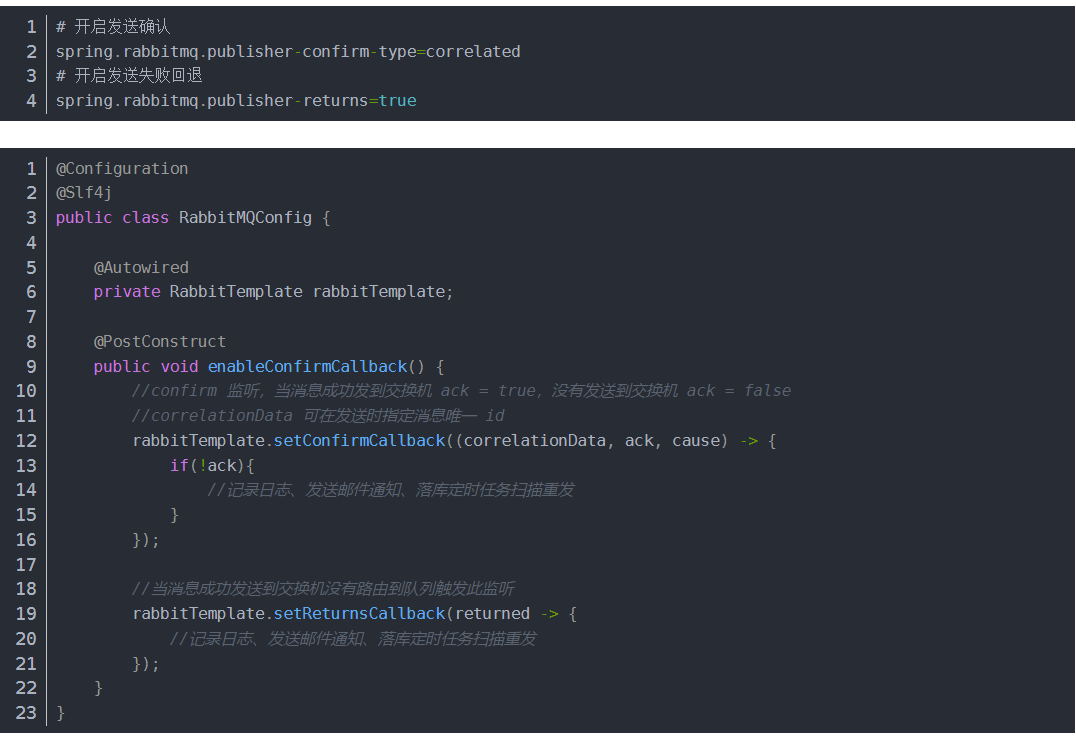
消费端可靠性投递
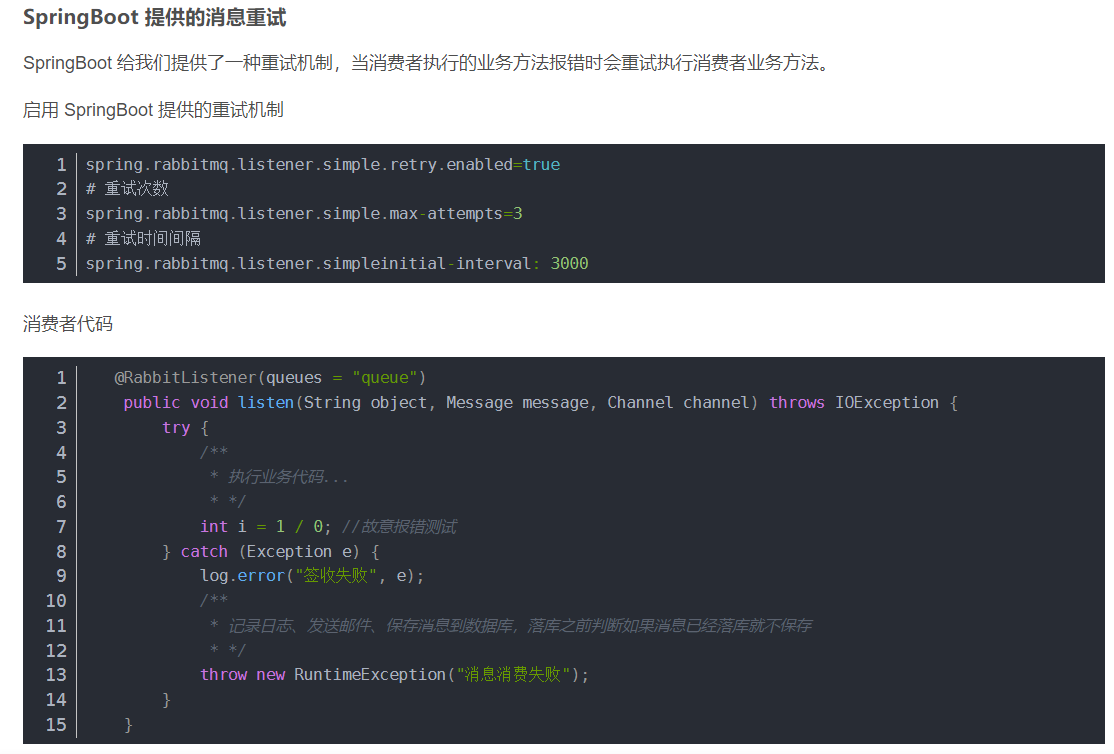
ACK机制改为手动
RabbitMQ的自动ack机制默认在消息发出后就立即将这条消息删除,而不管消费端是否接收到,是否处理完。
我们需要进行手动消费
#开启手动ACK,消费消息的时候,就必须发送ack确认,不然消息永远还在队列中
spring.rabbitmq.listener.simple.acknowledge-mode=manual
这里要小心! basicNack 方法的第三个参数代表是否重回队列,通常代码的报错并不会因为重试就能解决,所以可能这种情况:继续被消费,继续报错,重回队列,继续被消费…死循环。
一定要有重发消息次数的限制,或者干脆不入队,发送到Redis进行下记录也行。
二、单点登录背景
一个大的应用系统内部,有很多的子系统,每个子系统都有相应的一套登录认证机制,对用户来说,访问每一个系统都登录一次太麻烦。于是使用一个统一的单点登录认证中心,通过这个认证中心,达到一次登录即可访问所有系统的功能,避免重复登录。
三、单点登录原理
通过统一的认证中心,给应用系统提供一个公共的访问令牌token,各子系统通过这个令牌去获取登录账号与本地账号比较是否一致。
四、单点登录实现
在统一的登录入口,输入用户密码登录,会向服务端发送请求
请求里包含登录相关的cookie,来标识登录请求和存放登录信息
通过拦截器,拦截请求,根据cookie的基本信息,获取到对应的登录凭证token
通过token,获取到登录账号信息
退出过程类似,发送一个退出请求,销毁掉相应的cookie,和本地存储的账号信息
SpringCloud微服务
熔断器
1.1 为什么要使用熔断器
在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致级联故障, 进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。服务雪崩效应是一种 因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程。
(1)修改tensquare_qa模块的application.yml ,开启hystrix
feign:
hystrix:
enabled: true
2 微服务网关Zuul
2.1 为什么需要微服务网关
不同的微服务一般有不同的网络地址,而外部的客户端可能需要调用多个服务的接口才 能完成一个业务需求。比如一个电影购票的收集APP,可能回调用电影分类微服务,用户 微服务,支付微服务等。如果客户端直接和微服务进行通信,会存在一下问题:
# 客户端会多次请求不同微服务,增加客户端的复杂性
# 存在跨域请求,在一定场景下处理相对复杂
# 认证复杂,每一个服务都需要独立认证 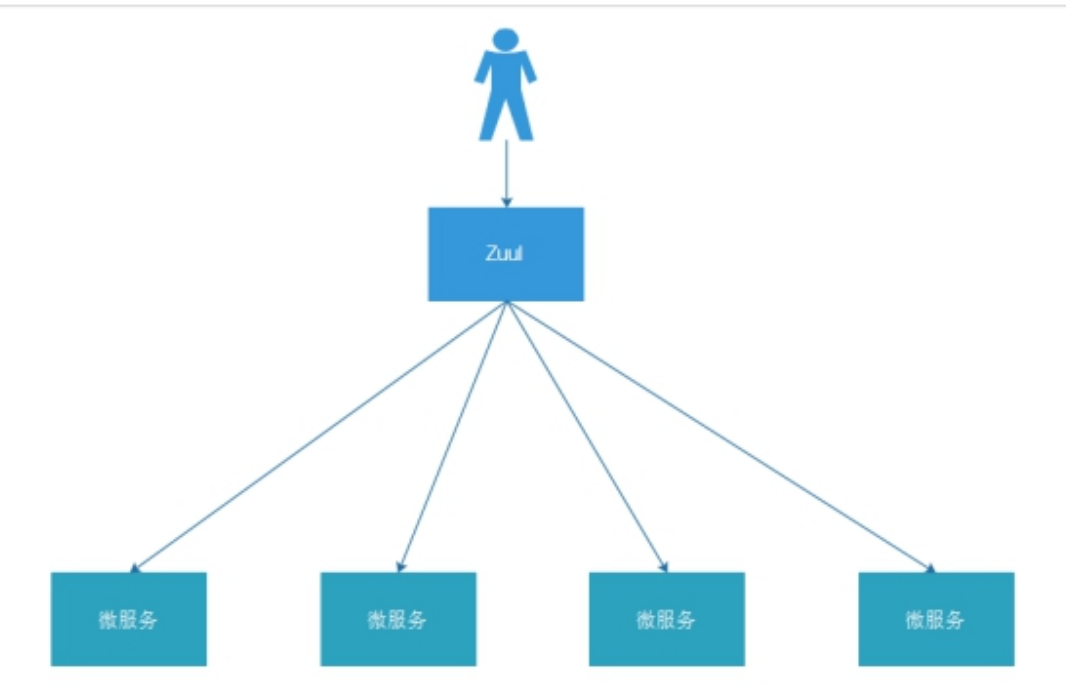
zuul:
routes:
tensquare‐gathering: #活动
path: /gathering/ #配置请求URL的请求规则
serviceId: tensquare‐gathering #指定Eureka注册中心中的服务id
tensquare‐article: #文章
path: /article/ #配置请求URL的请求规则
serviceId: tensquare‐article #指定Eureka注册中心中的服务id
tensquare‐base: #基础
path: /base/** #配置请求URL的请求规则
serviceId: tensquare‐base #指定Eureka注册中心中的服务id 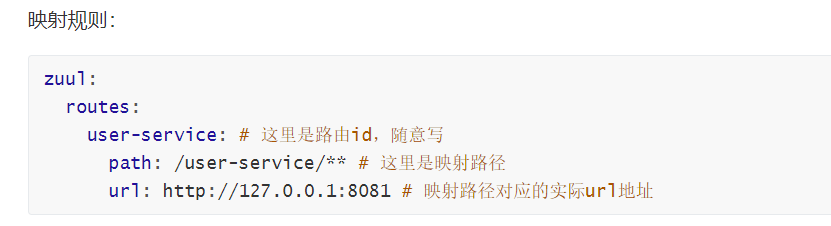
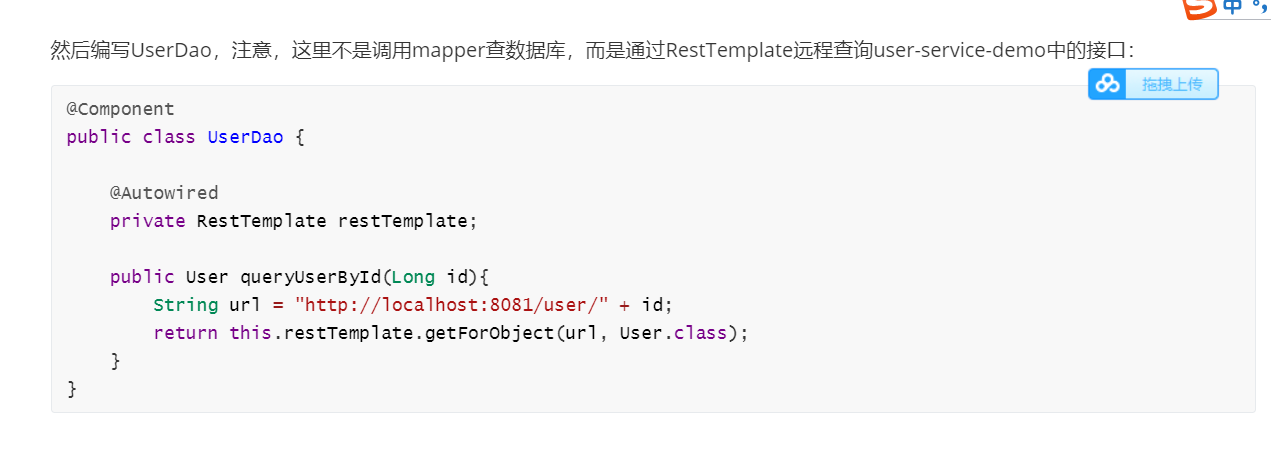
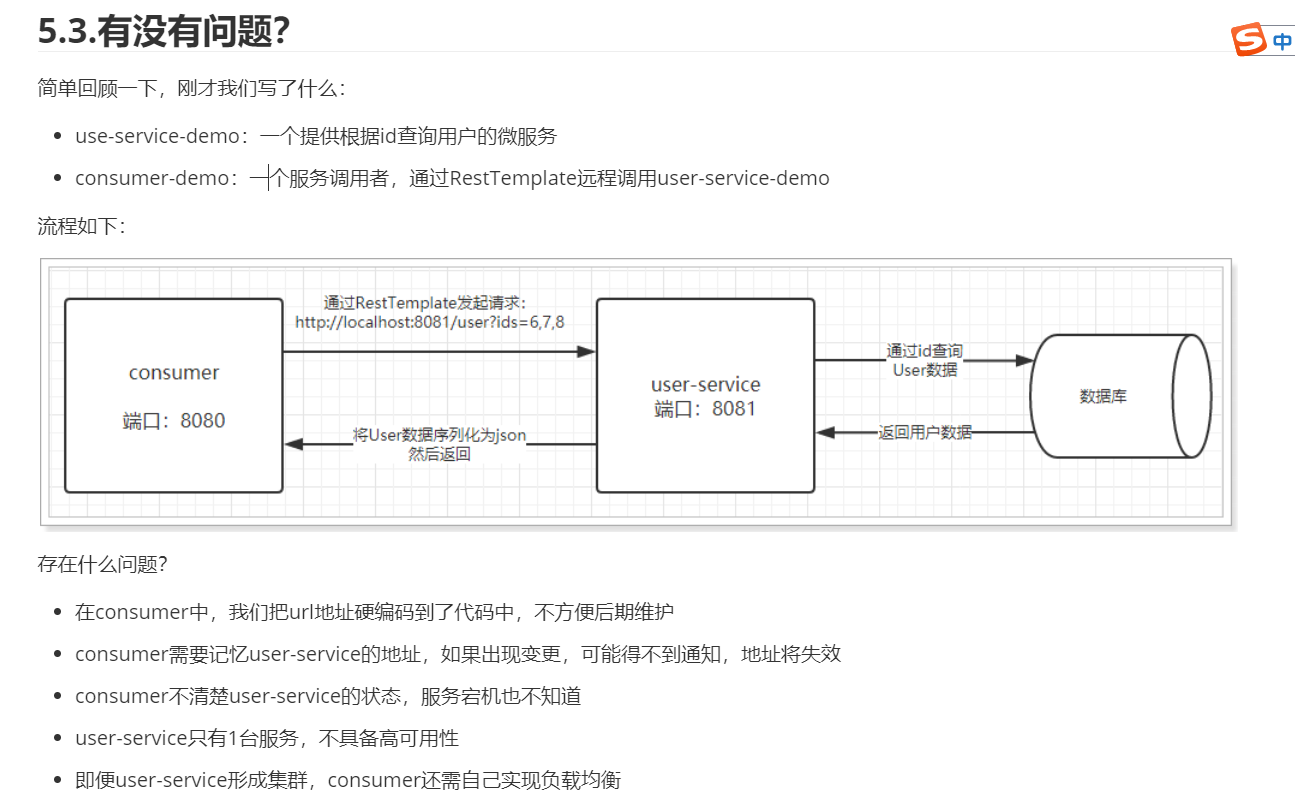
存在什么问题?
- 在consumer中,我们把url地址硬编码到了代码中,不方便后期维护
- consumer需要记忆user-service的地址,如果出现变更,可能得不到通知,地址将失效
- consumer不清楚user-service的状态,服务宕机也不知道
- user-service只有1台服务,不具备高可用性
- 即便user-service形成集群,consumer还需自己实现负载均衡
其实上面说的问题,概括一下就是分布式服务必然要面临的问题:
- 服务管理
- 如何自动注册和发现
- 如何实现状态监管
- 如何实现动态路由
- 服务如何实现负载均衡
- 服务如何解决容灾问题
- 服务如何实现统一配置
以上的问题,我们都将在SpringCloud中得到答案。
Zuul作为网关的其中一个重要功能,就是实现请求的鉴权。而这个动作我们往往是通过Zuul提供的过滤器来实现的。
3.8.1.ZuulFilter
ZuulFilter是过滤器的顶级父类。在这里我们看一下其中定义的4个最重要的方法: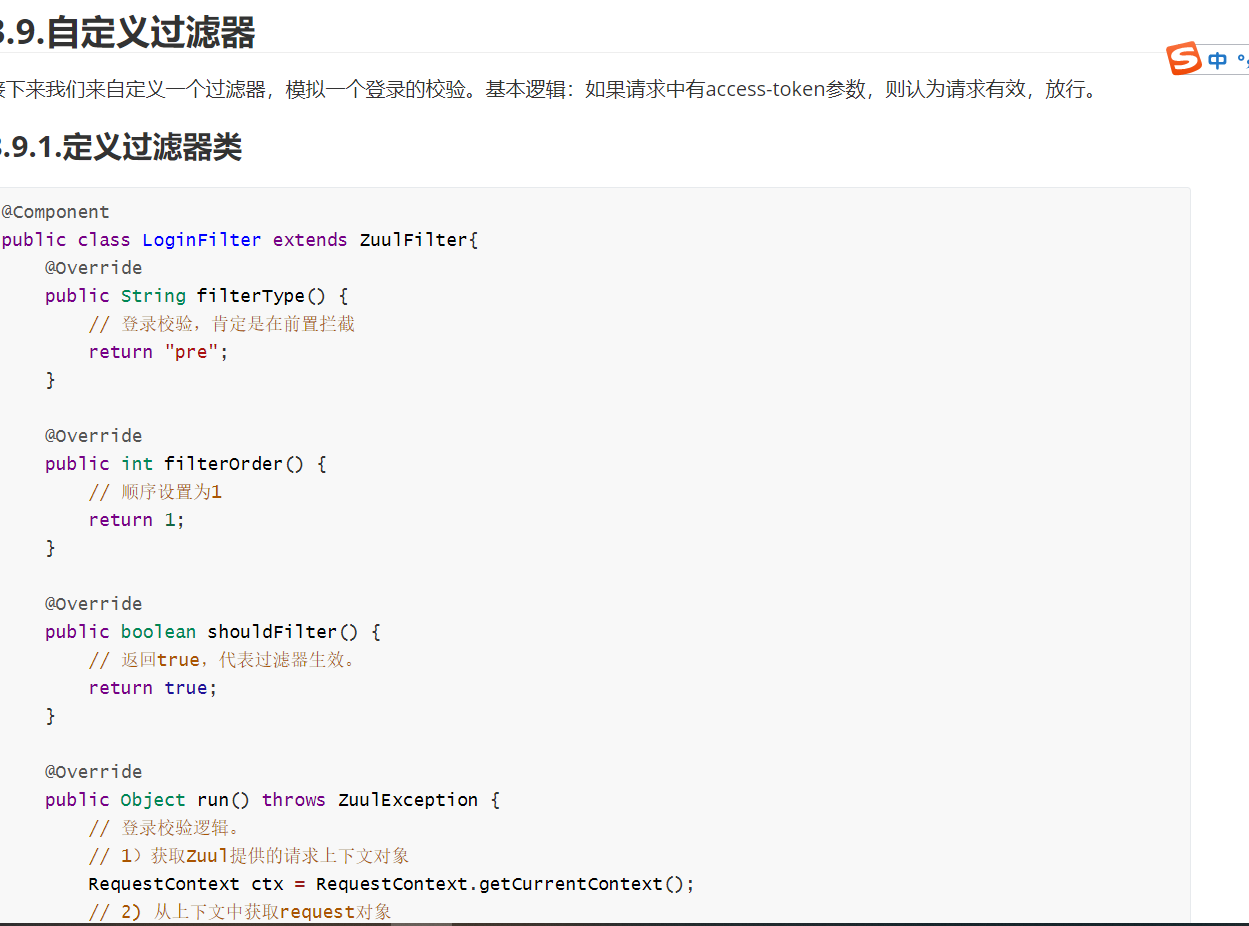

若有收获,就点个赞吧
0 人点赞
