- 周瑜spring笔记
- 前端如何调用后端的接口?
- 注解知识
- 7、SpringBoot运行项目的几种方式?
- Springboot运行流程
- SpringBoot的启动
- 四、小结:自动装配的流程(原理)
- 什么是Tomcat?
- SpringMVC流程
- Spring生命周期的概要流程
- Spring依赖注入(控制反转)
- Spring事务
- 全局异常类处理
- Springboot全局异常类注解详解
- Springboot循环依赖问题
- 什么情况下循环依赖可以被处理?
- 注意:单例bean与单例模式不是一个概念,只是相同的名字可以拿到同一个对象,原理单例注册表实现,
- Spring生命周期
- @Component 和 @Bean 的区别是什么?
- springIOC
- 面向切面编程(AOP)">Spring面向切面编程(AOP)
周瑜spring笔记
笔记在线更新版:https://www.yuque.com/books/share/5f19528d-d89b-4b69-a7bd-9f436a2dd734
前端如何调用后端的接口?
接口一般指的是HTTP接口,也可以说是HTTP API。接口由后端提供,前端调用后端接口以获取后端数据、在Index页面,添加Jquery的ajax方式,调用后台接口,返回结果的处理代码。,而且接口由URL和HTTP方法构成,URL为接口的地址,HTTP方法指的是GET, PUT, DELETE等等。
HTTP请求过程详解博客 (76条消息) 一次完整的http请求全过程(知识体系版)星海拾遗的博客-CSDN博客请求过程
1、使用AJAX调用后端接口
其中url参数处要填写出被调用服务的ip:port/接口名,调用成功后接口返回值即为success函数中的data
4.解决方案
1.Js创建了一个ajax请求
2.浏览器另外开启一个ajax引擎线程,执行ajax请求
3.执行得到响应后将回调函数放入任务队列中。
4.Js执行任务队列中的回调函数。
注解知识
假如你想为应用设置很多的常量或参数,这种情况下,XML是一个很好的选择,因为它不会同特定的代码相连。如果你想把某个方法声明为服务,那么使用Annotation会更好一些,因为这种情况下需要注解和方法紧密耦合起来,
:**Annotations仅仅是元数据,和业务逻辑无关**
- .注解类可以没有成员,没有成员的注解称为标识注解,例如JDK注解中的@Override、@Deprecation
元注解:
何为元注解?就是注解的注解,就是给你自己定义的注解添加注解,你自己定义了一个注解,但你想要你的注解有什么样的功能,此时就需要用元注解对你的注解进行说明了
元注解
@Target说明了Annotation所修饰的对象范围:即注解的作用域,用于说明注解的使用范围(即注解可以用在什么地方,比如类的注解,方法注解,成员变量注解等等)
注意:如果Target元注解没有出现,那么定义的注解可以应用于程序的任何元素。
- CONSTRUCTOR:用于描述构造器2.FIELD:用于描述域3.LOCAL_VARIABLE:用于描述局部变量4.METHOD:用于描述方法5.PACKAGE:用于描述包
2.2 @Retention
@Retention定义了该Annotation被保留的时间长短:
@Retention的取值是在RetentionPoicy这个枚举中规定的
1.SOURCE:在源文件中有效(即源文件保留)
2.CLASS:在class文件中有效(即class保留)在类加载的时候丢弃。在字节码文件的处理中有用。注解默认使用这种方式。3.RUNTIME:在运行时有效(即运行时保留)始终不会丢弃,运行期也保留该注解,因此可以使用反射机制读取该注解的信息。我们自定义的注解通常使用这种方式。
注意:注解的的RetentionPolicy的属性值是RUTIME,这样注解处理器可以通过反射,获取到该注解的属性值,从而去做一些运行时的逻辑处理
@Inherit父类中使用的注解可以被子类继承.
@Documented保存文件的
【通过class 获取类的相关信息,通过class创建对象,通过class调用对象的方法和属性,这种操作称为反射操作】
7、SpringBoot运行项目的几种方式?
打包用命令或者放到容器中运行
1、 打成jar包,使用java -jar xxx.jar运行
2、 打成war包,放到tomcat里面运行
直接用maven插件运行 maven spring-boot:run
Springboot运行流程
总结:@AutoConfigurationPackage 注解就是将主配置类(@SpringBootConfiguration标注的类)的所在包及下面所有子包里面的所有组件扫描到Spring容器中。所以说,默认情况下主配置类包及子包以外的组件,Spring 容器是扫描不到的。
在loadFactoryNames方法中做了关键三步
从当前项目的类路径中获取所有 META-INF/spring.factories 这个文件下的信息
将上面获取到的信息封装成一个 Map 返回。
从返回的 Map 中通过刚才传入的EnableAutoConfiguration.class参数,获取该 key 下的所有值(资源)。
核心运行原理
使用Spring Boot的时候,通过引入对应场景的Starter,被称为场景启动器,再Spring Boot项目启动的时候会自动加载相关的依赖,添加相应的默认配置。通过最简单的方式来完成对于第三方组件的集成操作,这个就是Spring Boot自动配置的核心的思想。如下图所示,图例来源某电子书截图
@EnableAutoConfiguration;该注解由组合注解@SpringBootApplication引入,完成自动配置开启,扫描各个包下的spring.factories文件,并加载文件中注入的自动配置类,当然自定义的场景启动器也是通过这种方式进行加载。
由于@ComponentScan注解只能扫描spring-boot项目包内的bean并注册到spring容器中,因此需要@EnableAutoConfiguration注解来注册项目包外的bean。而spring.factories文件,可用来记录项目包外需要注册的bean类名。
比如RedisTemplate,操作Redis,expire等命令
@Conditional;条件注解,这个是Spring提供的注解,通过这个注解也衍生了很多的其他注解。表示满足定义的条件的时候才会被实例化成Spring 容器中的Bean对象。
AutoConfiguration类;自动配置类,代表了Spring Boot 中的一类配置类,再这些配置类中定义了第三方需要使用的Bean的初始化以及初始化的条件。
Starter;场景启动器,第三方组件的自动配置依赖启动器,默认将满足某一使用场景的第三方配置全部包含到其中,再使用的时候直接引用对应的starter就可以实现对于某个场景的快速实现,的第三方库配置(例如Jackson, JDBC, Mongo, Redis, Mail等等)
Spring Boot项目需要创建一个启动类,这个启动类上面需要标注一个注解@SpringBootApplication,表示启用了SpringBoot自动配置方式。
主要功能就是再SpringBoot项目启动的时候,对于Spring容器中注入对应的配置类。再SpringBoot中自动配置通常是基于项目classpath中引入的类和已经定义好的Bean来实现的
Spring 是一个“引擎”;
Spring MVC 是基于Spring的一个 MVC 框架;
Spring Boot 是基于Spring4的条件注册的一套快速开发整合包。
run 方法的主要步骤点,和回调机制
从类路径下META‐INF/spring.factories 获取 SpringApplicationRunListeners
回调所有的获取SpringApplicationRunListener.starting()方法
准备环境prepareEnvironment()
创建环境完成后回调SpringApplicationRunListener.environmentPrepared();表示环境准备完成
准备上下文环境prepareContext() :
将environment保存到ioc中;
回调之前保存的所有的ApplicationContextInitializer的initialize方法;
回调所有的SpringApplicationRunListener的contextPrepared();
prepareContext运行完成以后回调所有的SpringApplicationRunListener的contextLoaded();
refreshContext(context); 刷新容器,ioc容器初始化。扫描,创建,加载所有组件的地方;(配置类,组件,自动配置)
从ioc容器中获取所有的ApplicationRunner和CommandLineRunner进行回调
所有的SpringApplicationRunListener回调finished方法
SpringBoot的启动
是通过new SpringApplication()实例来启动的,启动过程主要做如下几件事情:
1. 配置属性
2. 获取监听器,发布应用开始启动事件
3. 初始化输入参数
4. 配置环境,输出banner
5. 创建上下文
6. 预处理上下文
7. 刷新上下文
8. 刷新上下文
9. 发布应用已经启动事件
10.发布应用启动完成事件
而启动Tomcat就是在第7步的“刷新上下文”;Tomcat的启动主要是初始化2个核心组件,连接器(Connector)和容器(Container),一个Tomcat实例就是一个Server,一个Server包含多个Service,也就是多个应用程序,每个Service包含多个连接器(Connetor)和一个容器(Container),而容器下又有多个子容器,按照父子关系分别为:Engine、Host、Context、Wrapper,其中除了Engine外,其余的容器都是可以有多个。
tomcat 中的 connector 主要负责用来处理 http 请求
Springboot中的上下文理解
现实化理解: Context翻译成上下文并不直观,按照语言使用的环境,翻译成“环境”、“容器”可能更好。把Context翻译成“上下文”只是不直观罢了,不过也没大错。我们来看看中文的“上下文”是什么意思。我们常说听话传话不能“断章取义”,而要联系它的“上下文”来看。比如,小丽对王老五说“我爱你”,光看这句还以为在说情话呢。但一看上下文--“虽然我爱你,但你太穷了,我们还是分手吧”,味道就完全变了。从这里来看“上下文”也有“环境”的意思,就是语言的环境。
PS:
上下文其实是一个抽象的概念。我们常见的上下文有Servlet中的pageContext,访问JNDI时候用的Context。写过这些代码的人可能比较容易理解,其实他们真正的作用就是承上启下。比如说pageContext他的上层是WEB容器,下层是你写的那个Servlet类,pageContext作为中间的通道让Servlet 和Web容器进行交互。
如果没有这些外部环境,这段程序是运行不起来的。
子程序之于程序,进程之于操作系统,甚至app的一屏之于app,都是一个道理
当程序执行了一部分,要跳转到其他的地方,而跳转到的地方需要之前程序的一些结果(包括但不限于外部变量,外部对象等等)。
app点击一个按钮进入一个新的界面,也要保存你是在那个屏幕跳过来的等等信息,以便你点击返回的时候能正确跳回
通俗一点理解就是,当程序从一个位置调到另一个位置的时候,这个时候就叫上下文的切换
而不是采用一个socket一个线程,就是因为在切换线程(也就是切换上下文)的时候,需要保留大量的现场数据,而在重新切回到该线程时,又要恢复这个保存的数据(即保存的环境),保存/恢复都是需要花费cpu大量的资源和时间的,所以不如one loop per thread + thread poll的模式,当然one loop per thread + thread poll还有其他的好处,这只是其中一个好处,不需要大量的切换上下文,占用cpu大量的资源。
举例:Tomcat和Redis
可以看到,在spring-factories中配置了自动装配类
这个自动装配类会被读取到内存中
这个类本质上就是配置类**,贴了注解@bean,也就是说这里会创建Datasource
四、小结:自动装配的流程(原理)
1、main方法中SpringApplication.run(HelloBoot.class,args)的执行流程中有refreshContext(context)。
2、而这个refreshContext(context)内部会解析,配置类上自动装配功能的注解@EnableAutoConfiguration中的,@EnableAutoConfiguration中的,引入类AutoConfigurationImportSelector。
3、AutoConfigurationImportSelector这个类中的方法SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(), getBeanClassLoader()会读取jar包中的/项目中的META-INF/spring.factories文件。
4、spring.factories配置了自动装配的类,最后根据配置类的条件,自动装配Bean。
小结:
SpringBoot启动会加载大量的自动配置类。
我们看需要的功能有没有SpringBoot默认写好的自动配置类。
我们再来看这个自动配置类中到底配置了那些组件(只要我们要用的组件有,我们就不需要再来配置了)。
给容器中自动配置类添加组件的时候,会从properties类中获取某些属性。我们就可以在配置文件中指定这些属性的值。
不知道小伙伴们有没有发现,很多需要待加载的类都放在类路径下的META-INF/Spring.factories 文件下,而不是直接写死这代码中,这样做就可以很方便我们自己或者是第三方去扩展,我们也可以实现自己 starter,让SpringBoot 去加载。现在明白为什么 SpringBoot 可以实现零配置,开箱即用了吧!
什么是Tomcat?
简单点说 就是用来处理网络传输过来的一些请求 比如http请求 并处理请求 返回数据
通俗点说他是jsp网站的服务器之一,就像asp网站要用到微软的IIS服务器,php网站用apache服务器一样,
因为你的jsp动态网站使用脚本语言等写的,需要有服务器来解释你的语言吧,服务器就是这个功能。如果你的网页是纯html的,浏览器就可以直接解释查看效果,但是你的网页一但是.jsp .asp .php 等的动态网页时浏览器自己就无法解释了,需要上面说到的服务器
。tomcat便可以解释jsp等java编写的网站。
SpringMVC流程
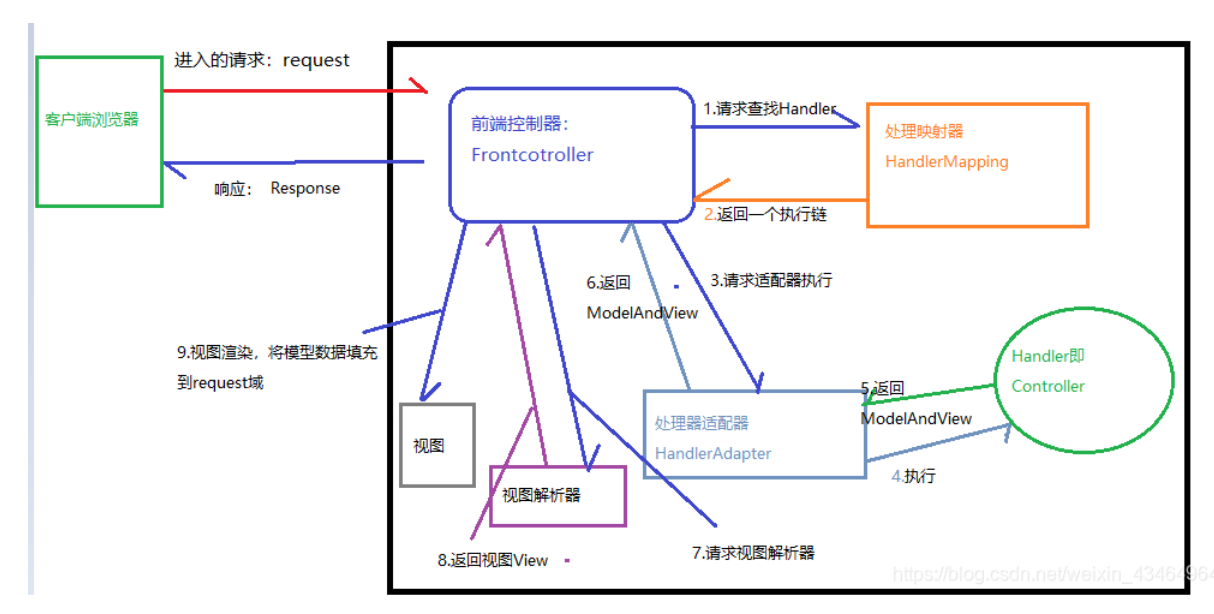
执行流程:
DispatcherServlet: 是整个springmvc框架的核心。
前端控制器/核心控制器:所有的请求和响应都由此控制器进行分配。
前端控制器的所有工作都是基于组件完成的:
三大组件:
HandlerMapping: 它负责根据客户端的请求寻找对应的hadler,找到以后把寻找的handler返回给DispatcherServlet;
HandlerAdapter:它负责执行寻找到的Handler的方法,方法执行完后将返回值给HandlerAdapter, HandlerAdapter将返回值传给DispatcherServlet;
ViewResolver:它根据DispatcherServlet指定的返回结果寻找对应的页面,找到后将结果返回给DispatcherServlet。
DispatcherServlet负责最终的响应,默认是转发的操作。
前端控制器,处理器适配器,视图解析器
Spring生命周期的概要流程
Bean 的生命周期概括起来就是 4 个阶段:
- 实例化(Instantiation)
- 属性赋值(Populate)
- 初始化(Initialization)
- 销毁(Destruction)
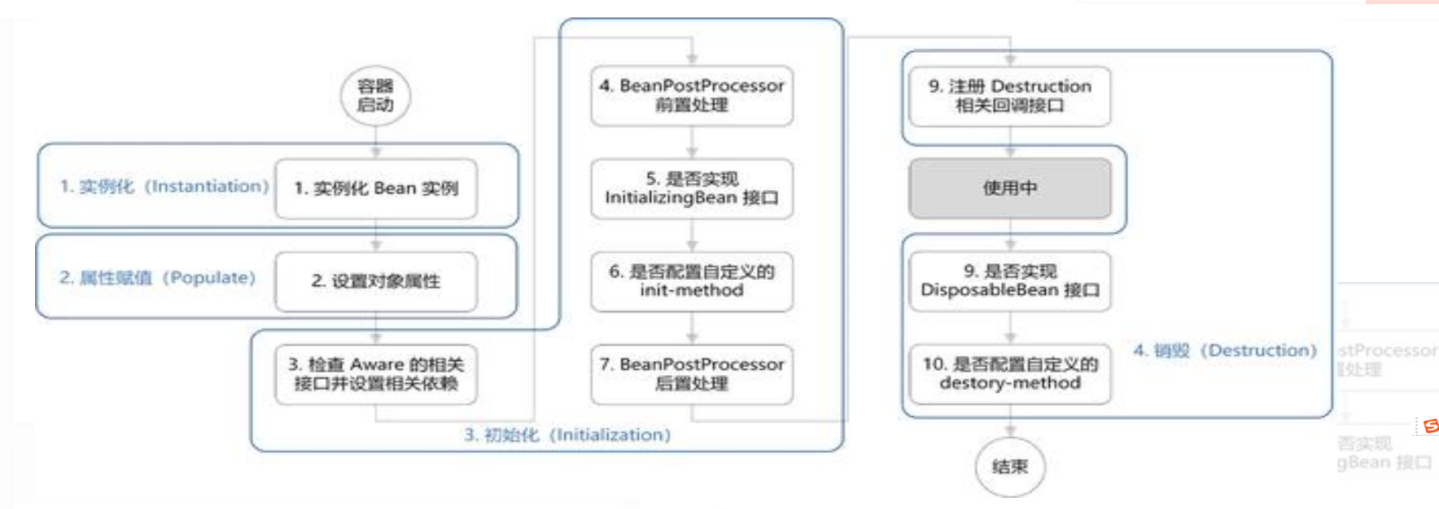
- 实例化:第 1 步,实例化一个 bean 对象;
- 属性赋值:第 2 步,为 bean 设置相关属性和依赖;
- 初始化:第 3~7 步,步骤较多,其中第 5、6 步为初始化操作,第 3、4 步为在初始化前执行,第 7 步在初始化后执行,该阶段结束,才能被用户使用;
销毁:第 8~10步,第8步不是真正意义上的销毁(还没使用呢),而是先在使用前注册了销毁的相关调用接口,为了后面第9、10步真正销毁 bean 时再执行相应的方法。
3.1 Aware 接口
若 Spring 检测到 bean 实现了 Aware 接口,则会为其注入相应的依赖。所以通过让bean 实现 Aware 接口,则能在 bean 中获得相应的 Spring 容器资源。
Spring 中提供的 Aware 接口有:BeanNameAware:注入当前 bean 对应 beanName;
- BeanClassLoaderAware:注入加载当前 bean 的 ClassLoader;
BeanFactoryAware:注入 当前BeanFactory容器 的引用。
Spring依赖注入(控制反转)
依赖注入的另一种说法是“控制反转”,通俗的理解是:平常我们new一个实例,这个实例的控制权是我们程序员,而控制反转是指new实例工作不由我们程序员来做而是交给spring容器来做
详情博客 : (75条消息) spring依赖注入的三种方式以及优缺点_xiegongmiao的博客-CSDN博客_spring依赖注入的三种方式优缺点
三种注入方式
当我们在使用依赖注入的时候,通常有三种方式:
通过构造器来注入; 先类型 加 名字
@Autor 与 @Resource对比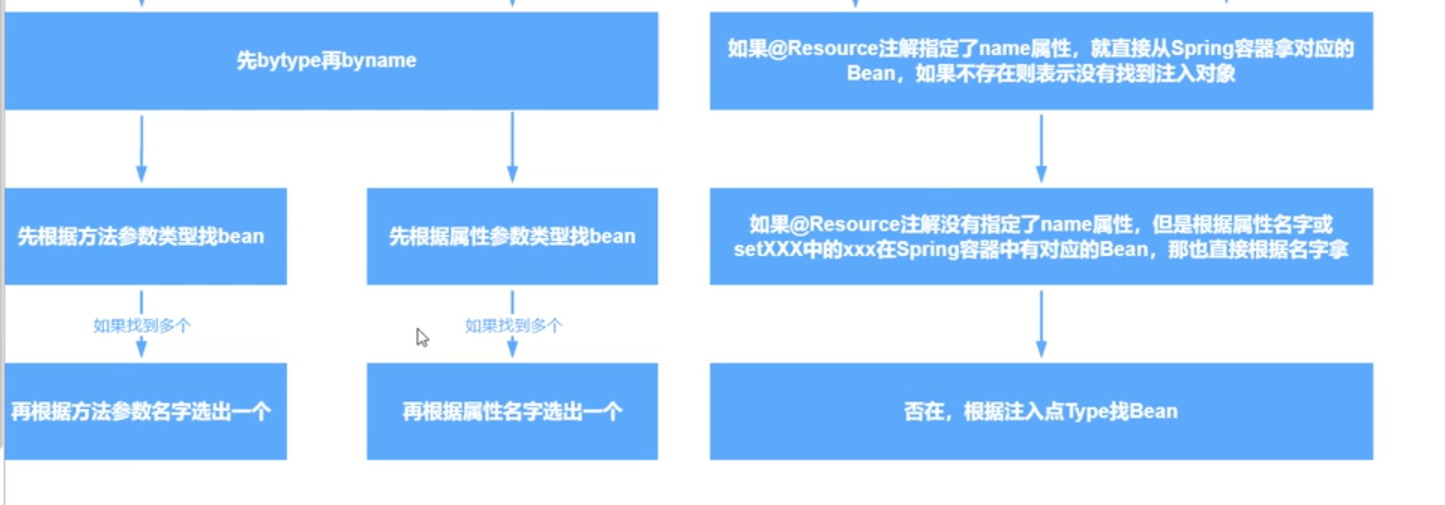
2.通过setter方法来注入
3.通过filed变量来注入;
1.基于constructor的注入,会固定依赖注入的顺序;该方式不允许我们创建bean对象之间的循环依赖关系,这种限制其实是一种利用构造器来注入的益处 - 当你甚至没有注意到使用setter注入的时候,Spring能解决循环依赖的问题;
2.基于setter的注入,只有当对象是需要被注入的时候它才会帮助我们注入依赖,而不是在初始化的时候就注入; 另一方面如果你使用基于constructor注入,CGLIB不能创建一个代理,迫使你使用基于接口的代理或虚拟的无参数构造函数。
3.相信很多同学都选择使用直接在成员变量上写上注解来注入,正如我们所见,这种方式看起来非常好,精短,可读性高,不需要多余的代码,也方便维护;
缺点:
当我们利用constructor来注入的时候,比较明显的一个缺点就是:假如我们需要注入的对象特别多的时候,我们的构造器就会显得非常的冗余、不好看,非常影响美观和可读性,维护起来也较为困难;
当我们选择setter方法来注入的时候,我们不能将对象设为final的; 因为已经创建完对象了,而final是加载到常量池的,在类加载的准备阶段就已经赋值了,而构造器可以,
当我们在field变量上来实现注入的时候
a. 这样不符合JavaBean的规范,而且很有可能引起空指针;
b. 同时也不能将对象标为final的;
c. 类与DI容器高度耦合,我们不能在外部使用它;
d.类不通过反射不能被实例化(例如单元测试中),你需要用DI容器去实例化它,这更像集成测试;
总结:
强制性的依赖性或者当目标不可变时,使用构造函数注入(应该说尽量都使用构造器来注入)
可选或多变的依赖使用setter注入(建议可以使用构造器结合setter的方式来注入)
在大多数的情况下避免field域注入(感觉大多数同学可能会有异议,毕竟这个方式写起来非常简便,但是它的弊端确实远大于这些优点)
Spring事务


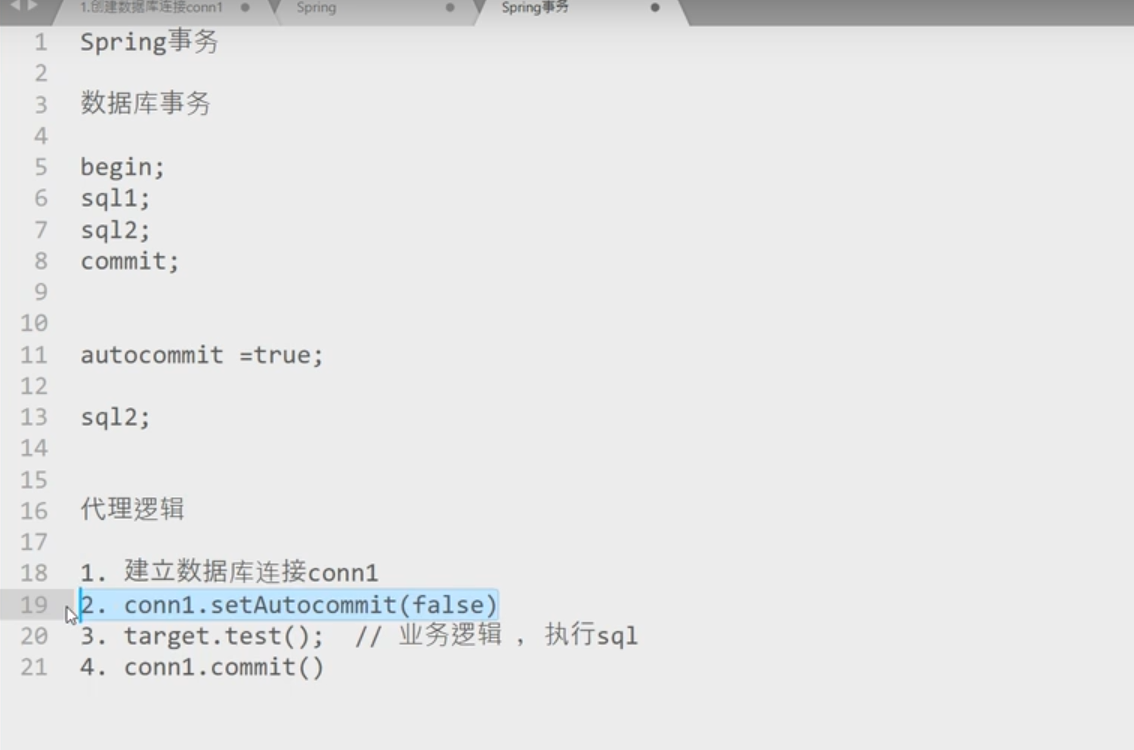
只有用代理对象的方法调动时事务注解才有用

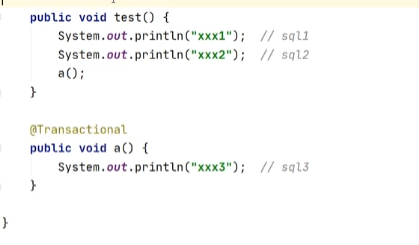
事务会失效的场景,不用代理对象调用方法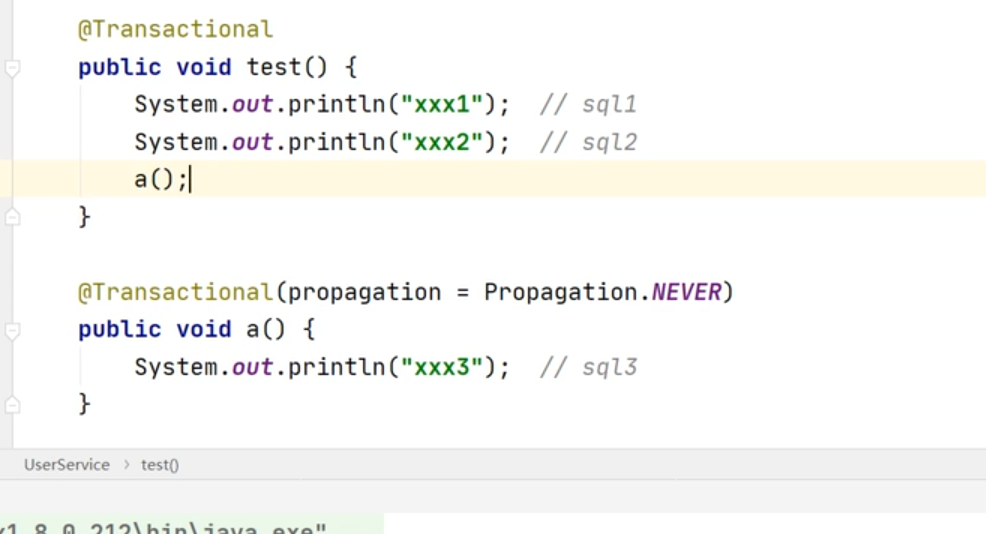

自己调自己,用自己的属性去调用方法肯定是用的一个代理对象
单例开始就创建对象,原型用的时候创建对象,
先判断是否为单例和原型,然后加载到bitMap里边,然后如果单例加载到单例池里边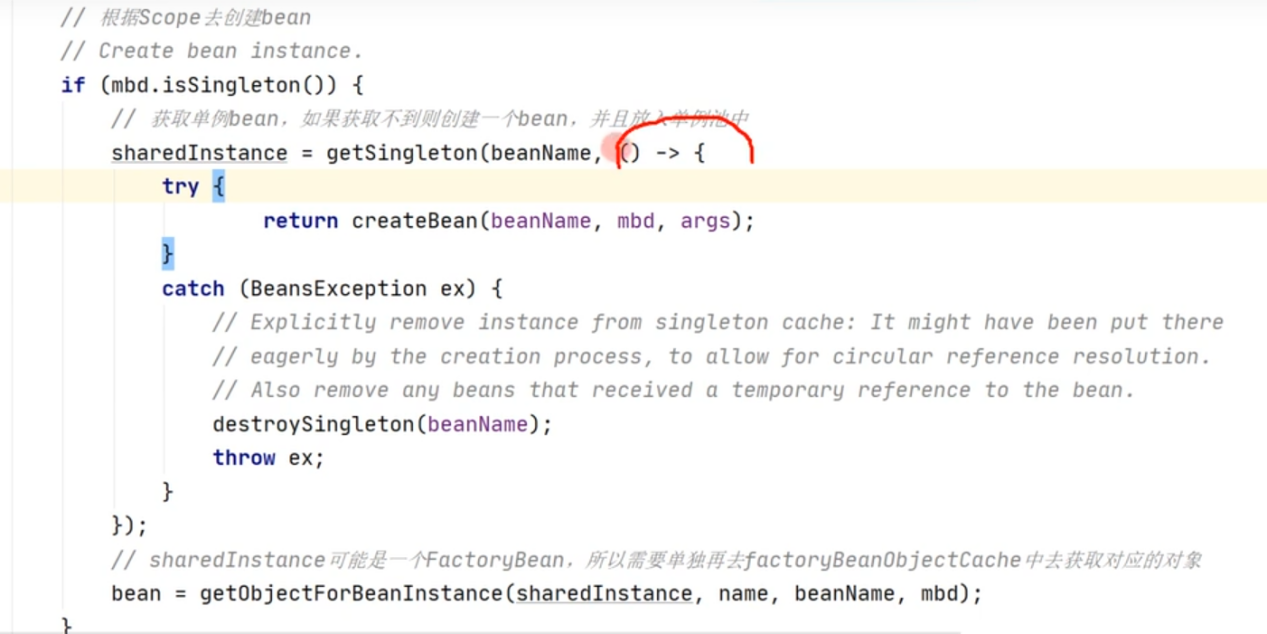
全局异常类处理
throw 用在函数内,后面跟的 是异常对象
@ControllerAdvice作用注解将作用在所有注解了@RequestMapping的控制器的方法上。
另外需要注意的是,@ControllerAdvice注解是一定需要搭配其它的注解或者接口使用的,否则就算这个注解类被识别到,没有具体的处理方法,SpringMVC是不会进行任何操作的。
@ControllerAdvice注解从名字上就可以看出来这个是针对Controller的切面增强处理注解,类似与@Controller和@RestController一样,@ControllerAdvice也有对应的@RestControllerAdvice注解用来返回序列化之后的对象。
@ExceptionHandler的使用,其它两个接口则可以对请求体和返回体进行统一的处理,如整个项目需要对请求和返回进行加解密,则可以使用这两个接口对请求体和响应进行切面处理。
如果没有这个@ExceptionHandler,tomcat就会报异常信息,并且返回内置的500错误页面,很恶心,用户看不懂,而且其实这不属于服务器异常,而是Java代码可处理的异常,为防止这个增加responsestatus注解使其返回200正确,然后又返回responsebody注解返回json数据,返回一个自动以的状态,对象,加上属性使其改变为fail
自定义异常
1 定义一个接口,包括获得错误码和错误信息方法和返回这个接口的方法
二、接口作为方法的返回值进行传递:必须返回一个实现类的对象。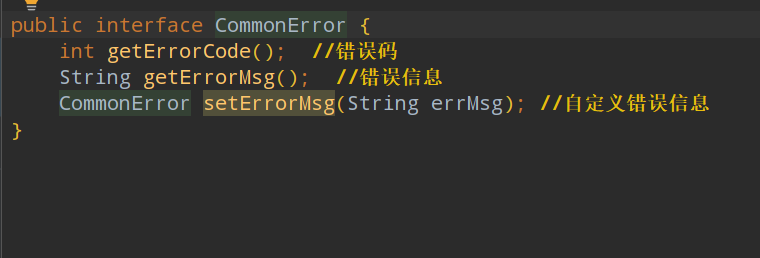 2.定义枚举类,定义通用的接口的常用错误码和错误信息
2.定义枚举类,定义通用的接口的常用错误码和错误信息
例如参数不合法,未知错误等,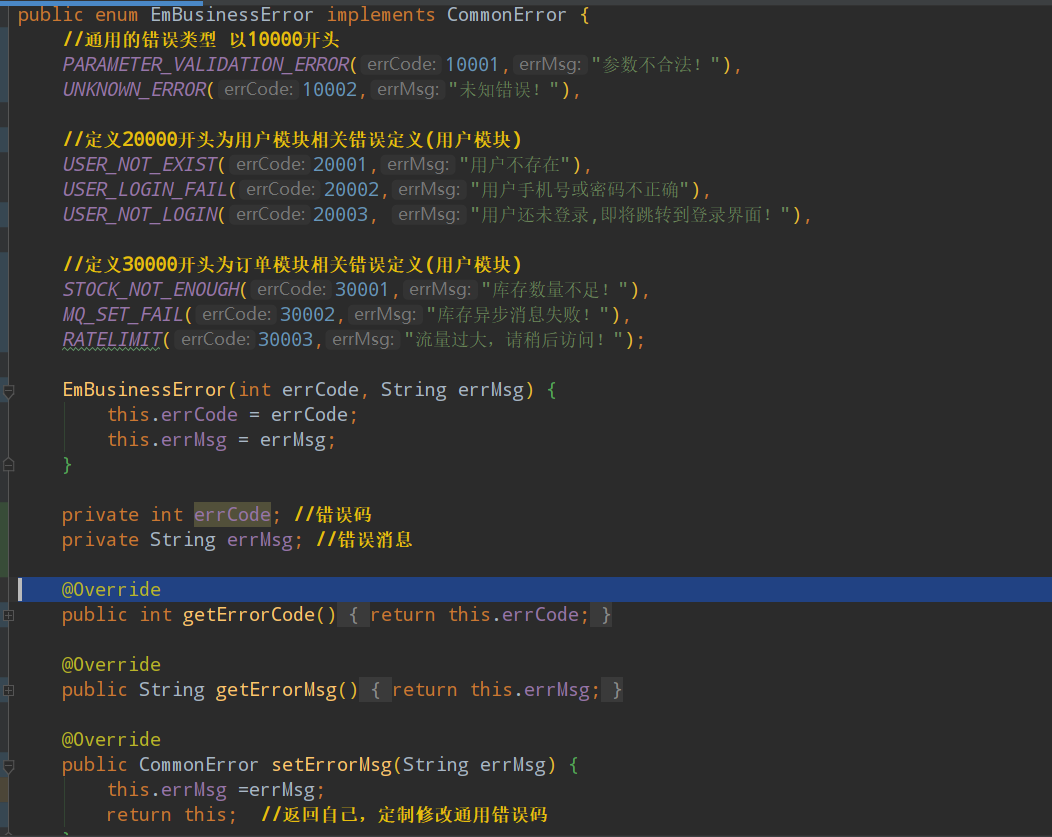
4.继承异常exception和实现接口
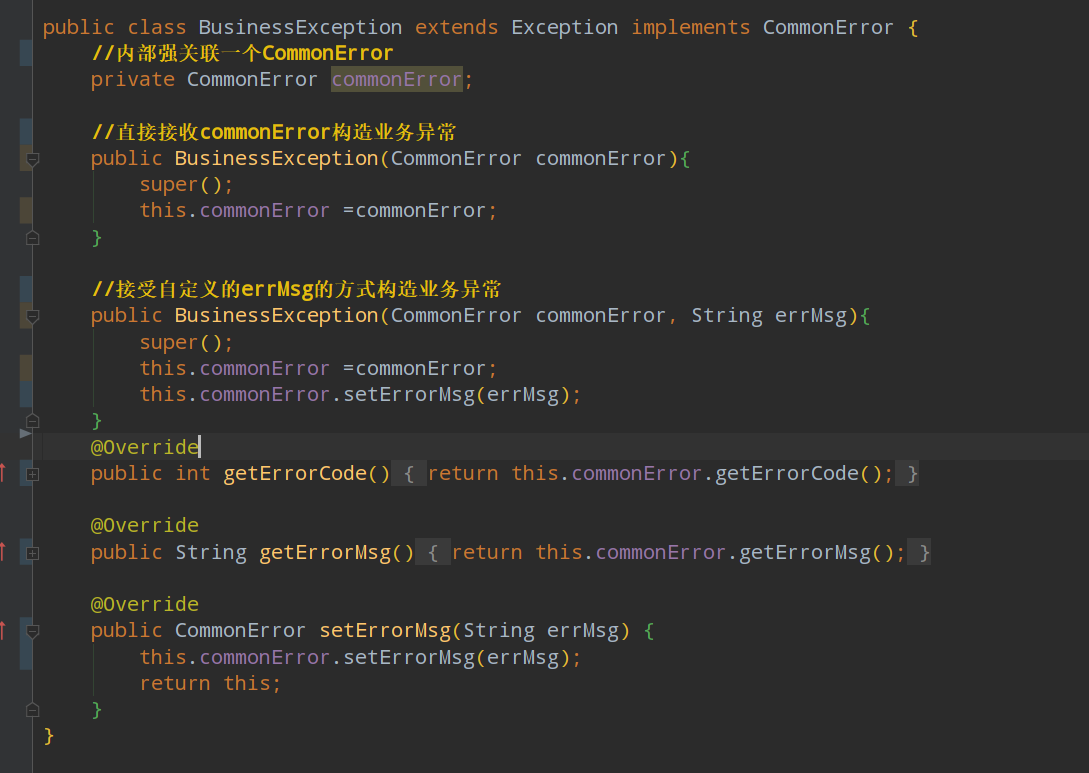
【2】为什么需要枚举类?
(1)就如上面所说的,有些类的实例有限且固定,需要有一种特定且方便的方式来表示这种类。<br /> (2)使用枚举类可以使程序更加健壮,避免创建对象的随意性。<br /> (3)避免一些常量值的意义不明确(这个在下面会有具体示例)。
【3】枚举类的语法
(1) 枚举类默认继承 java.lang.Enum 类,而不是 Object 类,因此枚举类不能显示继承其他父类。<br /> (2) 使用 enum 定义的非抽象的枚举类默认会使用 final 修饰,因此非抽象枚举类不能派生子类(即不能被继承)。<br /> > final关键字回顾:final修饰的类不能被继承、修饰的方法不能被重写、修饰的属性其值不能改变<br />(3) 枚举类的构造器只能使用 private 访问控制符,如果忽略访问控制符的话,则默认使用 private 修饰;如果强制指定其他的访问控制符(例如public、procted等),则会报错。<br />(4) 枚举类的所有实例必须在枚举类的第一行显示列出,否则这个枚举类永远都不可能产生实例。列出
Springboot全局异常类注解详解
@ControllerAdvice
此注解扫描当前包下所有的@controller注解生成的bean,放入map集合里,放在一个缓存池里,加上@ResponseBody注解
从而响应返回json数据,将Java对象转换成json数据返回给前端,从而防止tomcat内部发生异常直接返回封装好的恶心界面。这时候前端收到json数据之后可以对应一个弹窗显示,就很友好,
然后@ExceptionHandler(value = Exception.class)注解就是捕获异常,底层是判断异常,加上value值说明异常类的范围,比如直接像上边,然后底层判断哪些异常,调用的是trycatch方法处理异常,用日志打印错误信息,返回控制台。
在其中比较重要的有三个注解,分别是:
1)@SpringBootConfiguration // 继承了Configuration,表示当前是注解类
2)@EnableAutoConfiguration // 开启springboot的注解功能,springboot的四大神器之一,其借助@import的帮助
3)@ComponentScan(excludeFilters = { // 扫描路径设置(具体使用待确认)
接下来对三个注解一一详解,增加对springbootApplication的理解:
BeanFactory 和ApplicationContext的区别
BeanFactory和ApplicationContext都是接口,并且ApplicationContext间接继承了BeanFactory。
BeanFactory是Spring中最底层的接口,提供了最简单的容器的功能,只提供了实例化对象和获取对象的功能,而ApplicationContext是Spring的一个更高级的容器,提供了更多的有用的功能。
ApplicationContext提供的额外的功能:获取Bean的详细信息(如定义、类型)、国际化的功能、统一加载资源的功能、强大的事件机制、对Web应用的支持等等。
加载方式的区别:BeanFactory采用的是延迟加载的形式来注入Bean;ApplicationContext则相反的,它是在Ioc启动时就一次性创建所有的Bean,好处是可以马上发现Spring配置文件中的错误,坏处是造成浪费。
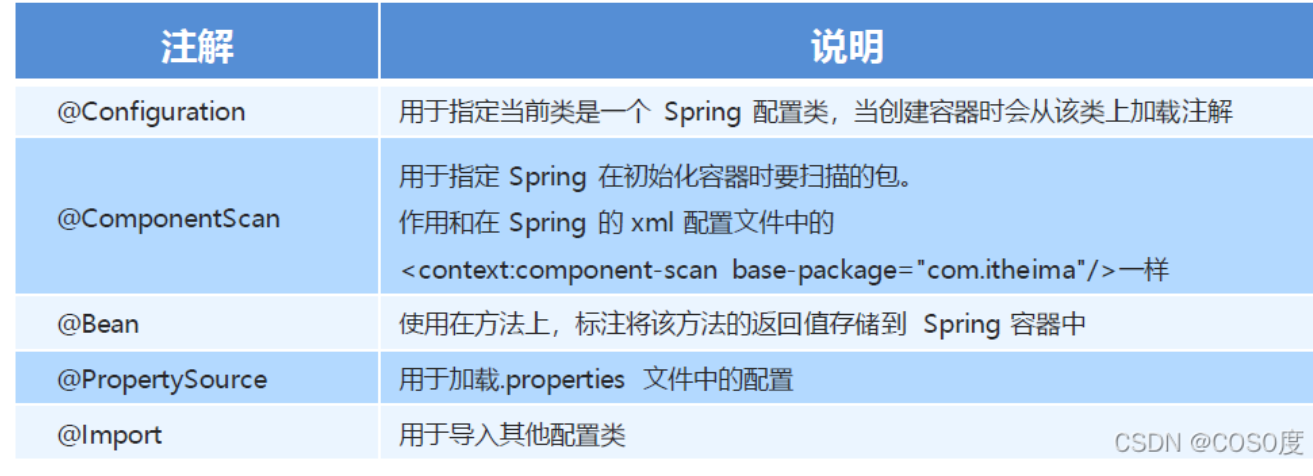
到了这里,注解可能还没起什么作用。我们需要通过反向代理去读取类中定义的注解,读出来使用就简单了。
一.什么是注解:
注解是标记,也可以理解成是一种应用在类、方法、参数、属性、构造器上的特殊修饰符。注解作用有以下三种:第一种:生成文档,常用的有@param@return等。第二种:替代配置文件的作用,尤其是在spring等一些框架中,使用注解可以大量的减少配置文件的数量。第三种:检查代码的格式,如@Override,标识某一个方法是否覆盖了它的父类的方法。
二.注解的底层实现原理:
注解的底层也是使用反射实现的,我们可以自定义一个注解来体会下。注解和接口有点类似,不过申明注解类需要加上@interface,注解类里面,只支持基本类型、String及枚举类型,里面所有属性被定义成方法,并允许提供默认值。
Springboot循环依赖问题
什么情况下循环依赖可以被处理?
在回答这个问题之前首先要明确一点,Spring解决循环依赖是有前置条件的
1.出现循环依赖的Bean必须要是单例
2.依赖注入的方式不能全是构造器注入的方式(很多博客上说,只能解决setter方法的循环依赖,这是错误的)
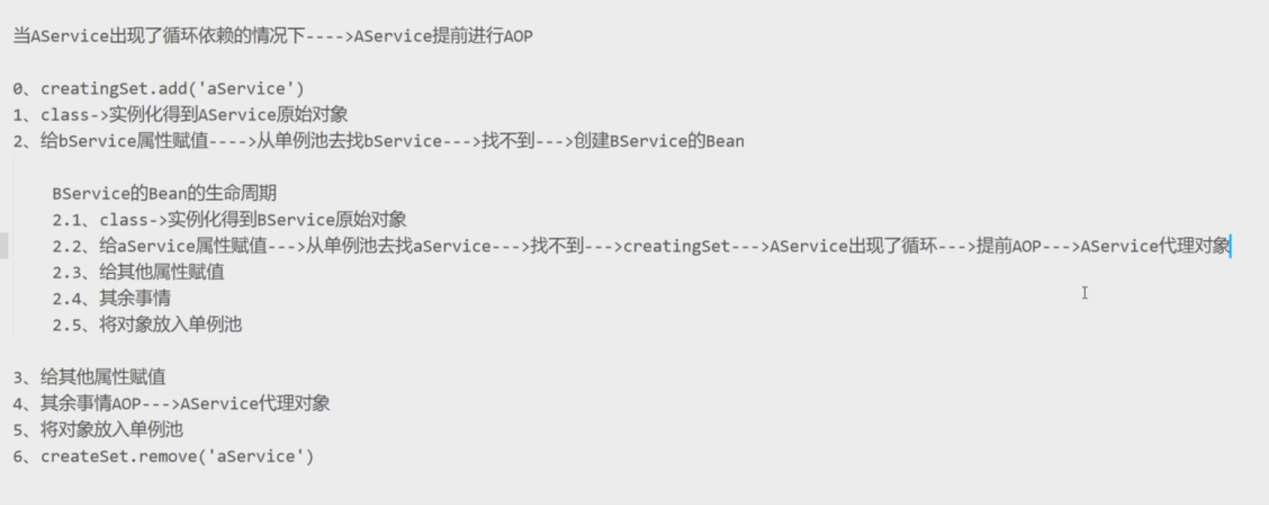
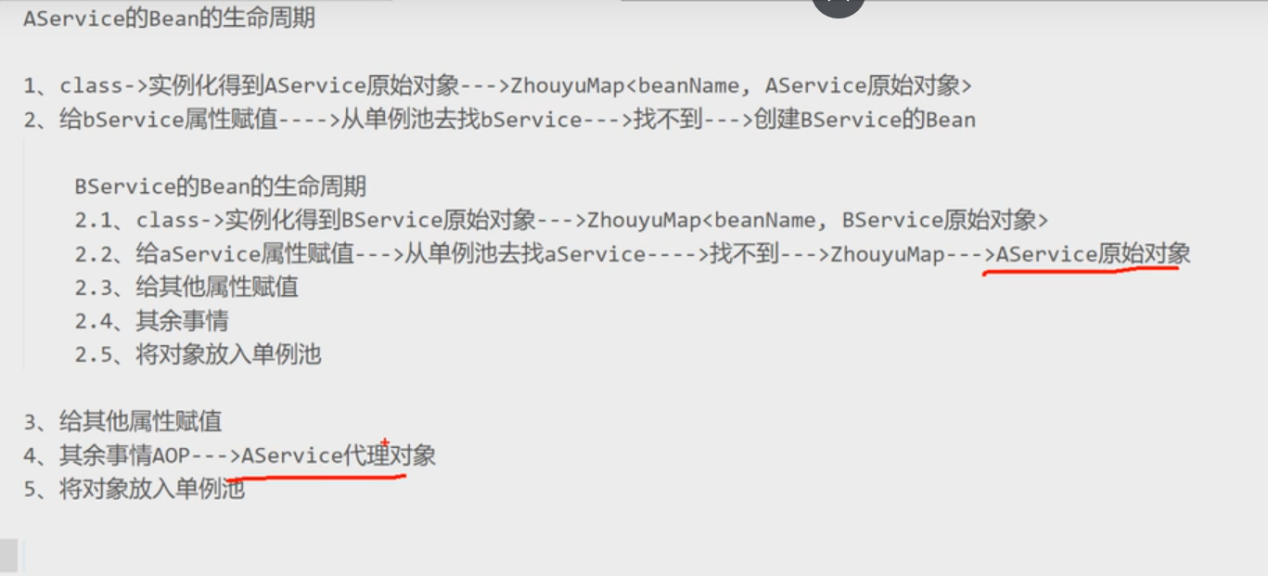
有AOP情况
无AOP
特殊情况,有个c也循环注入a
二级缓存解决单例安全问题,保证只创建一个对象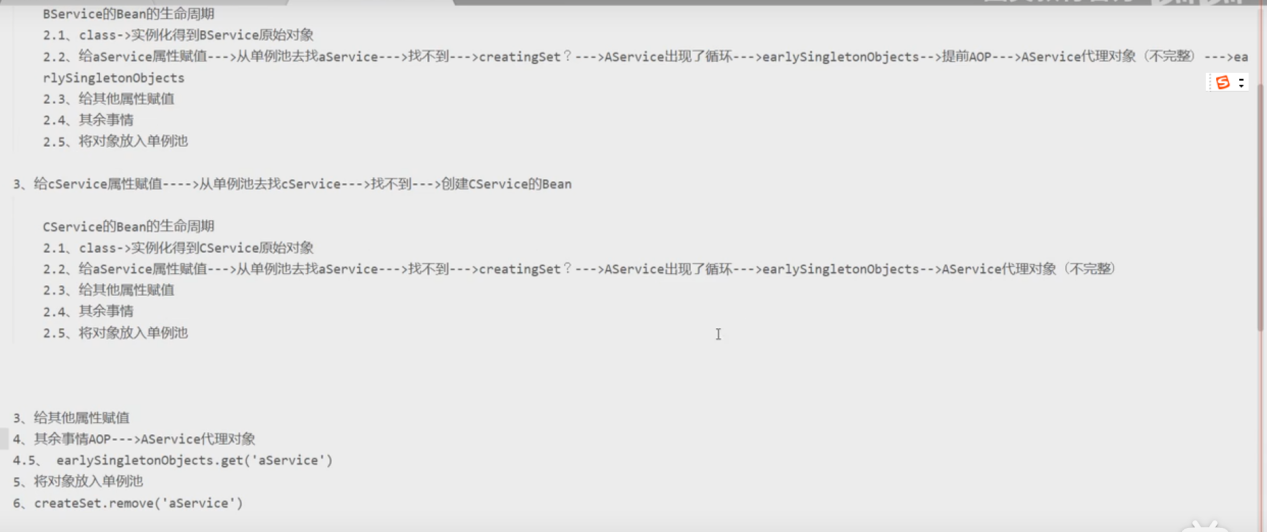
关于循环依赖的解决方式应该要分两种情况来讨论
1.简单的循环依赖(没有AOP)
2.结合了AOP的循环依赖
与此同时,我们应该知道,Spring在创建Bean的过程中分为三步
1.实例化,简单理解就是new了一个对象
2.属性注入,为实例化中new出来的对象填充属性
3.初始化,执行aware接口中的方法,初始化方法,完成AOP代理
三级缓存
一级ConcurrentHashMap
二级 三级都是HashMap 因为两缓存只能有一个对象,为了保证这个,如果调AOP存三级缓存,不调AOP(打日志)就不存三级,为了保证只创建一个代理对象,单例,如果三级缓存创建了就删除二级缓存的对象,如果二级缓存有对象就删除二级缓存的,保证只创建一个对象,因为为了保持单例使用的hash表,beanName保持的,如果一个存了,那个绝对不能存,否则就不是一个代理对象了,而为了保证这个原子操作,就只能加synchronize锁,而ConcurrentHashMap没用了,一级有用,最后的结果都是放在一级缓存(成品,二级只是半成品),单例池里的。用ConcuhashMap。存Lam表达式回调返回给二级缓存。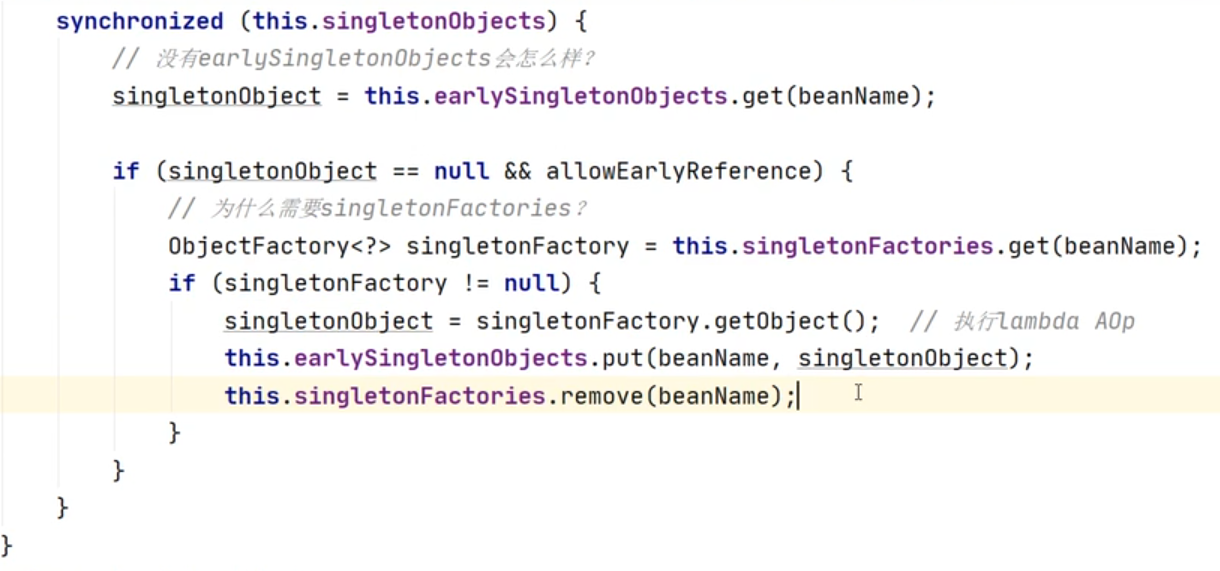
循环依赖原因
原因很好理解,创建新的A时,发现要注入原型字段B,又创建新的B发现要注入原型字段A…
这就套娃了, 你猜是先StackOverflow还是OutOfMemory?
Spring怕你不好猜,就先抛出了BeanCurrentlyInCreationException
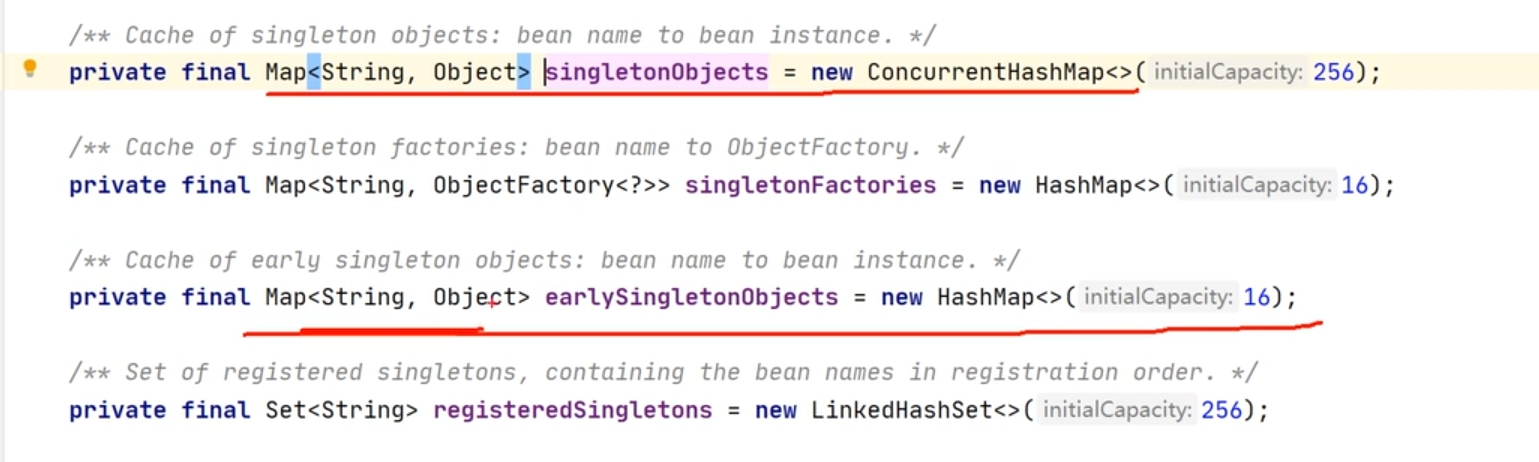
三级缓存
singletonObjects:第一级缓存,里面存放的都是创建好的成品Bean。单例池 concurrenthashmap
earlySingletonObjects : 第二级缓存,里面存放的都是半成品的Bean。null值,但是无所谓,后边会填充 hashMap
singletonFactories :第三级缓存, 不同于前两个存的是 Bean对象引用,此缓存存的bean 工厂对象,也就存的是 专门创建Bean的一个工厂对象。此缓存用于解决循环依赖代理对象 hashMap
- singletonObjects:成品缓存 单例池
- earlySingletonObjects: 单例半成品缓存,同时也解决循环依赖
- singletonFactories :单例工厂缓存
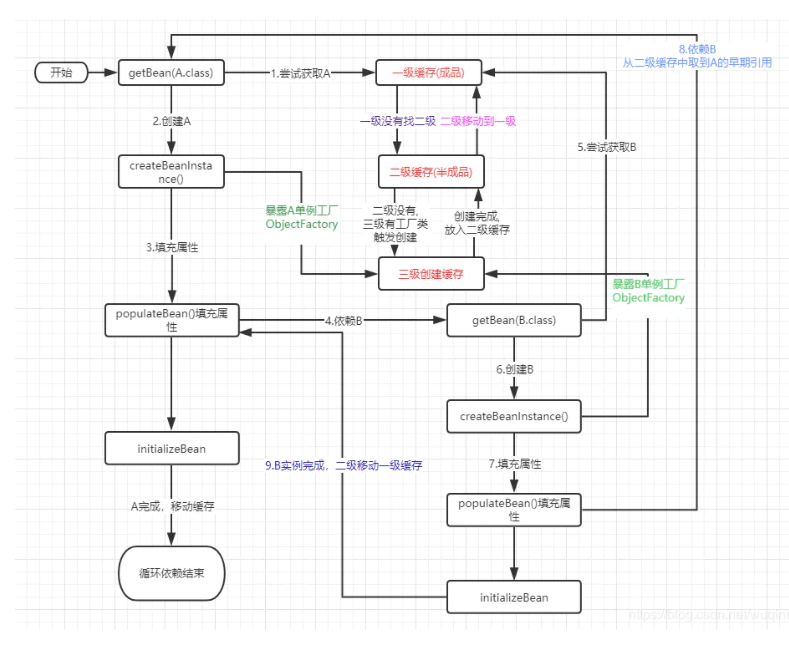
循环依赖的关键点:**提前暴露绑定A原始引用的工厂类到工厂缓存。等需要时触发后续操作处理A的早期引用,将处理结果放入二级缓存**
注意:单例bean与单例模式不是一个概念,只是相同的名字可以拿到同一个对象,原理单例注册表实现,
3.为啥需要三个缓存
Spring 为啥用三个缓存去解决循环依赖问题?
上面两个缓存的地方,我们只是没有考虑代理的情况。
代理的存在
Bean在创建的最后阶段,会检查是否需要创建代理,如果创建了代理,那么最终返回的就是代理实例的引用。我们通过beanname获取到最终是代理实例的引用
也就是说:上文中,假设A最终会创建代理,提前暴露A的引用, B填充属性时填充的是A的原始对象引用。A最终放入成品库里是代理的引用。那么B中依然是A的早期引用。这种结果最终会与我们的期望的大相径庭了。
Spring生命周期
Bean 的生命周期概括起来就是 4 个阶段:
- 实例化(Instantiation)
- 属性赋值(Populate)
- 初始化(Initialization)
- 销毁(Destruction)
- 分为有AOP 和无AOP两种情况
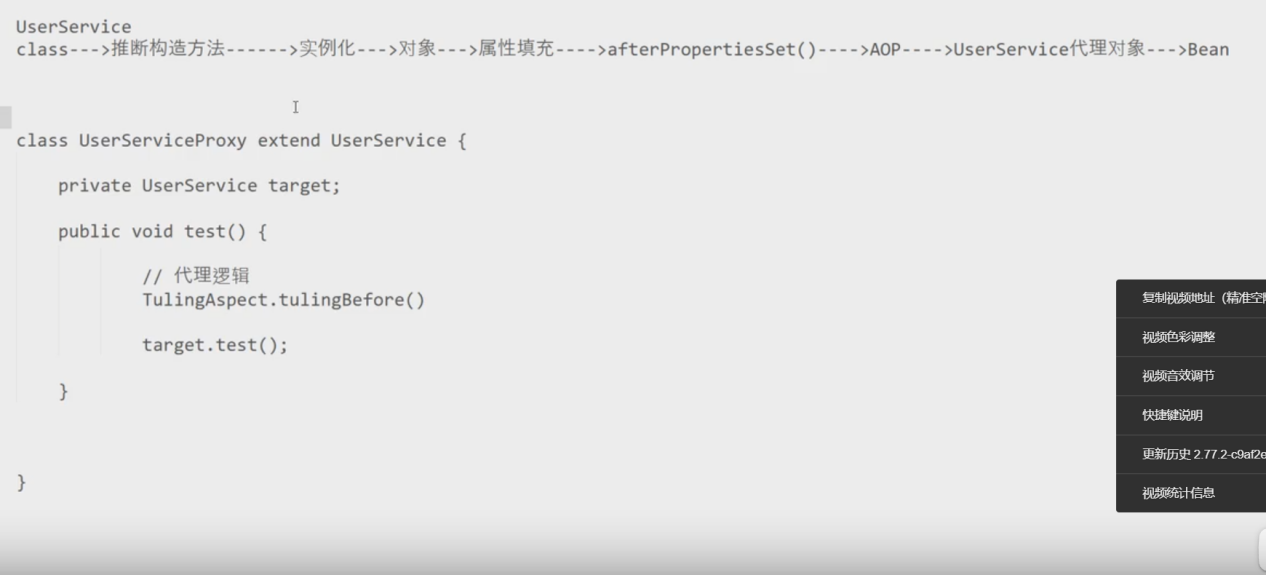
3. Bean的实例化:
(1) 采⽤策略化bean的实例, 两种⽅式:cglib、反射
(2) 获取Bean的实例之后,根据BeanDefinition中信息,填充Bean的属性、依赖
4. 检测各种Aware接⼝,BeanFactory的、ApplicationContext的等
5. 调⽤BeanPostProcessor接⼝的前置处理⽅法,处理符合要求的Bean实例
6. 如果实现了InitializingBean接⼝,执⾏对应的afterPropertiesSet()⽅法
7. 如果定义了init-method,执⾏对应的⾃定义初始化⽅法
8. 调⽤BeanPostProcessor接⼝的前置处理⽅法,处理符合要求的Bean实例
9. 使⽤
10. 判断Bean的Scope,如果是prototype类型,不再管理
11. 如果是单例类型,如果实现了DisposableBean接⼝,执⾏对应的destoy⽅法
12. 如果定义了destory-method,执⾏对应的⾃定义销毁⽅法
Bean 容器找到配置文件中 Spring Bean 的定义。
Bean 容器利用 Java Reflection API 创建一个Bean的实例。
如果涉及到一些属性值 利用 set()方法设置一些属性值。
如果 Bean 实现了 BeanNameAware 接口,调用 setBeanName()方法,传入Bean的名字。
如果 Bean 实现了 BeanClassLoaderAware 接口,调用 setBeanClassLoader()方法,传入 ClassLoader对象的实例。
如果Bean实现了 BeanFactoryAware 接口,调用 setBeanClassLoader()方法,传入 ClassLoade r对象的实例。
与上面的类似,如果实现了其他 *.Aware接口,就调用相应的方法。
如果有和加载这个 Bean 的 Spring 容器相关的 BeanPostProcessor 对象,执行postProcessBeforeInitialization() 方法
如果Bean实现了InitializingBean接口,执行afterPropertiesSet()方法。
如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
如果有和加载这个 Bean的 Spring 容器相关的 BeanPostProcessor 对象,执行postProcessAfterInitialization() 方法
当要销毁 Bean 的时候,如果 Bean 实现了 DisposableBean 接口,执行 destroy() 方法。
当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法
4. 总结
最后总结下如何记忆 Spring Bean 的生命周期:
- 首先是实例化、属性赋值、初始化、销毁这 4 个大阶段;
- 再是初始化的具体操作,有 Aware 接口的依赖注入、BeanPostProcessor 在初始化前后的处理以及 InitializingBean 和 init-method 的初始化操作;
- 销毁的具体操作,有注册相关销毁回调接口,最后通过DisposableBean 和 destory-method 进行销毁
Spring 框架中用到了哪些设计模式?
工厂设计模式 : Spring使用工厂模式通过 BeanFactory、ApplicationContext 创建 bean 对象。
代理设计模式 : Spring AOP 功能的实现。
单例设计模式 : Spring 中的 Bean 默认都是单例的。
模板方法模式 : Spring 中 jdbcTemplate、hibernateTemplate 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
适配器模式 :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配Controller。
@Component 和 @Bean 的区别是什么?
控制反转,简单点说,就是创建对象的控制权,被反转到了Spring框架上。
通常,我们实例化一个对象时,都是使用类的构造方法来new一个对象,这个过程是由我们自己来控制的,而控制反转就把new对象的工交给了Spring容器。
依赖注入,组件不做定位查询,只提供标准的Java方法让容器去决定依赖关系。容器全权负责组件的装配,把符合依赖关系的对象通过Java Bean属性或构造方法传递给需要的对象。
依赖注入:由IoC容器动态地将某个对象所需要的外部资源(包括对象、资源、常量数据)注入到组件(Controller, Service等)之中。简单点说,就是IoC容器会把当前对象所需要的外部资源动态的注入给我们。
Spring依赖注入的方式主要有四个,基于注解注入方式、set注入方式、构造器注入方式、静态工厂注入方式。推荐使用基于注解注入方式,配置较少,比较方便。
@Autowired默认按类型进行自动装配(该注解属于Spring),默认情况下要求依赖对象必须存在,如果要允许为null,需设置required属性为false,例:@Autowired(required=false)。如果要使用名称进行装配,可以与@Qualifier注解一起使用。
在 bean 实例化完成、属性注入完成之后,会执行回调方法,具体请参见类 AbstractAutowireCapableBeanFactory#initBean 方法。
首先会回调几个实现了 Aware 接口的 bean,然后就开始回调 BeanPostProcessor 的 postProcessBeforeInitialization 方法,之后是回调 init-method,然后再回调 BeanPostProcessor 的 postProcessAfterInitialization 方法
这里将会初始化 BeanFactory、加载 Bean、注册 Bean 等等。这个方法将根据配置,加载各个 Bean,然后放到 BeanFactory 中。读取配置的操作在 XmlBeanDefinitionReader 中,其负责加载配置、解析。
id 为 “car” 的 bean 其实指定的是一个 FactoryBean,不过配置的时候,我们直接让配置 Person 的 Bean 直接依赖于这个 FactoryBean 就可以了。
Spring面向切面编程(AOP)
应用场景:记录日志、异常处理等操作,AOP把所有共用代码都剥离出来,单独放置到某个类中进行集中管理,在具体运行时,由容器进行动态织入这些公共代码。
和面向切面编程(AOP)的容器框架。

若有收获,就点个赞吧
0 人点赞
