- NameServer
- MessageId
- 4 Broker
- 日志存储
- 有序性
- RocketMq为何如此之快?
- 高级特性
- 可视化工具好处
- 重平衡
- RocketMq与kafka不同(总结)
- RocketMq事务(外部事务)
- 7 主从复制不同(也差不多)
- 7.有序性保证不一样
- 8.重平衡(差不多)
- 8 消息过滤不同
- 10 重试机制不同(kafka慢)
- 11 刷盘不同(RocketMq慢)
NameServer
NameServer 是一个 Broker 与 Topic 路由的注册中心,支持 Broker 的动态注册与发现。RocketMQ 的思想来自于 Kafka ,而 Kafka 是依赖了 Zookeeper的。所以,在RocketMQ的早期版本,即在 MetaQ v1.0 与 v2.0 版本中,也是依赖于 Zookeeper 的。从 MetaQ v3.0 ,即 RocketMQ 开始去掉Zookeeper 依赖,使用了自己的 NameServer 。 主要包括两个功能:
Broker 管理:
接受 Broker 集群的注册信息并且保存下来作为路由信息的基本数据;
提供心跳检测 机制,检查 Broker 是否还存活。
路由信息管理:
每个 NameServer 中都保存着 Broker 集群的整个路由信息和用于客户端查询的队列信息。 Producer 和 Conumser 通过 NameServer 可以获取整个Broker集群的路由信息,从而进行消 息的投递和消费。
NameServer路由信息有四个Map,
topic信息,brokerIp等信息,集群信息,心跳具体信息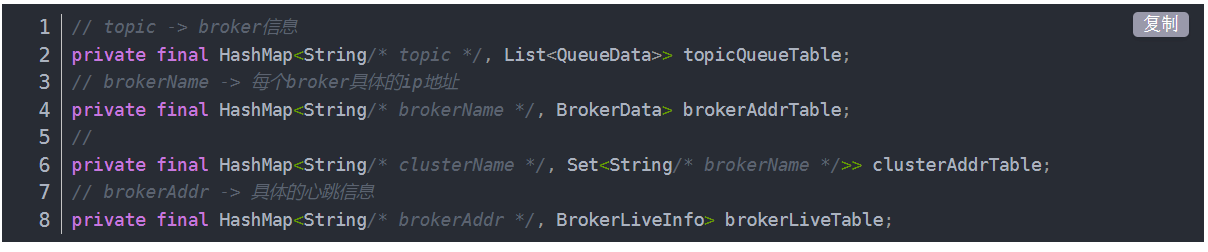
注意,这是与其它像 zk 、 Eureka 、 Nacos 等注册中心不同的地方。
这种 NameServer 的无状态方式,有什么优缺点:
无状态:即 NameServer 集群中的各 个节点间是无差异的,各节点间相互不进行信息通讯
如何保证数据同步 ?
在Broker节点启动时,轮询 NameServer 列表,与每个 NameServer 节点建立长连接,发起注册 请求。在 NameServer 内部维护着⼀个 Broker 列表,用来动态存储 Broker 的信息。
优缺点
优点: NameServer 集群搭建简单,扩容简单。
缺点:对于 Broker ,必须明确指出所有 NameServer 地址。否则未指出的将不会去注册。也正因为如此, NameServer 并不能随便扩容。因为,若 Broker 不重新配置,新增的 NameServer 对于 Broker 来说是不可见的,其不会向这个 NameServer 进行注册。
Broker 节点为了证明自己是活着的,为了维护与 NameServer 间的长连接,会将最新的信息以 心跳包 的 方式上报给 NameServer ,每 30 秒发送一次心跳。心跳包中包含 BrokerId 、 Broker 地址(IP+Port)、 Broker 名称、 Broker 所属集群名称等等。 NameServer 在接收到心跳包后,会更新心跳时间戳, 记录这 个 Broker 的最新存活时间。
NameServer 可能会将其从 Broker 列表中剔除。
NameServer 中有⼀个定时任务,每隔 10 秒就会扫描⼀次 Broker 表,查看每一个 Broker 的最新心跳时间戳距离当前时间是否超过 120 秒,如果超过,则会判定 Broker 失效,然后将其从 Broker
Zookeeper与NameServer选客户端IP区别
Nameserve先随机,失败后轮询
客户端在配置时必须要写上 NameServer 集群的地址,那么客户端到底连接的是哪个 NameServer 节点 呢?客户端首先会生产一个随机数,然后再与NameServer 节点数量取模,此时得到的就是所要连接的节点索引,然后就会进行连接。如果连接失败,则会采用round-robin 策略,逐个尝试着去连 接其它节 点。
首先采用的是 随机策略 进行的选择,失败后采用的是 轮询策略 。
扩展: Zookeeper Client 是如何选择 Zookeeper Server 的?两次随机
简单来说就是,经过两次 Shufæe ,然后选择第一台 Zookeeper Server 。
详细说就是,将配置文件中的 zk server 地址进行第一次 shufæe ,然后随机选择一个。这个选择出的一般都是一个 hostname 。然后获取到该 hostname对应的所有 ip ,再对这些 ip 进行第二 shufæe ,从 shufæe 过的结果中取第一个 server 地址进行连接。
MessageId
RocketMQ 中每个消息拥有唯一的 MessageId ,且可以携带具有业务标识的 Key ,以方便对消息的查询。不过需要注意的是, MessageId 有两个:在生产者send()消息时会自动生成一个 MessageId ( msgId) , 当消息到达 Broker 后, Broker 也会自动生成一个 MessageId(offsetMsgId) 。 msgId 、offsetMsgId与key 都 称为消息标识。
4 Broker
Broker 充当着消息中转角色,负责存储消息、转发消息。 Broker 在 RocketMQ 系统中负责接收并存储从生产者发送来的消息,同时为消费者的拉取请求作准备。 Broker 同时也存储着消息相关的元数据,包括消费者组消费进度偏移offset 、主题、队列等。
构成
Remoting Module : 整个 Broker 的实体,负责处理来自 clients 端的请求。而这个 Broker 实体则由以下模块构成。
Client Manager : 客户端管理器。负责接收、解析客户端 (Producer/Consumer) 请求,管理客户端。例如,维护 Consumer 的 Topic 订阅信息
Store Service : 存储服务。提供方便简单的 API 接口,处理 消息存储到物理硬盘 和 消息查询 功能。
HA Service : 高可用服务,提供 Master Broker 和 Slave Broker 之间的数据同步功能。
Index Service : 索引服务。根据特定的 Message key ,对投递到 Broker 的消息进行索引服务,同时也提供根据 Message Key 对消息进行快速查询的功能。
消息查询
1 按照MessageId查询消息
RocketMQ中的MessageId的长度总共有16字节,其中包含了消息存储主机地址(IP地址和端口),消息Commit Log offset。“按照MessageId查询消息”在RocketMQ中具体做法是:Client端从MessageId中解析出Broker的地址(IP地址和端口)和Commit Log的偏移地址后封装成一个RPC请求后通过Remoting通信层发送(业务请求码:VIEW_MESSAGE_BY_ID)。Broker端走的是QueryMessageProcessor,读取消息的过程用其中的 commitLog offset 和 size 去 commitLog 中找到真正的记录并解析成一个完整的消息返回。
2 按照Message Key查询消息
按照Message Key查询消息,主要是基于RocketMQ的IndexFile索引文件来实现的。RocketMQ的索引文件逻辑结构,类似JDK中HashMap的实现。
接收查看发送状态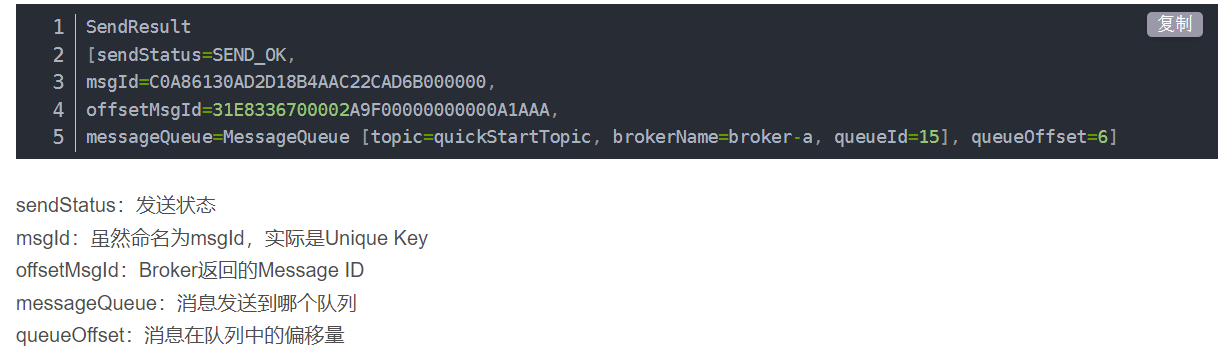
Topic 的创建模式
手动创建 Topic 时,有两种模式:
集群模式:该模式下创建的 Topic 在该集群中,所有 Broker 中的 Queue 数量是相同的 。
Broker 模式:该模式下创建的 Topic 在该集群中,每个 Broker 中的 Queue 数量可以不同。
自动创建 Topic 时,默认采用的是 Broker 模式,会为每个 Broker 默认创建 4 个 Queue 。
集群如何保证数据不丢失?
其解决方案是,将每个Broker 集群节点进行横向扩展,即将 Broker 节点再建为一个 HA 集群,解决单点问题。 Broker 节点集群是一个主从集群,即集群中具有 Master 与 Slave 两种角色。
Master 负责处理读写操作请 求, Slave 负责对 Master 中的数据进行备 份。当 Master 挂掉了, Slave 则会自动切换为 Master 去工作。所 以这个 Broker 集群是主备集群。一个 Master 可以包含多个Slave ,但一个 Slave 只能隶 属于一个 Master 。 Master 与 Slave 的对应关系是通过指定相同的 BrokerName 、不同的 BrokerId 来确定的。 BrokerId 为 0 表 示 Master ,非 0 表示 Slave 。
每个 Broker 与 NameServer 集群中的所有节点建立长连接,定时注册 Topic 信 息到所 NameServer 。
复制策略
复制策略是Broker的Master与Slave间的数据同步方式。
分为同步复制与异步复制:
同步复制:消息写入master后,master会等待slave同步数据成功后才向producer返回成功ACK
异步复制:消息写入master后,master立即向producer返回成功ACK,无需等待slave同步数据成功
异步复制策略会降低系统的写入延迟,RT变小,提高了系统的吞吐量
刷盘策略
刷盘策略指的是broker中消息的落盘方式,即消息发送到broker内存后消息持久化到磁盘的方式。分为 同步刷盘与异步刷盘:
同步刷盘:当消息持久化到broker的磁盘后才算是消息写入成功。
异步刷盘:当消息写入到broker的内存后即表示消息写入成功,无需等待消息持久化到磁盘。
多Master多Slave模式-异步复制
broker集群由多个master构成,每个master又配置了多个slave(在配置了RAID磁盘阵列的情况下,一 个master一般配置一个slave即可)。master与slave的关系是主备关系,即master负责处理消息的读写请求,而slave仅负责消息的备份与master宕机后的角色切换。 异步复制即前面所讲的复制策略中的异步复制策略,即消息写入master成功后,master立即向producer返回成功ACK,无需等待slave同步数据成功。 该模式的最大特点之一是,当master宕机后slave能够自动切换为master。不过由于slave从master的同步具有短暂的延迟(毫秒级),所以当master宕机后,这种异步复制方式可能会存在少量消息的丢失问题。
日志存储
需要注意的是,一个Broker中仅包含一个commitlog目录,所有的mappedFile文件都是存放在该目录中的。即无论当前Broker中存放着多少Topic的消息,这些消息都是被顺序写入到了mappedFile文件中的。也就是说,这些消息在Broker中存放时并没有被按照Topic进行分类存放。
mappedFile文件是顺序读写的文件,所有其访问效率很高
无论是SSD磁盘还是SATA磁盘,通常情况下,顺序存取效率都会高于随机存取。
高效存储日志性能
性能提升
RocketMQ中,无论是消息本身还是消息索引,都是存储在磁盘上的。其不会影响消息的消费吗?当然不会。其实RocketMQ的性能在目前的MQ产品中性能是非常高的。因为系统通过一系列相关机制大大提升了性能。
零拷贝
首先,RocketMQ对文件的读写操作是通过mmap零拷贝进行的,将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率。
ageCache的预读取机制
其次,consumequeue中的数据是顺序存放的,还引入了PageCache的预读取机制,使得对consumequeue文件的读取几乎接近于内存读取,即使在有消息堆积情况下也不会影响性能。
PageCache机制,页缓存机制,是OS对文件的缓存机制,用于加速对文件的读写操作。一般来 说,程序对文件进行顺序读写的速度几乎接近于内存读写速度,主要原因是由于OS使用 PageCache机制对读写访问操作进行性能优化,将一部分的内存用作PageCache。
写操作:OS会先将数据写入到PageCache中,随后会以异步方式由pdflush(page dirty flush) 内核线程将Cache中的数据刷盘到物理磁盘
读操作:若用户要读取数据,其首先会从PageCache中读取,若没有命中,则OS在从物理磁 盘上加载该数据到PageCache的同时,也会顺序对其相邻数据块中的数据进行预读取。
RocketMQ中可能会影响性能的是对commitlog文件的读取。因为对commitlog文件来说,读取消息时会产生大量的随机访问,而随机访问会严重影响性能。不过,如果选择合适的系统IO调度算法,比如设置调度算法为Deadline(采用SSD固态硬盘的话),随机读的性能也会有所提升。
有序性
如果有多个Queue参与,其仅可保证在该Queue分区队列上的消息顺序,则称为分区有序。
如何实现Queue的选择?在定义Producer时我们可以指定消息队列选择器,而这个选择器是我们 自己实现了MessageQueueSelector接口定义的。
当发送和消费参与的Queue只有一个时所保证的有序是整个Topic中消息的顺序, 称为全局有序
RocketMq为何如此之快?
Kafka 实现了零拷贝原理来快速移动数据,避免了内核之间的切换。Kafka 可以将数据记录分批发送,从生产者到文件系统(Kafka 主题日志)到消费者,可以端到端的查看这些批次的数据。
批处理能够进行更有效的数据压缩并减少 I/O 延迟,Kafka 采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费,更多关于磁盘寻址的了解,请参阅 程序员需要了解的硬核知识之磁盘 。
顺序读写
零拷贝
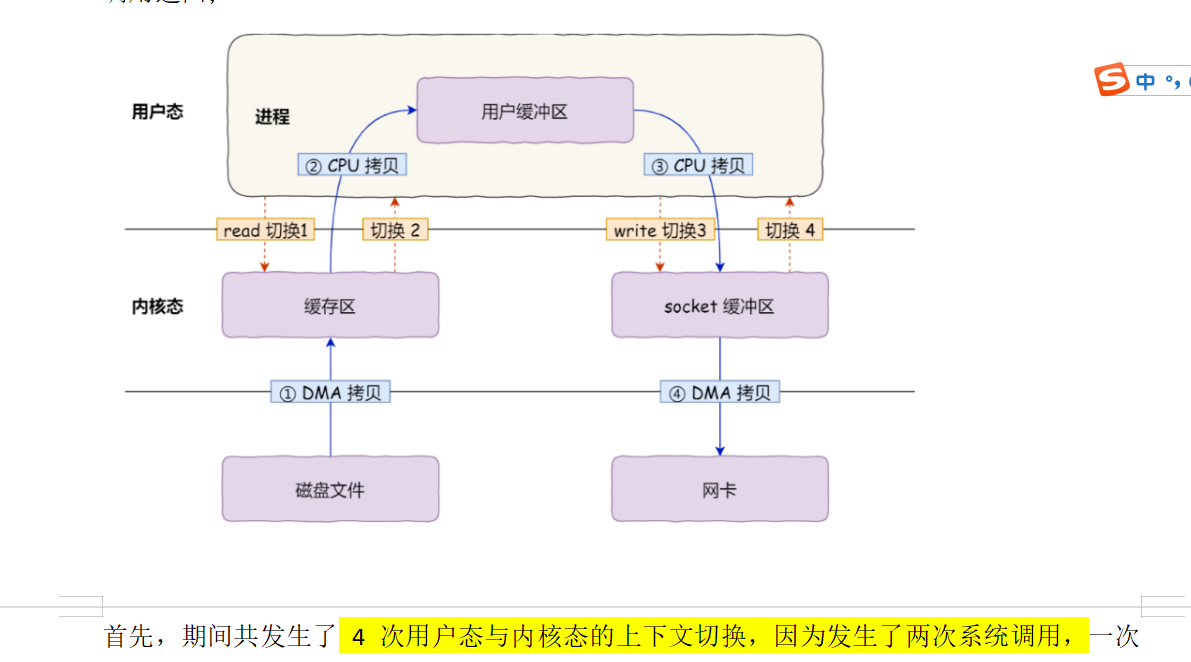
从网络到用户经历四次内核到用户态的切换。两次系统的调用,开销特别大。
因此用户的缓冲区是没有必要存在的。
mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间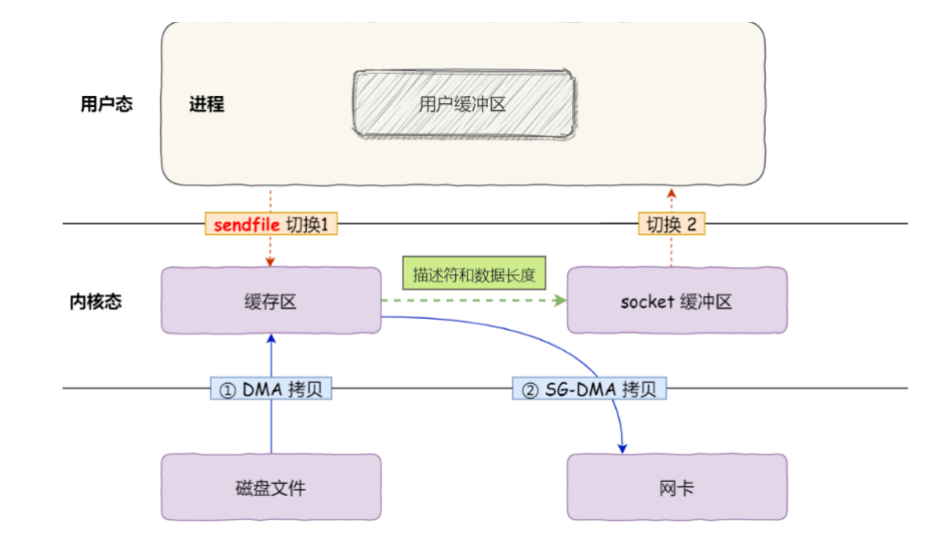
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据所以是零拷贝,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。少了一两次内核到用户态的复制。
批量消息
生产者进行消息发送时可以一次发送多条消息,这可以大大提升Producer的发送效率。不过需要注意以下几点:
批量发送的消息必须具有相同的Topic
批量发送的消息必须具有相同的刷盘策略
批量发送的消息不能是延时消息与事务消息
批量发送大小
默认情况下,一批发送的消息总大小不能超过4MB字节。如果想超出该值,有两种解决方案:
方案一:将批量消息进行拆分,拆分为若干不大于4M的消息集合分多次批量发送
方案二:在Producer端与Broker端修改属性
Producer端需要在发送之前设置Producer的maxMessageSize属性
Broker端需要修改其加载的配置文件中的maxMessageSize属性
存在的问题
消费者能力低,并且可能一个失败,一批失败,
没有像kafka做的那么好,比如延时或者满了就发,更灵活
Consumer的pullBatchSize属性与consumeMessageBatchMaxSize属性是否设置的越大越好?当然不是。
pullBatchSize值设置的越大,Consumer每拉取一次需要的时间就会越长,且在网络上传输出现问题的可能性就越高。若在拉取过程中若出现了问题,那么本批次所有消息都需要全部重新拉取。
consumeMessageBatchMaxSize值设置的越大,Consumer的消息并发消费能力越低,且这批被消费的消息具有相同的消费结果。因为consumeMessageBatchMaxSize指定的一批消息只会使用一个线程进行处理,且在处理过程中只要有一个消息处理异常,则这批消息需要全部重新再次消费处理。
高级特性
1 延时队列
2 消息查询
3 死信队列
可视化工具好处
1.在创建Topic时指定Queue的数量。有三种指定方式:
1)在代码中创建Producer时,可以指定其自动创建的Topic的Queue数量
2)在RocketMQ可视化控制台中手动创建Topic时指定Queue数量
3)使用mqadmin命令手动创建Topic时指定Queue数量
2.根据Messagekey查询消息
3.查看死信队列里的和重试的消息
%ready% 重试队列
死信队列消息(Dead-Letter Message,DLM)。
这个队列就是死信队列(Dead-Letter Queue,DLQ
死信队列就是一个特殊的Topic,名称为%DLQ%consumerGroup@consumerGroup ,即每个消费者组都有一个死信队列
重平衡
4.6.1 什么是 Rebalance
Rebalance即再均衡,指的是,将⼀个Topic下的多个Queue在同⼀个Consumer Group中的多个Consumer间进行重新分配的过程。
生产者broker重平衡,消费者重平衡
Rebalance 限制
由于⼀个队列最多分配给⼀个消费者,因此当某个消费者组下的消费者实例数量大于队列的数量时,多余的消费者实例将分配不到任何队列。
4.6.3 Rebalance 危害
Rebalance的在提升消费能力的同时,也带来一些问题:
消费暂停:在只有一个Consumer时,其负责消费所有队列;在新增了一个Consumer后会触发Rebalance的发生。此时原Consumer就需要暂停部分队列的消费,等到这些队列分配给新的Consumer后,这些暂停消费的队列才能继续被消费。
消费重复:Consumer 在消费新分配给自己的队列时,必须接着之前Consumer 提交的消费进度的offset继续消费。然而默认情况下,offset是异步提交的,这个异步性导致提交到Broker的offset与Consumer实际消费的消息并不一致。这个不一致的差值就是可能会重复消费的消息。
同步提交:consumer提交了其消费完毕的一批消息的offset给broker后,需要等待broker的成功 ACK。当收到ACK后,consumer才会继续获取并消费下一批消息。在等待ACK期间,consumer 是阻塞的。
异步提交:consumer提交了其消费完毕的一批消息的offset给broker后,不需要等待broker的成 功ACK。consumer可以直接获取并消费下一批消息。
对于一次性读取消息的数量,需要根据具体业务场景选择一个相对均衡的是很有必要的。因为 数量过大,系统性能提升了,但产生重复消费的消息数量可能会增加;数量过小,系统性能会下降,但被重复消费的消息数量可能会减少。
消费突刺:由于Rebalance可能导致重复消费,如果需要重复消费的消息过多,或者因为Rebalance暂停时间过长从而导致积压了部分消息。那么有可能会导致在Rebalance结束之后瞬间需要消费很多消息。
Reblance产生的原因
导致Rebalance产生的原因,无非就两个:消费者所订阅Topic的Queue数量发生变化,或消费者组中消费者的数量发生变化。
1)Queue数量发生变化的场景:
Broker扩容或缩容
Broker升级运维
Broker与NameServer间的网络异常
Queue扩容或缩容
2)消费者数量发生变化的场景:
Consumer Group扩容或缩容
Consumer升级运维
Consumer与NameServer间网络异常
RocketMq与kafka不同(总结)
4 批量发送做的不好,没有提供压缩机制
Kafka:
1.批量发送
buffer.memory
RecordAccumulator 缓冲区总大小,默认 32m。
batch.size 缓冲区每一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据 传输延迟增加。
Kafka比如设置延时5ms(默认为0ms)或者满了就发,更灵活
而如果批量里那个出现问题就去在应答区单独重试,而不是整批重试
5 支持压缩机制,
生产端压缩,消费者解压缩
消息压缩(默认不压缩)
在对大数据处理上,瓶颈往往体现在网络上而不是CPU(压缩和解压会耗掉部分CPU资源)。
RocketMq没有封装好的方法去压缩消息
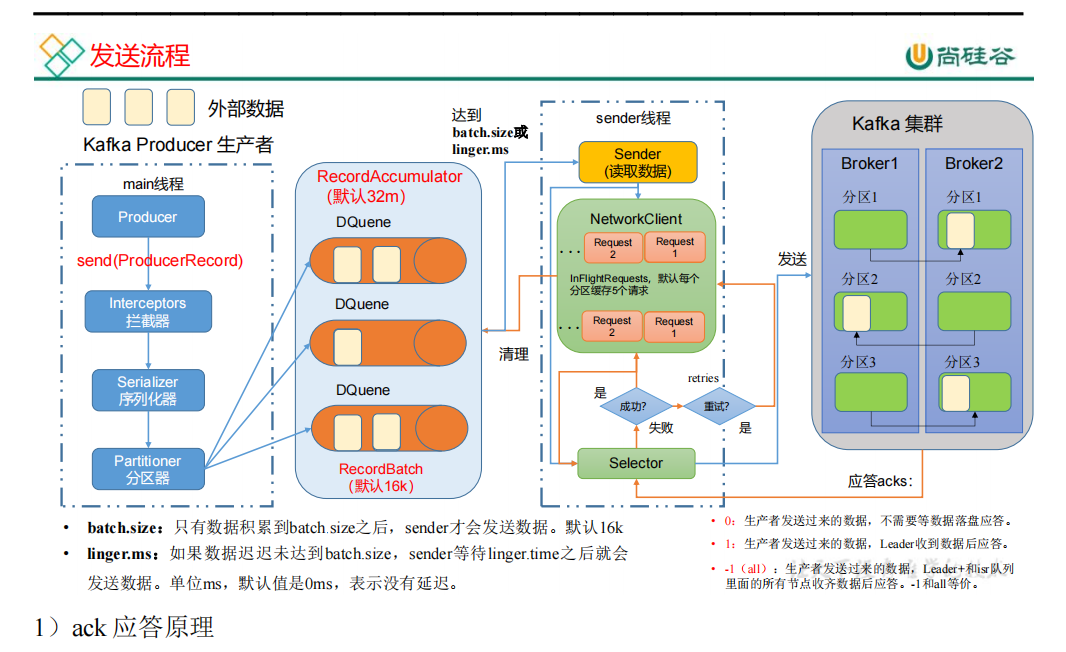
RocketMq(kafka快)
没有默认批量机制
可以批量发送大小
默认情况下,一批发送的消息总大小不能超过4MB字节。如果想超出该值,有两种解决方案:拆分成小个4MB,不可以设置4MB大小,没有kafka灵活
问题:若出现了问题,那么本批次所有消息都需要全部重新拉取。
2.RocketMq没有封装好的API去压缩消息
6 nameServer注册中心与zookeeper区别
nameServer(全局无序)
优点: NameServer 集群搭建简单,扩容简单。
缺点:对于 Broker ,必须明确指出所有 NameServer 地址。否则未指出的将不会去注册。也正因为如此, NameServer 并不能随便扩容。因为,若 Broker 不重新配置,新增的 NameServer 对于 Broker 来说是不可见的,其不会向这个 NameServer 进行注册。
Broker 节点为了证明自己是活着的,为了维护与 NameServer 间的长连接,会将最新的信息以 心跳包 的 方式上报给 NameServer ,每 30 秒发送一次心跳。
如何保证nameServer节点同步?
在Broker节点启动时,轮询 NameServer 列表,与每个 NameServer 节点建立长连接,发起注册 请求。在 NameServer 内部维护着⼀个 Broker 列表,用来动态存储 Broker 的信息。
NameServer路由信息有四个Map,
topic信息,brokerIp等信息,集群信息,心跳具体信息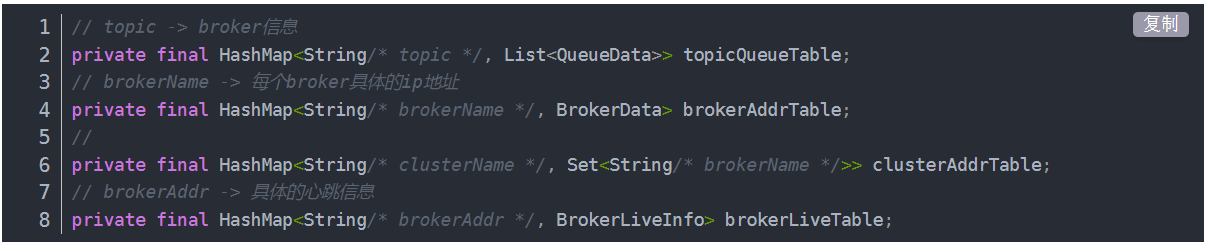
Zookeeper(有序)
注意,这是与其它像 zk 、 Eureka 、 Nacos 等注册中心不同的地方。
这种 NameServer 的无状态方式,有什么优缺点:
无状态:即 NameServer 集群中的各 个节点间是无差异的,各节点间相互不进行信息通讯。
Zookeeper各个节点之前都有监控,宕机就通知所有节点。可以动态增加broker和服务节点数量,有监控,会调整。不想nameServer还得重新改配置文件。
Zookeeper保证数据同步原理
1、leader 接受到消息请求后,将消息赋予给一个全局唯一的64位自增id,叫:zxid,通过zxid的代销比较即可以实现因果有序的这个特征
2、leader 为每个follower 准备了一个FIFO队列(通过TCP协议来实现,以实现了全局有序这个特点)将带有zxid的消息作为一个提案(proposal)分发给所有的follower
3、当follower接受到proposal,先把proposal写到磁盘,写入成功以后再向leader恢复一个ack
4、当leader 接受到合法数量(超过半数节点)的 ack,leader 就会向这些follower发送commit命令,同时会在本地执行该消息
5、当follower接受到消息的commit命令以后,就会提交该消息
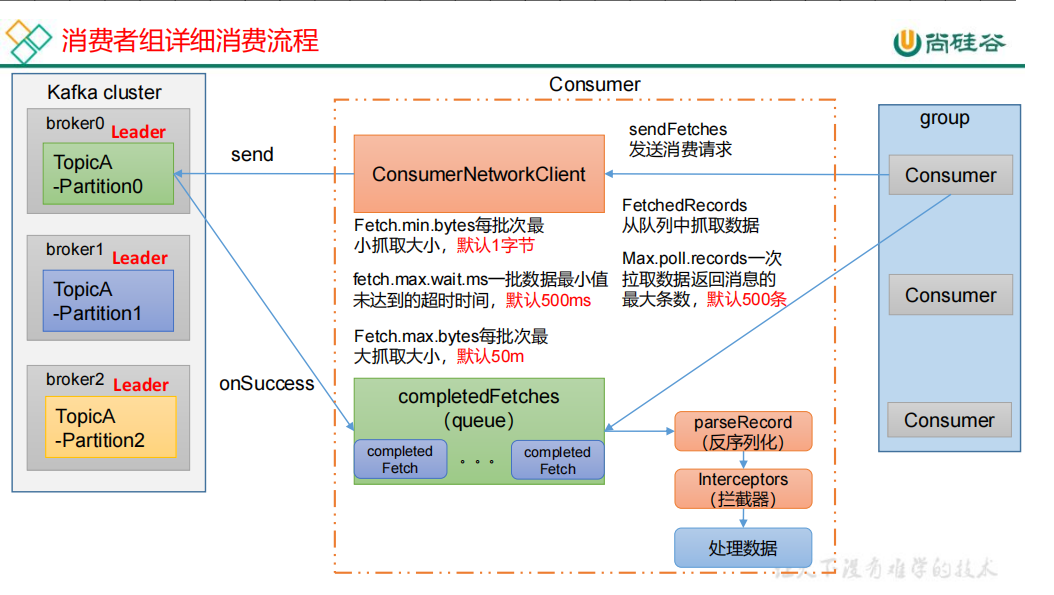
3.高级特性(kafka快)
1延时队列
2消息查询
1 按照MessageId查询消息
RocketMQ中的MessageId的长度总共有16字节,其中包含了消息存储主机地址(IP地址和端口),消息Commit Log offset。“按照MessageId查询消息”在RocketMQ中具体做法是:Client端从MessageId中解析出Broker的地址(IP地址和端口)和Commit Log的偏移地址后封装成一个RPC请求后通过Remoting通信层发送(业务请求码:VIEW_MESSAGE_BY_ID)。Broker端走的是QueryMessageProcessor,读取消息的过程用其中的 commitLog offset 和 size 去 commitLog 中找到真正的记录并解析成一个完整的消息返回。
2 按照Message Key查询消息
按照Message Key查询消息,主要是基于RocketMQ的IndexFile索引文件来实现的。RocketMQ的索引文件逻辑结构,类似JDK中HashMap的实现。
3死信队列
4.定时消息(特性)
4.日志文件存储(前边一样,后边kafka快)
MQ:
即无论当前Broker中存放着多少Topic的消息,这些消息都是被顺序写入到了mappedFile文件中的。也就是说,这些消息在Broker中存放时并没有被按照Topic进行分类存放。
所有队列都放在一个文件上。
写好些,读不好读。
Kafka:
但是kafka是一个分区一个文件,当topic过多,分区的总量也会增加,kafka中存在过多的文件,当对消息刷盘时,topic太多,分区太多,导致文件散落,有序写变成随机写。
读好读,写不好写。
5.事务不同
Kafka事务(保证的是自身消息的事务)
重点总结:保证的全分区幂等性,消息只发一次,并且保证发送多条分区的任务要发送成功都成功,失败都失败。
采取两阶段提交协议,借助broker内部事务协调者
保证精确一次发送(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。
Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务。
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
具有
事务ID加pid单区幂等id 形成全局唯一id(保证全局幂等)
即使客户端挂掉了,它重启后也能继续处理未完成的事务,因为有全局id
事务应用场景
最简单的需求是producer发的多条消息组成一个事务这些消息需要对consumer同时可见或者同时不可见 。
producer可能会给多个topic,多个partition发消息,这些消息也需要能放在一个事务里面,这就形成了一个典型的分布式事务。
kafka的应用场景经常是应用先消费一个topic,然后做处理再发到另一个topic,这个consume-transform-produce过程需要放到一个事务里面,比如在消息处理或者发送的过程中如果失败了,消费位点也不能提交
Kafka+本地消息表解决分布式事务(实现类似RocketMQ功能)
生产者本地业务逻辑执行完成之后,往数据库插入一条待发送的数据(在一个事务内,要么全部成功,要么全部失败)
然后从数据库去取这条待发送的数据,发送到kafka,状态更新为已发送(一个事务)。
消费者从kafka取出消息之后,将消息数据库数据更新为待消费(在一个事务内,要么全部成功,要么全部失败)
然后从数据库去取这条待消费的数据,进行消费端的业务处理,处理完成之后,状态更新为已消费(一个事务)。
定时任务扫描数据库的待发送数据,如果有,则代表有生产者本地执行成功,
但是发送到kafka失败的情况,那就重新发送。
定时任务扫描数据库的待消费数据,如果有,则代表有消费者消息取到了,
但是执行本地逻辑没有成功,那就重新执行消费逻辑。
三、优缺点
优点:
事务吞吐量大. 因为不需要等待其他数据源响应.
容错性好. A服务在发布事件的时候, B服务甚至可以不在线。
缺点:
1、容易出现较多的中间状态,保证不了实时性。
比如生产者已经发送数据了,但是消费者才执行到第一步
(拉取消息,留证据到本地数据库消息表),这个时候用户登录之后,
可能就看不到消费后的数据。在实时性要求高的业务不太适用。
2、与具体业务场景绑定,偶尔性强,不可以共用。
四、适用场景:
1、实时性要求不高,只要满足最终一致性的情况
2、生产者的逻辑是否成功,不依赖于消费者的逻辑执行是否成功的情况,
比如:
下订单和出库,这就是典型的生产者的逻辑要依赖于消费者的逻辑
是否执行成功。
因为下订单,如果库存不够,那么订单也是不能成功的。
参考博客: (91条消息) kafka如何实现分布式 - CSDN
RocketMq事务(外部事务)
半事务消息
本地事务状态
消息回查(防止确认ack因网络堵塞而导致系统停止)

整体流程
Producer执行本地事务;
Step4:本地事务完毕,根据事务的状态,Producer向Broker发送二次确认消息,确认该Half Message的Commit或者Rollback状态。Broker收到二次确认消息后,对于Commit状态,则直接发送到Consumer端执行消费逻辑,而对于Rollback则直接标记为失败,一段时间后清除,并不会发给Consumer。正常情况下,到此分布式事务已经完成,剩下要处理的就是超时问题,即一段时间后Broker仍没有收到Producer的二次确认消息;
Step5:针对超时状态,Broker主动向Producer发起消息回查;
Step6:Producer处理回查消息,返回对应的本地事务的执行结果;
Step7:Broker针对回查消息的结果,执行Commit或Rollback操作,同Step4。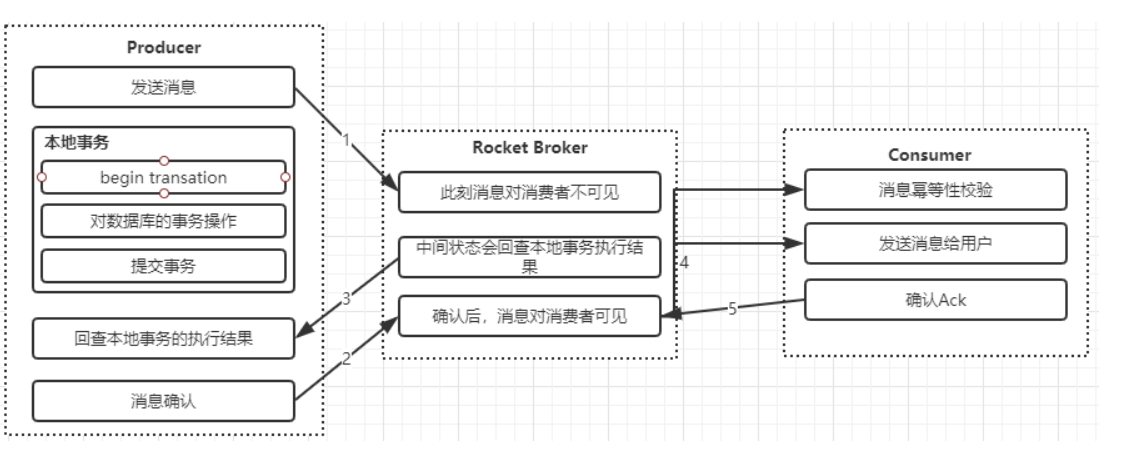
7 主从复制不同(也差不多)
MQ:
复制策略
复制策略是Broker的Master与Slave间的数据同步方式。
分为同步复制与异步复制:
同步复制:消息写入master后,master会等待slave同步数据成功后才向producer返回成功ACK
异步复制:消息写入master后,master立即向producer返回成功ACK,无需等待slave同步数据成功
异步复制策略会降低系统的写入延迟,RT变小,提高了系统的吞吐量
Kakfa
副本机制保障高可用和一致性。Ack机制 = -1
所有主副本都同步完ack,可同步可异步。
切换时间短,直接选取最近的副本。
Zookeeper 中ISR活着的,AR第一个。
7.有序性保证不一样
Kafka通过幂等性可保证有序(批量发送的缺点)
具有
分区策略选择key。保证一个分区。或者同一个指定区号。
MQ:
队列选择器传参
我们可使用Hash取模法,让同一个订单发送到同一个队列中,再使用同步发送,只有同个订单的创建消息发送成功,再发送支付消息。这样,我们保证了发送有序。
RocketMQ的topic内的队列机制,可以保证存储满足FIFO(First Input First Output 简单说就是指先进先出),剩下的只需要消费者顺序消费即可。
RocketMQ仅保证顺序发送,顺序消费由消费者业务保证!!!
这里很好理解,一个订单你发送的时候放到一个队列里面去,你同一个的订单号Hash一下是不是还是一样的结果,那肯定是一个消费者消费,那顺序是不是就保证了?
8.重平衡(差不多)
MQ重平衡
生产者broker重平衡,消费者重平衡
Rebalance 限制
由于⼀个队列最多分配给⼀个消费者,因此当某个消费者组下的消费者实例数量大于队列的数量时,多余的消费者实例将分配不到任何队列。
4.6.3 Rebalance 危害
Rebalance的在提升消费能力的同时,也带来一些问题:
消费暂停:在只有一个Consumer时,其负责消费所有队列;在新增了一个Consumer后会触发Rebalance的发生。此时原Consumer就需要暂停部分队列的消费,等到这些队列分配给新的Consumer后,这些暂停消费的队列才能继续被消费。
消费重复:Consumer 在消费新分配给自己的队列时,必须接着之前Consumer 提交的消费进度的offset继续消费。然而默认情况下,offset是异步提交的,这个异步性导致提交到Broker的offset与Consumer实际消费的消息并不一致。这个不一致的差值就是可能会重复消费的消息。
同步提交:consumer提交了其消费完毕的一批消息的offset给broker后,需要等待broker的成功 ACK。当收到ACK后,consumer才会继续获取并消费下一批消息。在等待ACK期间,consumer 是阻塞的。
异步提交:consumer提交了其消费完毕的一批消息的offset给broker后,不需要等待broker的成 功ACK。consumer可以直接获取并消费下一批消息。
对于一次性读取消息的数量,需要根据具体业务场景选择一个相对均衡的是很有必要的。因为 数量过大,系统性能提升了,但产生重复消费的消息数量可能会增加;数量过小,系统性能会 下降,但被重复消费的消息数量可能会减少。
消费突刺:由于Rebalance可能导致重复消费,如果需要重复消费的消息过多,或者因为Rebalance暂停时间过长从而导致积压了部分消息。那么有可能会导致在Rebalance结束之后瞬间需要消费很多消息。
Kafka重平衡
条件





检测broker中主副本区的个数,当新broker宕机恢复后没有主副本区,导致压力过大,重平衡。10%不合理。设置更大。搭配分区策略。和再平衡策略一样,
Round Robin(针对所有topic排序(性能低,但是不容易倾斜)),Range(针对一个分区(性能高,但是容易倾斜前几个))和Sticky(性能中等),默认使用的是Range为性能
8 消息过滤不同
Mq:
1.bysql方法传参

9 tag匹配
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer(“CID_EXAMPLE”);
consumer.subscribe(“TOPIC”, “TAGA || TAGB || TAGC”);
3.拦截器
Kafka:
只能拦截器里边配
10 重试机制不同(kafka慢)
Kafka:
Mq:
生产端,
消息去重
同步默认去重试两次,异步只重试一次。也可设置重试次数为0,保证效率
消费端。
重试十六次
1,5,10,。。。2小时最后
一般设置成这样的代码这里的代码意思很明显: 主动抛出一个异常,然后如果超过3次,
不行放在死信队列去人工修改,这种有bug。其他无bug
11 刷盘不同(RocketMq慢)
Kafka没有同步刷盘
MQ有同步:默认异步

若有收获,就点个赞吧
0 人点赞
