大家都是如何刷 LeetCode 的?
lz在加拿大。
先贴一个自己的刷题的进度吧: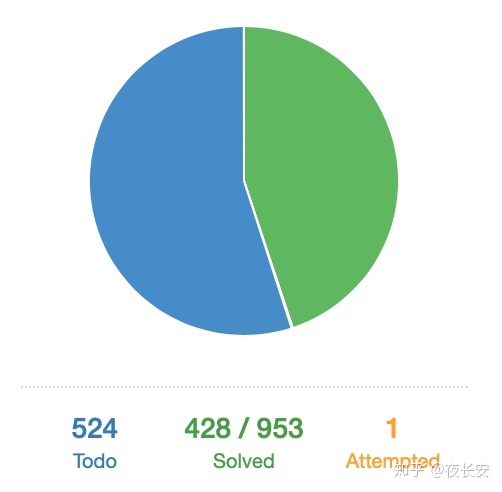
到目前为止,一共刷了428题。
通过刷题,拿了很多公司(IBM, Google, Amazon, Microsoft, Zenefits, Splunk)的面试以及offer。这428题不是简单的刷一遍就过去的,而是反复练习,直到代码最优,解法最优(有时候甚至觉得自己的代码精简到一个符号都无法减少的地步)。所以有时候面试官问问题,问题还没说完,我就知道应该如何表述自己的心路历程,然后慢慢地给出最优解。
而这一切的关键就在于:做笔记!
下面是我的笔记截图:
对于遇到的每个题目,事后我都做上标记:普通题目,难题、好题。此外,每个题目都分为以下几个步骤做好详细的笔记:
1. 原题目
2. 自己的第一遍解法
3. 网上好的解法
4. 自己可以改进的地方
5. 进一步精简优化自己的代码直至代码简无可简(这是非常关键的一步,到达这一步,才会发现获得能力的提升远远要超过简单地把题目解出来)
6. 获得的思考(或者学习到的地方,可以是算法、数据结构或者Java的特性—例如Stream等等)
每一个题目都经过至少一遍这样的迭代。这样几遍下来,我对于每个题目都有了更加深刻的理解,大部分的题目我都有自信能够写出最优解甚至代码都是最优化的(至少比论坛回复里面的最高票答案还要精简)。
举个例子,Two Sum问题。
我最早的解法是暴力搜索。当时的代码(C++)是这样的:
class Solution {
public:
vector
// Start typing your C/C++ solution below
// DO NOT write int main() function
vector
if (numbers.empty() || numbers.size() == 1)
return index;
for (int i = 0; i < numbers.size()-1; ++i) {
// j should start from i+1
for (int j = i+1; j < numbers.size(); ++j) {
if (numbers[i] + numbers[j] == target) {
index.clear();
index.push_back(i+1);
index.push_back(j+1);
break;
}
}
}
return index;
}
}
这个解法不仅复杂度高,而且代码冗长繁琐。
后来看了网上高票答案的解法,知道了用hashmap来做,于是写出了优化的代码(Java):
public int[] twoSum(int[] nums, int target) {
Map
int[] result = {-1, -1};\u2028\u2028
for (int i = 0; i < nums.length; ++i) {\u2028
if (map.containsKey(target - nums[i])) {\u2028
result[0] = map.get(target - nums[i]);\u2028
result[1] = i;\u2028
break;\u2028
}\u2028\u2028
map.put(nums[i], i);\u2028
}\u2028\u2028
return result;\u2028
}
再后来,对代码进行了一些细节的简化:
public class Solution {
public int[] twoSum(int[] nums, int target) {
Map
for (int i = 0; i < nums.length; ++i) {
if (map.containsKey(target- nums[i])) {
return new int[]{map.get(target- nums[i]), i};
}
map.put(nums[i], i);
}
return int[]{-1, -1};
}
}
至此,代码几乎达到最精简状态。(中间有略去几次迭代)总之,不断地学习别人的代码,改进自己的代码,不断地锤炼自己的代码,直至算法最优化,代码最简洁!潜移默化中,不仅对题目解法有了更深刻的理解(什么是最优解),而且也知道如何用最简洁的代码实现这个最优解。
再举个极端的例子吧,179. Largest Number,这个题目我最后精简成的代码如下:
public String largestNumber(int[] nums) {\u2028
return Arrays.stream(nums)\u2028
.mapToObj(String::valueOf)\u2028
.sorted((s1, s2) -> (s2 + s1).compareTo(s1 + s2))\u2028
.reduce((s1, s2) -> s1.equals(“0”) ? s2 : s1 + s2).get();\u2028
}
我本人不是算法高手,算是勤能补拙类型。这样长期坚持下来,慢慢地感觉自己编程能力提升了很多。不仅面试的时候得心应手,而且在工作中提交code review的时候,往往有自信说自己的代码是简单,干净与优雅的。
编辑于 2018-12-19
更多回答
从第一题Two Sum开始,默默刷了一年多,算不上经验吧,就是我自己的一点碎碎念。没什么条理,想到哪儿写到哪儿。
刷题我见过两种流派,一种【兔系】,一种【龟系】。
【龟篇】
我自己是比较偏“龟系”的刷法【传送 >ciaoshen.com】。从一开始为了找工作,每天4,5题,到后来慢慢变成一种习惯,每天早上起来,喝两口咖啡先来一发。我个人比较信奉Peter Norvig的 “十年理论”。之前Dave Thomas提出的 ”Code Kata“ 也是类似的概念,核心理念就是 “刻意训练” 。现在刷leetcode就是我坚持的“刻意训练”的一部分。日常工作里调调参数,修修Bug,用用框架实际上达不到”刻意训练“的标准。像leetcode这样的OJ正好提供了这样一个”道场“不是很好吗。
我们有的时候过分注重了算法题的“算法意义”,而忽略了”工程意义“。题刷多了就知道,常用套路其实来来回回就那么几个。但明确了算法,能不能准确地实现,做到bug free又是另一回事。再进一步,数据结构用的合不合理,也会影响最终效率。代码写出来,别人好不好懂,又是另一个层面的要求。最后要参加面试,又必须在规定时间里完成,不但要写的快,代码还要干净,符合工程规范。
所以”龟系“刷法的精髓就是每个题目要做干净。不要满足于一种解法,各种解法都写一写。我现在accept了350+题,用了1000多种方法。平均每题2~3个Solution。基本每题都做到beats 90+%。
350+Problems / 1000+Solutions
最好不要满足于accept,要追求最高效率。做一题就要杀死一题。leetcode不是给了运行时间的分布吗,基本上每个波峰都代表了一种特定复杂度的算法,中间的起伏体现的就是具体实现细节的差距。每次都要向最前面的波峰努力啊>.<。追逐最前一个波峰的过程不但锻炼算法,还锻炼数据结构,锻炼对库函数的熟悉程度。经常比较不同数据结构不同库函数的效率,时间久了能产生一种直觉,以后一出手就是最优选择。(小贴士:点开竖直的分布条,是可以看到对应代码的,对学习高手的解法很有帮助。)
但“龟系”不是说在一道题上耗死。越是龟系越要注意时间上要掌握好分寸,能解出来最好,解不出来也不要倔强。我觉得比较好的一个平衡点差不多是“一个小时”。如果一个小时还是解决不了可以点开右边Related Topics链接看提示。还是不能解决就看讨论区。
现在一年多坚持下来,最大的收获不是知道了多少算法套路,而是代码硬能力上的进步。之前经常会卡在一些实现细节的地方,现在只要整体方向确定下来业务逻辑捋清楚,具体实现编码反而是最轻松的工作。这就是为什么大厂面试要考算法。功底好的工程师才有精力腾出来考虑工程,产品方面的问题。
【兔篇】
“兔系“更加符合”刷题“的说法,就是按标签刷,按公司刷。今天做binary tree就一下子做10,20题。很多人可能对这个做法有点抵触,觉得太功利,没有思考的过程。当初我也有这个偏见。但后来发现很多最后拿到FLAG offer的大神都这么干。而且过程之暴力令人发指。记得有个大神刷到第三遍,每天可以做80+题。拿到题根本不思考,直接在自带编辑框开始码,而且还基本做到bug free。
我也不知道他是不是在吹,但“兔系”的精髓就是要暴力,天马流星拳,大力出奇迹。有的人提倡”不要看答案“。这种观点我觉得是对的,像我自己就很少看答案。但作为兔系选手,讲求的就是要疯,不如一上来就看答案,就照着答案写。这个做法看起来不靠谱,其实它有内在的合理性:大部分算法都不是我们发明的。什么动态规划,二叉树,线段树,并查集,贪心算法,到后来所谓的不看答案自己做出来,其实都是在用固定套路。到最后你看那些acmer高手,看似思路很快,其实就是知道的套路比你多,而且不是多一点。所以既然明确了是为了找工作的目标,那就放下矜持,放下承见,拿到offer比什么都强,哪怕是以一种羊癫疯的姿势。
最后,刷题呢工具一定要用起来。比如我用Java刷,什么ant, gradle, junit, log4j, slf4j都用起来。可以省去很多搭环境,搭框架的时间,把精力都集中在解决算法上。leetcode最近出了一个Playground我就觉得很好呀,直接在网页上写代码省去了很多麻烦。但我也提个小意见,就是如果能更完整地支持vim就更好了。现阶段我还是不得不自己开编辑器。这里给大家安利一个一键生成”Solution/Test”框架的小工具**leetcode-helper**。
下载地址(最新v0.55):
一行命令ant generate,生成支持Junit和log4j/slf4j的 **Solution/Test/TestRunner** 骨架类,
一行命令生成Solution以及Junit单元测试骨架
一行命令ant compile test,实现编译以及JUnit单元测试。
一行命令编译,运行JUnit单元测试
而且附带了一个leetcode常用数据结构包com.ciaoshen.leetcode.util。 像常用的比如ListNode,TreeNode的基本实现都有了。
现在每天早上拿着我的煎饼果子和咖啡,一键生成骨架,开编辑器就坐下来写算法,然后一键测试,提交。然后该干嘛干嘛。leetcode真的成了我的一种生活方式。不求名,不求利,但求无愧于心,干一行爱一行。
为了找工作,16年开始使用leetcode刷题,有一些心得体会可以分享。
刷题前的背景:
- 本科EE。上过的相关课程:cpp,数据结构与算法,算法设计与分析。
刷题工具:
- 国际版 leetcode.com。国内版leetcode虽然题目一样,周赛一样,但是没有上线discuss板块,题目的官方参考solution也不如国际版及时。
- 我在网页编辑器里直接码,没有用IDE。这也许不是个好方法,有很多人推荐用IDE+框架(好处是有代码补全;拼写检查;debug也更方便也更高效,等等)。
- 网站 Reference - C++ Reference ,记不住STL数据结构用法时查阅。
- 纸和笔:想不明白的时候在纸上写写画画,帮助思考。
- 手机:倒计时功能提示时间,时间到了之后如果没有思路,或WA,或TLE,就到Discuss讨论区取经。
我的刷题经历大概有下面几个阶段:
第一阶段,16年夏天,刷题顺序是easy >> medium >> hard,题目范围是前300道。
- easy部分,熟悉了cpp的语法以及STL的用法(经常遇到记不住function名字的情况,我会查阅 Reference - C++ Reference 这个网站)。这部分题目基本能独立写出来。
- medium部分,重温了基础的数据结构和算法,重点总结了各种常见数据结构和算法。
- hard部分,很多题没有思路,需要看Discuss。
- 刷题节奏大概是easy阶段每天12道,medium阶段一天能做8道,hard阶段随缘2~4道。(早八点到下午六点,中间只有吃饭没别的活动了,晚上跟着ucb的cs61b学学java)每道题AC后,会检查运行时间。慢的话就去discuss上学习大神们的解法思路,然后自己写一遍提交。查看discuss的情况还包括:自己的代码写的很繁杂,逻辑不清晰,自己又理不顺时;题目的tag里提示有别的解法时;想了半小时以上没思路时。
- 这个刷题顺序的缺点是,难以发现同类题目的共性。后来我在第二阶段按照Tag又刷一遍。
第二阶段,17年春夏,按题目Tag(bfs, dfs, dp …)把做过的题再做一遍并总结,每个类别写了点笔记。这一遍总结了很多常用的算法snippet和套路,基本烂熟于心。对于每个Tag,也是按easy>>medium>>hard的顺序过的。这一阶段感受到水平显著提高:
- 思路和code变得更简洁:大部分题目代码量控制在50行以内。
- 能够bug free且快速地写出常用的代码块(比如union find,dfs/bfs几个变种, binary search, partition 等等)。总结的snippet和套路使我能够bug free的解决medium题目。
- 得益于上面一条,medium类型解题时间缩短。
- 能够选用更简单的数据结构,使得运行时间更快。
第三阶段,18年秋季开始至今,每周参与leetcode contest,保持手感。虽然水平差只能过三道题(hard题要么没思路要么TLE),但也乐在其中。赛后写篇笔记,分析一下遇到的问题。这阶段应该不能算是刷题了(我理解的刷题是短时间内做很多题)。不过一年contest做满的话也有200多道题了。
关于国际版和国内版leetcode目前的区别,截图说明:
1 没有上线社区讨论
2 题解更新不及时
查看全部 28 个回答
Measure
Measure

若有收获,就点个赞吧
0 人点赞
