200—-mysql第一天
RDBMS即关系数据库管理系统(Relational Database Management System)的特点:
- 1.数据以表格的形式出现
- 2.每行为各种记录名称
- 3.每列为记录名称所对应的数据域
- 4.许多的行和列组成一张表单
- 5.若干的表单组成database
MySql服务的启动,停止与卸载
启动mysql:net start mysql
停止mysql:net stop mysql
卸载mysql: sc delete mysql
修改root用户密码 打开命令行输入
mysqladmin -u root -p password新密码
执行后提示输入旧密码完成密码修改
mysql通过脚本来完成对数据库的操作,该脚本由一条或多条mysql语句(sql语句+扩展语句)组成
mysql函数用来实现数据库操作的一些高级功能,这些函数大致分为以下几类:字符串函数,数学函数,日期时间函数,搜索函数,加密函数,信息函数。
mysql有三大类数据类型:数字,日期/时间,字符串
数字类型:
整数:tinyint,smallint,mediumint,int,bigint
浮点数:float,double,real.decimal
日期和时间:
date,time,datetime,timestamp,year
字符串类型
字符串:char,varchar
文本:tinytext,text,mediumtext,longtext
二进制(可用来存储图片,音乐等): tinyblob,blob,mediumblob,longblob
详细说明在http://www.cnblogs.com/zbseoag/archive/2013/03/19/2970004.html
使用mysql数据库
登录mysql:
mysql -h 主机名 -u 用户名 -p 密码
mysql -h 127.0.0.0 -u root -p root
创建一个数据库:
create database 数据库 default charset set utf8 collate utf8_general_ci
查看数据库:
show databases
选择要操作的数据库:
mysql -D 数据库名 -u root -p root(没登录)
use 数据库名(登录)
创建数据库表:
create table 表名
查看表:
describe 表名
操作数据库
插入数据:
insert into 表名[(列名1,列名2,列名3········)]values(值1,值2,值3········)
查询数据:
select 列名称 from 表名称[查询条件]
按特定条件查询:
select 列名称 from 表名称 where 条件;
更新数据:
update 表名称 set 列名称=新值 where 更新条件;
删除数据;
delete from 表名称 where 删除条件;
创建后的修改
添加列:
alter table 表名 add 列名 列数据类型【after 插入位置】;
修改列:<br />alter table 表名 change 列名称 列新名称 新数据类型;删除列:<br />alter table 表名 drop 列名称;重命名表:<br />alter table 表名 rename 新表名;删除表:<br />drop 表名;清空数据表数据:<br />truncate 表名;查询表结构:<br />desc 表名显示创建表的sql语句:<br />show create table 表名删除数据库:<br />drop database 数据库名;
复制表:
create table 表名 like 表名(复制表的结构);
insert into 表名(字段 1,字段2,字段3·····)
select (字段1,字段2,······)from 表名(复制表结构,前提是表中的数据结构是相同的)
数据库安装后默认的几个数据库https://blog.csdn.net/zhang123456456/article/details/53771076/
自定义用户
默认的root用户属于mysql的超级管理员的职能,
创建mysql用户:
create user ‘username’@‘host’identified by‘password’
//本地用户可用localhost,如果想让该用户可以从任意远程主机登录。可以使用通配符%
授予权限:
grant privileges on databasename.tablename to ‘username’@’host’;
//想授予所有权限privileges的值变成all
例子:
grant select,insert on test.user to ‘username’@’host’;
想要让被授权的用户给别的用户授权:
grant privileges on databasename.tablename to ‘username’@’host’ WITH GRANT OPTION;
设置与更改用户密码:
set password for ‘username’@’host’=password(‘newpassword’);
当前登录用户修改密码:
set password=password(“newpassword”);
撤销用户权限:
revoke privilege on databasename.tablename from ‘username’@’host’;
删除用户:
drop user ‘username’@’host’;
数据分区
区分的形式
1.水平分区:对表的行进行分区
2.垂直分区:对表的列进行分区
分区的类型
1.RANGE(范围分区)
2.LIST(预定义分区)
3.HASH(哈希分区)
4.KEY(键分区)
5.COMPOSITE(符复合分区)
事务操作
1.为什么使用事务
主要用于处理操作量大,复杂度高的数据
2.什么情况使用事务
mysql中只有使用了Innodb数据库引擎的数据库或表才支持事务
事务处理可以用来维护数据库的完整性,保证成批的sql语句要么全部执行,要么全部不执行
事务用来管理insert,update,delete语句
3.使用事务的条件
事务的原子性:一组事务,要么成功,要么撤回
事务的稳定性:有非法数据(外键约束之类),事务撤回
事务的隔离性:事务独立运行,一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
事务的可靠性:软硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改,可靠性和高速度不可兼得innodb_flush_log_at_trx_commit选项,决定什么时候把事务保存到日志里
4.事务控制语句
显示地开启一个事务:
begin或start transaction
提交事务:<br />commit或commit work(使已对数据库进行的所有修改称为永久性的)事务的回滚:<br />rollback或rollback(回滚会结束用户的事务,并撤销正在进行的所有未提交的修改)
savepoint允许在事务中创建一个保存点,一个事务中可以有多个savepoint
savepoint identifier
删除一个事务的保存点,当没有指定的保存点时,执行语句会抛出一个异常;
release savepoint identifier
把事务回滚到标记点<br />rollback to identifier
用来设置事物的隔离级别,InnoDB存储引擎提供事务的隔离级别有READUNCOMMITTED,READ COMMITTED,REPEATABLE READ和SERIALIZABLE
set transaction
x
5.实现方法
begin开始一个事务
rollback事务回滚
commit事务确认
<br /> <br />set autocommit=0禁止自动提交<br />set autocommit=1开启自动提交
函数操作
1.为什么使用函数:
函数可以更方便的实现我们常用的功能
减少代码量,效率更高
函数分为系统函数和自定义的函数
2.如何使用函数
创建函数:
create [AGGREGATE]function function_name(parameter_name type,[parameter_namet type,········])
returns{string|integer|real}[返回值类型]
return body[函数体]
删除函数:<br />drop function function_name
存储过程
1. 下图是mysql语句的操作流程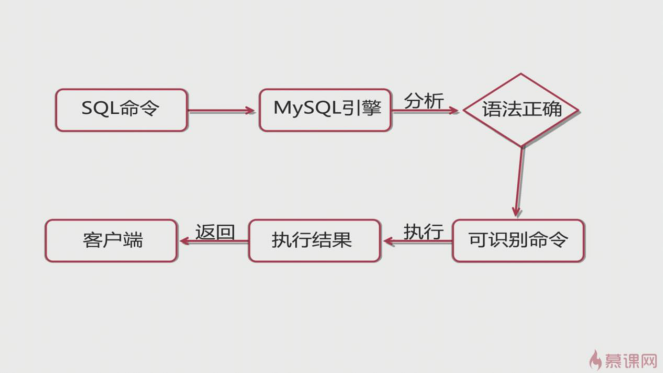
2.存储过程的好处
1.增强sql语句的功能和灵活性
2.实现较快的查询(把第一次查询的数据存储起来,再次调用的时候直接使用上一次存储的数据,避免重复的请求一个操作)
3.较少网络流量
3.使用存储过程
1.创建存储过程
create procedure sp_name([[in|out|inout]参数名 数据类型······])
begin
执行的sql语句
end
in 输入参数
表示该参数的值必须在调用存储过程是指定,在存储过程中修改该参数的值不能被返回,为默认值
out输出参数
该值可在存储过程内部被改变,并可返回
inout输入输出参数
调用时指定,并且可被改变和返回
参数名和SQL语句中的字段名不能相同
示例
2.删除存储过程
drop procedure sp_name
不能在一个存储过程中删除另一个存储过程。只能调用另一个存储过程
3.使用存储过程<br /> <br />call sp_name([param])//带参数<br />call sp_name[(param)]//不带参数4. 查询存储过程<br /> <br />show procedure status<br />show create prodedure sp_name
触发器操作
1.什么是触发器
当我执行一个事件时,同时也去执行另外一个事件,
2.触发器语法
create trigger <触发器名称> —最多64字节
{before|after}—触发器有执行时间设置,可以设置为事件发生前或后
{insert|update|delete}—可以设定触发的事件,
on <表名称>
for each row—触发器的执行间隔
<触发器sql语句>—触发器包含所要触发的sql语句,
视图操作
1.什么是视图
视图是一个虚拟表,表中是无数据的,其内容由查询定义,同真实的表一样,视图包含一系列带有名称的列和行数据,但是视图并不在数据库中以存储的数据值集形式存在,行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成,视图的数据来自于基表。
2.为什么使用视图
1.安全性
2.视图能简化用户操作
3.视图对重构数据库提供了一定程度的逻辑独立性,
3.使用视图
创建视图:
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW [db_name.]view_name [(column_list)] AS select_statement [WITH [CASCADED | LOCAL] CHECK OPTION]
删除视图
drop view if exists query_view;
使用视图
select * from query_view;
查询视图结构
describe query_view;
显示视图状态
show table status like ‘query_view’;

若有收获,就点个赞吧
0 人点赞
