文档到分片的路由算法
shard = hash(routing) % number_of_primary_shards
routing:是一个可变值,默认值文档的_id,也可以设置成自定义的值,routing通过
hash生成一个数字
number_of_primary_shards:主分片的数量
文档的操作流程
文档的新建、索引和删除请求都是写操作,必须在主分片上面完成之后才能被复制到相关的副本分片。
1、节点向其中一个节点发送新建、索引或者删除请求。
2、根据文档的_id确定文档属于哪个分片,请求转发到对应节点
3、在节点主分片上执行请求。一旦成功,请求转发到副本所在的节点
返回成功给客户端。
影响文档的操作流程的参数:
1、consistency
one:主分片写入即可
all:主分片和所有副本分片
quorum:主分片和部分副本分片。
数量为:Int( (primary + number_of_replicas) /2 ) + 1
2、timeout
如果没有足够的副本分片会发生什么? Elasticsearch会等待,希望更多的分片出现。默认情况下,它最多等待1分钟。 如果你需要,你可以使用 timeout 参数 使它更早终止: 100 100毫秒,30s 是30秒。
查询一个文档的流程??
查询文档可以从主分片或者任意副本分片检索文档。
1、客户端向节点(路由节点)发送获取文档请求。
2、路由节点使用文档_id确定文档属于哪一个分片,
3、主分片节点将文档返回给路由节点,然后返回给客户端
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的。
修改文档
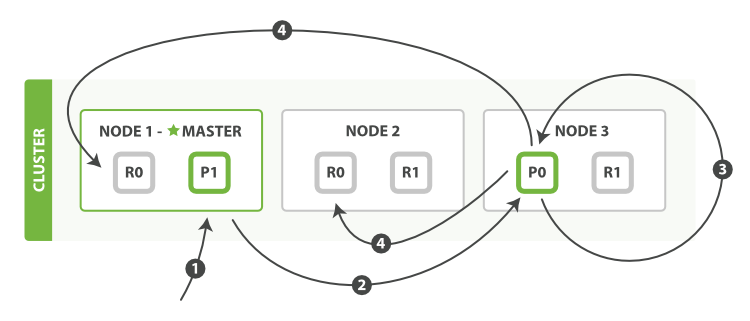
- 客户端向
Node 1发送更新请求。 - 它将请求转发到主分片所在的
Node 3。 Node 3从主分片检索文档,修改_source字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。- 如果
Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和Node 2上的副本分片,重新建立索引。 一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。

若有收获,就点个赞吧
0 人点赞
