数仓模型
数仓分为传统数仓和大数据数仓。
传统数仓是指以关系型数据库为主要构建数据的存储、分析,如Oracle、SQL Server、Db2等,以用友、金蝶这类财务软件为主。
大数据数仓是以集群为主,构建数据的存储、分析和展示。
下面是常用架构。
传统数仓
Inmon是一个自下而上的建模方式,根据数据去整理中央仓库,分布提供数据模型。
Kimball是一个自上而下的建模方式,根据数据先设计数据仓库,然后对外提供统计接口服务。
多使用Kettle、Informatica、存储过程等实现。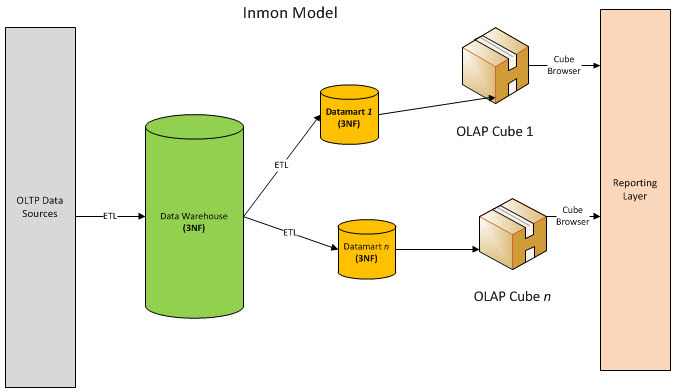

传统数仓的纠结,当数据数据量快速增长之后,由G->几百G->T->几百T->PB,传统数仓的弊端越发明显。
大数据数仓
Lamda
Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性,读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
Lambda架构分为三层,Batch Layer、Speed Layer 和Serving Layer三层。
Batch Layer是一个批处理系统,Speed Layer是一个流处理系统,Serving Layer是一个数据服务查询层。
基于HDFS文件系统构建。
Batch Layer:Spark、MR、Hive
Speed Layer:Spark Streaming、Flink、Storm、Nifi
Serving Layer:Druid,Presto、Kylin、Spark SQL等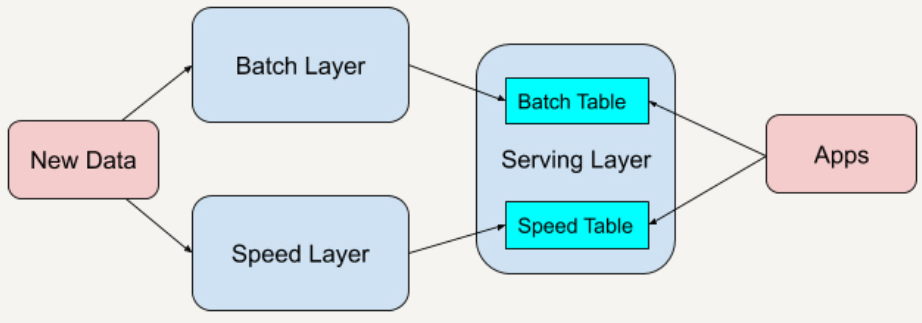
基于上述,数据来源:Flume、Sqoop、Kafka、Canal、Maxwell、file等。
Lambda的缺点是,批处理数据和实时数据的计算结果可能保持着不一致的现象,且维护复杂。
Kappa
在Lambda 的基础上进行了优化,删除了 Batch Layer 的架构,将数据通道以消息队列进行替代。因此对于Kappa架构来说,依旧以流处理为主,但是数据却在数据湖层面进行了存储,当需要进行离线分析或者再次计算的时候,则将数据湖的数据再次经过消息队列重播一次则可。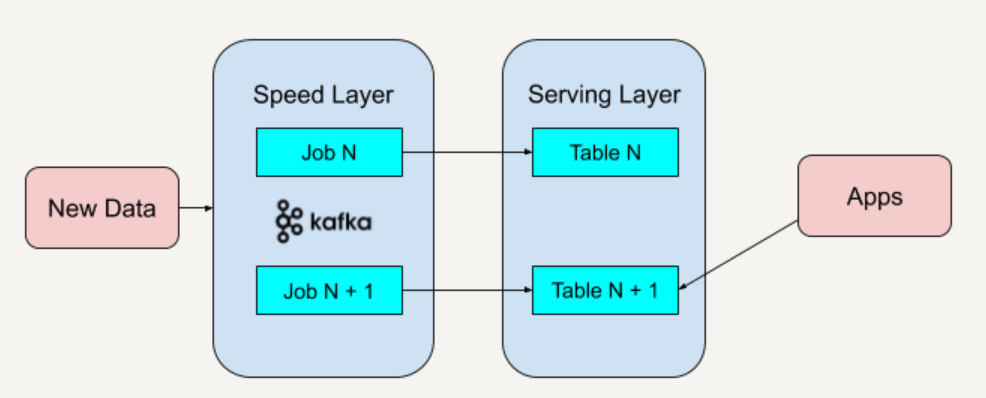
Kappa 架构的批处理和流处理都放在了速度层上,这导致了这种架构是使用同一套代码来处理算法逻辑的。所以 Kappa 架构并不适用于批处理和流处理代码逻辑不一致的场景。
Lambda和Kappa对比
| 优点 | 缺点 | |
|---|---|---|
| Lambda | 1、架构简单,易于理解 2、结合批处理和流处理流程的优点 |
1、流处理和批处理的逻辑一致,存在冗余 2、数据计算结果难以保持一致 |
| Kappa | 1、架构简单,只需要维护流处理模块 2、可以通过消息回放查看历史数据 |
1、对于中间件依赖严重,严重影响性能 2、数据可能造成丢失 |
传统数仓和大数据数仓对比
传统数仓和大数据数仓各有优势和应用场景。
| 传统数仓 | 大数据数仓 | |||
|---|---|---|---|---|
场 景 |
不 同 点 |
应用领域 |
1、数据结构严禁的领域,如银行、证券等 | 1、互联网领域 2、数据量大且需要留存分析 3、对数据实时性要求极高的领域,导航、外卖 |
| 数据响应 | 对数据的实时性要求较低 | 1、离线数仓对数据实时性要求较低,多是T+1模式 2、实时数仓对数据实时性要求高 |
||
| 数据来源 | 数据来源的数据格式单一,且数据量较小 | 数据来源多样、需要进行复杂计算且数据量大 | ||
| 联系 | 1、大数据仓库的报表层会使用传统数仓的技术 2、离线数仓的理论基础和传统数仓如出一辙 |
|||
技 术 |
不
同
点 | 技术复杂度 | 传统数仓技术相对简单,多以sql为主,开发语言为辅 | 大数据数仓生态复杂,以开发语言Java、Python、scala为主,sql为辅 |
| | | ETL工具 | 多以Kettle、Informatica等ETL工具为主 | 大数据生态,spark、nifi、flink等 |
| | | 存储 | 关系型数据库为主
1、数据量大了会进行分库分表
2、单表数据量不宜过大 | 技术多样且复杂,以HDFS为基础
1、Hive数据仓库,Hbase数据库,Hudi数据湖等
2、单表数据量不做过多限制 |
| | | 模型设计 | 1、表设计多依赖于范式设计
2、架构有Inmon和kimball架构
2、数据分层,ods,odw,odm等 | 1、为了节约资源长违反范式设计
2、lambda和kappa架构
3、离线仓库分层,ods,odw等 |
| | | SQL | 1、传统数仓有存储过程、函数、触发器、SQL
2、支持高级函数及用法 | 1、大数据数仓多以SQL为主
2、部分高级函数不支持,如connect by level |
| | | 优化 | 1、建索引
2、分库分表 | 1、优化复杂,不同框架有不同优化,如,Hive和Spark的优化则不同
2、为了优化有时需要引入其他框架,如hbase+phoenix |
| | 联系 | | 1、数据查询都是用SQL,大数据有 SQL on hadoop项目
2、都有etl工具,etl建模思路在离线数仓有极多相似之处
3、数据展示多用报表工具或自定义Java应用 | |
案例演示
dolphin调度任务
presto查询
Hive查询
superset可视化工具

若有收获,就点个赞吧
0 人点赞
