一、用画像是什么?what
定义:用户画像(User Persona)的概念最早由交互设计之父Alan Cooper提出,是建立在一系列属性数据之上的目标用户模型。一般是产品设计、运营人员从用户群体中抽象出来的典型用户,本质是一个用以描述用户需求的工具。注意:对真实用户深刻理解,及高精准相关数据的概括之上。
Personas are a concrete representation of target users.
真实用户的虚拟代表
——交互设计之父Alan Cooper
**
二、为什么需要用户画像?why
我认为最重要的点:
Persona的本质是一个用以沟通的工具,它帮助项目过程中的不同角色摆脱自己的思维模式,沉浸到目标用户角色中,站在用户的角度思考问题。当产品经理们、研究员们、设计师们、运营们、开发工程师们在项目过程中产生分歧时,各类角色能够借助Persona跳出眼前的焦灼,重新融入目标用户,不再讨论这个功能要不要保留,而是讨论李雷需不需要这个功能,韩梅梅会如何使用这个功能等等。
当然一个饱含丰富信息的Persona也可以让这些重要的用户特征信息直观的在项目相关成员间原汁原味的传递,帮助所有相关成员对目标用户形成一致的理解,建立共同创新的基础,节省反复沟通的成本。
用户画像是一种设计与沟通的工具,在团队里唤起大家对目标用户的同理心。**
在用户画像中,我们需要具有「目标」作为根本属性、人物背景信息、用户故事、体验目标、痛点和用户的使用场景。有了这些我们就会和熟悉的人联系起来,使这个用户画像丰富起来。
- 体验目标:用户在使用你的产品的时候最希望得到什么样的体验
- 痛点:用户现有的解决方式是用户比较痛苦的方式;
- 用户的使用场景:用户会在什么样的时间地点会用到这个产品。
- 用户故事:融合了很多属性,和用户的态度有关系;可以方便大家去记忆,用户故事里的属性做设计创新的时候就是稍次要属性。
每一个人的核心目标决定了他大多数行为的模式和根源。我们为这样一个人去设计的话,我们给他提供的服务都是提升他的需求。
按照用途,用户画像应该要包含什么?
作为设计与开发的团队,我们主要会关注用户是怎么做的,以及为什么这么做。所以我们会考虑行为模式、技术能力、使用目标、体检目标、面临挑战、使用场景等。
比如说我们做一个绘图软件,我们会关注他是专业设计师还是业余爱好者,他们的需求点是不同的。这样两种不同的技术能力就会影响你产品的走向。在设计与开发的时候我们就会多考虑用户怎么做,以及为什么这么做。
作为运营与市场,我们主要会考虑用户怎么想,价值观是什么?我是用一个环保为主题的广告更能打动他呢?我们更会考虑的用户属性。
作为战略团队,我们可能会考虑用户最终目标是什么呢?商业价值有多大呢?我们可能就要考虑人口规模、群体之间相互影响、人生目标等等。
1、精准营销:
这是运营最熟悉的玩法,在从粗放式到精细化运营过程中,将用户群体切割成更细的粒度,辅以短信、推送、邮件、活动等手段,驱以关怀、挽回、激励等策略。
2、用户分析
用户画像也是了解用户的必要补充。产品早期,产品经理们通过用户调研和访谈的形式了解用户。在产品用户量扩大后,调研的效用降低,这时候就可以辅以用户画像配合研究。方向包括新增的用户有什么特征,核心用户的属性是否变化等等。
3、数据应用
用户画像是很多数据产品的基础,诸如耳熟能详的推荐系统广告系统,广告基于一系列人口统计相关的标签,性别、年龄、学历、兴趣偏好、手机等等来进行投放的。
4、数据分析
用户画像可以理解为业务层面的数据仓库,各类标签是多维分析的天然要素。数据查询平台会和这些数据打通,最后辅助业务决策。
三、用户画像的主要内容?what
用户画像一般按业务属性划分多个类别模块。除了常见的人口统计,社会属性外,还有用户消费画像、用户行为画像,用户兴趣画像等。
人口属性和行为特征是大部分互联网公司做用户画像时会包含的:人口属性主要指用户的年龄、性别、所在的省份和城市、教育程度、婚姻情况、生育情况、工作所在的行业和职业等。行为特征主要包含活跃度、忠诚度等指标。
| 人口统计 | 社会属性 | 用户消费 | 用户行为 |
|---|---|---|---|
| 基本属性 | 家庭属性 | 消费属性 | 活跃属性 |
| 姓名 | 家庭ID组 | 首次消费时间 | 登陆次数 |
| 性别 | 家庭类型 | 最后一次消费时间 | 登陆时长 |
| 出生年月 | 家庭人数 | 消费频率 | 登陆深度 |
| 籍贯 | 家庭小孩标签 | 消费间隔次数 | |
| 婚姻 | 家庭老人标签 | 行为属性 | |
| 学历 | 家庭汽车标签 | 价值属性 | 点评次数 |
| 价值指数 | 点赞次数 | ||
| 公司 | 流失指数 | 收藏次数 | |
| 公司ID | 忠诚指数 | ||
| 工作地址 | 偏好属性 | ||
| 公司行业 | 消费周期 | 价格偏好 | |
| 公司职位 | 潜在用户标签 | 类目偏好 | |
| 收入 | 新客标签 | 特征偏好 | |
| 老客标签 | 下单时间偏好 | ||
| 终端设备 | VIP用户标签 | ||
| 手机设备 | 流失用户标签 | 风险 | |
| 手机类型 | 欺诈风险 | ||
| 退换货风险 | |||
| 黄牛风险 | |||
四、如何构建用户画像?how
第一步:理解用户
合理的、有效的Persona是建立在对目标用户/客户的充分理解基础之上的。
“他们对这件事的认知和态度是怎样的?”
“抛开我们的产品和服务,用户真正想要的是什么?”
“他们是如何完成这件事情的?”
“他们使用我们产品/服务的场景是怎样的?”
“……”
对用户从态度到行为,再到一些细节特征的立体数据的收集,对于建立一个生动的、具有参考价值的Persona是至关重要的。收集数据的方法有很多,深度访谈、影随、文化探寻等等,就不一一赘述了。方法只是手段,没有所谓的标准方法,达到收集数据、理解用户的目的即可。重要的是数据目标的确立,每个人身上有太多的属性、太多的特征、太多的故事,有些信息收集过来有可能反而会成为噪音。因此,在收集数据前,时应该先明确自己的研究范围,针对性的挖掘真实用户/客户身上的相关信息。
第二步:寻求关键变量
所谓关键变量是指导致用户对目标产品/服务的相关行为产生差异的核心因素。每个用户身上有很多属性、性别、年龄、家庭状态、文化水平、性格特征、互联网行为偏好、消费观、理财观、个人爱好等等,我们需要从这些众多特征中识别,哪些才是导致用户对我们目标产品/服务的态度及使用行为产生差异的主要原因。
例如,当我们寻找金融产品及服务的目标客群时,导致用户是理财还是消费,去线下办理还是用手机银行等不同类型金融相关行为差异的核心因素可能如下:
收入水平、消费观念、理财观念、互联网使用水平等。这些核心因素直接影响到用户需要什么样的金融服务,用户会在哪些渠道办理这些金融服务。而性格特征、文化水平等属性,虽然会对用户的某些行为产生一定影响,但在用户聚类的阶段可以暂时视为低信息含量的噪音处理。
确定关键变量后,我们将每个变量作为一个核心维度去分析收集到的用户数据,将用户相关的行为数据化作一些“信息值”分布在这个维度上。例如,若“互联网使用程度”、“人生阶段”及“经济条件”是用户对某项产品或服务的需求及态度产生差异的关键变量,我们可以将收集到的用户信息在这三个维度上做均匀排布(如下图所示),选取一些典型的用户特征作为这个维度上的“信息值”。
至此,我们便完成了用户聚类的第一步,即关键变量框架的搭建。

Step3:聚类
关键变量是帮助用户聚类的核心维度,有了关键变量后则可以通过将每个维度上的“信息值”串联,得到Persona的核心特征,所以接下来的工作就是“连连看”。
首先,回顾收集到的用户数据(将每个受访用户的行为标记在各个维度以记录该行为特征出现的概率,用以推算该信息值覆盖的用户数量)。
1. 尽量合理覆盖每个变量两端的“极端信息值”。
Persona的制作过程是在众多的目标用户群中寻找有代表性的典型用户,所谓典型用户则是在其拥有的核心特征中,某一个或多个特征是在所有用户群中具有极端需求的,我们覆盖了这部分用户的极端需求,从设计的角度上来说就找到了需求的边缘及设计的边缘,覆盖到了极端的边缘需求,理论上来说不超过边缘范围的需求也可以被覆盖到。这里要注意到的是,很多研究员或者设计师在设计时往往能够注意到“高信息值”边缘,也就是偏向于专家用户的那一段,对于“低信息值”边缘,也就是极端小白用户端,则往往比较容易忽略,我们在制作persona的时候,还是需要全面的考虑到目标用户群的覆盖范围。
另外,这里需要特别提到“合理”二字。有些人可能一味的追求连接所有变量两端的极端值,以希望寻找最典型的目标用户。但当我们将连接起来的变量还原为一个生动的用户形象时,我们可能会觉得这类人在生活中很少见,甚至是奇葩,或者有些畸形。当然,如果你的目标用户就是奇葩用户,则要另当别论了。因此,合理的连接极端值,则非常重要,要保证我们连接出来的用户是真实存在的,最简单的方式就是回头去看看受访的用户中,是否有真实的人物原型可以匹配上。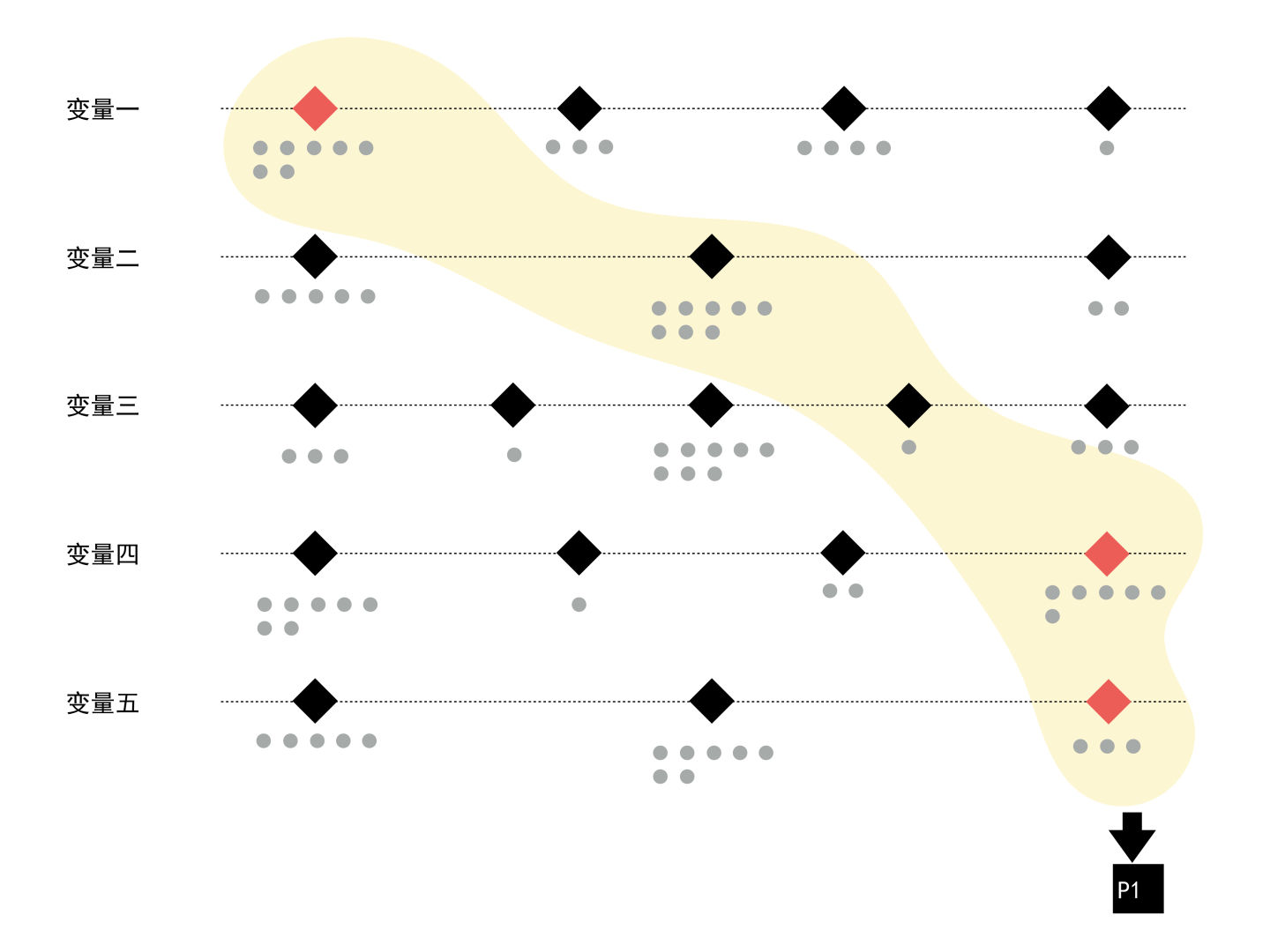
2. 尽量合理的连接用户行为集中的信息值。
所谓的典型用户,换个角度说也代表具有一定群众基础的用户,即相对来说基数较大的用户群。因此,我们在连接关键变量中的信息值时,也需要考虑该行为特征所属用户群的数量。这时,我们之前标注的受访用户出现频率则派上了用场。也就是我们只需要将行为分布密集的信息值连接起来,很大程度上就可以顺利的找到目标用户了。当然,这里同样要注意合理二字,以防我们连接出来的只是个架空人物,或理想用户,而现实生活中则不存在这类用户。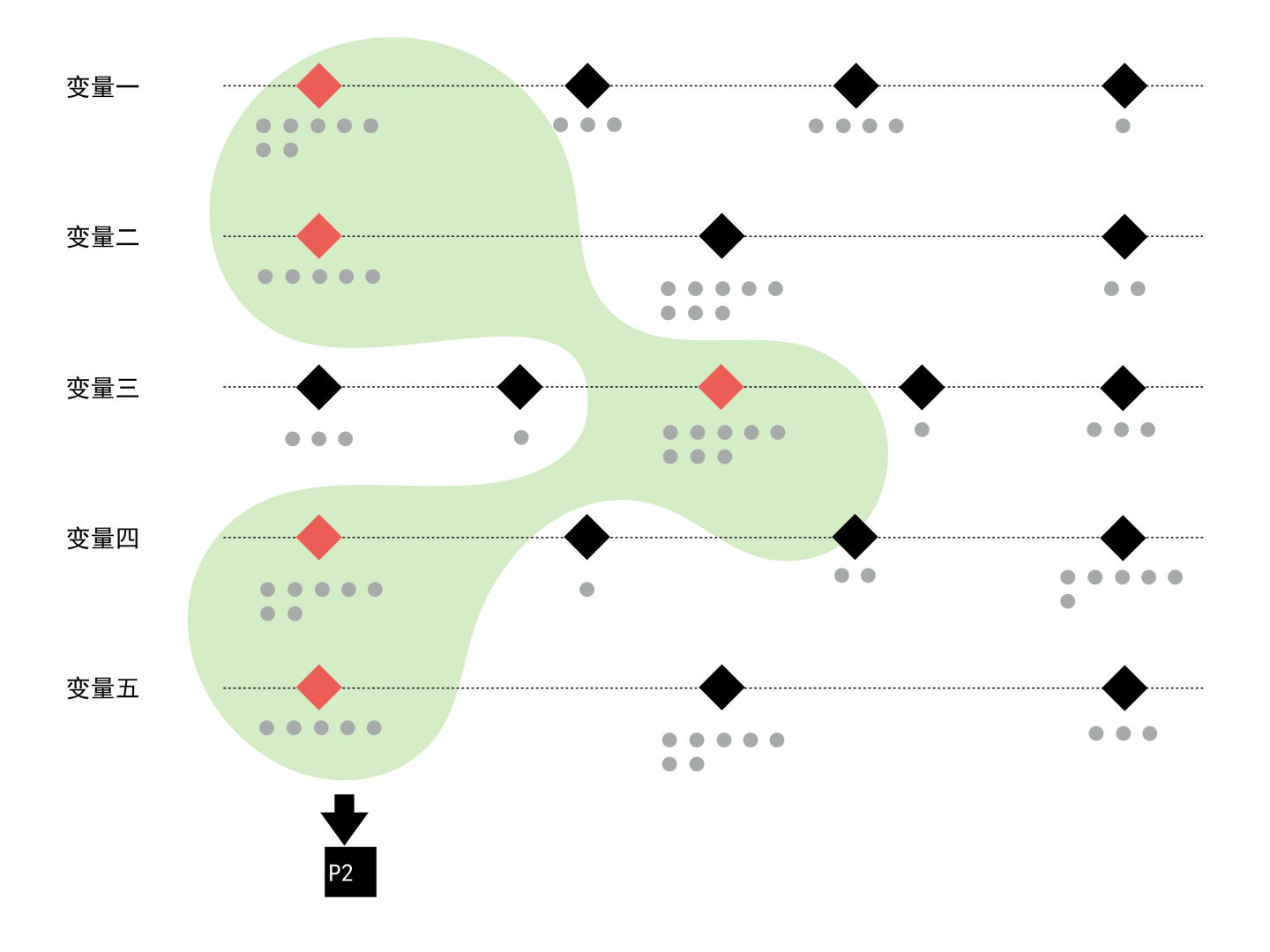
当然,如果在连接关键变量的信息值时可以两个原则兼顾,则我们制作出一个成功的persona的概率则会大大增加。
到这里,我们的用户聚类工作基本已经完成了,为了帮助大家理解,我们选取唐硕之前的一个项目作为案例说明。该项目是受某公司委托研究美食消费的用户行为,也就是研究吃货。
通过一系列的调研,我们收集到了丰富的吃货行为特征。通过分析,我们选取了“美食消费观”、“美食热衷度”、“美食主见度”及“美食社交倾向”作为影响用户美食消费行为的关键变量,并将关键信息值及用户行为特征数量分布进行了一一标注。
接下来就是见证奇迹的时刻!
通过按照以上两个原则的连接尝试,我们最终聚类出了三种典型的吃货。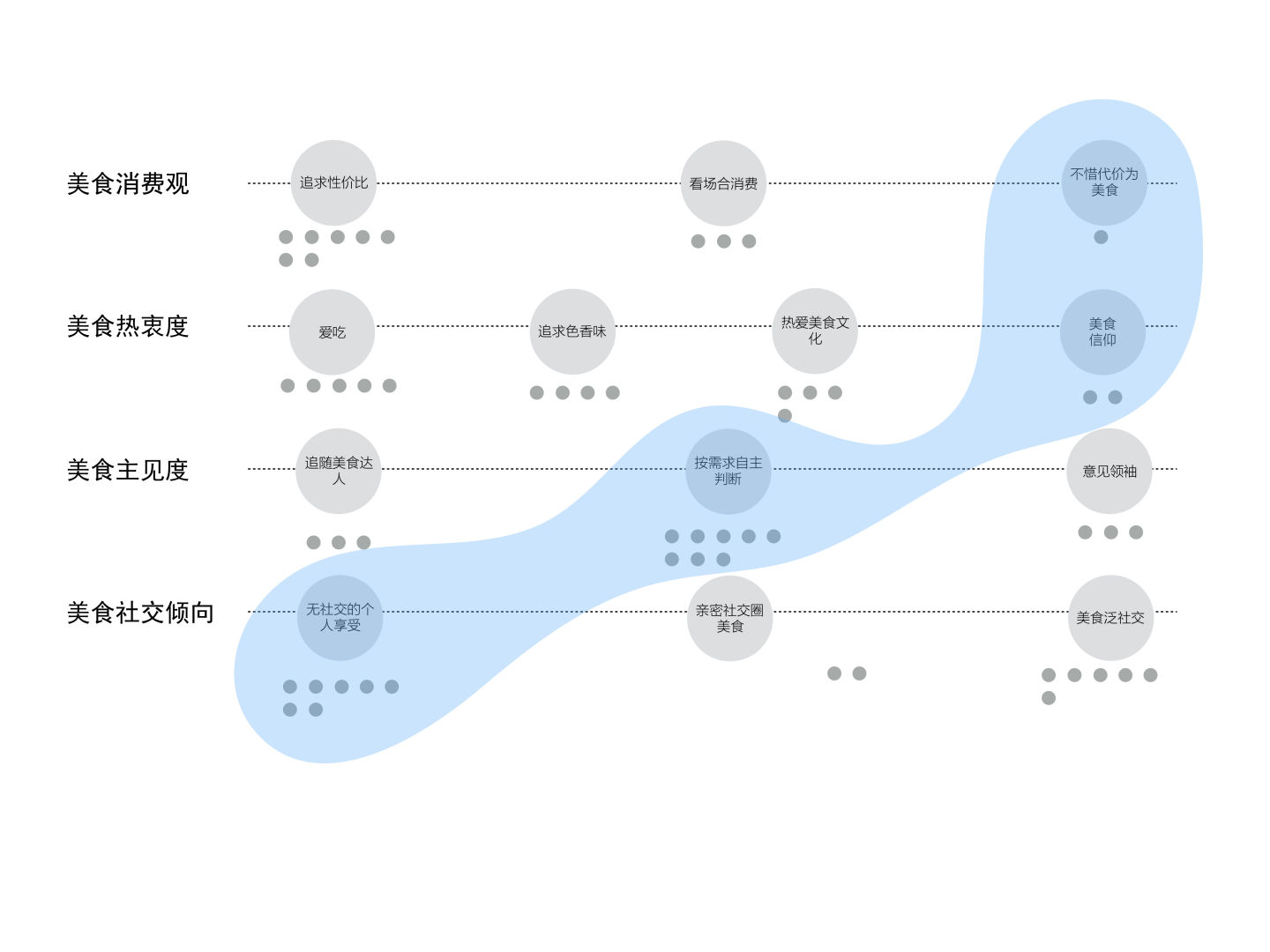
第一类人把“吃文化”当成他们了解世界的一个窗口,对食物抱有尊敬的心态,相信“you are what you eat”,把“吃”上升为人生信仰,愿意不惜代价去追寻美食。因此,也认为研究吃、享受吃及回味吃都是比较个人的事情,很少会与别人主动分享,但会自己花很多功夫去研究、探索甚至记录,并在这个过程中体会到深深的幸福感,我们把这类人叫做“美食信徒”。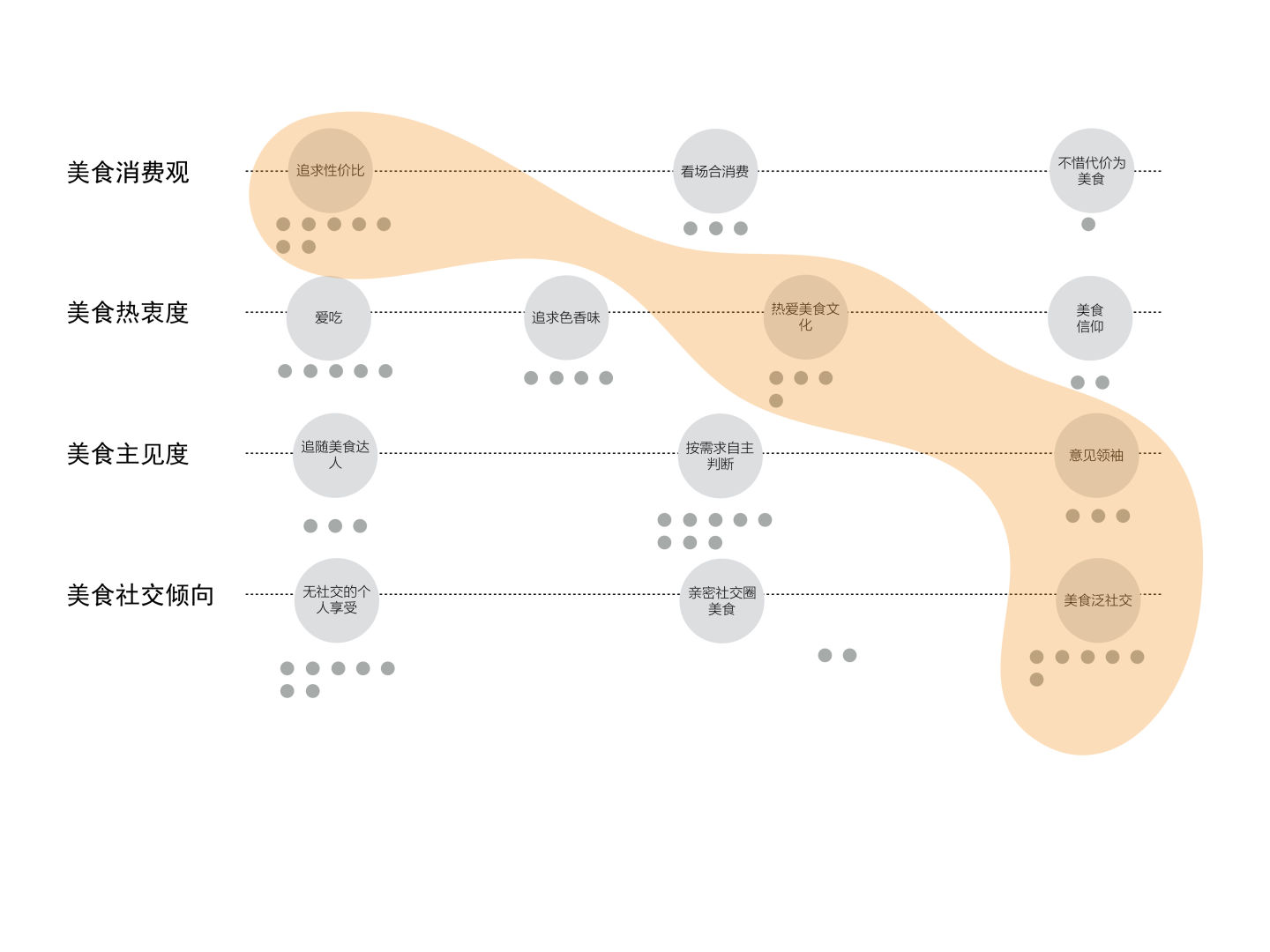
第二类人对“吃”的动力很多时候是来自分享时的成就感,他们往往是你身边最爱组局的“局长”,说起美食总是头头是道,对于哪里有打折,哪里有新餐厅这类的美食动态信息,找到他们就像打开了消息盒子。有时,他们不满足于身边的人对他们的崇拜,会在社交媒体上,甚至自媒体渠道上发表他们对美食的见解。凭借吃的本领,也可以成为一届网红,美食KOL。我们把这类人叫做“美食大V”。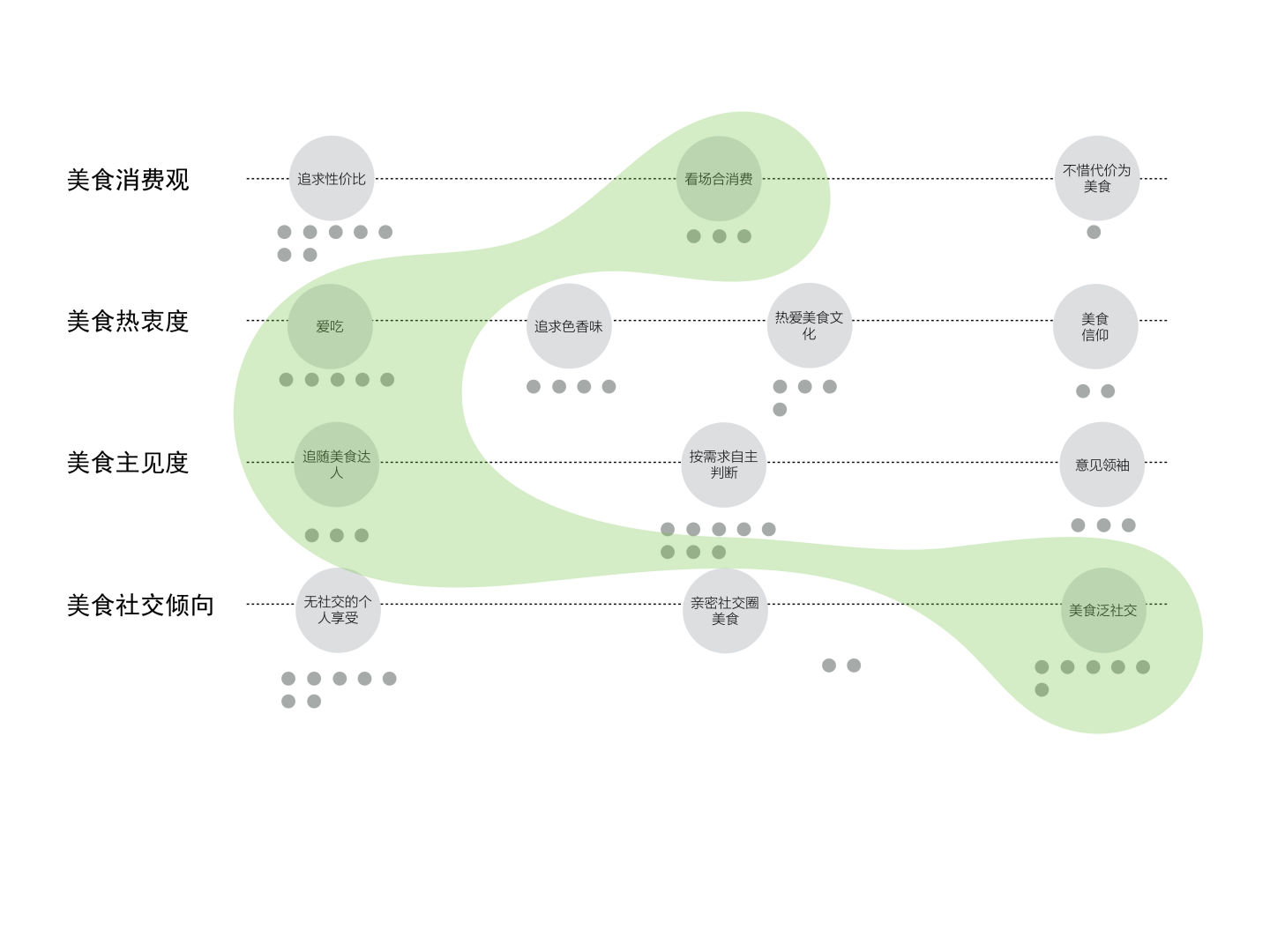
第三类人有着强烈的社交属性,但与第二类不同的是他们是美食的follower,自己并没有很多主见,不过没关系,他们身边聚集了一帮有主见的朋友。因此,每当他们燃起对美食的欲望,也就是他们呼朋唤友的时刻到了。很多时候,与其说美食对他们有巨大的吸引力,不如说和朋友们一起享受美食的时光更值得留恋,这类人就是我们的“美食社交族”。
这三类吃货各有特色,各有自己的需求偏好,也都分别代表着生活中相当一部分吃货的状态。当我们将这些persona与设计师、与产品经理进行沟通时,也得到了充分的共鸣,很容易有代入感,甚至让某些不能理解吃货们世界的设计师也对吃货们的生活产生了共鸣,激发了很多设计灵感。
Step4:丰富人物形象
接下来是要将聚类后的典型用户类型进行精细刻画,就像我们最开始说的,添加一些细节描述,让看的人更有画面感。拿上面案例中的美食社交族举例,在对美食社交族的日常生活中,我们会描述:“他们的手机日历中添加备注了各类朋友、亲戚们的生日、结婚纪念日等信息,似乎每一天对他们来说都充满了聚会的理由,他们时刻寻找着发起一次美食的契机。”这样的persona是不是生动了很多?
最后,我们需要将这些persona的信息制作成一个形象的人物画像,把这些关键信息紧凑而有序的呈现在一个版面上,以获取最佳的视觉传达的效果。
一般来说,我们会把最终的画像划分为几类信息模块:即分类信息、个人信息描述、互联网使用情况及与产品/服务相关的特征及需求描述。
这样,基本上一个完整的persona就可以惊艳亮相了,当然,在此之前,需要在视觉上稍作美化和调整,毕竟,这是一个看颜值的世界!
案例展示:
1、常用方法
Alen Cooper的“七步人物角色法”,Lene Nielsen的“十步人物角色法”等
用户访谈、焦点小组、文化探寻、包括问卷调查等定性、定量研究手段收集的真实用户数据之上的
2、主要步骤
获取和研究用户信息、细分用户群、建立和丰富用户画像。
| 方法 | 步骤 | 优点 | 缺点 |
|---|---|---|---|
| 定性用户画像 | 1、定性研究:访谈 | 省时省力、简单、需要专业人员少 | 缺少数据支持和验证 |
| 2、细分用户群 | |||
| 3、建立细分群体的用户画像 | |||
| 经定量验证的定性用户画像 | 1、定性研究:访谈 | 有一定的定量验证工作,需要少量专业人员 | 工作量较大,成本较高 |
| 2、细分用户群 | |||
| 3、定量验证细分群体 | |||
| 4、建立细分群体的用户画像 | |||
| 定量用户画像 | 1、定性研究 | 有充分的的佐证、更加科学、需要大量的专业人员 | 工作量较大、成本高 |
| 2、多个细分假说 | |||
| 3、通过定量收集细分数据 | |||
| 4、基于统计的聚类分析来细分用户 | |||
| 5、建立细分群体的用户画像 |
数据采集
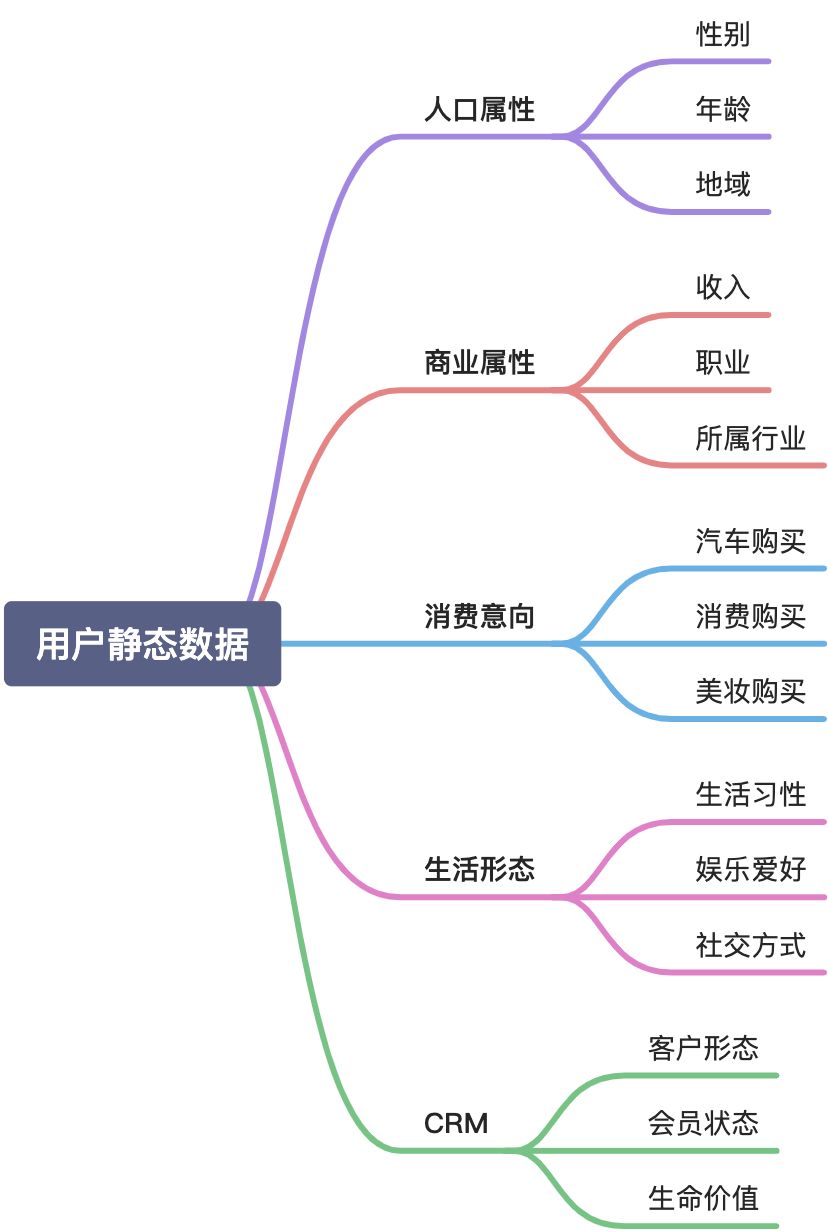
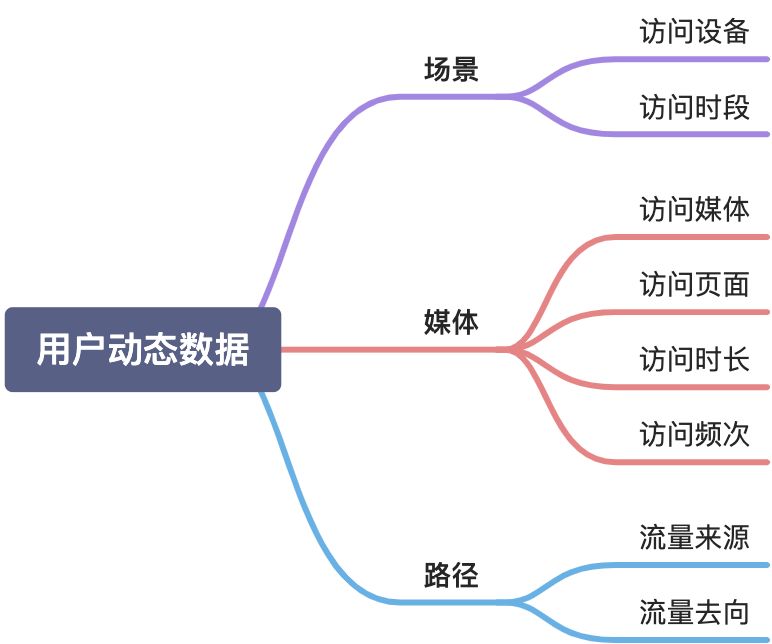
目标分析
用户画像的目标是通过分析用户行为,最终为每个用户打上标签,以及该标签的权重。标签,表征了内容,用户对该内容有兴趣、偏好、需求等等。权重,表征了指数,用户的兴趣、偏好指数,也可能表征用户的需求度,可以简单的理解为可信度,概率。
数据建模
一个事件模型包括:时间、地点、人物三个要素。每一次用户行为本质上是一次随机事件,可以详细描述为:什么用户,在什么时间,什么地点,做了什么事。
1、用户:关键在于对用户的标识,用户标识的目的是为了区分用户、单点定位。
2、时间:时间包括两个重要信息,时间戳和时间长度。时间戳,为了标识用户行为的时间点;时间长度,为了标识用户在某一页面的停留时间。
3、地点:用户接触点,Touch Point。对于每个用户接触点。潜在包含了两层信息:网址和内容。网址:每一个链接(页面/屏幕),即定位了一个互联网页面地址,或者某个产品的特定页面。可以是PC上某电商网站的页面,也可以是手机上的微博,微信等应用某个功能页面,某款产品应用的特定画面。如,长城红酒单品页,微信订阅号页面,某游戏的过关页。
4、内容:每个网址(页面/屏幕)中的内容。可以是单品的相关信息:类别、品牌、描述、属性、网站信息等等。如,红酒,长城,干红,对于每个互联网接触点,其中网址决定了权重;内容决定了标签。
5、事情:用户行为类型,对于电商有如下典型行为:浏览、添加购物车、搜索、评论、购买、点击赞、收藏 等等。
公式:用户标识+时间+行为类型+接触点(网址+内容),某用户因为在什么时间、地点、做了什么事。
五、注意事项
1、不要把典型用户当作用户画像
典型用户是虚构的,并不真实存在。而用户画像是把用户以标签的形式表现出来,每一个真实存在的用户都有对应的用户画像。
2、不要把用户画像简单理解成由用户标签构成
这也是 50% 以上的人都可能存在的错误认知,即把用户画像简单理解成由用户标签构成。用户标签是用来概括用户特征的,比如说姓名、性别、职业、收入、养猫、喜欢美剧等等。这些标签表面上看没有什么问题,但是实际上组成用户画像的标签要跟业务/产品结合。
举个夸张的例子,海底捞要做用户画像,最后列出来小明是一个大学生、高富帅、独生子、四川人,爱玩游戏、爱看动漫等用户标签。而事实上,对于海底捞而言,用户帅不帅、是否爱玩游戏真的没有关系。
其次,一个成功的Persona所包含的信息应该尽可能的包含体现用户核心特征的细节描述。价值观、核心需求等信息固然重要,但有时也难免过于抽象,而生动的细节描述则可以让人物形象更具画面感,更容易形成同理心。例如,当我们看到这样的描述:“Flora的粉色iPhone 6 Plus外包裹着一个Bling Bling镶满钻的时尚手机壳”,或者“Adam的“大白”后座摆放着一排布绒公仔和一个儿童安全座椅”,我们的大脑会立刻开始还原这些用户的真实形象,并尝试融入角色,站在这个用户的角度思考问题。此时的Persona才是具有power的,具有价值的。
3、没有建立真正有效的用户画像标签
如果你能够建立真正有效的用户画像标签,才算正确理解从而提升运营效果。这就涉及到构建用户画像最大的难点了。
比如某知识付费团队要卖课,那么建立用户画像最核心的诉求就是:提高课程购买数量。如果能通过用户画像了解用户购买课程的意愿,然后采取相应的运营策略,效率便会大幅度提高。而这个购买课程意愿度,就是我们最需要放在用户画像里的标签。
六、小结
1.我们进入了一个用户精细化运营阶段。在这个阶段中,我们不得不使用一个工具——用户“画像”标签体系;
2.用户画像是根据用户人口学特征、网络浏览内容、网络社交活动和消费行为等信息而抽象出的一个标签化的用户模型;
3.用户在企业发展的过程中有举足轻重的作用,主要应用有:精准营销、用户分析、数据应用、数据分析;
4.用户画像包含的内容并不完全固定,根据行业和产品的不同所关注的特征也有不同;
5.好的用户画像是理解用户的决策,考虑业务场景和业务形态的。
参考资料:
链接:https://www.zhihu.com/question/31429786/answer/614573282
链接:https://zhuanlan.zhihu.com/p/24488641
链接:https://zhuanlan.zhihu.com/p/29308215
参考书籍:
赢在用户-Web人物角色创建和应用实践指南

若有收获,就点个赞吧
0 人点赞
