前言
上一篇数据分析:数据预处理—标准化初解释(一)是在R中初步实现计算各类标准化的方法,没进一步分析为何要标准的原因,这一次我们借用两个标准化方法极值标准化和Zscore标准化重新解析标准化的原因。更多知识分享请到 https://zouhua.top/。
在构建模型过程中,通常使用多变量作为自变量去预测结果,多变量很多时候是具有多个不同的单位和量纲的。如果使用原始值去构建模型或做预测,这会导致每个变量对结果的贡献度不一致,因此常需要对自变量做 transform和standardization。
比如变量A的范围是0-1,000,000;变量B的范围是0-100,在没标准化前,它们对结果的贡献度是不同的。
常用标准化方法
- 极值标准化: $$NormalizedValue{x} = \frac{x-min{x}}{max{x}-min{x}}$$
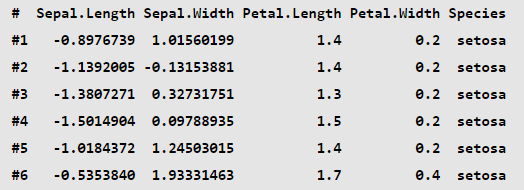
library(dplyr)data(iris)min_max_norm <- function(x){(x -min(x, na.rm = TRUE))/(max(x, na.rm = TRUE) - min(x, na.rm = TRUE))}iris_norm <- lapply(iris[, 1:4], min_max_norm) %>% data.frame() %>%mutate(Species=iris$Species)head(iris_norm)

Notes: 每个变量的范围在[0, 1]之间。极值标准化的缺点是会将数据拉向均值,对离群点不敏感,相反Zscore则考虑到极值的影响(通过除以标准差实现该效果)。
- Z-score标准化:$$ NormalizedValue_{x} = \frac{x - \mu}{\sigma} $$
scale函数可用于zscore标准化。
# single variableiris$Sepal.Width <- (iris$Sepal.Width - mean(iris$Sepal.Width, na.rm = TRUE)) / sd(iris$Sepal.Width, na.rm = TRUE)# multiple variableiris_standardize <- as.data.frame(scale(iris[1:4]))library(dplyr)iris_new <- iris %>% mutate_each_(list(~scale(.) %>% as.vector),vars = c("Sepal.Width","Sepal.Length"))head(iris_new)
Log Transformation
很多时候数据是偏斜分布的(左右两个分布是偏态分布,中间是正态分布)。通常使用log2转换使得其分布符合正态分布。

log(dat$variable)
最近看到一篇文献对数据做了log2transform+median normalization。
质谱数据(蛋白质组+代谢组)的intensity数值是整型且数目巨大,先使用log2transform一可以降低量纲影响二可以使得数据分布服从正态分布。
后面再做median normalization是排除log2transform后数据对预测结果仍然贡献不一致。
median_norm <- function(x){value <- as.numeric(x)x_scale <- (value - stats::median(value, na.rm = TRUE))/stats::IQR(value, na.rm = TRUE)return(x_scale)}

问题来了,缺失值该如何处理呢?
systemic information
sessionInfo()
R version 4.0.2 (2020-06-22)Platform: x86_64-conda_cos6-linux-gnu (64-bit)Running under: CentOS Linux 8 (Core)Matrix products: defaultBLAS/LAPACK: /disk/share/anaconda3/lib/libopenblasp-r0.3.10.solocale:[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8 LC_PAPER=en_US.UTF-8 LC_NAME=C[9] LC_ADDRESS=C LC_TELEPHONE=C LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=Cattached base packages:[1] stats graphics grDevices utils datasets methods baseother attached packages:[1] PTXQC_1.0.12 tibble_3.1.5 dplyr_1.0.7loaded via a namespace (and not attached):[1] tinytex_0.32 tidyselect_1.1.1 xfun_0.24 bslib_0.2.5.1 reshape2_1.4.4 purrr_0.3.4[7] colorspace_2.0-2 vctrs_0.3.8 generics_0.1.0 viridisLite_0.4.0 htmltools_0.5.1.1 yaml_2.2.1[13] utf8_1.2.1 rlang_0.4.11 jquerylib_0.1.4 pillar_1.6.4 glue_1.4.2 DBI_1.1.1[19] gdtools_0.2.2 RColorBrewer_1.1-2 lifecycle_1.0.0 plyr_1.8.6 stringr_1.4.0 munsell_0.5.0[25] gtable_0.3.0 rvest_0.3.6 kableExtra_1.3.4 evaluate_0.14 knitr_1.33 UpSetR_1.4.0[31] fansi_0.5.0 Rcpp_1.0.7 scales_1.1.1 webshot_0.5.2 jsonlite_1.7.2 systemfonts_0.3.2[37] gridExtra_2.3 ggplot2_3.3.5 digest_0.6.27 stringi_1.4.6 ade4_1.7-18 cowplot_1.1.0[43] grid_4.0.2 tools_4.0.2 magrittr_2.0.1 sass_0.4.0 ggdendro_0.1.22 R6P_0.2.2[49] seqinr_4.2-4 crayon_1.4.1 tidyr_1.1.4 pkgconfig_2.0.3 ellipsis_0.3.2 MASS_7.3-54[55] data.table_1.14.0 xml2_1.3.2 assertthat_0.2.1 rmarkdown_2.9 svglite_1.2.3.2 httr_1.4.2[61] rstudioapi_0.13 R6_2.5.0 compiler_4.0.2
Reference
参考文章如引起任何侵权问题,可以与我联系,谢谢。

若有收获,就点个赞吧
0 人点赞
