算法简介
BERT 是2018年Google提出的“11项全能模型”,在很多NLP场景里取得了非常好的结果。随着“Pretrain-Finetune”的模式逐渐发展,衍生出了很多类似的 BERT 类模型,我们统一把它们称之为预训练语言模型。除了对BERT预训练好的模型进行Finetune以外,BERT生成的向量本身也很有价值,我们也可以将BERT看做一个特征提取器,输入一个文本序列,输出一个向量的序列,同时我们可以将CLS输出的向量经过Dense后的向量作为整个句子的句向量。
ez_bert_feat 这个组件以原始文本作为输入,端到端输出经过BERT后的向量。我们实现并且重新训练了中/英文场景下的以下预训练模型:
- BERT (Google, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding)
- Roberta (Facebook, Robustly Optimized BERT Pretraining Approach)
- ALBERT(Google, ALBERT: A Lite BERT for Self-supervised Learning of Language Representations)
- T5 (Google, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer)
用户可以直接提取相应预训练模型下对句子进行编码/对句子的每个词进行编码。
具体而言,当用户给定一个句子S,该组件会自动将其分词为subtoken形式S = [CLS, tok1, tok2, ..., tokN, SEP],并给出三种类型结果任用户选择:
pool_output: 即图中的 C’,也就是对句子进行编码后的向量first_token_output: 即图中的 Call_hidden_outputs: 即图中的 [C, T1, T2, …, TN, TSEP]该组件拥有以下特性:
- 命令简单,最短只需要4个PAI命令参数
- 支持以模型名称选择预训练模型,同时支持模型路径输入选择自定义预训练模型
- 支持多种多类开源的BERT类预训练模型
- ODPS表端到端输出,输入原始数据,输出向量,仅需指定输出表名
- 支持对输入表中字段添加到输出表中
- 支持
easy_transfer_appfinetune模型保存的checkpoint来提取向量可视化配置参数
【输入桩配置】
| 输入桩(从左到右) | 限制数据类型 | 建议上游组件 | 是否必选 | | —- | —- | —- | —- | | 训练数据 | odps | 读数据表odps | 是 |
【右侧参数表单】
I/O字段设置:设置待向量化的列名,设置输出表保留列列名
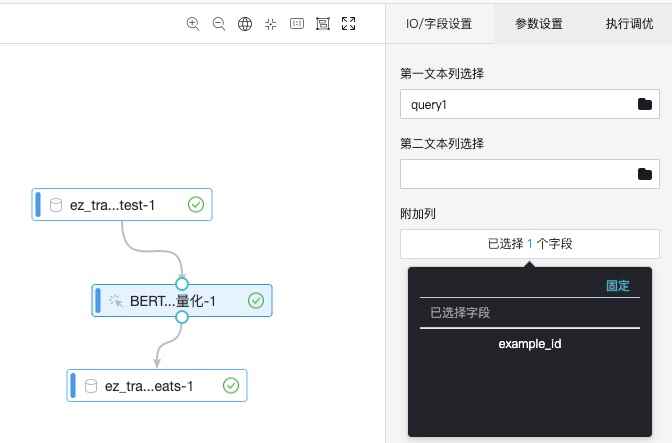
| 参数名称 | 参数描述 | 取值类型 | 必选,默认值 |
|---|---|---|---|
| 第一文本列选择 | 第一个文本序列在输入格式中对应的列名 | string类型 | 必选 |
| 第二文本列选择 | 第二个文本序列在输入格式中对应的列名 | string类型 | 可选,默认为空,’’ |
| 附加列 | 用户输入表中添加到输出的列 | string类型 | 可选,默认为空,’’ |
参数设置: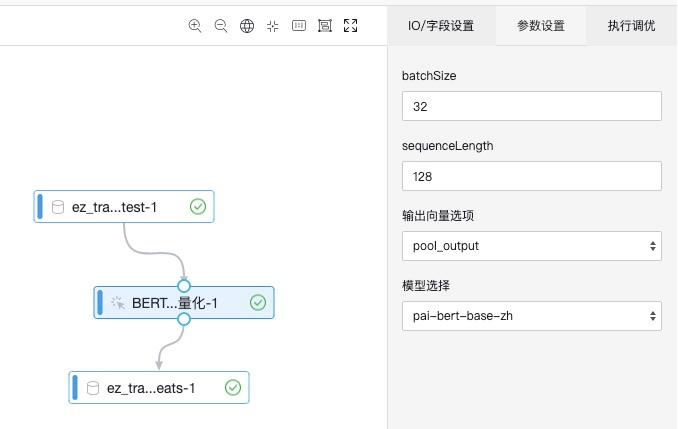
| 参数名称 | 参数描述 | 取值类型 | 必选,默认值 |
|---|---|---|---|
| batchSize | 特征提取批大小 | int类型 | 可选,默认为256 |
| sequenceLength | 序列整体最大长度 | int类型 | 可选,默认为128,范围为1~512 |
| 输出特征选项 | 选择输出数据中需要哪几个特征 | string类型 | 可选,默认为’pool_output’ ,’pool_output,first_token_output,all_hidden_outputs’ (可多选) |
| 模型选择 | 选择预训练模型 | string类型 | 预训练模型,比方说:pai-bert-base-zh, 其他模型详见:https://yuque.antfin-inc.com/pai/transfer-learning/uugdk2 |
执行调优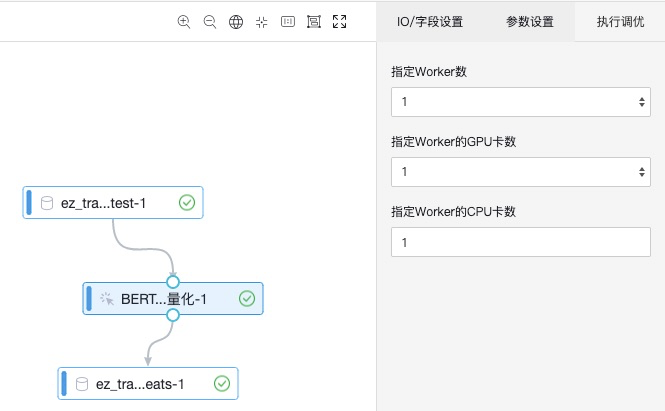
| 参数名称 | 参数描述 | 取值类型 | 必选,默认值 |
|---|---|---|---|
| 指定Worker数 | int | 可选,默认为3个Worker | |
| 指定Worker的GPU卡数 | int | 可选,标识是否使用GPU。默认是2张卡 | |
| 指定Worker的CPU卡数 | int | 可选,标识是否使用GPU。默认是4张卡。 |
【输出桩配置】
| 输出桩 | 限制数据类型 | 建议下游组件 | 是否必选 |
|---|---|---|---|
| 结果数据 | odps | 写数据表odps | 是 |
PAI命令及说明
1. PAI命令
pai -name ez_bert_feat_ext
-DinputTable=${table_name}
-DoutputTable=${table_name_out}
-DfirstSequence=query1
-DappendCols=example_id,category,score,query2
-DoutputSchema=pool_output
-DmodelName=oss://path/to/model.ckpt-xx
-DsequenceLength=32
-DbatchSize=128
-DworkerCount=1
-DworkerCPU=1
-DworkerGPU=1
-Dbuckets=oss://path/?role_arn=${role_arn}&host=${your_host}
2. 参数说明
| 参数名称 | 是否必选 | 参数描述 | 类型 | 默认值 |
|---|---|---|---|---|
| inputTable | 必选 | 输入待特征提取文本表格 | STRING,格式为project.table | 无 |
| outputTable | 必选 | 输出特征表格 | STRING,格式为project.table | 无 |
| firstSequence | 必选 | 第一个文本序列在输入格式中对应的列名 | STRING | 无 |
| secondSequence | 可选 | 第二个文本序列在输入格式中对应的列名 | STRING | 默认为空,’’ |
| appendCols | 可选 | 用户输入表中添加到输出的列 | STRING | 默认为空,’’ |
| outputSchema | 可选 | 选择输出数据中需要哪几个特征 | STRING | 默认为 ‘pool_output’ ,’pool_output,first_token_output,all_hidden_outputs’ (可多选) |
| modelName | 可选 | 预训练模型名 | STRING | 可选,默认为’pai-bert-base-zh’,详见后一节“支持模型”;用户也可自定义输入自己预训练好的模型checkpoint path |
| sequenceLength | 可选 | 序列整体最大长度 | INT | 默认为128,范围为1~512 |
| batchSize | 可选 | 特征提取批大小 | INT | 默认为256 |
| workerCount | 可选 | 指定Worker数 | INT | 默认为1个Worker |
| workerGPU | 可选 | 指定Worker的GPU卡数 | INT | 标识是否使用GPU。默认是1张卡 |
| workerCPU | 可选 | 指定Worker的CPU卡数 | INT | 标识是否使用GPU。默认是1张卡。 |
| buckets | 必选 | 需要鉴权的oss bucket | STRING | 无 |
| role_arn | 必选 | 用户的arn配置 | STRING | 无 |
| host | 必选 | 用户的bucket对应的oss host | STRING | 无 |
支持计算资源
【MaxCompute】
具体示例
1. 数据准备
首先在这个 链接 中下载本教程相关的数据,这是一个用\t 分隔的 .csv 文件,我们可以看到这个有五个字段,我们把它们命名为 example_id,query1,query2,category,score:
14606 借呗审核暂未通过怎么办 蚂蚁借呗的综合评估没通过怎么办 类别3 -0.05380478405955766
37202 花呗用不了 但是进入支付的时候花呗选不了 类别2 0.19953719332006672
31924 为什么我借呗还进去了 不能借出来了 借呗上借了款借呗进不去了 类别1 -0.9453511453023166
35904 花呗的钱能充值q币么 花呗可以卖q币么 类别3 0.7214070096167942
35871 蚂蚁借呗怎么才能显示在屏幕上 蚂蚁借呗怎么默认银行卡 类别1 -2.054884478044209
注意:本教程所用数据来自 AFQMC 蚂蚁金融语义相似度数据集,为了演示教程,我们随机生成了三个字段
example_id,category和score,用户在使用自己的table时一定要注意输入列不包含空值。
然后在自己的ODPS ${project_name} (如sre_mpi_algo_dev)中创建一张输入表并上传数据:
odpscmd -e "
CREATE TABLE ez_transfer_toy_test(
example_id INT, query1 STRING, query2 STRING, category STRING, score DOUBLE);
"
odpscmd -e "tunnel upload test.csv ez_transfer_toy_test -fd \t;"
在这里,需要指定另外一张输出表接受输出
project_name="sre_mpi_algo_dev"
table_name=odps://${project_name}/tables/ez_transfer_toy_test
table_name_out=odps://${project_name}/tables/ez_transfer_toy_test_bert_feats
注意:本组件会自动建输出表,但不会覆盖已有表,因此需要该表不存在,否则会报错
2. PAI Web教程
- 参考以上可视化配置参数。创建工作流,新建输入组件(读数据表组件)。将输入组件和模型组件链接,运行即可获得结果。工作流示例如下:

注意:如果是文本匹配的任务,会有句子对的输入,需要把第一文本列设为句子1,第二文本列设为句子2。单句子的任务,第二文本列设为空即可。
3. 输出结果
首先我们可以先查看一下输出表的Schema是否符合我们的预期:
DESC ez_transfer_toy_test_bert_feats;
预期结果如下:
+-------------------------------------------------------+
| Field | Type | Label | Comment |
+-------------------------------------------------------+
| pool_output | string | | |
| example_id | bigint | | |
| category | string | | |
| score | double | | |
| query2 | string | | |
+-------------------------------------------------------+
然后我们提取其中一行进行观察:
odpscmd -e 'SELECT * FROM ez_transfer_toy_test_bert_feats LIMIT 1;'
预期结果如下,其中 pool_output 为 768 维并用 , 分隔的字符串:
+-------------+------------+------------+------------+------------+
| pool_output | example_id | category | score | query2 |
+-------------+------------+------------+------------+------------+
| 0.999340713024,...,0.836870908737 | 14606 | 类别3 | -0.053804785 | 蚂蚁借呗的综合评估没通过怎么办 |
+-------------+------------+------------+------------+------------+
支持模型
支持模型可见ModelZoo列表:https://www.yuque.com/easytransfer/easytm/cn0uh8

若有收获,就点个赞吧
0 人点赞
