BERT序列标注是对序列中的每个token都当成一个多分类问题,如下所示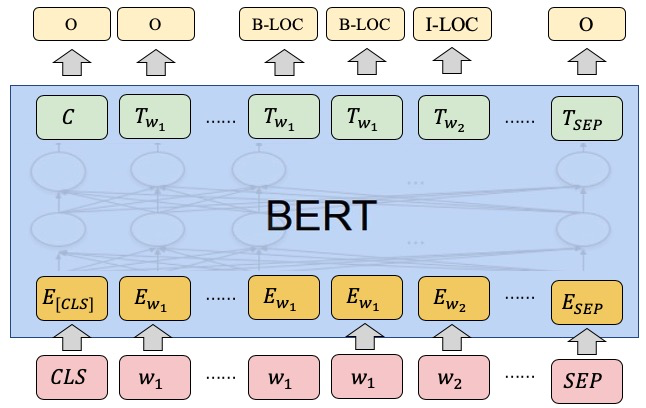
我们采用了Google原论文中的序列标注方法,即把word-piece后的第一个subtoken作为token-level分类器的输入,计算loss进行反向传播,其他的subtokens输出均会被mask
We use the representation of the first sub-token as the input to the token-level classifier over the NER label set
模型参数详解
除了通用的组件参数(详见完整PAI命令文档)以外,BERT还可以在 -DuserDefinedParameters 输入以下参数:
| 参数名 | 参数描述 | 取值类型 | 默认值 |
|---|---|---|---|
| pretrainedModelNameOrPath | 预训练BERT名 | string类型 | pai-bert-base-zh,支持EasyTransfer下的所有预训练模型;也可以是用户自己的预训练模型oss路径,格式为 oss://path/to/model_dir/model.ckpt |
输入字段/数据格式
| 参数名 | 对应模型中的字段 | 取值类型 | 格式 |
|---|---|---|---|
| firstSquence | sequence | string类型 | 每个词按空格分隔 |
| labelName | sequence tags | string类型 | 每个tag与序列的词一一对应,按空格分隔 |
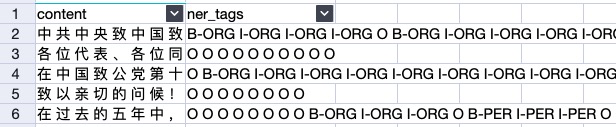
以下面的人民日报数据集为例:
| 参数名 | 列名 | 某一行内容 |
|---|---|---|
| firstSquence | content | 中 共 中 央 致 中 国 致 公 党 十 一 大 的 贺 词 |
| labelName | ner_tags | B-ORG I-ORG I-ORG I-ORG O B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG O O O |
英文以conll2003 NER数据为例:
| 参数名 | 列名 | 某一行内容 |
|---|---|---|
| firstSquence | content | Fischler proposed EU-wide measures after reports from Britain and France that under laboratory conditions sheep could contract Bovine Spongiform Encephalopathy ( BSE ) — mad cow disease . |
| labelName | ner_tags | B-PER O B-MISC O O O O B-LOC O B-LOC O O O O O O O B-MISC I-MISC I-MISC O B-MISC O O O O O O |

模型训练
训练序列标注模型无需对输入表进行序列化,直接输入原始Table即可。
首先配置一些环境参数:
export train_table=odps://${project_name}/tables/your_train_table_nameexport dev_table=odps://${project_name}/tables/your_dev_table_nameexport saved_model_dir=oss://path/to/your_model/export oss_bucket_name=your_bucket_nameexport access_key_id=your_access_idexport access_key_secret=your_access_key_secretexport host=your_host
pai -name easytexminer-project algo_platform_dev-Dmode=train-DinputTable=${train_table},${dev_table}-DfirstSequence=content-DlabelName=ner_tags-DlabelEnumerateValues=B-LOC,B-ORG,B-PER,I-LOC,I-ORG,I-PER,O-DmodelName=sequence_labeling_bert-DcheckpointDir=${saved_model_dir}-DlearningRate=3e-5-DnumEpochs=3-DsaveCheckpointSteps=32-DbatchSize=32-DworkerCount=1-DworkerGPU=1-DuserDefinedParameters="--pretrain_model_name_or_path=oss://easytransfer-new/161093/models/bert/pai-bert-tiny-zh/model.ckpt"-Dbuckets="oss://${oss_bucket_name}?access_key_id=${access_key_id}&access_key_secret=${access_key_secret}&host=${host}"
训练代码详见:path-to-easytexminer/scripts/sequence_labeling/run_labeling.sh
模型评估
pai -name easytexminer-project algo_platform_dev-Dmode=evaluate-DinputTable=${dev_table}-DfirstSequence=content-DlabelName=ner_tags-DlabelEnumerateValues=B-LOC,B-ORG,B-PER,I-LOC,I-ORG,I-PER,O-DmodelName=sequence_labeling_bert-DcheckpointPath=${saved_model_dir}-Dbuckets="oss://${oss_bucket_name}?access_key_id=${access_key_id}&access_key_secret=${access_key_secret}&host=${host}"
模型弹性分布式预测
首先定义相关的环境参数
export test_table=odps://${project_name}/tables/your_test_table_name
export saved_model_dir=oss://path/to/your_model/
export oss_bucket_name=your_bucket_name
export role_arn=acs:ram::xxx
export host=your_host
- 弹性分布式预测
最后的结果如下:pai -name easytexminer -project algo_platform_dev -Dmode=predict -DinputTable=odps://${proj_name}/tables/your_test_table -DoutputTable=odps://${proj_name}/tables/your_test_table_out -DfirstSequence=content -DoutputSchema=predictions -DappendCols=ner_tags -DmodelName=sequence_labeling_bert -DcheckpointPath=${saved_model_dir} -DbatchSize=32 -DworkerCount=1 -Dbuckets="oss://${oss_bucket_name}/?role_arn=${role_arn}&host=${host}"
模型蒸馏
如果12层模型太大,满足不了inference需求,蒸馏BERT序列标注模型到更小的模型可以参考教程《BERT序列标注蒸馏》
模型效果
使用人民日报数据效果如下 https://github.com/zjy-ucas/ChineseNER
| entity-level F1 | |
|---|---|
| BERT | 92.54% |
| BERT+CRF | 93.19% |
| BERT+LSTM+CRF | 93.75% |
模型服务
中文基础NER服务:
curl 1664081855183111.cn-shanghai.pai-eas.aliyuncs.com/api/predict/nlu_chinese_base_ner_base -H 'Authorization:MWZkNzJmZTY4NDY1YTAzZjUwMDcyMDllZTg3ZjQ1NzQ4NjY3YzM3Ng==' --data-binary '
{
"id": "1662",
"first_sequence": "古城保定,有一家梁连起创立的玉兰香大酒店,以其高质量的服务、物美价廉的菜肴而享誉四方。",
"sequence_length": 128
}'

若有收获,就点个赞吧
0 人点赞
