算法简介
通用NLP预测用来加载训练好的模型,对输入数据表进行预测,产出预测结果。该组件需要和其他组件组合使用,比方说可以和BERT文本分类,BERT文本匹配,BERT序列标注训练等组件组合。
可视化配置参数
【输入桩配置】
| 输入桩(从左到右) | 限制数据类型 | 建议上游组件 | 是否必选 |
|---|---|---|---|
| 测试数据 | odps | 读数据表odps | 是 |
| 模型输出checkpoint | oss | BERT训练组件,包括 BERT文本分类训练, BERT文本匹配训练, BERT序列标注训练等 |
是 |
【右侧参数表单】

参数设置:
| 参数名称 | 参数描述 | 取值类型 | 必选,默认值 |
|---|---|---|---|
| 第一文本列选择 | 第一个文本序列在输入格式中对应的列名 | string类型 | 必选 |
| 第二文本列选择 | 第二个文本序列在输入格式中对应的列名 | string类型 | 可选,默认为空,’’ |
| 输出列 | 选择输出数据中需要哪几个预测值 | string类型,格式: featname1, featname2 | 可选,默认为’predictions’;该参数根据模型不同所填不同, 详细可以参照下面的对照表 |
| 预测概率截断 | 预测的概率截断阈值 | double类型 | 可选,默认为无 |
| 附加列 | 用户输入表中添加到输出的列 | string类型 | 可选,默认为空,’’ |
| batchSize | 特征提取批大小 | int | 可选,默认为256 |
| 使用自定义模型 | 是否使用自定义模型 | 是/否 | 默认否,自动拉取连接的组件的导出模型,否则需要手动填写导出模型地址 |
outputSchema与模型对应表:
- textclassify[bert|textcnn], textmatch[bert|bert_two_tower|dam|dam_plus|bicnn|hcnn]可输出的字段
predictions,对单标签模型而言,输出相应类型的id,其中id与训练时的labelEnumerateValue顺序对应;对于多标签而言,输出multi-hot的向量,逗号分隔probabilities,输出每一个类的概率,逗号分隔logits,输出每一个类的概率,逗号分隔
执行调优:
| 参数名称 | 参数描述 | 取值类型 | 必选,默认值 |
|---|---|---|---|
| 指定Worker数 | worker的数量 | int | 可选,默认为3个Worker |
| 指定Worker的GPU卡数 | 每个worker的GPU卡数 | int | 可选,标识是否使用GPU。默认是2张卡 |
| 指定Worker的CPU卡数 | 每个worker的CPU核数 | int | 可选,标识是否使用GPU。默认是4张卡。 |
| 分布式策略 | 定义分布式策略 | MirroredStrategy 或者: ExascaleStrategy |
必须,单机单卡或者单机多卡选 MirroredStrategy 多机多卡选ExascaleStrategy |
【输出桩配置】
| 输出桩 | 限制数据类型 | 建议下游组件 | 是否必选 |
|---|---|---|---|
| 结果数据 | odps | 写odps数据表 | 否 |
支持计算资源
【MaxCompute】
具体示例
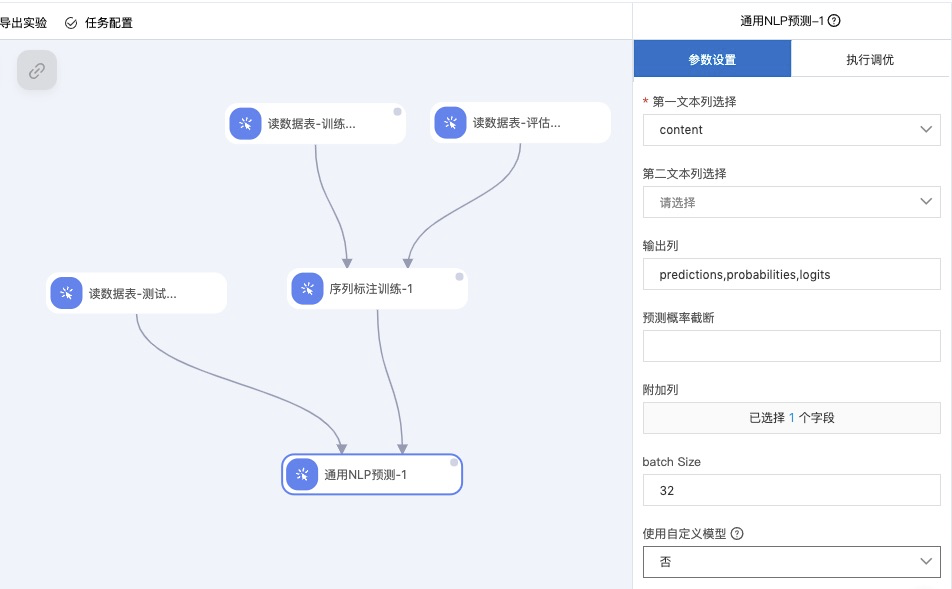
参考以上工作流示例,创建工作流,新建两个输入组件:
- 读数据表组件,对应预测数据
- 训练组件:需要和其他组件组合使用,候选组件为:BERT文本分类训练,BERT文本匹配训练,和BERT序列标注训练
将两个输入组件和模型组件连接,运行即可获得结果。

若有收获,就点个赞吧
0 人点赞
