知识蒸馏简介
随着BERT等预训练语言模型在各项任务上都取得了STOA效果,BERT这类模型已经成为 NLP 深度迁移学习管道中的重要组成部分。但 BERT 并不是完美无瑕的,这类模型仍然存在以下两个问题:
- 模型参数量太大:BERT-base 模型能够包含一亿个参数,较大的 BERT-large 甚至包含 3.4 亿个参数。显然,很难将这种规模的模型部署到资源有限的环境(例如移动设备或嵌入式系统)当中。
- 训练/推理速度慢:在基于 Pod 配置的 4 个 Cloud TPUs(总共 16 个 TPU 芯片)上对 BERT-base 进行训练,或者在 16 个 Cloud TPU(总共 64 个 TPU 芯片)上对 BERT-large 进行训练,每次预训练都需要至少 4 天的时间才能完成。而BERT的推理速度更是严重影响到了需要较高QPS的线上场景,部署成本非常高。
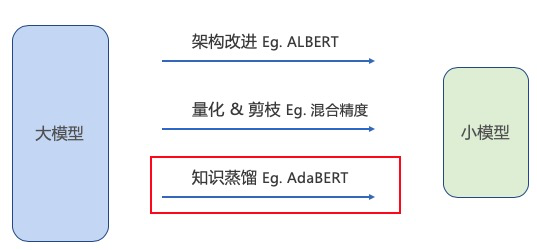
而这个问题,不仅仅是在NLP领域存在,计算机视觉也同样存在,通常来讲有以下三种解决方案:
- 架构改进:将原有的架构改进为更小/更快的架构,例如,将 RNN 替换为 Transformer 或 CNN,ALBERT替代BERT等;使用需要较少计算的层等。当然也可以采用其他优化,例如从学习率和策略、预热步数,较大的批处理大小等;
- 模型压缩:通常使用量化和修剪来完成,从而能够在架构不变(或者大部分架构不变)的情况下减少计算总量;
- 知识蒸馏:训练一个小的模型,使得其在相应任务行为上能够逼近大的模型的效果,如DistillBERT,BERT-PKD,TinyBERT等
PAI-NLP团队,在知识蒸馏上有大量相关的积累,如我们提出的AdaBERT,利用可微神经网络架构搜索来自动将BERT蒸馏成适应不同特定任务的小型模型。在多个NLP任务上的结果表明这些任务适应型压缩模型在保证表现相当的同时,推理速度比BERT快10~30倍,同时参数缩小至BERT的十分之一。本框架重点研究,以及提供简单易用的工具,来进行BERT的知识蒸馏。
EasyDistill能够快速接入EasyTransfer-AppZoo/ google-bert / hugginface-transformer的模型,进行多种方法,多种维度的蒸馏,总体框架如下: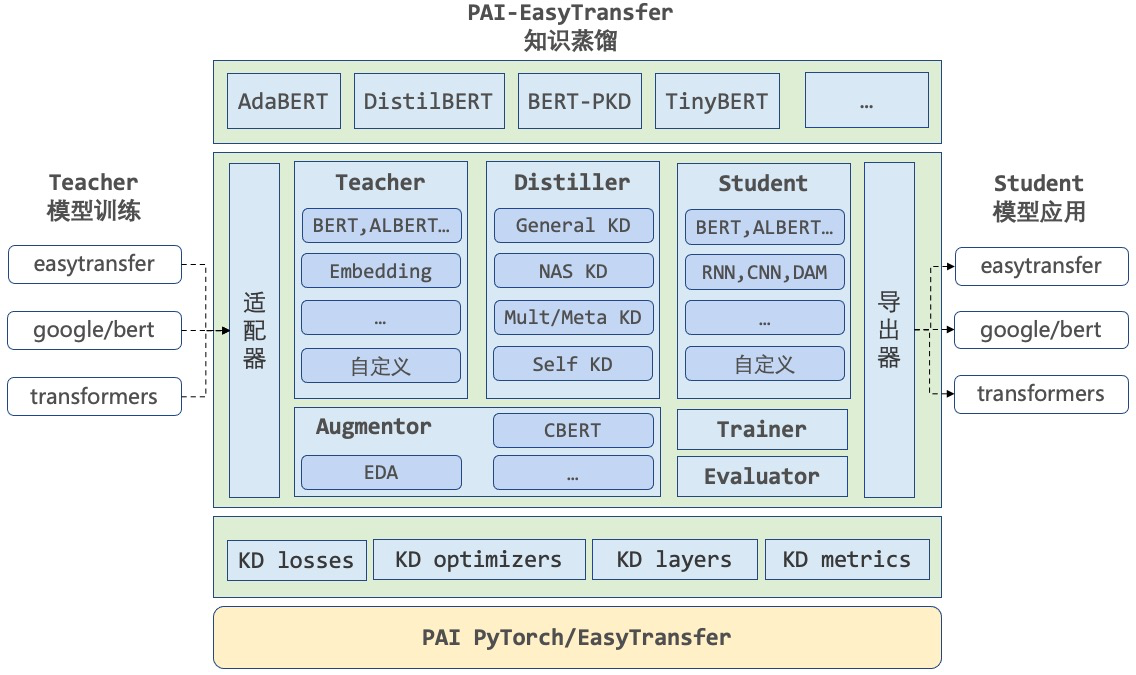
使用说明
支持的任务
当前知识蒸馏训练范式仅支持部分下游任务,包括:
- 文本分类 (Text Classification)
- 单塔文本匹配 (Single-Tower Text Match)
其他下游任务的支持有待后续更新。
主要流程
EasyTexMiner 知识蒸馏的主要流程为:
- 准备所需的数据集,并提前处理为 EasyTexMiner 支持的
tsv格式(以制表符\t分隔的值表)。 - 选定大规模的预训练模型作为 Teacher Model,并依照其所属的下游任务进行 fine-tuning。详情参考本文档对应章节。
- 导出训练好的 Teacher Model 的 logits 到文件。
- 根据需求选定小规模的预训练模型作为 Student Model,并依照知识蒸馏范式进行 fine-tuning。
- 得到目标模型。
用户接口
在常规的下游任务 fine-tuning 命令的基础上,使用知识蒸馏范式需要在 input_schema 的末尾追加 logits 条目,并在 user_defined_parameters 中显式地启用,以键值对的形式传入所需的参数:
| 参数名 | 类型 | 可选值 | 描述 |
|---|---|---|---|
enable_distillation |
bool | True/False | 是否启用知识蒸馏 |
type |
str | vanilla_kd(更多类型有待增加) | 知识蒸馏的类型 |
logits_name |
str | 应与 input_schema 中一致 |
Logits 字段在输入模式中的名称 |
logits_saved_path |
str | tsv 文件相对/绝对路径 | Teacher Model 导出的 logits 文件的路径 |
temperature |
float | 大于等于 1,一般不超过 10 | 知识蒸馏的温度 |
alpha |
float | [0, 1],一般不大于 0.5 | Teacher Knowledge 在训练过程中的占比 |
具体的 CLI 命令示例如下:
# SST-2 文本分类 知识蒸馏样例easytexminer \--app_name=text_classify \--mode=train \--worker_count=1 \--worker_gpu=1 \--tables=train.tsv,dev.tsv \--input_schema=sent:str:1,label:str:1,logits:float:2 \--first_sequence=sent \--label_name=label \--label_enumerate_values=0,1 \--checkpoint_dir=./results/small_sst2_student \--learning_rate=3e-5 \--epoch_num=1 \--random_seed=42 \--save_checkpoint_steps=200 \--sequence_length=128 \--micro_batch_size=32 \--user_defined_parameters="pretrain_model_name_or_path=${STUDENT_MODEL}enable_distillation=Truetype=vanilla_kdlogits_name=logitslogits_saved_path=${LOGITS_PATH}temperature=5alpha=0.2"
完整流程示例
本节以英文双句文本分类任务(MRPC)为例,给出完整的知识蒸馏流程命令示例。
可在此下载训练集和验证集。
为了快速测试,样例中使用了尽量精简的超参数设置(#epoch、batch size 等),需要根据实际场景调整。
定义所需环境变量
# GPU device settingsexport WORKER_COUNT=1export WORKER_GPU=1# Models to be usedexport TEACHER_MODEL=bert-large-uncasedexport STUDENT_MODEL=bert-small-uncased# Path to save the fine-tuned modelsexport TEACHER_CKPT=results/large-sst2-teacherexport STUDENT_CKPT=results/small-sst2-student# Path to save the teacher logitsexport LOGITS_PATH=results/large-sst2-teacher/logits.tsv
Teacher Fine-tuning
easytexminer \--app_name=text_classify \--mode=train \--worker_count=1 \--worker_gpu=1 \--tables=train.tsv,dev.tsv \--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \--first_sequence=sent1 \--second_sequence=sent2 \--label_name=label \--label_enumerate_values=0,1 \--checkpoint_dir=${TEACHER_CKPT} \--learning_rate=3e-5 \--epoch_num=1 \--random_seed=42 \--save_checkpoint_steps=100 \--sequence_length=128 \--micro_batch_size=32 \--user_defined_parameters="pretrain_model_name_or_path=${TEACHER_MODEL}"
导出 Teacher Logits
通过 predict 模式导出 teacher model 对训练集的 logits。
easytexminer \
--app_name=text_classify \
--mode=predict \
--worker_count=1 \
--worker_gpu=1 \
--tables=train.tsv \
--outputs=${LOGITS_PATH} \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \
--output_schema=logits \
--first_sequence=sent1 \
--second_sequence=sent2 \
--checkpoint_path=${TEACHER_CKPT} \
--micro_batch_size=32 \
--sequence_length=128
Student 知识蒸馏
注意在 input_schema 中追加 logits 字段,类型为 float,数量与任务的标签数保持一致。
easytexminer \
--app_name=text_classify \
--mode=train \
--worker_count=1 \
--worker_gpu=1 \
--tables=train.tsv,dev.tsv \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1,logits:float:2 \
--first_sequence=sent1 \
--second_sequence=sent2 \
--label_name=label \
--label_enumerate_values=0,1 \
--checkpoint_dir=${STUDENT_CKPT} \
--learning_rate=3e-5 \
--epoch_num=1 \
--random_seed=42 \
--save_checkpoint_steps=200 \
--sequence_length=128 \
--micro_batch_size=32 \
--user_defined_parameters="
pretrain_model_name_or_path=${STUDENT_MODEL}
enable_distillation=True
type=vanilla_kd
logits_name=logits
logits_saved_path=${LOGITS_PATH}
temperature=5
alpha=0.2
"
Student 模型预测
easytexminer \
--app_name=text_classify \
--mode=predict \
--worker_gpu=1 \
--worker_count=1 \
--tables=dev.tsv \
--outputs=student_pred.tsv \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \
--output_schema=predictions \
--first_sequence=sent1 \
--second_sequence=sent2 \
--checkpoint_path=${STUDENT_CKPT} \
--micro_batch_size=32 \
--sequence_length=128

若有收获,就点个赞吧
0 人点赞
