- touch 创建文件
- kill 杀进程
- 切换用户(管理员)
- free -m 查看内存说明
- df查看磁盘空间
- crontab 定时执行
- nmon命令总结
- xargs
- exec
- 输入输出重定向
- grep
- sed
- awk 文本和数据进行处理的编程语言
- fdisk磁盘分区
- du 查看磁盘空间使用情况
- sort命令 – 排序文件并输出
- usermod
- id命令 – 显示用户ID和组ID
- rpm命令 – RPM软件包管理器
- mysqldump命令 – MySQL数据库备份
- seq 命令 – 打印数字序列
- rz从windows上传文件
- sz从Windows下载文件
- uname命令 – 显示系统信息
- PS1环境变量控制每个命令头标识:
- su 切换用户
- ssh命令 – 安全连接客户端
- find命令 – 查找和搜索文件
- diff命令 – 比较文件的差异
- vimdiff命令 – 同时编辑多个文件
- netstat命令 – 显示网络状态
- 命令别名
- cut连接文件并打印到标准输出设备上
- mount命令 – 文件系统挂载
- date - 打印或设置系统日期和时间
- uptime命令 – 查看系统负载
- last命令 – 显示用户或终端的登录情况
- tr 从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
- expr 简单计算器
- read – 读取单行数据
- at命令 – 一次性定时计划任务
- ln -在文件之间建立连接
- chown命令 – 改变文件或目录用户和用户组
- zcat命令 – 查看压缩文件的内容
touch 创建文件
touch命令有两个功能:一是创建新的空文件,二是改变已有文件的时间戳属性。
touch [参数] [文件]
| -a | 改变档案的读取时间记录 |
|---|---|
| -m | 改变档案的修改时间记录 |
| -r | 使用参考档的时间记录,与 —file 的效果一样 |
| -c | 不创建新文件 |
| -d | 设定时间与日期,可以使用各种不同的格式Mongodb 数据库服务 |
| -t | 设定档案的时间记录,格式与 date 命令相同 |
创建空文件:
[root@linuxcool ~]# touch file.txt
批量创建文件:
[root@linuxcool ~]# touch file{1..5}.txt
[root@linuxcool ~]# ls
file1.txt file2.txt file3.txt file4.txt file5.txt
kill 杀进程
2.命令功能:
发送指定的信号到相应进程。不指定型号将发送SIGTERM(15)终止指定进程。如果任无法终止该程序可用“-KILL” 参数,其发送的信号为SIGKILL(9) ,将强制结束进程,使用ps命令或者jobs 命令可以查看进程号。root用户将影响用户的进程,非root用户只能影响自己的进程。
3.命令参数:
-l 信号,若果不加信号的编号参数,则使用“-l”参数会列出全部的信号名称
-a 当处理当前进程时,不限制命令名和进程号的对应关系
-p 指定kill 命令只打印相关进程的进程号,而不发送任何信号
-s 指定发送信号
-u 指定用户
说明:
只有第9种信号(SIGKILL)才可以无条件终止进程,其他信号进程都有权利忽略。 下面是常用的信号:
HUP 1 终端断线INT 2 中断(同 Ctrl + C)QUIT 3 退出(同 Ctrl + \)TERM 15 终止KILL 9 强制终止CONT 18 继续(与STOP相反, fg/bg命令)STOP 19 暂停(同 Ctrl + Z)
切换用户(管理员)
sudo : 暂时切换到超级用户模式以执行超级用户权限,提示输入密码时该密码为当前用户的密码,而不是超级账户的密码。不过有时间限制,Ubuntu默认为一次时长15分钟。
su : 切换到某某用户模式,提示输入密码时该密码为切换后账户的密码,用法为“su 账户名称”。如果后面不加账户时系统默认为root账户,密码也为超级账户的密码。没有时间限制。
sudo -i**: 为了频繁的执行某些只有超级用户才能执行的权限,而不用每次输入密码,可以使用该命令。提示输入密码时该密码为当前账户的密码。没有时间限制。执行该命令后提示符变为“#”而不是“$”。想退回普通账户时可以执行“exit”或“logout” 。
sudo su **运行结果 PWD=/home/用户名(当前用户主目录)
free -m 查看内存说明
-m 参数就是用 M显示内容使用情况
一、从系统层面分析
Mem:内存的使用情况总览表。
totel:机器总的物理内存 单位为:M
used:用掉的内存。
free:空闲的物理内存。
注:物理内存(totel)=系统看到的用掉的内存(used)+系统看到空闲的内存(free)
二、从程序的角度分析
shared:多个进程共享的内存总和,当前废弃不用。
buffers:缓存内存数。
cached: 缓存内存数。
注:程序预留的内存=buffers+cached
df查看磁盘空间
命令的功能是用来检查linux服务器的文件系统的磁盘空间占用情况。可以利用该命令来获取硬盘被占用了多少空间,目前还剩下多少空间等信息。
df -TH 查看磁盘大小
df -ih 查看inode:文件的字节数,拥有者id,组id,权限,改动时间,链接数,数据block的位置,解决:删除数量过多的小文件
df -h命令参数详解_linux磁盘管理命令之df常用方法介绍
命令名称:df
命令所在路径:/bin/df
执行权限:所有用户
语法:df [选项]… [FILE]…
功能描述:显示目前在Linux系统上的文件系统的磁盘使用情况统计。
参数:
文件-a, —all 包含所有的具有 0 Blocks 的文件系统
文件-h, —human-readable 使用人类可读的格式(预设值是不加这个选项的…)
文件-H, —si 很像 -h, 但是用 1000 为单位而不是用 1024
文件-i, —inodes 列出 inode 资讯,不列出已使用 block
文件-k, —kilobytes 就像是 —block-size=1024
文件-l, —local 限制列出的文件结构
文件-m, —megabytes 就像 —block-size=1048576
示例1: # df
显示文件系统的磁盘使用情况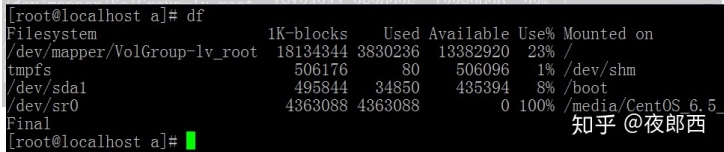
其中,
第一列指定文件系统的名称
第二列指定一个特定的文件系统1K-块1K是1024字节为单位的总内存
第三,第四列指已用和可用列分别对应的内存量
第五列指已使用的内存的百分比
最后一列”安装在”指文件系统的挂载点
df -hl:查看磁盘剩余空间
df -h:查看每个根路径的分区大小
crontab 定时执行
操作命令,每一个用户拥有自己的crontab,配置文件存在/var下面,不能被直接编辑。
-e 设置计时器
-l 列出当前计时器的设置
-r 删除计时器的设置
-i 交互式模式,删除计时器设置时要先询问
-u 指定要设定计时器的用户名称

第1列 第2列 3 4 5 6
第1列表示分钟0~59 每分钟用或者 /1表示
第2列表示小时1~23(0表示0点)
第3列表示日期1~31
第4列表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令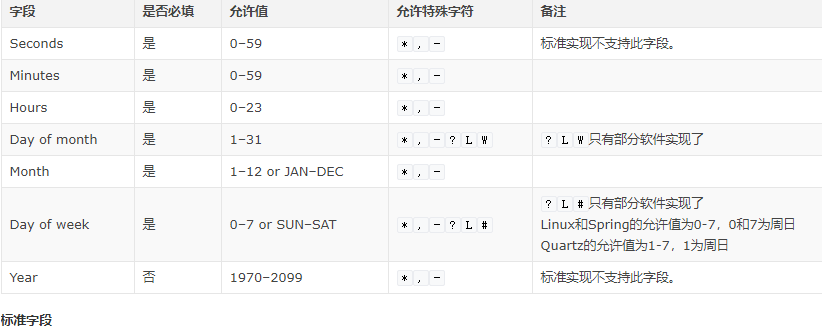
标准字段
逗号用于分隔列表。例如,在第5个字段(星期几)中使用 MON,WED,FRI 表示周一、周三和周五。
连字符定义范围。例如,2000-2010 表示2000年至2010年期间的每年,包括2000年和2010年。
除非用反斜杠()转义,否则命令中的百分号(%)会被替换成换行符,第一个百分号后面的所有数据都会作为标准输入发送给命令。
非标准字段
“L”代表“Last”。当在星期几字段中使用的时候,可以指定给定月份的结构,例如“最后一个星期五”(5L)。在月日字段中,可以指定一个月的最后一天。
“day of month”字段可以使用“W”字符。指定最接近给定日期的工作日(星期一-星期五)。例如,15W,意思是:“最接近该月15日的工作日。”;所以,如果15号是星期六,触发器在14号星期五触发。如果15日是星期天,触发器在16日星期一触发。如果15号是星期二,那么它在15号星期二触发。“1W”,如果这个月的第一天是星期六,不会跨到上个月,触发器会在这个月的第三天(也就是星期一)触发。只有指定一天(不能是范围或列表)的时候,才能指定“W”字符。
星期几字段可以使用“#”,后面必须跟一个介于1和5之间的数字。例如,5#3表示每个月的第三个星期五。
在某些实现中,“?”用来代替“”以将月中的某一天或周中的某一天留空。其他cron的实现是替换“?”为cron守护进程的启动时间,例如:?? ,如果cron在上午8:25启动,将更新为25 8 并在每天的这个时间运行,直到再次重新启动。
分钟字段设置 /5表示每5分钟一次,注意:这里指的是能被5整除的分钟数。
30 21 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每晚的21:30重启lighttpd 。
45 4 1,10,22 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每月1、10、22日的4 : 45重启lighttpd 。
10 1 6,0 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每周六、周日的1 : 10重启lighttpd 。
0,30 18-23 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示在每天18 : 00至23 : 00之间每隔30分钟重启lighttpd 。
0 23 6 /usr/local/etc/rc.d/lighttpd restart
上面的例子表示每星期六的11 : 00 pm重启lighttpd 。
0 /usr/local/etc/rc.d/lighttpd restart
每一小时重启lighttpd
0 23-7/1 /usr/local/etc/rc.d/lighttpd restart
晚上11点到早上7点之间,每隔一小时重启lighttpd
0 11 4 mon-wed /usr/local/etc/rc.d/lighttpd restart
每月的4号与每周一到周三的11点重启lighttpd
0 4 1 jan /usr/local/etc/rc.d/lighttpd restart
一月一号的4点重启lighttpd
特殊符号
符号 含义
表示任意时间都可以
- 表示取值范围
例如:
00 17-19 表示17 18 19都执行任务, 表示分隔时间.
例如
30 17,18,19 表示17.30 18.30 19.30执行/n n代表数字,表示每隔多久执行一次


du -sh *:查看每个文件夹的大小
nmon命令总结
(访问如下两个链接)
https://blog.csdn.net/xfg0218/article/details/77712457?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.baidujs&dist_request_id=1328679.50327.16163767127436467&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.baidujs
关于nmon的命令行参数
-f 电子表格输出格式[注意:默认-s300 -c288] 输出文件是
-F
-c
-d 请求磁盘服务和等待时间(DISKSERV和DISKWAIT)
-i
-g
-l
-m
-r
-s <秒>快照之间的间隔
-x 容量规划(1天时间,每15分钟监控一次= -fdt -s900 -c96)
-t 包括输出中的顶级进程
-T as -t plus在UARG部分保存命令行参数
-A 包括异步I / O(PROCAIO)部分的数据
-D 防止生成DISK部分(在磁盘组时有用)正在使用,因为有太多的硬盘要处理)
-E 停止生成ESS部分(磁盘组时需要)正在使用因为有太多的vpath要处理)
-J 防止生成JFS部分(防止Excel错误当你有超过255个文件系统)
-L 包括LARGEPAGE部分
-N 包括NFS部分
-S 包括带子类的WLM部分
-W 包括没有子类的WLM部分
-Y 包括SUMMARY部分(非常有效的替代-t if不需要PID级别数据)
如果想手动控制nmon的生成文件,只需要设置时间间隔,不设置监控次数,通过linux命令将进程杀死。
例如:ps -f | grep “nmon -f” 找到nmon的进程
kill -9 进程号 杀死进程
如果监控多台服务器可以使用一个脚本,脚本内容如下:
#!/bin/sh
ps -f | grep “nmon -f” > test.txt //将进程内容导出
num=$(awk ‘NR==1{print $2}’ test.txt) //找到进程号,其中NR是确定行数,print确定列数
kill -9 $num //杀死进程
xargs
xargs 又称管道命令,构造参数等。是给命令传递参数的一个过滤器,也是组合多个命令的一个工具 它把一个数据流分割为一些足够小的块,以方便过滤器和命令进行处理 。简单的说 就是把 其他命令的给它的数据 传递给它后面的命令作为参数
主要参数
-d 为输入指定一个定制的分割符
-i 用 {} 代替 传递的数据
-I string 用string来代替传递的数据-n[数字] 设置每次传递几行数据
-n 选项限制单个命令行的参数个数
-t 显示执行详情
-p 交互模式
-P n 允许的最大线程数量为n
-s[大小] 设置传递参数的最大字节数(小于131072字节)
-x 大于 -s 设置的最大长度结束 xargs命令执行
[root@localhost ~]# ls |grep .php |xargs -i mv {} {}.bak #将当前目录下php文件,改名字 [root@localhost ~]# ls |grep .php |xargs -I {} mv {} {}.bak #与上例相同 [root@localhost ~]# find ./ -name “.tmp” | xargs -i rm -rf {} #删除当前文件夹下的,tmp文件
# find ./ -type f -print0 |xargs -0 rm #删除该目录的所有普通文件 # find ./ -type f -exec rm ‘{}’ \; #同上 # find ./ -type f -exec rm ‘{}’ + #同上
[root@localhost ~]# ** find ./ -name “.json” | xargs grep baidu #查找所有含有baidu关键词的json文件
# 该命令用于从当前路径开始寻找包含特定字符串的文件。例子中可以看出,在test.txt文本中找到了字符串并打印了该行。 # find .| xargs grep “this is a test for finding” 2>null**
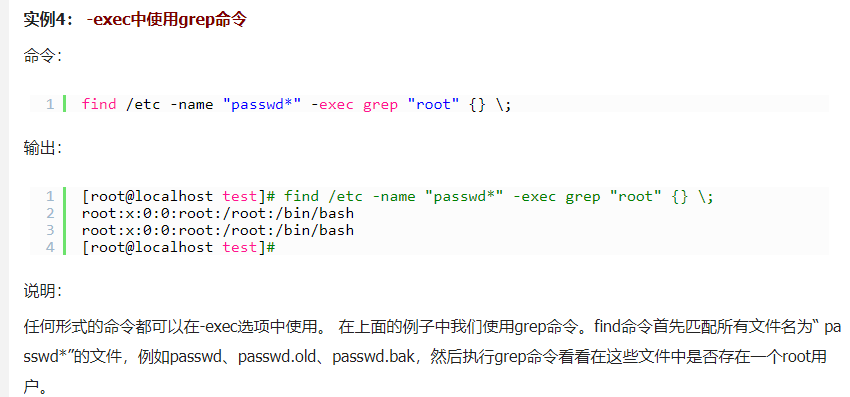
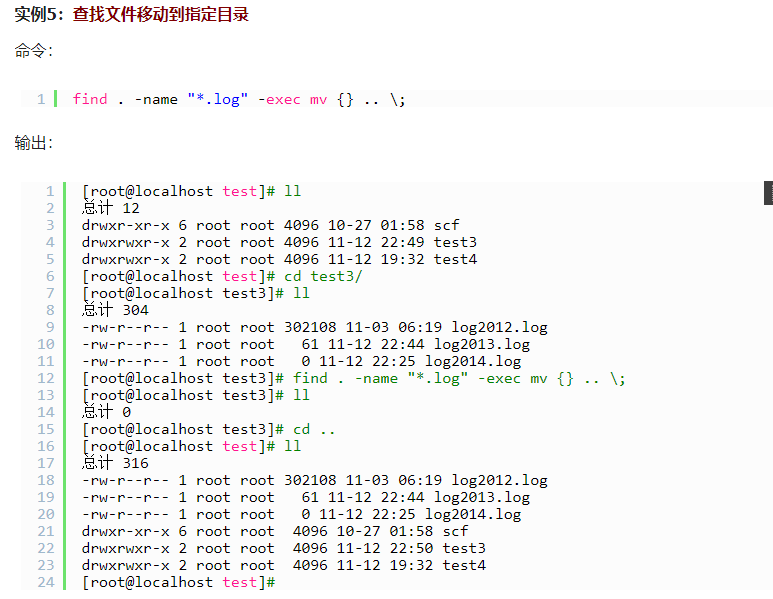
exec
-exec 参数后面跟的是command命令,它的终止是以;为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。
{} 花括号代表前面find查找出来的文件名。
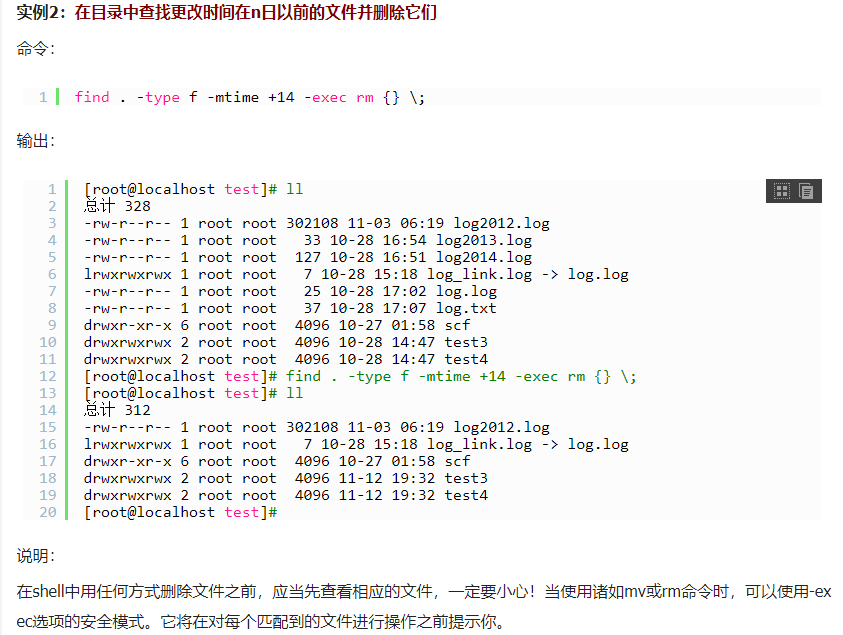
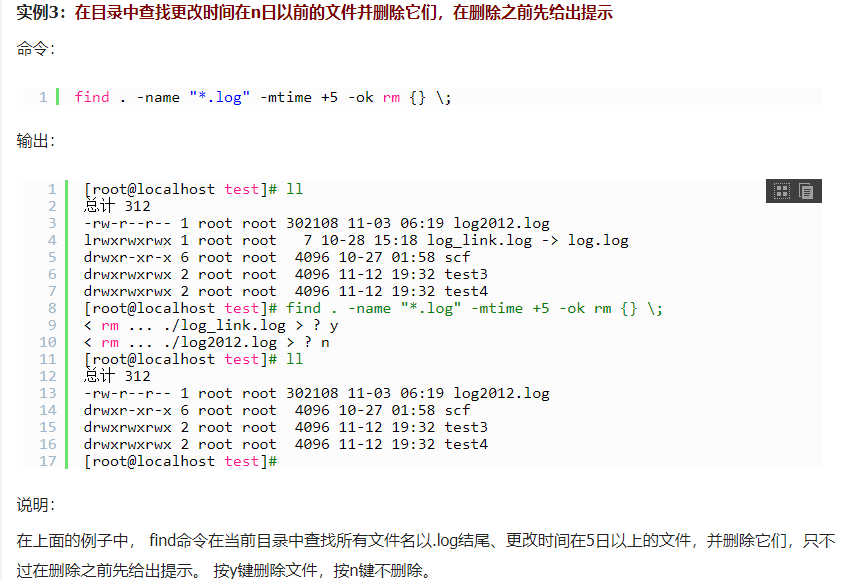
使用find时,只要把想要的操作写在一个文件里,就可以用exec来配合find查找,很方便的。在有些操作系统中只允许-exec选项执行诸如l s或ls -l这样的命令。大多数用户使用这一选项是为了查找旧文件并删除它们。建议在真正执行rm命令删除文件之前,最好先用ls命令看一下,确认它们是所要删除的文件。 exec选项后面跟随着所要执行的命令或脚本,然后是一对儿{ },一个空格和一个\,最后是一个分号。为了使用exec选项,必须要同时使用print选项。如果验证一下find命令,会发现该命令只输出从当前路径起的相对路径及文件名。
输入输出重定向
https://blog.csdn.net/world_zheng/article/details/83110029
grep
(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。Linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
匹配模式选择:
-E, —extended-regexp 扩展正则表达式egrep(过滤多个字符串)
-F, —fixed-strings 一个换行符分隔的字符串的集合fgrep
-G, —basic-regexp 基本正则
-P, —perl-regexp 调用的perl正则
-e, —regexp=PATTERN 后面根正则模式,默认无
-f, —file=FILE 从文件中获得匹配模式
-i, —ignore-case 不区分大小写
-w, —word-regexp 匹配整个单词
-x, —line-regexp 匹配整行
-z, —null-data 一个 0 字节的数据行,但不是空行
杂项:
-s, —no-messages 不显示错误信息
-v, —invert-match 显示不匹配的行
-V, —version 显示版本号
—help 显示帮助信息
—mmap use memory-mapped input if possible
输入控制:
-m, —max-count=NUM 匹配的最大数
-b, —byte-offset 打印匹配行前面打印该行所在的块号码。
-n, —line-number 显示的加上匹配所在的行号
—line-buffered 刷新输出每一行
-H, —with-filename 当搜索多个文件时,显示匹配文件名前缀
-h, —no-filename 当搜索多个文件时,不显示匹配文件名前缀
—label=LABEL print LABEL as filename for standard input
-o, —only-matching 只显示一行中匹配的部分
-q, —quiet, —silent 不显示任何东西
—binary-files=TYPE 假定二进制文件的TYPE 类型;
TYPE 可以是binary',text’, 或`without-match’
-a, —text 匹配二进制的东西
-I 不匹配二进制的东西
-d, —directories=ACTION 目录操作,读取,递归,跳过
-D, —devices=ACTION 设置对设备,FIFO,管道的操作,读取,跳过
-R, -r, —recursive 递归调用
—include=PATTERN 只查找匹配FILE_PATTERN 的文件
—exclude=PATTERN 跳过匹配FILE_PATTERN 的文件和目录
—exclude-from=FILE 跳过所有除FILE 以外的文件
-L, —files-without-match 匹配多个文件时,显示不匹配的文件名
-l, —files-with-matches 匹配多个文件时,显示匹配的文件名
-c, —count 显示匹配的行数
-Z, —null 在FILE 文件最后打印空字符
文件控制:
-B, —before-context=NUM 打印匹配本身以及前面的几个行由NUM控制
-A, —after-context=NUM 打印匹配本身以及随后的几个行由NUM控制
-C, —context=NUM 打印匹配本身以及随后,前面的几个行由NUM控制
-NUM 根-C的用法一样的
—color[=WHEN],
—colour[=WHEN] 使用标志高亮匹配字串;
-U, —binary 使用标志高亮匹配字串;
-u, —unix-byte-offsets 当CR 字符不存在,报告字节偏移(MSDOS 模式)
sed
对文本的处理很强大,并且sed非常小,参数少,容易掌握,他的操作方式根awk有点像。sed按顺序逐行读取文件。然后,它执行为该行指定的所有操作,并在完成请求的修改之后的内容显示出来,也可以存放到文件中。完成了一行上的所有操作之后,它读取文件的下一行,然后重复该过程直到它完成该文件。在这里要注意一点,源文件(默认地)保持不被修改。sed 默认读取整个文件并对其中的每一行进行修改。说白了就是一行一行的操作。我用sed主要就是用里面的替换功能,真的很强大。下面以实例,详细的说一下,先从替换开始,最常用的。
替换:sed ‘s#替换内容#替换成什么内容#g’文件名 (此命令不修改文件内容 加参数-i 修改内容)
替换(特殊符号代替):sed ‘s#()#\1#g’ 文件名 (其中()里可以些$1代表第一列或者1p代表第一行,而后面\1代表前俩#间第一个括号,\2代表第二个括号,前面括号可以是多个)
-n, —quiet, —silent 取消自动打印模式空间
-e 脚本, —expression=脚本 添加“脚本”到程序的运行列表
-f 脚本文件, —file=脚本文件 添加“脚本文件”到程序的运行列表
—follow-symlinks 直接修改文件时跟随软链接
-i[扩展名], —in-place[=扩展名] 直接修改文件(如果指定扩展名就备份文件)
-l N, —line-length=N 指定“l”命令的换行期望长度
—posix 关闭所有 GNU 扩展
-r, —regexp-extended 在脚本中使用扩展正则表达式(不用转义,否则得加反斜线“\‘)
-s, —separate 将输入文件视为各个独立的文件而不是一个长的连续输入
-u, —unbuffered 从输入文件读取最少的数据,更频繁的刷新输出
—help 打印帮助并退出
—version 输出版本信息并退出
-a ∶新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
-c ∶取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
-d ∶删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
-i ∶插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
-p ∶列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作~
-s ∶取代,可以直接进行取代,通常这个 s 的动作可以搭配正规表示法
a\ 在当前行下面插入文本。
i\ 在当前行上面插入文本。
c\ 把选定的行改为新的文本。
d 删除,删除选择的行。
D 删除模板块的第一行。
s 替换指定字符
h 拷贝模板块的内容到内存中的缓冲区。
H 追加模板块的内容到内存中的缓冲区。
g 获得内存缓冲区的全部内容,并替代当前模板块中的文本。
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l 列表不能打印字符的清单。
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p 打印模板块的行。
P(大写) 打印模板块的第一行。
q 退出Sed。
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
r file 从file中读行。
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file 写并追加模板块到file末尾。
W file 写并追加模板块的第一行到file末尾。
! 表示后面的命令对所有没有被选定的行发生作用。
= 打印当前行号码。
# 把注释扩展到下一个换行符以前。
sed替换标记
g 表示行内全面替换。
p 表示打印行。
w 表示把行写入一个文件。
x 表示互换模板块中的文本和缓冲区中的文本。
y 表示把一个字符翻译为另外的字符(但是不用于正则表达式)
\1 子串匹配标记
& 已匹配字符串标记
sed元字符集
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。
$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行。
. 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。
匹配0个或多个字符,如:/sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[] 匹配一个指定范围内的字符,如/[sS]ed/匹配sed和Sed。
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
\(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。
& 保存搜索字符用来替换其他字符,如s/love/&/,love这成love。
\< 匹配单词的开始,如:/\\> 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行。
x\{m,\} 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行。
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行。
打印第二行:
sed -n ‘2p’ zktest
打印第一二行:
sed -n ‘2,3p’ zk.test
例1
测试文件
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/false daemon:x:2:2:daemon:/sbin:/bin/false mail:x:8:12:mail:/var/spool/mail:/bin/false ftp:x:14:11:ftp:/home/ftp:/bin/false &nobody:$:99:99:nobody:/:/bin/false zhangy:x:1000:100:,,,:/home/zhangy:/bin/bash http:x:33:33::/srv/http:/bin/false dbus:x:81:81:System message bus:/:/bin/false hal:x:82:82:HAL daemon:/:/bin/false mysql:x:89:89::/var/lib/mysql:/bin/false aaa:x:1001:1001::/home/aaa:/bin/bash ba:x:1002:1002::/home/zhangy:/bin/bash test:x:1003:1003::/home/test:/bin/bash @zhangying::1004:1004::/home/test:/bin/bash policykit:x:102:1005:Po
例a,这个例子,把test文件中的root替换成tankzhang,只不过只替换一次及终止在这一行的操作,转到下一行
[zhangy@BlackGhost mytest]# sed ‘s/root/tankzhang/‘ test |grep tank tankzhang:x:0:0:root:/root:/bin/bash
例b,这个例子,用tankzhang把文件test中的root全部替换掉,请注意g这个字母,global的缩写
[zhangy@BlackGhost mytest]# sed ‘s/root/tankzhang/g’ test |grep zhang tankzhang:x:0:0:tankzhang:/tankzhang:/bin/bash zhangy:x:1000:100:,,,:/home/zhangy:/bin/bash ba:x:1002:1002::/home/zhangy:/bin/bash @zhangying::1004:1004::/home/test:/bin/bash
例c,加了-n p后表示只打印那些发生替换的行(部分替换),上面的例子,我并没有加上grep
[zhangy@BlackGhost mytest]# sed -n ‘s/root/tankzhang/p’ test tankzhang:x:0:0:root:/root:/bin/bash
例d,加了-n pg后表示只打印那些发生替换的行(全部替换),上面的例子,我并没有加上grep
[zhangy@BlackGhost mytest]# sed -n ‘s/root/tankzhang/pg’ test tankzhang:x:0:0:tankzhang:/tankzhang:/bin/bash
例e,在第二行,到第八行之间,替换以zhang开头的行,用ying来替换,并显示替换的行
[zhangy@BlackGhost mytest]# cat test | sed -ne ‘2,8s/^zhang/ying/gp’ yingy:x:1000:100:,,,:/home/zhangy:/bin/bash
例f,当有多个命令要执行时,可以用分号来分开,并且分隔符可以自定义,默认是/。上面的例子意思是在第二行,到第八行之间,替换以zhang开头的行,用ying来替换,在5,到10间,用goodbay来替换dbus,并显示替换的行
[zhangy@BlackGhost mytest]# cat test | sed -n ‘2,8s/^zhang/ying/gp;5,10s#dbus#goodbay#gp’ yingy:x:1000:100:,,,:/home/zhangy:/bin/bash goodbay:x:81:81:System message bus:/:/bin/false
例g,这个例子根上面的那个例子一样,只不过有一点不同,那就是-e来充当了分号的作用,-e也能分割多个命令。
[zhangy@BlackGhost mytest]# cat test | sed -ne ‘2,8s/zhang/ying/gp’ -ne ‘5,10s#dbus#goodbay#gp’ yingy:x:1000:100:,,,:/home/yingy:/bin/bash goodbay:x:81:81:System message bus:/:/bin/false
例h,正则的用法,在sed里面用括号的话要加上\的,不然会报错的。
[zhangy@BlackGhost mytest]# sed -ne ‘2,8s/^(zhangy)/\1ing/gp’ test zhangying:x:1000:100:,,,:/home/zhangy:/bin/bash [root@masters ~]# sed -ne ‘2,8s/^(zhangy)/&ing/gp’ test zhangying:x:1000:100:,,,:/home/zhangy:/bin/bash
例i,&的用处是,在找到的字符串后加上&后面的字符串,zhang后都加上了ying
[zhangy@BlackGhost mytest]# sed -ne ‘2,15s/zhang/&ying/gp’ test zhangyingy:x:1000:100:,,,:/home/zhangyingy:/bin/bash ba:x:1002:1002::/home/zhangyingy:/bin/bash @zhangyingying::1004:1004::/home/test:/bin/bash
例j,这个例子是说,在以zhang开头的行开始,到匹配Po的行结束,在他们之间进行替换
[zhangy@BlackGhost mytest]# sed -ne ‘/^zhang/,/Po/s/zhang/ying/gp’ test yingy:x:1000:100:,,,:/home/yingy:/bin/bash ba:x:1002:1002::/home/yingy:/bin/bash @yingying::1004:1004::/home/test:/bin/bash
例k,n;这里的n是next的缩写,找到root的行后,将其下一行的中的bin换成tank
[zhangy@BlackGhost mytest]$ sed ‘/root/{n;s/bin/tank/}’ test root:x:0:0:root:/root:/bin/bash tank:x:1:1:bin:/bin:/bin/false
例m,y的作用是将匹配的字符换成大写,不过替换字符和被替换字符长度要一样
[zhangy@BlackGhost mytest]$ sed -e ‘1,2y/root/ROOT/‘ test ROOT:x:0:0:ROOT:/ROOT:/bin/bash bin:x:1:1:bin:/bin:/bin/false
例n,h的作用是将找到的行,放到一个缓存区,G的作用是将缓存区中的内容放到最后一行
[zhangy@BlackGhost mytest]$ sed -e ‘/root/h’ -e ‘$G’ test ………………………….. ……………………….. ba:x:1002:1002::/home/zhangy:/bin/bash test:x:1003:1003::/home/test:/bin/bash @zhangying::1004:1004::/home/test:/bin/bash root:x:0:0:root:/root:/bin/bash
例o,行替换,用匹配root的行,来替换匹配zhangy的行
[zhangy@BlackGhost mytest]$ sed -e ‘/root/h’ -e ‘/zhangy/g’ test root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/false daemon:x:2:2:daemon:/sbin:/bin/false mail:x:8:12:mail:/var/spool/mail:/bin/false ftp:x:14:11:ftp:/home/ftp:/bin/false &nobody:$:99:99:nobody:/:/bin/false root:x:0:0:root:/root:/bin/bash http:x:33:33::/srv/http:/bin/false dbus:x:81:81:System message bus:/:/bin/false hal:x:82:82:HAL daemon:/:/bin/false mysql:x:89:89::/var/lib/mysql:/bin/false aaa:x:1001:1001::/home/aaa:/bin/bash root:x:0:0:root:/root:/bin/bash test:x:1003:1003::/home/test:/bin/bash root:x:0:0:root:/root:/bin/bash
例p,这个例子是说,在以zhang开头的行开始,到匹配Po的行结束,在他们之间进行替换
[zhangy@BlackGhost mytest]# sed -ne ‘/^zhang/,/Po/s/zhang/ying/gp’ test yingy:x:1000:100:,,,:/home/yingy:/bin/bash ba:x:1002:1002::/home/yingy:/bin/bash @yingying::1004:1004::/home/test:/bin/bash
例q,3q的意思是到第三行的时候,退出
[zhangy@BlackGhost mytest]$ sed -e ‘s/bin/tank/g;3q’ test root:x:0:0:root:/root:/tank/bash tank:x:1:1:tank:/tank:/tank/false daemon:x:2:2:daemon:/stank:/tank/false
例r,特殊匹配
匹配数字别忘了中括号外面还有一个中括号。 [:alnum:] 字母数字 [a-z A-Z 0-9] [:alpha:] 字母 [a-z A-Z] [:blank:] 空格或制表键 [:cntrl:] 任何控制字符 [:digit:] 数字 [0-9] [:graph:] 任何可视字符(无空格) [:lower:] 小写 [a-z] [:print:] 非控制字符 [:punct:] 标点字符 [:space:] 空格 [:upper:] 大写 [A-Z] [:xdigit:] 十六进制数字 [0-9 a-f A-F] [zhangy@BlackGhost mytest]# sed -ne ‘2,15s/zhangy.[[:digit:]]/=======/gp’ test =======:,,,:/home/zhangy:/bin/bash @=======::/home/test:/bin/bash
例2
例a,删除1,14行
[zhangy@BlackGhost test]$ sed -e ‘1,14d’ test @zhangying::1004:1004::/home/test:/bin/bash policykit:x:102:1005:Po
例b,删除4以后的行,包括第4行,把$当成最大行数就行了。
[zhangy@BlackGhost mytest]$ sed -e ‘4,$d’ test root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/false daemon:x:2:2:daemon:/sbin:/bin/false
例c,删除包括false的行,或者包括bash的行,别忘了加\
[zhangy@BlackGhost mytest]$ sed -e ‘/(false|bash)$/d’ test policykit:x:102:1005:Po
例d,删除从匹配root的行,到匹配以test开头的行,中间的行
[zhangy@BlackGhost mytest]$ sed -e ‘/root/,/^test/d’ test @zhangying::1004:1004::/home/test:/bin/bash policykit:x:102:1005:Po
例3
例a,读取test2的内容,并将其写入到匹配行的下面
[zhangy@BlackGhost mytest]$ sed -e ‘/^root/r test2’ test root:x:0:0:root:/root:/bin/bash ============= ——————- +++++++++++++ bin:x:1:1:bin:/bin:/bin/false daemon:x:2:2:daemon:/sbin:/bin/false
例b,将匹配数字的行,写入test2中
[zhangy@BlackGhost mytest]$ sed ‘/[[:digit:]]/w test2’ test
例c,将要插入的东西,插入匹配行的下面
[zhangy@BlackGhost mytest]$ sed ‘/root/a\ ===aaaa====’ test root:x:0:0:root:/root:/bin/bash ===aaaa==== bin:x:1:1:bin:/bin:/bin/false
例d,正好根a相反,将要插入的东西,插入到匹配行的上面
[zhangy@BlackGhost mytest]$ sed ‘/^daemon/i\=================’ test root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/false ================= daemon:x:2:2:daemon:/sbin:/bin/false mail:x:8:12:mail:/var/spool/mail:/bin/false
例4#取得一个文件(或目录)路径的父目录,s@@@为替换格式,(/./)是指一个”/“后面跟了任意字符又跟了一个”/“,其中()是用来把匹配内容作为一个整体后向引用,[^/]{1,}是指一个非”/“字符出现了一次,两次,或多次;/\?是指”/“出现了0次或1次,\1是后向引用前面匹配的内容 [root@practice ~]# echo “/usr/local/bin/“ |sed ‘s@(/.*/)[^/]{1,}/\?@\1@’/usr/local/ #使用扩展正则表达式后,亦可如此: [root@practice ~]# echo “/etc/rc.d/rc.sysinit” | sed -r ‘s@(/.*/)[^/]+/?@\1@’/etc/rc.d/
例5
#替换第3行的每个my为your,若没有则无替换 $ sed \”3s/my/your/g\” pets.txt #替换每行第3个my $ sed \”s/my/your/3\” pets.txt #只替换第3行的第1个my $ sed \”3s/my/your/1\” pets.txt #替换3~6行,每个my $ sed \”3,6s/my/your/g\” pets.txt#只替换每行的第2个以后的my $ sed \’s/my/your/3g\’ pets.txt
例6#注释匹配到的整行
sed -i ‘s/^[^#].*netmask/#&/‘ change_network.yml # - name: Change Application Server netmask lineinfile: dest: “{{old_inter}}” # regexp: “^NETMASK={{old_netmask}}$” # line: “NETMASK={{new_netmask}}”
awk 文本和数据进行处理的编程语言
awk命令是一种编程语言,用于在linux/unix下对文本和数据进行处理。而且它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。
语法格式:awk [参数] [文件]
-F 指定输入时用到的字段分隔符,紧跟分隔符,表示读入的字段以输入的分隔符分割
-v 进入变量模式 可以进行变量的赋值及调用(调用不需要加$符)
-f 从脚本中读取awk命令
-m 对val值设置内在限制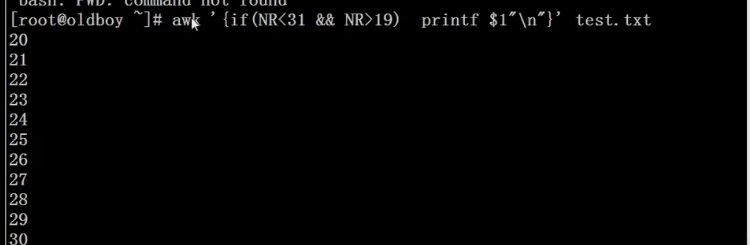
1,变量
变 量 描述
$n 当前记录的第n个字段,字段间由 FS分隔。
$0 完整的输入记录(整行)。
ARGC 命 令行参数的数目。
ARGIND 命令行中当前文件的位置(从0开始算)。
ARGV 包 含命令行参数的数组。
CONVFMT 数字转换格式(默认值为%.6g)
ENVIRON 环 境变量关联数组。
ERRNO 最后一个系统错误的描述。
FIELDWIDTHS 字 段宽度列表(用空格键分隔)。
FILENAME 当前文件名。
FNR 同 NR,但相对于当前文件。
FS 字段分隔符(默认是任何空格)。
IGNORECASE 如 果为真,则进行忽略大小写的匹配。
NF 当前记录中的字段数。$NF最后一列 $(NF-1)倒数第二列
NR 当 前记录数。行号
OFMT 数字的输出格式(默认值是%.6g)。
OFS 输 出字段分隔符(默认值是一个空格)。
ORS 输出记录分隔符(默认值是一个换行符)。
RLENGTH 由 match函数所匹配的字符串的长度。
RS 记录分隔符(默认是一个换行符)。
RSTART 由 match函数所匹配的字符串的第一个位置。
SUBSEP 数组下标分隔符(默认值是\034)。
2,运算符
运算符 描述
= += -= = /= %= ^= **= 赋值
?: C条件表达式
|| 逻 辑或
&& 逻辑与
~ !~ 匹 配正则表达式和不匹配正则表达式
< <= > >= != == 关 系运算符
空格 连接
+ - 加,减
/ & 乘,除与求余
+ - ! 一元加,减和逻辑非
^ * 求幂
++ — 增加或减少,作为前缀或后缀
$ 字 段引用
in 数组成员
3,awk的正则
匹配符 描述
\Y 匹配一个单词开头或者末尾的空字符串
\B 匹配单词内的空字符串
\< 匹配一个单词的开头的空字符串,锚定开始
> 匹配一个单词的末尾的空字符串,锚定末尾
\W 匹配一个非字母数字组成的单词
\w 匹配一个字母数字组成的单词
\’ 匹配字符串末尾的一个空字符串
\‘ 匹配字符串开头的一个空字符串
4,字符串函数
函数名 描述
sub 匹配记录中最大、最靠左边的子字符串的正则表达式,并用替换字符串替换这些字符串。如果没有指定目标字符串就默认使用整个记录。替换只发生在第一次匹配的 时候
gsub 整个文档中进行匹配
index 返回子字符串第一次被匹配的位置,偏移量从位置1开始
substr 返回从位置1开始的子字符串,如果指定长度超过实际长度,就返回整个字符串
split 可按给定的分隔符把字符串分割为一个数组。如果分隔符没提供,则按当前FS值进行分割
length 返回记录的字符数
match 返回在字符串中正则表达式位置的索引,如果找不到指定的正则表达式则返回0。match函数会设置内建变量RSTART为字符串中子字符串的开始位 置,RLENGTH为到子字符串末尾的字符个数。substr可利于这些变量来截取字符串
toupper和tolower 可用于字符串大小间的转换,该功能只在gawk中有效
5,数学函数
函数名 返回值
atan2(x,y) y,x 范围内的余切
cos(x) 余弦函数
exp(x) 求 幂
int(x) 取整
log(x) 自然对 数
rand() 随机数
sin(x) 正弦
sqrt(x) 平 方根
srand(x) x是rand()函数的种子
int(x) 取 整,过程没有舍入
rand() 产生一个大于等于0而小于1的随机数
6,format的使用
要点:
1、其与print命令的最大不同是,printf需要指定format;
2、format用于指定后面的每个item的输出格式;
3、printf语句不会自动打印换行符;\n
format格式的指示符都以%开头,后跟一个字符;如下:
%c: 显示字符的ASCII码;
%d, %i:十进制整数;
%e, %E:科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串;
%u: 无符号整数;
%%: 显示%自身;
修饰符:
N: 显示宽度;
-: 左对齐;
+:显示数值符号;
例1
测试文件test
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/bin/false
daemon:x:2:2:daemon:/sbin:/bin/false
mail:x:8:12:mail:/var/spool/mail:/bin/false
ftp:x:14:11:ftp:/home/ftp:/bin/false
&nobody:$:99:99:nobody:/:/bin/false
zhangy:x:1000:100:,,,:/home/zhangy:/bin/bash
http:x:33:33::/srv/http:/bin/false
dbus:x:81:81:System message bus:/:/bin/false
hal:x:82:82:HAL daemon:/:/bin/false
mysql:x:89:89::/var/lib/mysql:/bin/false
aaa:x:1001:1001::/home/aaa:/bin/bash
ba:x:1002:1002::/home/zhangy:/bin/bash
test:x:1003:1003::/home/test:/bin/bash
@zhangying::1004:1004::/home/test:/bin/bash
policykit:x:102:1005:Po
例a
cat test | awk -F: ‘{\
if ($1 == “root”){\
print $1;\
}else if($1 == “bin”){\
print $2;\
}else{\
print $3;\
} \
}’
例b
awk ‘{\
for(i=0;i
print $i;\
}else if($i ~/zhangy/){\
print $i;continue;\
}else if($i ~/mysql/){\
print $i;next;\
}else if($i ~/^test/){\
print $i;break;\
} \
}\
}’ test
例c
tail test | awk ‘BEGIN{while(getline d){ split(d,test);for(i in test){\
print test[i]\
}}}’
例d
ls -al /home/zhangy/mytest | awk ‘BEGIN{while(getline d){ split(d,test);\
print test[9] ;}
}’
例e
echo “32:34” |awk -F: ‘{print “max = “,max($1,$2)}\
function max(one,two){
if(one > two){
return one;
}else{
return two;
}
}’
例f
awk -F: ‘{mat=match($1,/^[a-zA-Z]+$/);print mat,RSTART,RLENGTH}’ test
例g
cat test |awk -F: ‘\
NF != 7{\
printf(“line %d,does not have 7 fields:%s\n”,NR,$0)}\
$1 !~ /^[A-Za-z0-9]/{printf(“line %d,non alpha and numeric user id:%s: %s\n”,NR,$1,$0)}\
$2 == “
例2
测试文件
[root@Blackghost test2]# cat aaa //测试文件aaa
1111:23434:zhang
hoadsf:asdf:ccc
[root@Blackghost test2]# cat ccc //测试文件ccc
1111:23434:zhang
hoadsf:asdf:ccc
tank:zhang:x20342
ying:zhasdf:72342
hosa:asdfa:2345sdf
例a
[root@Blackghost test2]# awk ‘{print NR;print FNR;print $0;}’ aaa
1 //NR
1 //FNR
1111:23434:zhang
2
2
hoadsf:asdf:ccc
例b
[root@Blackghost test2]# awk ‘{print NR;print FNR;print $0;}’ aaa ccc
1
1
1111:23434:zhang
2 //NR
2 //FNR
hoadsf:asdf:ccc
3 //NR
1 //FNR 下面的数据是来自ccc,所以NFR重置为1
1111:23434:zhang
4
2
hoadsf:asdf:ccc
5
3
tank:zhang:x20342
6
4
ying:zhasdf:72342
7
5
hosa:asdfa:2345sdf
例3
只显示出现过一次的记录
# cat aaa
59314
46791
59992
60311
60134
59992
60311
97343
# cat aaa | awk ‘!a[$1]++’
59314
46791
59992
60311
60134
97343
例4
#输出/etc/passwd中关于root的第二个位置的内容
# cat /etc/passwd |grep root |awk -F ‘:’ ‘{print $2}’
例5
处理前:
[root@practice ~]# ip addr show
1: lo: mtu 16436 qdisc noqueue
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet 10.99.133.33/32 scope global lo
2: eth2: mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 0:1b:21:48:3e:b3 brd ff:ff:ff:ff:ff:ff
inet 172.20.33.44/23 brd 172.20.33.255 scope global eth2
3: eth3: mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:1b:31:39:3e:2c brd ff:ff:ff:ff:ff:ff
4: eth0: mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:25:29:09:8e:f2 brd ff:ff:ff:ff:ff:ff
inet 228.215.154.140/26 brd 228.215.154.191 scope global eth0
5: eth1: mtu 1500 qdisc pfifo_fast qlen 1000
link/ether 00:25:09:09:8e:f3 brd ff:ff:ff:ff:ff:ff
inet 228.215.154.150/26 brd228.215.154.191 scope global eth1
处理后
[root@practice ~]# ip addr show | awk ‘BEGIN{FS=”[/ ]+”;OFS=” — “}$2~”eth”{$3~”NO-CARRIER”?a=0:a=1}$NF~”eth”&&a{print $NF,$3}’
eth2 — 172.20.33.44
eth0 — 228.215.154.140
eth1 — 228.215.154.150
获取本机上网络接口上可用的公网IP地址
BEGIN{FS=”[/ ]+”;OFS=” — “} 是指把一个或多个空格或者/作为读取文本时的字段分隔符,把” — “作为执行完后的输出字段分隔符
$2~”eth”{$3~”NO-CARRIER”?a=0:a=1}找到第二个字段匹配到”eth”的行并判断第三个字段是否匹配到”NO-CARRIER”,匹配到则a=0,否则a=1
$NF~”eth”&&a将最后一个字段和a相与,结果为真则打印最后一个字段和第三个字段,否则不处理
例6
awk取出last命令结果中非空行中的每
[root@practice ~]# last |awk ‘$0!=””&&$2!~”boot”&&$3~”[[:digit:]]”{ips[$3]++}END{for(i in ips)printf “%18-s%10-d\n”,i,ips[i]}’
172.20.33.1 1
172.20.33.95 7
192.168.2.100 6
192.168.2.101 3
172.20.33.26 1
192.168.2.102 8
172.20.32.123 7
192.168.140.1 2
172.20.33.93 1
&&表示 且,与
$0!=””表示排除结果中的空行
$2!~”boot”表示排除重启的记录
$3~”[[:digit:]]表示第三个字段匹配数字而不是字符
{ips[$3]++}表示把第三个字段即IP地址作为下标,组成一个数组ips,IP地址每出现一次,其出现次数累加一
END{for(i in ips)printf “%18-s%10-d\n”,i,ips[i]}
表示从数组中获取每个IP地址,及其出现的次数,并定义对齐方式和变量类型打印出来
例7
#将passwd中的第三列放到test中
[root@localhost ~]# awk -F: ‘{if(NR>=10 && NR<=20) print $3 }’ /etc/passwd > test
You have mail in /var/spool/mail/root
[root@localhost ~]# cat test
10
11
12
13
14
99
81
113
69
32
499
例8
[root@xuegod68 mnt]# head -5 2.txt
10.0.0.3 —[21/Mar/2015-07:50:17+0800]GET/HTTP/1.1200 19 -
10.0.0.3 —[21/Mar/2015-07:50:17+0800]GET/HTTP/1.1200 19 -
10.0.0.5 —[21/Mar/2015-07:50:17+0800]GET/HTTP/1.1200 19 -
10.0.0.3 —[21/Mar/2015-07:50:17+0800]GET/HTTP/1.1200 19 -
10.0.0.6 —[21/Mar/2015-07:50:17+0800]GET/HTTP/1.1200 19 -
[root@xuegod68 mnt]# awk ‘{array[$1]++} END {for(key in array) printkey,array[key]}’ 2.txt
10.0.0.3 35
10.0.0.4 5
10.0.0.5 10
10.0.0.6 10
例9**
#将UID大于等于500的用户及UID打印出来
[root@localhost ~]# awk -F: ‘$3>=500 {print $1,$3}’ /etc/passwd
nfsnobody 65534
admin 502
test 503
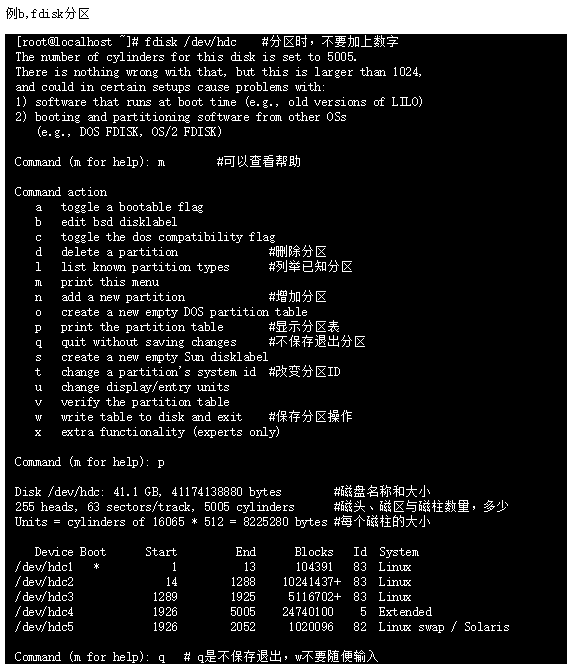
fdisk磁盘分区
-v 打印 fdisk 的版本信息并退出.
-l 列出指定设备的分区表信息并退出。 如果没有给出设备,那么使用那些在 /proc/partitions (如果存在)提到的.
-u 以扇区数而不是以柱面数的形式显示分区表中各分区的信息. -s 分区 将分区的 大小 (单位为块)信息输出到标准输出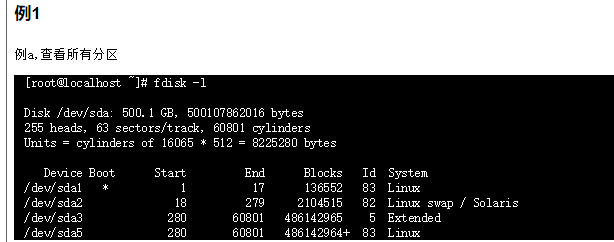
du 查看磁盘空间使用情况
du [-abcDhHklmsSx] [-L <符号连接>][-X <文件>][—block-size][—exclude=<目录或文件>] [—max-depth=<目录层数>][—help][—version][目录或文件
-a, —all 显示对所有文件的统计,而不只是包含子目录。
-b, —bytes 输出以字节为单位的大小,替代缺省时1024字节的计数单位。
—block-size=size 输出以块为单位的大小,块的大小为 size 字节。( file- utils-4.0 的新选项)
-c, —total 在处理完所有参数后给出所有这些参数的总计。这个选项被 用给出指定的一组文件或目录使用的空间的总和。
-D, —dereference-args 引用命令行参数的符号连接。但不影响其他的符号连接。 这对找出象 /usr/tmp 这样的目录的磁盘使用量有用, /usr/tmp 等通常是符号连接。 译住:例如在 /var/tmp 下建立一个目录test, 而/usr/tmp 是指向 /var/tmp 的符号连接。du /usr/tmp 返回一项 /usr/tmp , 而 du - D /usr/tmp 返回两项 /usr/tmp,/usr/tmp/test。
—exclude=pattern 在递归时,忽略与指定模式相匹配的文件或子目录。模式 可以是任何 Bourne shell 的文件 glob 模式。( file- utils-4.0 的新选项)
-h, —human-readable 为每个数附加一个表示大小单位的字母,象用M表示二进制 的兆字节。
-H, —si 与 -h 参数起同样的作用,只是使用法定的 SI 单位( 用 1000的幂而不是 1024 的幂,这样 M 代表的就是1000000 而不是 1048576)。(fileutils-4.0 的新选项)
-k, —kilobytes 输出以1024字节为计数单位的大小。
-l, —count-links 统计所有文件的大小,包括已经被统计过的(作为一个硬连接)。
-L, —dereference 引用符号连接(不是显示连接点本身而是连接指向的文件或 目录所使用的磁盘空间)。
-m, —megabytes 输出以兆字节的块为计数单位的大小(就是 1,048,576 字节)。
—max-depth=n 只输出命令行参数的小于等于第 n 层的目录的总计。 —max-depth=0的作用同于-s选项。(fileutils-4.0的新选项)
-s, —summarize 对每个参数只显示总和。
-S, —separate-dirs 单独报告每一个目录的大小,不包括子目录的大小。
-x, —one-file-system 忽略与被处理的参数不在同一个文件系统的目录。
-X file, —exclude-from=file 除了从指定的文件中得到模式之外与 —exclude 一样。 模式以行的形式列出。如果指定的文件是’-‘,那么从标准输 入中读出模式。(fileutils-4.0 的新选项) GNU 标准选项
—help 在标准输出上输出帮助信息后正常退出。
—version 在标准输出上输出版本信息后正常退出。
du -sh [目录名]:返回该目录的大小 例子 du -sh 查询本目录下文件大小
du -sm [文件夹]:返回该文件夹总M数
du -sh xmldb/:查看linux文件目录的大小和文件夹包含的文件数 统计总数大小
du -sm | sort -n:统计当前目录大小 (单位m) 并按 大小 排序
du -sk | sort -n:统计当前目录大小 (单位k) 并按 大小 排序
du -sk | grep XXX:看一个(xxx)文件的大小
du -m:查看该目录下所有文件
du -m | cut -d “/” -f 2:
看第二个 查看此文件夹有多少文件 /// 有多少文件 bin conf
du xxx/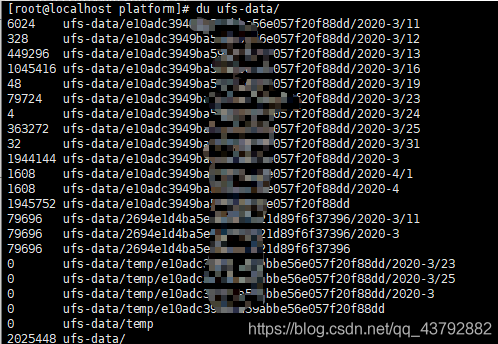
du xxx/ |wc -l
解释: wc [-lmw] 参数说明:-l :多少行;-m:多少字符;-w:多少字 xxx目录下查询出来有几个行


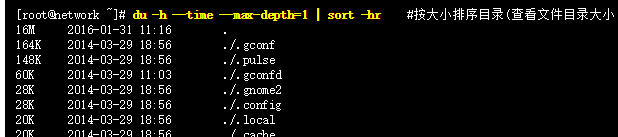
sort命令 – 排序文件并输出
sort [参数] [文件]
| -b | 忽略每行前面开始出的空格字符 |
|---|---|
| -c | 检查文件是否已经按照顺序排序 |
| -d | 排序时,处理英文字母、数字及空格字符外,忽略其他的字符 |
| -f | 排序时,将小写字母视为大写字母 |
| -i | 排序时,除了040至176之间的ASCII字符外,忽略其他的字符 |
| -m | 将几个排序号的文件进行合并 |
| -M | 将前面3个字母依照月份的缩写进行排序 |
| -n | 依照数值的大小排序 |
| -o <输出文件> | 将排序后的结果存入制定的文件 |
| -r | 以相反的顺序来排序 |
| -t <分隔字符> | 指定排序时所用的栏位分隔字符 |
| -k | 指定需要排序的栏位 |
[root@www ~]# cat /etc/passwd | sort #sort 是默认以第一个数据来排序,而且默认是以字符串形式来排序,所以由字母 a 开始升序排序。 [root@www ~]# cat /etc/passwd | sort -t ‘:’ -k 3 #/etc/passwd 内容是以 : 来分隔的,我想以第三栏来排序,该如何 [root@www ~]# cat /etc/passwd | sort -t ‘:’ -k 3n #用数字排序,默认是以字符串来排序的 [root@www ~]# cat /etc/passwd | sort -t ‘:’ -k 3nr #倒序排列,默认是升序排序 [root@www ~]# cat /etc/passwd | sort -t’:’ -k 6.2,6.4 -k 1r #对/etc/passwd,先以第六个域的第2个字符到第4个字符进行正向排序,再基于第一个域进行反向排序 [root@www ~]# cat /etc/passwd | sort -t’:’ -k 7 -u #查看/etc/passwd有多少个shell:对/etc/passwd的第七个域进行排序,然后去重
usermod
修 改 使 用 者 帐 号
-a append 把用户追加到某些组中,仅与-G选项一起使用
-c comment 更 新 使 用 者 帐 号 password 档 中 的 注 解 栏 , 一 般 是 使 用 chfn(1) 来 修 改 。
-d home_dir 更 新 使 用 者 新 的 登 入 目 录 。 如 果 给 定 -m 选 项 , 使 用 者 旧 目 录 会 搬 到 新 的 目 录 去 ,如 旧 目 录 不 存 在 则 建 个 新 的 。
-e expire_date 加 上 使 用 者 帐 号 停 止 日 期 。 日 期 格 式 为 MM/DD/YY.
-f inactive_days 帐 号 过 期 几 日 后 永 久 停 权。当 值 为 0 时 帐 号 则 立 刻 被 停 权 。 而 当 值 为 -1 时 则 关闭此功能 。预 设 值 为 -1。
-g initial_group 更 新 使 用 者 新 的 起 始 登 入 群 组 。 群 组 名 须 已 存 在 。群 组 ID 必 须 参 照 既 有 的 的 群 组 。 群 组 ID 预 设 值 为 1 。
-G group,[…] 定 义 使 用 者 为 一 堆 groups 的 成 员 。 每 个 群 组 使 用 “,” 区 格 开 来 , 不 可 以 夹 杂 空 白 字 元 。 群 组 名 同 -g 选 项 的 限 制 。 如 果 使 用 者 现 在 的 群 组 不 再 此 列 , 则 将 使 用 者 由 该 群 组 中 移 除 。
-l login_name 变 更 使 用 者 login 时 的 名 称 为 login_name 。 其 于 不 变 。 特 别 是 , 使 用 者 目 录 名 应 该 也 会 跟 着 更 动 成 新 的 登 入 名 。
-s shell 指 定 新 登 入 shell 。 如 此 栏 留 白 , 系 统 将 选 用 系 统 预 设 shell 。
-L 锁定一个用户的帐号. 这个操作是放一个感叹号在你的密码前,禁用密码.你不能配合-p或-U使用.
-U 解锁一个用户的帐号.这个操作是在加密密码前取消感叹号,恢复帐号登录.你不能配合-p或-L使用.
-u uid 使 用 者 ID 值 。必 须 为 唯 一 的 ID 值 , 除 非 用 -o 选 项 。 数 字 不 可 为 负 值。预 设 为 最 小 不 得 小 于 999 而 逐 次 增 加 。 0~ 999 传 统 上 是 保 留 给 系 统 帐 号 使 用 。 使 用 者 目 录 树 下 所 有 的 档 案 目 录 其 user ID 会 自 动 改 变 。 放 在 使 用 者 目 录 外 的 档 案 则 要 自 行 手 动 更 动 。
[root@Blackghost ~] usermod -d /home/bak/ zhangying #更改用户home目录 [root@Blackghost ~] usermod -e 05/06/13 zhangying #给用户加个有效期
1、将 newuser2 添加到组 staff 中
# usermod -G staff newuser2
2、修改 newuser 的用户名为 newuser1
# usermod -l newuser1 newuser
3、锁定账号 newuser1
# usermod -L newuser1
4、解除对 newuser1 的锁定
# usermod -U newuser1
# usermod -a -G groupA user #将用户user添加到用户组groupA 中,同时不离开其他用户组
# usermod -u 777 tank #改变用户的uid
id命令 – 显示用户ID和组ID
-g 显示用户所属群组的ID
-G 显示用户所属附加群组的ID
-n 显示用户,所属群组或附加群组的名称
-r 显示实际ID
-u 显示用户ID
—help 显示帮助
—version 显示版本信息
rpm命令 – RPM软件包管理器
-a 查询所有的软件包
-b或-t 设置包装套件的完成阶段,并指定套件档的文件名称;
-c 只列出组态配置文件,本参数需配合”-l”参数使用
-d 只列出文本文件,本参数需配合”-l”参数使用
-e或—erase 卸载软件包
-f 查询文件或命令属于哪个软件包
-h或—hash 安装软件包时列出标记
-i 显示软件包的相关信息
—install 安装软件包
-l 显示软件包的文件列表
-p 查询指定的rpm软件包
-q 查询软件包
-R 显示软件包的依赖关系
-s 显示文件状态,本参数需配合”-l”参数使用
-U或—upgrade 升级软件包
-v 显示命令执行过程
-vv 详细显示指令执行过程
-h (or —hash) 安装时输出hash记号 (`#'')<br />[root@localhost ~]# rpm -ivh ipchains-1.3.6-1.i386.rpm #安装包,并显示详细进度<br />[root@localhost ~]# rpm -i ftp://ftp.xxx.xxx #在线安装<br />[root@localhost ~]# rpm -Va #校验所有的rpm包,查找丢失的文件<br />[root@localhost ~]# rpm -qf /usr/bin/who #查找一个文件属于哪个rpm包<br />[root@localhost ~]# rpm -qpi mon-0.37j-1.i386.rpm #列出一个rpm包的描述信息<br />[root@localhost ~]# rpm -qpl mon-0.37j-1.i386.rpm #列出一个rpm包的文件信息<br />[root@localhost ~]# rpm -Uvh ipchains-1.3.6-1.i386.rpm #升级包<br />[root@localhost ~]# rpm -q httpd #查看httpd的安装包<br />[root@localhost ~]# rpm -e httpd #移除安装包<br />[root@localhost ~]# rpm -qi httpd #得到httpd安装包的信息<br />Name : httpd Relocations: (not relocatable)<br />Version : 2.2.3 Vendor: CentOS<br />Release : 45.el5.centos.1 Build Date: 2011年05月04日 星期三 18时54分56秒<br />Install Date: 2011年06月29日 星期三 08时05分34秒 Build Host: builder10.centos.org<br />Group : System Environment/Daemons Source RPM: httpd-2.2.3-45.el5.centos.1.src.rpm<br />Size : 3281960 License: Apache Software License<br />Signature : DSA/SHA1, 2011年05月04日 星期三 20时31分28秒, Key ID a8a447dce8562897<br />URL : [http://httpd.apache.org/](http://httpd.apache.org/)<br />Summary : Apache HTTP 服务器<br />Description :<br />The Apache HTTP Server is a powerful, efficient, and extensible<br />web server.<br />[root@localhost ~]# rpm -ql httpd #列出httpd中有哪些文件<br />[root@localhost ~]# rpm -qa #列出所有已安装的包<br />[root@test ~]# **rpm -qf which iostat `** #查询iostat命令归属的软件包
mysqldump命令 – MySQL数据库备份
mysqldump命令是MySQL数据库中备份工具,用于将MySQL服务器中的数据库以标准的sql语言的方式导出,并保存到文件中。
语法格式: mysqldump [参数]
— -add-drop-table 在每个创建数据库表语句前添加删除数据库表的语句
— -add-locks 备份数据库表时锁定数据库表
— -all-databases 备份MySQL服务器上的所有数据库
— -comments 添加注释信息
— -compact 压缩模式,产生更少的输出
— -complete-insert 输出完成的插入语句
— -databases 指定要备份的数据库
— -default-character-set 指定默认字符集
— -force 当出现错误时仍然继续备份操作
— -host 指定要备份数据库的服务器
— -lock-tables 备份前,锁定所有数据库表
— -no-create-db 禁止生成创建数据库语句
— -no-create-info 禁止生成创建数据库库表语句
— -password 连接MySQL服务器的密码
— -port MySQL服务器的端口号
— -user 连接MySQL服务器的用户名
1、备份命令
格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 —database 数据库名 > 文件名.sql
例如: mysqldump -h 192.168.1.100 -p 3306 -uroot -ppassword —database cmdb > /data/backup/cmdb.sql
2、备份压缩
导出的数据有可能比较大,不好备份到远程,这时候就需要进行压缩
格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 —database 数据库名 | gzip > 文件名.sql.gz
例如: mysqldump -h192.168.1.100 -p 3306 -uroot -ppassword —database cmdb | gzip > /data/backup/cmdb.sql.gz
3、备份同个库多个表
格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 —database 数据库名 表1 表2 …. > 文件名.sql
例如 mysqldump -h192.168.1.100 -p3306 -uroot -ppassword cmdb t1 t2 > /data/backup/cmdb_t1_t2.sql
4、同时备份多个库
格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 —databases 数据库名1 数据库名2 数据库名3 > 文件名.sql
例如:mysqldump -h192.168.1.100 -uroot -ppassword —databases cmdb bbs blog > /data/backup/mutil_db.sql
5、备份实例上所有的数据库
格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 —all-databases > 文件名.sql
例如:mysqldump -h192.168.1.100 -p3306 -uroot -ppassword —all-databases > /data/backup/all_db.sql
6、备份数据出带删除数据库或者表的sql备份
格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 —add-drop-table —add-drop-database 数据库名 > 文件名.sql
例如:mysqldump -uroot -ppassword —add-drop-table —add-drop-database cmdb > /data/backup/all_db.sql
7、备份数据库结构,不备份数据
格式:mysqldump -h主机名 -P端口 -u用户名 -p密码 —no-data 数据库名1 数据库名2 数据库名3 > 文件名.sql
例如:mysqldump —no-data –databases db1 db2 cmdb > /data/backup/structure.sql
导出整个数据库:
[root@linuxcool ~]# mysqldump -u linuxcool -p smgp_apps_linuxcool > linuxcool.sql
导出数据库中的一个表:
[root@linuxcool ~]# mysqldump -u linuxcool -p smgp_apps_linuxcool users > linuxcool_users.sql
导出一个数据库结构:
[root@linuxcool ~]# mysqldump -u linuxcool -p -d —add-drop-table smgp_apps_linuxcool > linuxcool_db.sql
1、导出
命令:mysqldump -u用户名 -p数据库密码 数据库名 > 文件名
如果用户名需要密码,则需要在此命令执行后输入一次密码核对;如果数据库用户名不需要密码,则不要加“-p”参数,导入的时候相同。注意输入的用户名需要拥有对应数据库的操作权限,否则无法导出数据。由于是作系统维护和全部数据库的导出,一般我们使用root等超级用户权限。
比如要将abc这个数据库导出为一个文件名为db_abc.sql的数据库文件到当前目录下,则输入下面的命令:
mysqldump -uroot -ppassword abc >db_abc.sql
如果要直接导出sql.zip或者gzip格式文件命令如下:
mysqldump -uroot -ppassword abc >gzip > db_abc.sql.gzip
需要注意的是:-u和-p后面直接跟用户名和密码,不要有空格。
2、导入
命令:mysql -u用户名 -p数据库密码 数据库名 < 文件名 同mysqldump命令一样的用法,各参数的意义同mysqldump。 比如我们要将/root/backup/db_abc.sql这个文件的数据导入到abc数据库中,则使用下面的命令:
mysql -uroot -ppassword abc < /root/backup/db_abc.sql
如果是zip或gzip格式则使用下面的命令:
mysql -uroot -ppassword abc
mysqldump -hhostname -uusername -ppassword databasename > backupfile.sql
备份MySQL数据库为带删除表的格式备份MySQL数据库为带删除表的格式,能够让该备份覆盖已有数据库而不需要手动删除原有数据库。
mysqldump —-add-drop-table -uusername -ppassword databasename > backupfile.sql
直接将MySQL数据库压缩备份
mysqldump -hhostname -uusername -ppassword databasename | gzip > backupfile.sql.gz
备份MySQL数据库某个(些)表
mysqldump -hhostname -uusername -ppassword databasename specific_table1 specific_table2 > backupfile.sql
同时备份多个MySQL数据库
mysqldump -hhostname -uusername -ppassword —databases databasename1 databasename2 databasename3 > multibackupfile.sql
仅仅备份数据库结构
mysqldump —no-data —databases databasename1 databasename2 databasename3 > structurebackupfile.sql
备份服务器上所有数据库
mysqldump —all-databases allbackupfile.sql
还原MySQL数据库的命令
mysql -hhostname -uusername -ppassword databasename < backupfile.sql
还原压缩的MySQL数据库
gunzip < backupfile.sql.gz | mysql -uusername -ppassword databasename
将数据库转移到新服务器
1、首先在新的服务器上创建数据库,create database newdatabase;
2、mysqldump -uusername -ppassword olddatabasename | mysql -hhostname -uuserbname –ppassword newdatabasename
4、总结一下压缩备份
备份并用gzip压缩:mysqldump < mysqldump options> | gzip > outputfile.sql.gz
从gzip备份恢复:gunzip < outputfile.sql.gz | mysql < mysql options>
备份并用bzip压缩:mysqldump < mysqldump options> | bzip2 > outputfile.sql.bz2
从bzip2备份恢复:bunzip2 < outputfile.sql.bz2 | mysql < mysql options>
seq 命令 – 打印数字序列
seq命令可以输出连续的数字,或者输出固定间隔的数字,或者输出指定格式的数字,这样说比较模糊,看示例就很容易理解。
-s 指定输出的分隔符,默认为\n,即默认为回车换行
-w 指定为定宽输出,不能和-f一起用
-f 按照指定的格式输出,不能和-w一起使用
常用选项示例:
-s选项:指定分隔符,下图示例为指定加号为分隔符,输出的数字将会使用”+”连接,默认情况下回车换行(\n)为分隔符。
使用如下方法可以使用制表符(\t)作为分隔符,相当于我们键盘上的tab键。
注意:上图示例中使用了命令替换,也就是说,先使用echo命令输出制表符,然后用输出的制表符作为seq命令输出数字的连接符。
-w 选项:指定为定宽输出,例如下图,最大值为11,是两位数,那么不到两位的数前面自动用0补全,当然,如果指定的位数最大为三位数字,那么一位数和两位数前面的位数都会用0补全,也就是说,以最大值的位数为标准宽度,不足标准宽度的数字将会用0补位,示例如下图。
-f选项:按照指定的格式输出生成的数字,在没有使用-f选项指定格式时,默认格式为%g,可以理解为使用-f 指定模式为”%g”,跟不指定格式没有任何区别。
上述示例中,输出的数字没有任何区别,因为在不指定格式的情况下,默认格式为’%g’
那么除了上述的默认格式,我们经常还会使用如下常用格式,”%3g”这种格式表示指定”位宽”为三位,那么数字位数不足部分用空格补位,如下示例中,编号1对应的命令使用的格式为默认格式,与不指定任何格式输出的结果相同,编号2对应的命令使用的格式表示输出的数字位宽固定为3位,不足三位的数字用空格在数字左侧补齐。
“%02g” 表示指定位宽为两位,数字位数不足用0补位,这种写法跟上述提到的-w选项类似,只不过-w是以指定的最大值的位数为最大位数,而 -f 选项可以直接指定位数,在下例中,我们也对比了-w选项与-f选项的区别。
上述例子中的格式中,都包含一个’%’,其实 % 前面还可以指定字符串。
例如在屏幕上打印5个名为dir1 , dir2 .. dir5 的字符串,这时候就用到这种写法。
所以,结合上述示例中的seq命令的特性,再结合其他命令,就能为我们带来许多方便。
例如一次性创建5个名为dir001 , dir002 .. dir005 的目录,这时候就用到这种写法。
mkdir $(seq -f ‘dir%03g’ 1 10)
或者如下命令,与上述命令的效果相同。
例1:
# seq 1 10
结果是1 2 3 4 5 6 7 8 9 10
例2:
#!/bin/bash
for i in seq 1 10
do
echo $i
done
或者
for i in $(seq 1 10)
意思是打印三位不足的地方以0填补,在前面加上str
# seq -w -f “str%03g” 9 11
seq: 当输出等宽字符串时不应再指定格式字符串,-w与-f不能一起用
Try ‘seq —help’ for more information.
# seq -w 9 11
输出是同宽的
# seq -s “ “ -f “str%03g” 9 11
结果:str009 str010 str011
-s 指定分隔符,默认是回车
# seq -s “ echo -e "\t"“ 9 11
结果:9 10 11
先用命令做成一个tab,然后再指定成分隔符
#seq 0 100 >test.txt
使用seq命令将0-100打印到test.txt文件中
rz从windows上传文件
sz从Windows下载文件
rz -y sz -y (-y表示覆盖原有的文件)
用此命令之前得现装软件。
yum install lrzsz -y
uname命令 – 显示系统信息
-a 显示系统所有相关信息
-m 显示计算机硬件架构
-n 显示主机名称
-r 显示内核发行版本号
-s 显示内核名称
-v 显示内核版本
-p 显示主机处理器类型
-o 显示操作系统名称
-i 显示硬件平台
PS1环境变量控制每个命令头标识:

su 切换用户
(一定加“-”表示将当前环境变量切换过去) 
不加“-”,用户切换过去,看home目录还是之前用户的家目录
ssh命令 – 安全连接客户端
-1 强制使用ssh协议版本1
-2 强制使用ssh协议版本2
-4 强制使用IPv4地址
-6 强制使用IPv6地址
-A 开启认证代理连接转发功能
-a 关闭认证代理连接转发功能
-b
-C 请求压缩所有数据
-F<配置文件> 指定ssh指令的配置文件,默认的配置文件为“/etc/ssh/ssh_config”
-f 后台执行ssh指令
-g 允许远程主机连接本机的转发端口
-i<身份文件> 指定身份文件(即私钥文件)
-l<登录名> 指定连接远程服务器的登录用户名
-N 不执行远程指令
-o<选项> 指定配置选项
-p<端口> 指定远程服务器上的端口
-q 静默模式,所有的警告和诊断信息被禁止输出
-X 开启X11转发功能
-x 关闭X11转发功能
-y 开启信任X11转发功能
例1:
[root@localhost www]# ssh 192.168.1.108 #当前用户登录远程主机
[root@localhost www]# ssh 192.168.1.108 -l tank #以tank用户登录远程主机
[root@localhost www]# ssh tank@192.168.1.108 -p 2222 #指定端口登录
[root@localhost www]# ssh -D 7575 tank@192.168.1.108 #通过代理登录
例2
[root@red2 .ssh]# ssh 192.168.1.2 date #远程执行命令
Sun Jul 29 14:07:32 EDT 2001
[root@red1 ~]# ssh-copy-id -i .ssh/id_rsa.pub 10.90.0.136 #发送公钥
find命令 – 查找和搜索文件
-iname 忽略大小写
-exec find命令对匹配的文件执行该参数所给出的其他linux命令。相应命令的形式为’ 命令 - and’ {} \;,注意{ }和\;之间的空格。
-ok 和- exec的作用相同,只不过和会人交互而已,OK执行前会向你确认是不是要执行。
find命令主要参数:
-perm 按照文件权限来查找文件。
-prune 使用这一选项可以使find命令不在当前指定的目录中查找,如果同时使用了- depth选项,那么-prune选项将被find命令忽略。
-group 按照文件所属的组来查找文件。
-mtime -n +n 按照文件的更改时间来查找文件, -n表示文件更改时间距现在n天以内,+n表示文件更改时间距现在n天以前。find命令还有-atime和-ctime选项,但它们都和-mtime选项
相似,所以我们在这里只介绍-mtime选项。
-nogroup 查找无有效所属组的文件,即该文件所属的组在/etc/groups中不存在。
-nouser 查找无有效属主的文件,即该文件的属主在/etc/passwd中不存在。
-newer file1 ! file2 查找更改时间比文件file1新但比文件file2旧的文件。
-type 查找某一类型的文件,诸如:
b - 块设备文件。
d - 目录。
c - 字符设备文件。
p - 管道文件。
l - 符号链接文件。
f - 普通文件。
s - socket文件
-size n[cwbkMG] : 文件大小 为 n 个由后缀决定的数据块。其中后缀为:
b: 代表 512 位元组的区块(如果用户没有指定后缀,则默认为 b)
c: 表示字节数
k: 表示 kilo bytes (1024字节)
w: 字 (2字节)
M:兆字节(1048576字节)
G: 千兆字节 (1073741824字节)
-depth 在查找文件时,首先查找当前目录中的文件,然后再在其子目录中查找。
-delete (删除)
-maxdepth 查找最大目录层数 如 1,即只查找一层目录
-fstype 查找位于某一类型文件系统中的文件,这些文件系统类型通常可以在配置文件
/etc/fstab中找到,该配置文件中包含了本系统中有关文件系统的信息。
-mount 在查找文件时不跨越文件系统mount点。
-follow 如果find命令遇到符号链接文件,就跟踪至链接所指向的文件。
-cpio 对匹配的文件使用cpio命令,将这些文件备份到磁带设备中。
-o 是或者的意思
-a 是而且的意思
-not 是相反的意思
-empty 搜索空文件或空目录
例子:
a.通过名字来查找: 2347-1270=1077 1653+1500
[zhangy@BlackGhost ~]$ find ~ -name memcached.pid -print #查找home目录下文件名为memcache.pid的文件
/home/zhangy/memcached/memcached.pid
[zhangy@BlackGhost ~]$ find . -name “.pid” -print #.代表当前目录,查找所有以pid结尾的文件
./memcached/memcached.pid
./.tencent/qq/95219454.pid
[zhangy@BlackGhost ~]$ find ~ -name “[0-9].pid” -print #查找以数字开头的所有pid文件,在这里要说[0-9]不能匹配23,它跟一般的语言类正则不太一样,shell里面的*可以代表一切字符(单个,多个都行),如果想匹配2345只能这样写[0-9][0-9][0-9][0-9]
/home/zhangy/.tencent/qq/95219454.pid
[zhangy@BlackGhost ~]$ find /home/zhangy/.tencent/ -name “[0-9].pid” -print #在.tencent文件夹下面找pid文件
/home/zhangy/.tencent/qq/95219454.pid
b,通过文件权限来查找
[zhangy@BlackGhost css]$ find ~ -perm 755 -print |more #~代表的是$home目录,查找权限为755的文件
/home/zhangy/www/css2/ctextshadow.html
/home/zhangy/www/css2/c_textautospace.html
[zhangy@BlackGhost css]$ find . -perm 700 -name “u“ -print |more #查找所有以产u_开头的,并且权限为700的文件
./css2/u_length_cm.html
./css2/u_length_px.html
c,prune来忽略目录来查找
[zhangy@BlackGhost download]$ find . -name “.gz” -prune -o ( ! -name aaa ) -print #查找在前目录中,不在以aaa结尾的目录中的,不以gz结尾的文件
.
./eaccelerator-0.9.5.3.tar
./fix-crash-in-excerpts.patch
./AddFeed_Widget_WordPress_Plugin.zip
./jQuery china-addthis plugin 1.07.rar
d,根据文件类型来查找文件
[zhangy@BlackGhost download]$ find . -type d -print #查找当前目录下面的目录
.
./ddd
[zhangy@BlackGhost download]$ find . ! -type d -print #找当前目录下面的非目录文件
./eaccelerator-0.9.5.3.tar
./haproxy-1.3.15.7.tar.gz
./fix-crash-in-excerpts.patch
e,根据文件所属用户和用户组来找文件
[zhangy@BlackGhost download]$ find . -nouser -print #查找当前目录中,没有归属的文件
[zhangy@BlackGhost download]$ find /home/zhangy/download -user zhangy -group users -print #查找用户组为users,所属用户为zhangy的文件
/home/zhangy/download
/home/zhangy/download/eaccelerator-0.9.5.3.tar
/home/zhangy/download/haproxy-1.3.15.7.tar.gz
f,根文件大小来查找
[zhangy@BlackGhost download]$ find /home/zhangy/download -size +1000000c -print #查找文件大小大于1000000字符的文件,注意+号表示大于
/home/zhangy/download/eaccelerator-0.9.5.3.tar
/home/zhangy/download/mmseg-0.7.3.tar.gz
[zhangy@BlackGhost download]$ find /home/zhangy/download -size -10 -print #查找文件大小小于10块的文件,注意-号表示小于,一块等于512b
/home/zhangy/download
/home/zhangy/download/fix-crash-in-excerpts.patch
/home/zhangy/download/test.sql.zip
g,根文件的修改时间来查找
[zhangy@BlackGhost download]$ find /home/zhangy -mtime -5 -print #5天修改过的文件,- 表示以内
/home/zhangy/www/css2/c_textshadow.html
/home/zhangy/www/css2/c_textautospace.html
[zhangy@BlackGhost download]$ find /home/zhangy -mtime +5 -print #查找5天前修改过的文件,+表示以前
/home/zhangy/www/test.php
[root@vmx14420 www]# find ./ -mmin -5 -print #查找5分钟以内修改过的文件
./cache/index.html
h,exec解释
[zhangy@BlackGhost download]$ find . -type f -size +1000000c -exec ls -al {} \; #显示当前目录下面所有大于1000000的文件,exec后面执行了一个命令,{}这个代表文件名
-rw-r—r— 1 zhangy users 3624960 2009-03-08 ./eaccelerator-0.9.5.3.tar
-rw-r—r— 1 zhangy users 3091711 12-18 13:48 ./mmseg-0.7.3.tar.gz
-rw-r—r— 1 zhangy users 1191330 2009-06-26 ./pcre-7.9.tar.gz
i,匹配
[tank@localhost workspace]$ find ./database/ -name ‘.sql’ -print #查找以sql结尾的文件
./database/28toplearning.sql
[tank@localhost workspace]$ find ./database/ -name ‘.sql‘ -print #查找文件名包括sql文件
./database/28toplearning.sql
[tank@localhost workspace]$ find ./database/ -name ‘28‘ -print #查找以28开头的文件
./database/28toplearning.sql
diff命令 – 比较文件的差异
-a diff预设只会逐行比较文本文件
-b 不检查空格字符的不同
-W 在使用-y参数时,指定栏宽
-x 不比较选项中所指定的文件或目录
-X 您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件
-y 以并列的方式显示文件的异同之处
—help 查看帮助信息
—left-column 在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容
—suppress-common-lines 在使用-y参数时,仅显示不同之处
-行数(一个整数)
显示上下文 行数 (一个整数). 这个选项自身没有指定输出格式,这是没有效果的,除非和 -c 或者 -u 组合使用. 这是已废置的选项,对于正确的操作, 上下文至少要有两行。
-a 所有的文件都视为文本文件来逐行比较,甚至他们似乎不是文本文件.
-b 忽略空格引起的变化.
-B 忽略插入删除空行引起的变化.
-c 使用上下文输出格式.
-C 行数(一个整数)
—context[=lines]
使用上下文输出格式,显示以指定 行数 (一个整数), 或者是三行(当 行数 没有给出时. 对于正确的操作, 上下文至少要有两行.
-d 改变算法也许发现变化的一个更小的集合.这会使 diff 变慢 (有时更慢).
-D name 合并 if-then-else 格式输出, 预处理宏(由name参数提供)条件.
-e —ed 输出为一个有效的 ed 脚本.
—exclude=pattern 比较目录的时候,忽略和目录中与 pattern(样式) 相配的.
—exclude-from=file 比较目录的时候,忽略和目录中与任何包含在 file(文件) 的样式相配的文件和目录.
—expand-tabs 在输出时扩展tab为空格,保护输入文件的tab对齐方式
-f 产生一个很象 ed 脚本的输出,但是但是在他们在文件出现的顺序有改变
-F regexp 在上下文和统一格式中,对于每一大块的不同,显示出匹配 regexp. 的一些前面的行.
—forward-ed 产生象 ed 脚本的输出,但是它们在文件出现的顺序有改变。
-h 这选项现在已没作用,它呈现Unix的兼容性.
-H 使用启发规则加速操作那些有许多离散的小差异的大文件. —horizon-lines=lines 比较给定行数的有共同前缀的最后行,和有共同或缀的最前行.
-i 忽略大小写.
-I regexp 忽略由插入,删除行(由regexp 参数提供参考)带来的改变. —ifdef=name 合并 if-then-else 格式输出, 预处理宏(由name参数提供)条件.
—ignore-all-space 在比较行的时候忽略空白.
—ignore-blank-lines 忽略插入和删除空行
—ignore-case 忽略大小写.
—ignore-matching-lines=regexp 忽略插入删除行(由regexp 参数提供参考).
—ignore-space-change 忽略空白的数量.
—initial-tab 在文本行(无论是常规的或者格式化的前后文关系)前输出tab代替空格. 引起的原因是tab对齐方式看上去象是常规的一样.
-n 输出 RC-格式 diffs; 除了每条指令指定的行数受影响外 象 -f 一样。
-p 显示带有c函数的改变.
-P 在目录比较中,如果那个文件只在其中的一个目录中找到,那么它被视为在 另一个目录中是一个空文件. .
-q 仅报告文件是否相异,不报告详细的差异.
-r 当比较目录时,递归比较任何找到的子目录.
-s
报告两个文件相同.
-S file
当比较目录时,由 file 开始. 这用于继续中断了的比较.
—sdiff-merge-assist
打印附加的信息去帮助 sdiff. sdiff 在运行 diff 时使用这些选项. 这些选项不是特意为使用者直接使用而准备的。
-t 在输出时扩展tab为空格,保护输入文件的tab对齐方式
-T 在文本行(无论是常规的或者格式化的前后文关系)前输出tab代替空格.引起的原因 是tab对齐方式看上去象是常规的一样.—text 所有的文件都视为文本文件来逐行比较,甚至他们似乎不是文本文件.
-u 使用统一的输出格式.
—unchanged-group-format=format
使用 format 输出两个文件的公共行组,其格式是if-then-else.
—unchanged-line-format=format
使用 format 输出两个文件的公共行,其格式是if-then-else.
—unidirectional-new-file
在目录比较中,如果那个文件只在其中的一个目录中找到,那么它被视为在 另一个目录中是一个空文件.
-U lines —unified[=lines] 使用前后关系格式输出,显示以指定 行数 (一个整数), 或者是三行(当 行数 没有给出时. 对于正确的操作, 上下文至少要有两行.
-v —version 输出 diff 版本号.
-w 在比较行时忽略空格
-W columns—width=columns 在并列格式输出时,使用指定的列宽.
-x pattern 比较目录的时候,忽略和目录中与 pattern(样式) 相配的.
-X file比较目录的时候,忽略和目录中与任何包含在 file(文件) 的样式相配的文件和目录.
-y使用并列格式输出 
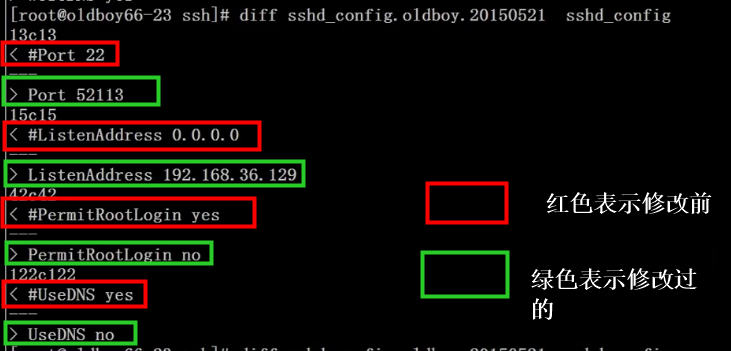
vimdiff命令 – 同时编辑多个文件
(可比对两个文件会将不同处高亮标出)
w 在命令模式下,按Ctrl + w在多个文件之间跳转
u 在命令模式下,按u执行撤销操作
qa 同时退出多个文件
wqa 保存并同时退出多个文件
例子:同时编辑比较两个文件
[root@linuxcool ~]# vimdiff file1 file2 
netstat命令 – 显示网络状态
-a 显示所有连线中的Socket
-p 显示正在使用Socket的程序识别码和程序名称
-u 显示UDP传输协议的连线状况
-i
显示网络界面信息表单
-n 直接使用IP地址,不通过域名服务器
例1
a.列出所有端口 (包括监听和未监听的)
[root@BlackGhost zhangy]# netstat -a | more
b.列出所有TCP端口
[root@BlackGhost zhangy]# netstat -at
c.列出所有UDP端口
[root@BlackGhost zhangy]# netstat -au
d.显示核心路由信息
[root@BlackGhost zhangy]# netstat -r
e.显示网络接口列表
[root@BlackGhost zhangy]# netstat -i
f.显看已连接的TCP端口,以及PID
[root@BlackGhost zhangy]# netstat -tpnl
g.查看连接某服务端口最多的的IP地址
[root@BlackGhost zhangy]# netstat -nat | grep “192.168.1.15:22” |awk ‘{print $5}’|awk -F: ‘{print $1}’|sort|uniq -c|sort -nr|head -20
18 221.136.168.36
3 154.74.45.242
2 78.173.31.236
2 62.183.207.98
2 192.168.1.14
2 182.48.111.215
2 124.193.219.34
2 119.145.41.2
2 114.255.41.30
例2
[root@localhost ~]# netstat -anp |grep 3306 -c #查看3306 端口(mysql)的链接数
11
例3
# netstat -alp|grep 8080 #找出运行在指定端口的进程
例4
# tcp 连接统计
# netstat -n | awk ‘/^tcp/{++S[$NF]} END {for (a in S) print a, S[a]}’
ESTABLISHED 10
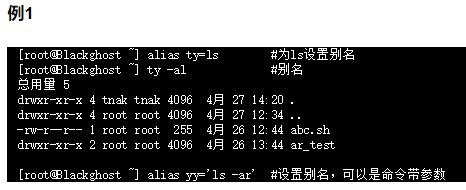
命令别名
Linux命令默认都带别名,比如直接rm会问你要不要删除(其实默人带别名询问的)
alias查看以及定义命令别名
取消别名:unalias
加别名例子:alias cp=’cp -i’
1、临时生效
[root@localhost ~]#alias grep=”grep —color=auto”
[root@localhost ~]#alias //检查
2、永久生效
方法一 编辑/etc/profile【对所有用户生效(永久的)】
[root@localhost ~]#echo “alias grep=’grep —color=auto’”>>/etc/profile
[root@localhost ~]#tail -1 /etc/profile
[root@localhost ~]#source /etc/profile 重新读取文件来生效
方法二 编辑/etc/.bashrc【只对当前所登陆的用户生效(永久的)】
[root@localhost ~]#echo “alias grep=’grep —color=auto’”>>~/.bashrc
[root@localhost ~]#tail -1 .bashrc
[root@localhost ~]#source .bashrc 重新读取文件来生效
sudo命令:
配置文件再/etc/sudoers
编辑配置文件时visudo和vi /etc/sudoers
cut连接文件并打印到标准输出设备上
-b, —bytes=LIST 以字节为单位进行分割 ,仅显示行中指定直接范围的内容
-c, —characters=LIST 输出 这些 字符
-d, —delimiter=DELIM 使用 DELIM 取代 TAB 做 字段(field) 分隔符
-f, —fields=LIST 输出 这些 字段
-n 取消分割多字节字符
-s, —only-delimited 不显示 没有 分隔符 的 行
—output-delimiter=STRING 使用 STRING 作为 输出分隔符, 缺省 (的 输出分隔符) 为 输入分隔符
—help 显示 帮助信息, 然后 结束
—version 显示 版本信息, 然后 结束
使用 且 只使用 -b, -c 或 -f 中的 一个 选项. LIST 由 一个 范围 (range) 或 逗号 隔开的 多个 范围 组成. 范围 是 下列 形式 之一:
N 第 N 个 字节, 字符 或 字段, 从 1 计数 起
N- 从 第 N 个 字节, 字符 或 字段 直至 行尾
N-M 从 第 N 到 第 M (并包括 第M) 个 字节, 字符 或 字段
-M 从 第 1 到 第 M (并包括 第M) 个 字节, 字符 或 字段
如果 没有 指定 文件 FILE, 或 FILE 是 -, 就从 标准输入 读取 数据.
| -b | 以字节为单位进行分割 ,仅显示行中指定直接范围的内容 |
|---|---|
| -c | 以字符为单位进行分割 , 仅显示行中指定范围的字符 |
| -d | 自定义分隔符,默认为制表符”TAB” |
| -f | 显示指定字段的内容 , 与-d一起使用 |
| -n | 取消分割多字节字符 |
| —complement | 补足被选择的字节、字符或字段 |
| —out-delimiter | 指定输出内容是的字段分割符 |
假设有一个学生报表信息,包含 No、Name、Mark、Percent:
[root@linuxcool ~]# cat student.txt
No Name Mark Percent
01 tom 69 91
02 jack 71 87
03 alex 68 98
使用 -f 选项提取指定字段(这里的 f 参数可以简单记忆为 —fields的缩写):
[root@linuxcool ~]# cut -f 2 student.txt
Name
tom
jack
alex
—complement 选项提取指定字段之外的列(打印除了第二列之外的列):
[root@linuxcool ~]# cut -f2 —complement student.txt
No Mark Percent
01 69 91
02 71 87
03 68 98
使用 -d 选项指定字段分隔符:
[root@linuxcool ~]# cat student2.txt
No;Name;Mark;Percent
01;tom;69;91
02;jack;71;87
03;alex;68;98
[root@linuxcool ~]# cut -f2 -d”;” student2.txt
Name
tom
jack
alex
[root@linuxcool ~]# cat test.txt
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxyz
打印第 1 个到第 3 个字符:
[root@linuxcool ~]# cut -c1-3 test.txt
abc
abc
abc
abc
abc
注意:-b 表示字节;-c 表示字符;-f 表示定义字段。
N- :从第 N 个字节、字符、字段到结尾; N-M :从第 N 个字节、字符、字段到第 M 个(包括 M 在内)字节、字符、段; -M :从第 1 个字节、字符、字段到第 M 个(包括 M 在内)字节、字符、字段。
打印前 2 个字符:
[root@linuxcool ~]# cut -c-2 test.txt
ab
ab
ab
ab
ab
打印从第 5 个字符开始到结尾:
[root@linuxcool ~]# cut -c5- test.txt
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
efghijklmnopqrstuvwxyz
例1
[root@localhost ~]# cat /etc/passwd | cut -b 1 |head -5 #输出文件的第一个字节
r
b
d
a
l
[root@localhost ~]# cat /etc/passwd | cut -c 1-4 |head -5 #输出文件的前四个字符
root
bin:
daem
adm:
lp:x
[root@localhost ~]# cat /etc/passwd | cut -f1 -d ‘:’ |head -5 #以:分割文件,输出第一个字段
root
bin
daemon
adm
lp
例2
# cat a.txt
ssss affff dddd fe fsc
rrr f adfa eer ddd
# cat a.txt |cut -f1,3 -d $’\t’ #1,3列
ssss dddd
rrr adfa
例3
# cat file.txt
unix or linux os
is unix good os
is linux good os
# cut -c4 file.txt #将所有行的第四个字符打印出来。
x
u
l
# cut -c4,6 file.txt #将每一行的第四个和第六个字符打印出来
xo
ui
ln
# cut -c4-7 file.txt #将第四个到第七个字符打印出来,注意是闭区间。
x or
unix
linu
# cut -c-6 file.txt #将每一行的前六个字符都打印出来
unix o
is uni
is lin
# cut -c10- file.txt #将从起始位置到行末的所有文本都打印出来
inux os
ood os
good os
# cut -d ‘ ‘ -f2 file.txt #定义空格为一行的分隔符,并将每一行的第二个字段打印出来
or
unix
linux
# cut -d ‘ ‘ -f2,3 file.txt #将第二个字段和第三个字段打印出来
or linux
unix good
linux good
# cut -d ‘ ‘ -f1-3 file.txt #将第一个字段、第二个字段、第三个字段的内容都打印出来
# cut -d ‘ ‘ -f-3 file.txt #将前三个字段都打印出来
mount命令 – 文件系统挂载
-t 指定挂载类型
-l 显示已加载的文件系统列表
-h 显示帮助信息并退出
-V 显示程序版本
-n 加载没有写入文件“/etc/mtab”中的文件系统
-r 将文件系统加载为只读模式
-a 加载文件“/etc/fstab”中描述的所有文件系统
-a 加载文件/etc/fstab中设置的所有设备。
-f 不实际加载设备。可与-v等参数同时使用以查看mount的执行过程。
-F 需与-a参数同时使用。所有在/etc/fstab中设置的设备会被同时加载,可加快执行速度。
-h 显示在线帮助信息。
-L<标签> 加载文件系统标签为<标签>的设备。
-l 显示已加载的文件系统列表(同直接执行mount)
-n 不将加载信息记录在/etc/mtab文件中。
-o<选项> 指定加载文件系统时的选项。有些选项也可在/etc/fstab中使用。这些选项包括:
async 以非同步的方式执行文件系统的输入输出动作。
atime 每次存取都更新inode的存取时间,默认设置,取消选项为noatime。
auto 必须在/etc/fstab文件中指定此选项。执行-a参数时,会加载设置为auto的设备,取消选取为noauto。
defaults 使用默认的选项。默认选项为rw、suid、dev、exec、anto nouser与async。
dev 可读文件系统上的字符或块设备,取消选项为nodev。
exec 可执行二进制文件,取消选项为noexec。
loop 用来把一个文件当成硬盘分区挂接上系统。
noatime 每次存取时不更新inode的存取时间。
noauto 无法使用-a参数来加载。
nodev 不读文件系统上的字符或块设备。
noexec 无法执行二进制文件。
nosuid 关闭set-user-identifier(设置用户ID)与set-group-identifer(设置组ID)设置位。
nouser 使一位用户无法执行加载操作,默认设置。
remount 重新加载设备。通常用于改变设备的设置状态。
ro 以只读模式加载。
rw 以可读写模式加载。
suid 启动set-user-identifier(设置用户ID)与set-group-identifer(设置组ID)设置位,取消选项为nosuid。
sync 以同步方式执行文件系统的输入输出动作。
user 可以让一般用户加载设备。
-r 以只读方式加载设备。
-t<文件系统类型> 指定设备的文件系统类型。常用的选项说明有:
minix Linux最早使用的文件系统。
ext2 Linux目前的常用文件系统。
msdos MS-DOS 的 FAT。
vfat Win85/98 的 VFAT。
nfs 网络文件系统。
iso9660 CD-ROM光盘的标准文件系统。
ntfs Windows NT的文件系统。
hpfs OS/2文件系统。Windows NT 3.51之前版本的文件系统。
auto 自动检测文件系统。
ubifs (Unsorted Block Image File System, UBIFS)无序区块镜像文件系统是用于固态存储设备上,为JFFS2的后继文件系统之一。
-v 执行时显示详细的信息。
-V 显示版本信息。
-w 以可读写模式加载设备,默认设置。
查看版本:
[root@linuxcool ~]# mount -V
启动所有挂载:
[root@linuxcool ~]# mount -a
挂载 /dev/cdrom 到 /mnt:
[root@linuxcool ~]# mount /dev/cdrom /mnt
挂载nfs格式文件系统:
[root@linuxcool ~]# mount -t nfs /123 /mnt
挂载第一块盘的第一个分区到/etc目录 :
[root@linuxcool ~]# mount -t ext4 -o loop,default /dev/sda1 /etc
[root@linux ~]# mount -l #列出所挂载的系统
[root@linux ~]# mount /dev/sda1 /media/usb #挂载u盘
[root@linux ~]# mount —bind /media/usb /mnt #将已挂载的设备移到其他目录
[root@linux ~]# mount -o loop ./abc.iso /mnt/cdrom #将ISO文件
[root@linux ~]# mount -t ntfs-3g /dev/sda1 /mnt/windows #挂载windows盘
# mount -o username=xiexiangrong,password=xxxxxx -l //192.168.6.2/soft /mnt #访问windows共享文件
-o username= windows user,password=访问密码
-l //网络地址/共享文件
对ntfs格式的磁盘分区应使用-t ntfs 参数,对fat32格式的磁盘分区应使用-t vfat参数。若汉字文件名显示为乱码或不显示,可以使用下面的命令格式。
# mount -t ntfs -o iocharset=cp936 /dev/sdc1 /mnt/usbhd1
使用目录/mnt/vcdrom,即可访问盘镜像文件mydisk.iso中的所有文件。
# mount -o loop -t iso9660 /home/sunky/mydisk.iso /mnt/vcdrom
administrator 和 pldy123 是ip地址为10.140.133.23 windows计算机的一个用户名和密码,c$是这台计算机的一个磁盘共享
# mount -t smbfs -o username=administrator,password=pldy123 //10.140.133.23/c$ /mnt/samba
这里我们假设10.140.133.9是NFS服务端的主机IP地址,当然这里也可以使用主机名,但必须在本机/etc/hosts文件里增加服务端ip定义。/export/home/sunky为服务端共享的目录。
# mount -t nfs -o rw 10.140.133.9:/export/home/sunky /mnt/nfs
date - 打印或设置系统日期和时间
根据指定格式显示当前时间或设置系统时间.
-d, —date=STRING
显示由 STRING 指定的时间, 而不是当前时间
-f, —file=DATEFILE
显示 DATEFILE 中每一行指定的时间, 如同将 DATEFILE 中的每行作为 —date 的参数一样
-I, —iso-8601[=TIMESPEC] 按照 ISO-8601 的日期/时间格式输出时间.
TIMESPEC=date' (或者不指定时)仅输出日期,等于hours’, minutes', 或seconds’ 时按照指定精度输出日期及时间.
-r, —reference=FILE
显示 FILE 的最后修改时间
-R, —rfc-822
根据 RFC-822 指定格式输出日期
-s, —set=STRING
根据 STRING 设置时间
-u, —utc, —universal
显示或设置全球时间(格林威治时间)
—help
显示本帮助文件并退出
—version
显示版本信息并退出
格式 FORMAT 控制着输出格式. 仅当选项指定为全球时间时本格式才有效。 分别解释如下:
%% 文本的 %
%a 当前区域的星期几的简写 (Sun..Sat)
%A 当前区域的星期几的全称 (不同长度) (Sunday..Saturday)
%b 当前区域的月份的简写 (Jan..Dec)
%B 当前区域的月份的全称(变长) (January..December)
%c 当前区域的日期和时间 (Sat Nov 04 12:02:33 EST 1989)
%d (月份中的)几号(用两位表示) (01..31)
%D 日期(按照 月/日期/年 格式显示) (mm/dd/yy)
%e (月份中的)几号(去零表示) ( 1..31)
%h 同 %b
%H 小时(按 24 小时制显示,用两位表示) (00..23)
%I 小时(按 12 小时制显示,用两位表示) (01..12)
%j (一年中的)第几天(用三位表示) (001..366)
%k 小时(按 24 小时制显示,去零显示) ( 0..23)
%l 小时(按 12 小时制显示,去零表示) ( 1..12)
%m 月份(用两位表示) (01..12)
%M 分钟数(用两位表示) (00..59)
%n 换行
%p 当前时间是上午 AM 还是下午 PM
%r 时间,按 12 小时制显示 (hh:mm:ss [A/P]M)
%s 从 1970年1月1日0点0分0秒到现在历经的秒数 (GNU扩充)
%S 秒数(用两位表示)(00..60)
%t 水平方向的 tab 制表符
%T 时间,按 24 小时制显示(hh:mm:ss)
%U (一年中的)第几个星期,以星期天作为一周的开始(用两位表示) (00..53)
%V (一年中的)第几个星期,以星期一作为一周的开始(用两位表示) (01..52)
%w 用数字表示星期几 (0..6); 0 代表星期天
%W (一年中的)第几个星期,以星期一作为一周的开始(用两位表示) (00..53)
%x 按照 (mm/dd/yy) 格式显示当前日期
%X 按照 (%H:%M:%S) 格式显示当前时间
%y 年的后两位数字 (00..99)
%Y 年(用 4 位表示) (1970…)
%z 按照 RFC-822 中指定的数字时区显示(如, -0500) (为非标准扩充)
%Z 时区(例如, EDT (美国东部时区)), 如果不能决定是哪个时区则为空
默认情况下,用 0 填充数据的空缺部分. GNU 的 date 命令能分辨在 %'和数字指示之间的以下修改<br />-‘ (连接号) 不进行填充 `_’ (下划线) 用空格进行填充
例子:
[root@localhost www]# date #显示日期和时间
2013年 05月 04日 星期六 14:35:33 CST
[root@localhost www]# date -s ‘14:35:40’ #设置时间
2013年 05月 04日 星期六 14:35:40 CST
[root@rudder ~]# date +%m%d%H%M%S
0819150511
[root@rudder ~]# date 0819150511
Fri Aug 19 15:05:00 EST 2011
#date -s //设置当前时间,只有root权限才能设置,其他只能查看。
#date -s 20061010 //设置成20061010,这样会把具体时间设置成空00:00:00
#date -s 12:23:23 //设置具体时间,不会对日期做更改
#date -s “12:12:23 2006-10-10″ //这样可以设置全部时间
[root@localhost ~]# date -d “20150305” +%s #时间转时间戳
1425484800
[root@localhost ~]# date -d ‘1970-01-01 UTC 1425484800 seconds’ #时间戳转时间
2015年 03月 05日 星期四 00:00:00 CST
# date -d @1436781720
2015年 07月 13日 星期一 18:02:00 CST
[root@shell01 ~]# date +%F #当天
2020-03-05
[root@shell01 ~]# date -d ‘+1day’ +%F #后一天
2020-03-06
[root@localhost ~]# date +%Y%m%d #获取当前日期格式为yyyymmdd
20150410
[root@localhost ~]# date -d “1 day ago” +”%Y%m%d” #获取前一天的日期格式为yyyymmdd
20150409
# date +%Y%m%d #显示当天年月日
# date +%Y%m%d —date=”+1 day” #显示后一天的日期
# date +%Y%m%d —date=”-1 day” #显示前一天的日期
# date +%Y%m%d —date=”-1 month” #显示上一月的日期
# date +%Y%m%d —date=”+1 month” #显示下一月的日期
# date +%Y%m%d —date=”-1 year” #显示前一年的日期
# date +%Y%m%d —date=”+1 year” #显示下一年的日期
# date -s #设置当前时间,只有root权限才能设置,其他只能查看。
# date -s 20080523 #设置成20080523,这样会把具体时间设置成空00:00:00
# date -s 01:01:01 #设置具体时间,不会对日期做更改
# date -s “01:01:01 2008-05-23″ #这样可以设置全部时间
# date -s “01:01:01 20080523″ #这样可以设置全部时间
# date -s “2008-05-23 01:01:01″ #这样可以设置全部时间
# date -s “20080523 01:01:01″ #这样可以设置全部时间
# date -d “2015-11-15 23:00:01”
Mon Nov 15 23:00:01 PST 2015
# date -d “2015/11/15 23:0:2”
Mon Nov 15 23:00:02 PST 2015
# date -d “2015/11/15T23:0:2”
Mon Nov 15 08:00:02 PST 2015
# echo “2015-11-15 23:00:01” > date.txt
# echo “2015/11/15 23:00:02” >> date.txt
# cat date.txt
2015-11-15 23:00:01
2015/11/15 23:00:02
# date -f date.txt
Mon Nov 15 23:00:01 PST 2015
Mon Nov 15 23:00:02 PST 2015
# date -r date.txt
Mon Nov 15 21:14:36 PST 2015
# date -I
2015-11-15
# date -Ihours
2015-11-15T21-0800
# date -Iminutes
2015-11-15T21:16-0800
# date -Iseconds
2015-11-15T21:16:24-0800
# date -R
Mon, 15 Nov 2015 21:47:08 -0800
# date -u
Tue Nov 16 05:47:13 UTC 2015
# date +”Today is %A.”
Today is Monday.
# date +”Date:%b. %e, %G”
Date:Nov. 15, 2015
# date +”Date: %b.%e, %G”
Date: Nov.15, 2015
# date +”%x %X”
11/15/2015 09:50:21 PM
# date +”%Y-%m-%d %H:%M:%S”
2015-11-15 21:51:32
# date +”%Y-%m-%d %I:%M:%S %p”
2015-11-15 09:51:55 PM
例9
# date +%s #显示系统的时间戳
例10
#输出指定日期之前的N天的时间戳
# date -d “20181101 30 days ago” +%s
1538409600
例11
[root@centos5 ~]# date +”%F %T”
2018-11-24 11:33:48
例12
# date +%j #今年已经过了多少天
129 **
uptime命令 – 查看系统负载
-p 以漂亮的格式显示机器正常运行的时间
-s 系统自开始运行时间,格式为yyyy-mm-dd hh:mm:ss
-h 显示帮助信息
参考实例
显示当前系统运行负载情况:
[root@linuxcool ~]# uptime
15:23:22 up 2 days, 5:13, 3 users, load average: 0.12, 0.04, 0.05
使用-p参数显示机器正常运行的时间:
[root@linuxcool ~]# uptime -p
up 2 days, 5 hours, 15 minutes
使用-s参数显示机器启动时间:
[root@linuxcool ~]# uptime -s
2019-05-09 10:09:43
last命令 – 显示用户或终端的登录情况
-R 省略hostname的栏位
usename 展示username的登入讯息
tty 限制登入讯息包含的终端代号
参考实例
显示近期用户或终端的登录情况:
[root@linuxcool ~]# last
简略显示,并指定显示的个数:
[root@linuxcool ~]# last -n 5 -R
显示最后一列显示主机IP地址:
[root@linuxcool ~]# last -n 5 -a -i
tr 从标准输入中替换、缩减和/或删除字符,并将结果写到标准输出。
-c, -C, —complement 首先补足SET1
-d, —delete 删除匹配SET1 的内容,并不作替换
-s, —squeeze-repeats 如果匹配于SET1 的字符在输入序列中存在连续的
重复,在替换时会被统一缩为一个字符的长度
-t, —truncate-set1 先将SET1 的长度截为和SET2 相等
—help 显示此帮助信息并退出
—version 显示版本信息并退出
SET 是一组字符串,一般都可按照字面含义理解。解析序列如下:
\NNN 八进制值为NNN 的字符(1 至3 个数位)
\ 反斜杠
\a 终端鸣响
\b 退格
\f 换页
\n 换行
\r 回车
\t 水平制表符
\v 垂直制表符
字符1-字符2 从字符1 到字符2 的升序递增过程中经历的所有字符
[字符] 在SET2 中适用,指定字符会被连续复制直到吻合设置1 的长度
[字符次数] 对字符执行指定次数的复制,若次数以 0 开头则被视为八进制数
[:alnum:] 所有的字母和数字
[:alpha:] 所有的字母
[:blank:] 所有呈水平排列的空白字符
[:cntrl:] 所有的控制字符
[:digit:] 所有的数字
[:graph:] 所有的可打印字符,不包括空格
[:lower:] 所有的小写字母
[:print:] 所有的可打印字符,包括空格
[:punct:] 所有的标点字符
[:space:] 所有呈水平或垂直排列的空白字符
[:upper:] 所有的大写字母
[:xdigit:] 所有的十六进制数
[=字符=] 所有和指定字符相等的字符
仅在SET1 和SET2 都给出,同时没有-d 选项的时候才会进行替换。
仅在替换时才可能用到-t 选项。如果需要SET2 将被通过在末尾添加原来的末字符的方式
补充到同SET1 等长。SET2 中多余的字符将被省略。只有[:lower:] 和[:upper:]
以升序展开字符;在用于替换时的SET2 中以成对表示大小写转换。-s 作用于SET1,既不
替换也不删除,否则在替换或展开后使用SET2 缩减。
[root@localhost zhangy]# echo “TANK” |tr A-Z a-z #大写字母转小写
tank
[root@localhost zhangy]# echo ‘tank zhang’ | tr a-z A-Z #小写字线转大写
TANK ZHANG
[root@localhost zhangy]# cat aaa.txt #原文件
aaa
bbb
[root@localhost zhangy]# cat aaa.txt|tr ‘a’ ‘c’ #字母c替换字母a
ccc
bbb
[root@localhost zhangy]# cat aaa.txt|tr -d ‘a’ #删除所有字母a
bbb
[root@localhost zhangy]# cat aaa.txt|tr -d ‘\n\t’ 删除文件file中出现的换行’\n’、制表’\t’字符
aaabbb
[root@localhost zhangy]# cat aaa.txt|tr -s [a-zA-Z] #删除重复的字母
a
b
[root@localhost zhangy]# cat aaa.txt|tr -s ‘\n’ #删除空行
aaa
bbb
[root@localhost zhangy]# cat aaa.txt |tr -s ‘\011’ ‘\040’ #用空格符\040替换制表符\011
aaa
bbb
# tr a c < test #将test文件中的a变成c
# cat aaa
656122 asdfasd asdfasd
asdfasd asdfas
# cat aaa | tr ‘ ‘ ‘\n’
656122
asdfasd
asdfasd
asdfasd
asdfas
expr 简单计算器
【表达式】
| :逻辑或
& :逻辑与
< :小于
<=:小于等于
= :等于
! :不等于
>=:大于等于
> :大于
+ :加
- :减
:乘
/ :除
% :取余
stringgexp :检查string的模式是否匹配regexp
match string regexp :等同于string regexp
index string chars :string 中 chars 的索引
length string :string 的长度
+ token :将token 看作一个字符串
例1
[root@redhat ~]# expr length 123132134524asdqweqweqewqfgdfgdfgdf #求长度
35
[root@redhat ~]# expr 35 ‘>’ 9 #逻辑判断
1
[root@redhat ~]# expr 6 ‘+’ 5 #数学运算
11
计算字串长度:
[root@linuxcool ~]# expr length “this is a test”
14
抓取字串:
[root@linuxcool ~]# expr substr “this is a test” 3 5
is is
抓取第一个字符数字串出现的位置:
[root@linuxcool ~]# expr index “sarasara” a
2
整数运算:
[root@linuxcool ~]# expr 14 % 9
5
[root@linuxcool ~]# expr 10 + 10
20
[root@linuxcool ~]# expr 1000 + 900
1900
[root@linuxcool ~]# expr 30 / 3 / 2
5
[root@linuxcool ~]# expr 30 3
expr: Syntax error
[root@linuxcool ~]# expr 30 / 3
90
注意:使用乘号时,必须用反斜线屏蔽其特定含义。因为shell可能会误解显示星号的意义
使用expr进行四则运算:
[root@linuxcool ~]# expr ( 10 + 10 ) \ 2 + 100
140
read – 读取单行数据
read 内部命令被用来从标准输入读取单行数据。这个命令可以用来读取键盘输入,当使用重定向的时候,可以读取文件中的一行数据。
-a 后跟一个变量,该变量会被认为是个数组,然后给其赋值,默认是以空格为分割符。
-d 后面跟一个标志符,其实只有其后的第一个字符有用,作为结束的标志,会举例说 明。
-p 后面跟提示信息,即在输入前打印提示信息。
-e 在输入的时候可以使用命令补全功能。
-n 后跟一个数字,定义输入文本的长度,很实用。
-r 屏蔽,如果没有该选项,则作为一个转义字符,有的话 就是个正常的字符了。
-s 安静模式,在输入字符时不再屏幕上显示,例如login时输入密码。
-t 后面跟秒数,定义输入字符的等待时间。
-u 后面跟fd,从文件描述符中读入,该文件描述符可以是exec新开启的。
# read -t 30 -p “please input your name: “ name #提示“请输入姓名”并等待30秒,输入值保存到变量name中
please input your name: tank
# echo $name
tank
简单读取:
#!/bin/bash echo “输入网站名: “ read file echo “你输入的网站名是 $file” exit 0
允许在 read 命令行中直接指定一个提示:
#!/bin/bash read -p “输入网站名:” file echo “你输入的网站名是 $file” exit 0
指定 read 命令等待输入的秒数,当计时满时,read命令返回一个非零退出状态:
#!/bin/bash if read -t 5 -p “输入网站名:” file then echo “你输入的网站名是 $file” else echo “\n抱歉,你输入超时了。” fi exit 0
设置 read 命令计数输入的字符。当输入的字符数目达到预定数目时,自动退出,并将输入的数据赋值给变量:
#!/bin/bash read -n1 -p “Do you want to continue [Y/N]?” answer case $answer in Y | y) echo “fine ,continue”;; N | n) echo “ok,good bye”;; ) echo “error choice”;; esac exit 0
使 read 命令中输入的数据不显示在命令终端上:
#!/bin/bash read -s -p “请输入您的密码:” pass echo “\n您输入的密码是 $pass” exit 0
简单读取:
#!/bin/bash
echo “输入网站名: “
read file
echo “你输入的网站名是 $file”
exit 0
允许在 read 命令行中直接指定一个提示:
#!/bin/bash
read -p “输入网站名:” file
echo “你输入的网站名是 $file”
exit 0
指定 read 命令等待输入的秒数,当计时满时,read命令返回一个非零退出状态:
#!/bin/bash
if read -t 5 -p “输入网站名:” file
then
echo “你输入的网站名是 $file”
else
echo “\n抱歉,你输入超时了。”
fi
exit 0
设置 read 命令计数输入的字符。当输入的字符数目达到预定数目时,自动退出,并将输入的数据赋值给变量:
#!/bin/bash
read -n1 -p “Do you want to continue [Y/N]?” answer
case $answer in
Y | y)
echo “fine ,continue”;;
N | n)
echo “ok,good bye”;;
)
echo “error choice”;;
esac
exit 0
使 read 命令中输入的数据不显示在命令终端上:
#!/bin/bash
read -s -p “请输入您的密码:” pass
echo “\n您输入的密码是 $pass”
exit 0
at命令 – 一次性定时计划任务
-V 在标准错误上输出版本号。
-q queue 使用指定的队列。一个队列用一个字母标定,有效的的队列标定的 范围是从a到z和从A到Z。at 的缺省队列是 a,batch 的缺省队列是 b。队列的字母顺序越高,则队列运行时越谦让(运行级别越低)。 指定的队列 “=”保留给当前运行的作业所在的队列。 如果一个作业被提交到一个以大写字母标定的队列,则与提交到 batch 同样对待。如果给 atq 指定一个队列,则只显示在此指定 队列中的作业。
-m 当作业完成时即使没有输出也给用户发邮件。
-f file 从文件而不是标准输入中读取作业信息。
-l 等同于atq。
-d 等同于atrm。
-v 对于 atq, 显示完整的在队列中未被删除的作业,对于其他 命令,显示作业将要执行的时间。 显示的时间的格式类似于”1997-02-20 14:50”,但如果设置了 POSIXLY_CORRECT 环境变量之后,格式类似于”Thu Feb 20 14:50:00 1996”。
-c 连接命令行中列出的作业并输出到标准输出。
atq 查看系统中的等待作业
-d 删除系统中的等待作业(等效于atrm命令)
-c 打印任务的内容
-q 使用指定的列队
-f 将指定文件提交等待作业
-t 以时间的形式提交运行作业
查看系统中的等待作业:
[root@linuxcool ~]# atq
使用”at -d”或者”atrm”(二者同效)指定id来删除系统中的等待作业,id为”atq”命令输出的第一行顺序数字:
[root@linuxcool ~]# at -d 1
[root@linuxcool ~]# atrm 1
假设存在 linuxcool.sh 脚本,立即运行:
[root@linuxcool ~]# at -f linuxcool.sh now
在25分钟之后运行 linuxcool.sh 脚本:
[root@linuxcool ~]# at -f linuxcool.sh now+25 min
在10:11运行 linuxcool.sh 脚本:
[root@linuxcool ~]# at -f linuxcool.sh 10:11
在2019年7月27日运行 linuxcool.sh 脚本:
[root@linuxcool ~]# at -f linuxcool.sh 07/27/2019
查看单个at任务内容
[zhangy@BlackGhost ~]$ at -c 3
#!/bin/sh
# atrun uid=0 gid=0
# mail tnak 0
umask 22
………省略……..
echo 1111
# at 5pm+3 days #三天后的下午5点,执行 /bin/ls
at> /bin/ls
at>
job 7 at 2016-01-08 17:00
# at 17:20 tomorrow #明天17点钟,输出时间到指定文件内
at> date >/root/date.log
at>
job 8 at 2016-01-06 17:20
# atq #查看任务
8 2016-01-06 17:20 a root
7 2016-01-08 17:00 a root
# atrm 7 #删除任务
# atq
8 2016-01-06 17:20 a root
# 指定在今天下午5:30执行某命令。以下命令格式,结果都一样:
# at 5:30pm
# at 17:30
# at 17:30 today
# at now + 5 hours
# at now + 300 minutes
# at 17:30 24.2.99
# at 17:30 2/24/99
# at 17:30 Feb 24
# at -f /home/test/work 4pm + 3 days #在三天后下午4点执行文档work中的作业
ln -在文件之间建立连接
-f : 链结时先将与 dist 同档名的档案删除
-d : 允许系统管理者硬链结自己的目录
-i : 在删除与 dist 同档名的档案时先进行询问
-n : 在进行软连结时,将 dist 视为一般的档案
-s : 进行软链结(symbolic link)
-v : 在连结之前显示其档名
-b : 将在链结时会被覆写或删除的档案进行备份
-S SUFFIX : 将备份的档案都加上 SUFFIX 的字尾
-V METHOD : 指定备份的方式
—help : 显示辅助说明
—version : 显示版本
chown命令 – 改变文件或目录用户和用户组
-R 对目前目录下的所有文件与子目录进行相同的拥有者变更
-c 若该文件拥有者确实已经更改,才显示其更改动作
-f 若该文件拥有者无法被更改也不要显示错误讯息
-h 只对于连结(link)进行变更,而非该 link 真正指向的文件
-v 显示拥有者变更的详细资料
—help 显示辅助说明
—version 显示版本
-H 如果命令行参数是一个通到目录的符号链接,则遍历符号链接
-L 遍历每一个遇到的通到目录的符号链接
-P 不遍历任何符号链接(默认)
[root@localhost ~]# chown zhangy:zhangy nginx.conf #将nginx.conf所属用户和组改为zhangy,zhangy
[root@localhost ~]# ls -al |grep nginx.conf
-rw-r—r— 1 zhangy zhangy 0 5月 3 15:21 nginx.conf
[root@localhost ~]# chown -R zhangy:zhangy www #将www目录,所属用户和组改为zhangy,zhangy
[root@localhost ~]# ls -al |grep ww
drwxr-xr-x 2 zhangy zhangy 4096 5月 3 15:20 www
[root@localhost ~]# chown root nginx.conf #将nginx.conf,所属用户改为root
[root@localhost ~]# ls -al |grep nginx.conf
-rw-r—r— 1 root zhangy 0 5月 3 15:21 nginx.conf
[root@localhost database]# ll
总用量 4592
-rw-r—r— 1 root root 2466 7月 23 18:02 1.html
-rw-r—r—. 1 tank tank 4099771 5月 28 14:42 28toplearning.sql
-rw-r—r—. 1 tank tank 596069 5月 29 00:07 toplearning.tar.gz
[root@localhost database]# chown .tank 1.html #只改变组
[root@localhost database]# ll
总用量 4592
-rw-r—r— 1 root tank 2466 7月 23 18:02 1.html #组已改变
-rw-r—r—. 1 tank tank 4099771 5月 28 14:42 28toplearning.sql
-rw-r—r—. 1 tank tank 596069 5月 29 00:07 toplearning.tar.gz
zcat命令 – 查看压缩文件的内容
-S 当后缀不是标准压缩包后缀时使用此选项
-c 将文件内容写到标注输出
-d 执行解压缩操作
-l 显示压缩包中文件的列表
-L 显示软件许可信息
-q 禁用警告信息
-r 在目录上执行递归操作
-t 测试压缩文件的完整性
-V 显示指令的版本信息
-l 更快的压缩速度
-9 更高的压缩比
不解压缩文件的情况下,显示压缩包中文件的内容:
[root@linuxcool ~]# zcat file.gz
查看多个压缩文件:
[root@linuxcool ~]# zcat file1.gz file2.gz
查看普通文件的内容:
[root@linuxcool ~]# zcat -f file
获取压缩文件的属性(压缩大小,未压缩大小,比率 — 压缩率):
[root@linuxcool ~]# zcat -l file.gz
禁止所有警告:
[root@linuxcool ~]# zcat -q file.gz

若有收获,就点个赞吧
0 人点赞
