常用转义字符:
- 反斜杠:(\)使反斜杠后面的变量变为单纯的字符串
- 单引号:(’’)转义其中所有的变量为单纯的字符串
- 双引号:(””)保留其中的变量属性。,不进行转义处理
- 反引号:(^^)把其中的命令执行后返回结果
shell上:
- 0表示标准输入
- 1表示标准输出
- 2表示标准错误输出
默认为标准输出重定向,与 1> 相同
2>&1意思是把 标准错误输出 重定向到 标准输出.&>file意思是把 标准输出 和 标准错误输出 都重定向到文件file中
用例子说话:
1. grep da * 1>&22. rm -f $(find / -name core) &> /dev/null上面两例中的 & 如何理解,&不是放到后台执行吗?
1.&>file或n>&m均是一个独立的重定向符号,不要分开来理解。2.明确文件和文件描述符的区别。3.&>file表示重定向标准输出和错误到文件例如:
rm -f $(find / -name core) &> /dev/null,/dev/null是一个文件,这个文件比较特殊,所有传给它的东西它都丢弃掉。
4.n>&m表示使文件描述符n成为输出文件描述符m的副本。这样做的好处是,有的时候你查找文件的时候很容易产生无用的信息,如:2> /dev/null的作用就是不显示标准错误输出;另外当你运行某些命令的时候,出错信息也许很重要,便于你检查是哪出了毛病,如:2>&1
例如:
注意,为了方便理解,必须设置一个环境使得执行grep da *命令会有正常输出和错误输出,然后分别使用下面的命令生成三个文件:
grep da * > greplog1grep da * > greplog2 1>&2grep da * > greplog3 2>&1 //grep da * 2> greplog4 1>&2 结果一样#查看greplog1会发现里面只有正常输出内容#查看greplog2会发现里面什么都没有#查看greplog3会发现里面既有正常输出内容又有错误输出内容
grep 文本搜索工具
grep 是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能配合多种命令使用,使用上十分灵活。
匹配模式选择:-E, --extended-regexp 扩展正则表达式egrep-F, --fixed-strings 一个换行符分隔的字符串的集合fgrep-G, --basic-regexp 基本正则-P, --perl-regexp 调用的perl正则-e, --regexp=PATTERN 后面根正则模式,默认无-f, --file=FILE 从文件中获得匹配模式-i, --ignore-case 不区分大小写-w, --word-regexp 匹配整个单词-x, --line-regexp 匹配整行-z, --null-data 一个 0 字节的数据行,但不是空行杂项:-s, --no-messages 不显示错误信息-v, --invert-match 显示不匹配的行-V, --version 显示版本号--help 显示帮助信息--mmap use memory-mapped input if possible输入控制:-m, --max-count=NUM 匹配的最大数-b, --byte-offset 打印匹配行前面打印该行所在的块号码。-n, --line-number 显示的加上匹配所在的行号--line-buffered 刷新输出每一行-H, --with-filename 当搜索多个文件时,显示匹配文件名前缀-h, --no-filename 当搜索多个文件时,不显示匹配文件名前缀--label=LABEL print LABEL as filename for standard input-o, --only-matching 只显示一行中匹配PATTERN 的部分-q, --quiet, --silent 不显示任何东西--binary-files=TYPE 假定二进制文件的TYPE 类型;TYPE 可以是`binary', `text', 或`without-match'-a, --text 匹配二进制的东西-I 不匹配二进制的东西-d, --directories=ACTION 目录操作,读取,递归,跳过-D, --devices=ACTION 设置对设备,FIFO,管道的操作,读取,跳过-R, -r, --recursive 递归调用--include=PATTERN 只查找匹配FILE_PATTERN 的文件--exclude=PATTERN 跳过匹配FILE_PATTERN 的文件和目录--exclude-from=FILE 跳过所有除FILE 以外的文件-L, --files-without-match 匹配多个文件时,显示不匹配的文件名-l, --files-with-matches 匹配多个文件时,显示匹配的文件名-c, --count 显示匹配的行数-Z, --null 在FILE 文件最后打印空字符文件控制:-B, --before-context=NUM 打印匹配本身以及前面的几个行由NUM控制-A, --after-context=NUM 打印匹配本身以及随后的几个行由NUM控制-C, --context=NUM 打印匹配本身以及随后,前面的几个行由NUM控制-NUM 根-C的用法一样的--color[=WHEN],--colour[=WHEN] 使用标志高亮匹配字串;一般加auto-U, --binary 使用标志高亮匹配字串;-u, --unix-byte-offsets 当CR 字符不存在,报告字节偏移(MSDOS 模式)
规则表达式
^ # 锚定行的开始 如:'^grep'匹配所有以grep开头的行。$ # 锚定行的结束 如:'grep$' 匹配所有以grep结尾的行。. # 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。* # 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。.* # 一起用代表任意字符。[] # 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。[^] # 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。\(..\) # 标记匹配字符,如'\(love\)',love被标记为1。\< # 锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。\> # 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。x\{m\} # 重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。x\{m,\} # 重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。x\{m,n\} # 重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。\w # 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。\W # \w的反置形式,匹配一个或多个非单词字符,如点号句号等。\b # 单词锁定符,如: '\bgrep\b'只匹配grep。
在多个文件中查找:
grep "match_pattern" file_1 file_2 file_3 ...
输出除之外的所有行 -v 选项:
grep -v "match_pattern" file_name
高亮显示查找结果 —color=auto 选项:
grep "match_pattern" file_name --color=auto
使用正则表达式 -E 选项:
grep -E "[1-9]+"# 或egrep "[1-9]+"
使用正则表达式 -P 选项:
grep -P "(\d{3}\-){2}\d{4}" file_name
只输出文件中匹配到的部分 -o 选项:
echo this is a test line. | grep -o -E "[a-z]+\."line.echo this is a test line. | egrep -o "[a-z]+\."line.
统计文件或者文本中包含匹配字符串的行数 -c 选项:
grep -c "text" file_name
搜索多个文件并查找匹配文本在哪些文件中:
grep -l "text" file1 file2 file3...
忽略匹配样式中的字符大小写:
echo "hello world" | grep -i "HELLO"# hello
选项 -e 制动多个匹配样式:
echo this is a text line | grep -e "is" -e "line" -oisline
在grep搜索结果中包括或者排除指定文件:
# 只在目录中所有的.php和.html文件中递归搜索字符"main()"grep "main()" . -r --include *.{php,html}# 在搜索结果中排除所有README文件grep "main()" . -r --exclude "README"# 在搜索结果中排除filelist文件列表里的文件grep "main()" . -r --exclude-from filelist
使用0值字节后缀的grep与xargs:
# 测试文件:echo "aaa" > file1echo "bbb" > file2echo "aaa" > file3grep "aaa" file* -lZ | xargs -0 rm# 执行后会删除file1和file3,grep输出用-Z选项来指定以0值字节作为终结符文件名(\0),xargs -0 读取输入并用0值字节终结符分隔文件名,然后删除匹配文件,-Z通常和-l结合使用。
grep静默输出:
grep -q "test" filename# 不会输出任何信息,如果命令运行成功返回0,失败则返回非0值。一般用于条件测试。
cut 列截取工具
在 每个文件 FILE 的 各行 中, 把 提取的 片断 显示在 标准输出.-b, --bytes=LIST 输出 这些 字节-c, --characters=LIST 输出 这些 字符-d, --delimiter=DELIM 使用 DELIM 取代 TAB 做 字段(field) 分隔符-f, --fields=LIST 输出 这些 字段-n 与“-b”选项连用,不分割多字节字符;-s, --only-delimited 不显示 没有 分隔符 的 行--output-delimiter=STRING 使用 STRING 作为 输出分隔符, 缺省 (的 输出分隔符) 为 输入分隔符--help 显示 帮助信息, 然后 结束--version 显示 版本信息, 然后 结束使用 且 只使用 -b, -c 或 -f 中的 一个 选项. LIST 由 一个 范围 (range) 或 逗号 隔开的 多个 范围 组成. 范围 是 下列 形式 之一:N 第 N 个 字节, 字符 或 字段, 从 1 计数 起N- 从 第 N 个 字节, 字符 或 字段 直至 行尾N-M 从 第 N 到 第 M (并包括 第M) 个 字节, 字符 或 字段-M 从 第 1 到 第 M (并包括 第M) 个 字节, 字符 或 字段如果 没有 指定 文件 FILE, 或 FILE 是 -, 就从 标准输入 读取 数据.
实例:
[root@localhost ~]# cat /etc/passwd | cut -b 1 |head -5 #输出文件的第一个字节
r
b
d
a
l
[root@localhost ~]# cat /etc/passwd | cut -c 1-4 |head -5 #输出文件的前四个字符
root
bin:
daem
adm:
lp:x
[root@localhost ~]# cat /etc/passwd | cut -f1 -d ':' |head -5 #以:分割文件,输出第一个字段
root
bin
daemon
adm
lp
# cat a.txt
ssss affff dddd fe fsc
rrr f adfa eer ddd
# cat a.txt |cut -f1,3 -d $'\t' #1,3列
ssss dddd
rrr adfa
# cat file.txt
unix or linux os
is unix good os
is linux good os
# cut -c4 file.txt #将所有行的第四个字符打印出来。
x
u
l
# cut -c4,6 file.txt #将每一行的第四个和第六个字符打印出来
xo
ui
ln
# cut -c4-7 file.txt #将第四个到第七个字符打印出来,注意是闭区间。
x or
unix
linu
# cut -c-6 file.txt #将每一行的前六个字符都打印出来
unix o
is uni
is lin
# cut -c10- file.txt #将从起始位置到行末的所有文本都打印出来
inux os
ood os
good os
# cut -d ' ' -f2 file.txt #定义空格为一行的分隔符,并将每一行的第二个字段打印出来
or
unix
linux
# cut -d ' ' -f2,3 file.txt #将第二个字段和第三个字段打印出来
or linux
unix good
linux good
# cut -d ' ' -f1-3 file.txt #将第一个字段、第二个字段、第三个字段的内容都打印出来
# cut -d ' ' -f-3 file.txt #将前三个字段都打印出来
sort排序工具
它将文件的每一行作为一个单位,从首字符向后,依次按ASCLL码值进行比较,最后将他们按升序输出。
排序选项:
-b, --ignore-leading-blanks 忽略开头的空白。
-d, --dictionary-order 仅考虑空白、字母、数字。
-f, --ignore-case 将小写字母作为大写字母考虑。
-g, --general-numeric-sort 根据数字排序。
-i, --ignore-nonprinting 排除不可打印字符。
-M, --month-sort 按照非月份、一月、十二月的顺序排序。
-h, --human-numeric-sort 根据存储容量排序(注意使用大写字母,例如:2K 1G)。
-n, --numeric-sort 根据数字排序。
-R, --random-sort 随机排序,但分组相同的行。
--random-source=FILE 从FILE中获取随机长度的字节。
-r, --reverse 将结果倒序排列。
--sort=WORD 根据WORD排序,其中: general-numeric 等价于 -g,human-numeric 等价于 -h,month 等价于 -M,numeric 等价于 -n,random 等价于 -R,version 等价于 -V。
-V, --version-sort 文本中(版本)数字的自然排序。
其他选项:
--batch-size=NMERGE 一次合并最多NMERGE个输入;超过部分使用临时文件。
-c, --check, --check=diagnose-first 检查输入是否已排序,该操作不会执行排序。
-C, --check=quiet, --check=silent 类似于 -c 选项,但不输出第一个未排序的行。
--compress-program=PROG 使用PROG压缩临时文件;使用PROG -d解压缩。
--debug 注释用于排序的行,发送可疑用法的警报到stderr。
-m, --merge 合并已排序文件,之后不再排序。
-o, --output=FILE 将结果写入FILE而不是标准输出。
-s, --stable 通过禁用最后的比较来稳定排序。
-S, --buffer-size=SIZE 使用SIZE作为内存缓存大小。
-t, --field-separator=SEP 使用SEP作为列的分隔符。
-T, --temporary-directory=DIR 使用DIR作为临时目录,而不是 $TMPDIR 或 /tmp;多次使用该选项指定多个临时目录。
--parallel=N 将并发运行的排序数更改为N。
-u, --unique 去除重复行
-z, --zero-terminated 设置行终止符为NUL(空),而不是换行符。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
KEYDEF的格式为:F[.C][OPTS][,F[.C][OPTS]] ,表示开始到结束的位置。
F表示列的编号
C表示
OPTS为[bdfgiMhnRrV]中的一到多个字符,用于覆盖当前排序选项。
使用--debug选项可诊断出错误的用法。
SIZE 可以有以下的乘法后缀:
% 内存的1%;
b 1;
K 第N列
[root@www ~]# cat /etc/passwd | sort #sort 是默认以第一个数据来排序,而且默认是以字符串形式来排序,所以由字母 a 开始升序排序。
[root@www ~]# cat /etc/passwd | sort -t ':' -k 3 #/etc/passwd 内容是以 : 来分隔的,我想以第三栏来排序,该如何
[root@www ~]# cat /etc/passwd | sort -t ':' -k 3n #用数字排序,默认是以字符串来排序的
[root@www ~]# cat /etc/passwd | sort -t ':' -k 3nr #倒序排列,默认是升序排序
[root@www ~]# cat /etc/passwd | sort -t':' -k 6.2,6.4 -k 1r #对/etc/passwd,先以第六个域的第2个字符到第4个字符进行正向排序,再基于第一个域进行反向排序
[root@www ~]# cat /etc/passwd | sort -t':' -k 7 -u #查看/etc/passwd有多少个shell:对/etc/passwd的第七个域进行排序,然后去重
uniq邻近行去重工具
显示或忽略重复的行。
主要用途
- 将输入文件(或标准输入)中邻近的重复行写入到输出文件(或标准输出)中。
- 当没有选项时,邻近的重复行将合并为一个。
选项
-c, --count 在每行开头增加重复次数。
-d, --repeated 所有邻近的重复行只被打印一次。
-D 所有邻近的重复行将全部打印。
--all-repeated[=METHOD] 类似于 -D,但允许每组之间以空行分割。METHOD取值范围{none(默认),prepend,separate}。
-f, --skip-fields=N 跳过对前N个列的比较。
--group[=METHOD] 显示所有行,允许每组之间以空行分割。METHOD取值范围:{separate(默认),prepend,append,both}。
-i, --ignore-case 忽略大小写的差异。
-s, --skip-chars=N 跳过对前N个字符的比较。
-u, --unique 只打印非邻近的重复行。
-z, --zero-terminated 设置行终止符为NUL(空),而不是换行符。
-w, --check-chars=N 只对每行前N个字符进行比较。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
参数
INPUT(可选):输入文件,不提供时为标准输入。
OUTPUT(可选):输出文件,不提供时为标准输出。
返回值
返回0表示成功,返回非0值表示失败。
例1
[root@localhost ~]# cat uniqtest #测试文件
this is a test
this is a test
this is a test
i am tank
i love tank
i love tank
this is a test
whom have a try
WhoM have a try
you have a try
i want to abroad
those are good men
we are good men
[zhangy@BlackGhost mytest]$ uniq -c uniqtest #uniq的一个特性,检查重复行的时候,只会检查相邻的行。重复数据,肯定有很多不是相邻在一起的
3 this is a test
1 i am tank
2 i love tank
1 this is a test #和第一行是重复的
1 whom have a try
1 WhoM have a try
1 you? have a try
1 i want to abroad
1 those are good men
1 we are good men
[zhangy@BlackGhost mytest]$ sort uniqtest |uniq -c #这样就可以解决上个例子中提到的问题
1 WhoM have a try
1 i am tank
2 i love tank
1 i want to abroad
4 this is a test
1 those are good men
1 we are good men
1 whom have a try
1 you have a try
[zhangy@BlackGhost mytest]$ uniq -d -c uniqtest #uniq -d 只显示重复的行
3 this is a test
2 i love tank
[zhangy@BlackGhost mytest]$ uniq -D uniqtest #uniq -D 只显示重复的行,并且把重复几行都显示出来。他不能和-c一起使用
this is a test
this is a test
this is a test
i love tank
i love tank
[zhangy@BlackGhost mytest]$ uniq -f 1 -c uniqtest #在这里those只有一行,显示的却是重复了,这是因为,-f 1 忽略了第一列,检查重复从第二字段开始的。
3 this is a test
1 i am tank
2 i love tank
1 this is a test
2 whom have a try
1 you have a try
1 i want to abroad
2 those are good men #只有一行,显示二行
[zhangy@BlackGhost mytest]$ uniq -i -c uniqtest #检查的时候,不区分大小写
3 this is a test
1 i am tank
2 i love tank
1 this is a test
2 whom have a try #一个大写,一个小写
1 you have a try
1 i want to abroad
1 those are good men
1 we are good men
[zhangy@BlackGhost mytest]$ uniq -s 4 -c uniqtest #检查的时候,不考虑前4个字符,这样whom have a try 就和 you have a try 就一样了。
3 this is a test
1 i am tank
2 i love tank
1 this is a test
3 whom have a try #根上一个例子有什么不同
1 i want to abroad
1 those are good men
1 we are good men
[zhangy@BlackGhost mytest]$ uniq -u uniqtest #去重复的项,然后全部显示出来
i am tank
this is a test
whom have a try
WhoM have a try
you have a try
want to abroad
those are good men
we are good men
[zhangy@BlackGhost mytest]$ uniq -w 2 -c uniqtest #对每行第2个字符以后的内容不作检查,所以i am tank 根 i love tank就一样了。
3 this is a test
3 i am tank
1 this is a test
1 whom have a try
1 WhoM have a try
1 you have a try
1 i want to abroad
1 those are good men
1 we are good men
例2
# grep -oE '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}' /var/log/nginx/access.log |sort |uniq -c #查看nginx访问IP数
1 101.200.78.64
2 103.41.52.94
1 106.185.47.161
2 113.240.250.155
260 13.0.782.215
2 185.130.5.231
26 192.168.10.16
6 192.168.10.17
148 192.168.10.2
189 192.168.10.202
270 192.168.10.222
25 192.168.10.235
291 192.168.10.3
12 192.168.10.5
2 23.251.63.45
20 7.0.11.0
tee工具
用来将标准输入的内容输出到标准输出并可以保存为文件
长选项与短选项等价
-a, --append 追加到文件中而不是覆盖。
-i, --ignore-interrupts 忽略中断信号(Ctrl+c中断操作无效)。
-p 诊断写入非管道的错误。
--output-error[=MODE] 设置写错误时的行为,请查看下方的MODE部分。
--help 显示帮助信息并退出。
--version 显示版本信息并退出。
grep -v '^#' vsftpd.conf |grep -v '^$' |tee vsftpd.conf.bak
解释:将vsftpd.conf 文件种不以#开头且不是空行的文件打印屏幕并输出到vsftpd.conf.bak文件中
diff逐行找不同
比较给定的两个文件的不同。如果使用“-”代替“文件”参数,则要比较的内容将来自标准输入。diff命令是以逐行的方式,比较文本文件的异同处。如果该命令指定进行目录的比较,则将会比较该目录中具有相同文件名的文件,而不会对其子目录文件进行任何比较操作。
注意:diff描述俩个文件不同的方式是告诉我们怎样改变第一个文件之后与第二个文件匹配
-<行数>:指定要显示多少行的文本。此参数必须与-c或-u参数一并使用;
-a或——text:diff预设只会逐行比较文本文件;
-b或--ignore-space-change:不检查空格字符的不同;
-B或--ignore-blank-lines:不检查空白行;
-c:显示全部内容,并标出不同之处;
-C<行数>或--context<行数>:与执行“-c-<行数>”指令相同;
-d或——minimal:使用不同的演算法,以小的单位来做比较;
-D<巨集名称>或ifdef<巨集名称>:此参数的输出格式可用于前置处理器巨集;
-e或——ed:此参数的输出格式可用于ed的script文件;
-f或-forward-ed:输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处;
-H或--speed-large-files:比较大文件时,可加快速度;
-l<字符或字符串>或--ignore-matching-lines<字符或字符串>:若两个文件在某几行有所不同,而之际航同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异;
-i或--ignore-case:不检查大小写的不同;
-l或——paginate:将结果交由pr程序来分页;
-n或——rcs:将比较结果以RCS的格式来显示;
-N或--new-file:在比较目录时,若文件A仅出现在某个目录中,预设会显示:Only in目录,文件A 若使用-N参数,则diff会将文件A 与一个空白的文件比较;
-p:若比较的文件为C语言的程序码文件时,显示差异所在的函数名称;
-P或--unidirectional-new-file:与-N类似,但只有当第二个目录包含了第一个目录所没有的文件时,才会将这个文件与空白的文件做比较;
-q或--brief:仅显示有无差异,不显示详细的信息;
-r或——recursive:比较子目录中的文件;
-s或--report-identical-files:若没有发现任何差异,仍然显示信息;
-S<文件>或--starting-file<文件>:在比较目录时,从指定的文件开始比较;
-t或--expand-tabs:在输出时,将tab字符展开;
-T或--initial-tab:在每行前面加上tab字符以便对齐;
-u,-U<列数>或--unified=<列数>:以合并的方式来显示文件内容的不同;
-v或——version:显示版本信息;
-w或--ignore-all-space:忽略全部的空格字符;
-W<宽度>或--width<宽度>:在使用-y参数时,指定栏宽;
-x<文件名或目录>或--exclude<文件名或目录>:不比较选项中所指定的文件或目录;
-X<文件>或--exclude-from<文件>;您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件;
-y或--side-by-side:以并列的方式显示文件的异同之处;
--help:显示帮助;
--left-column:在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容;
--suppress-common-lines:在使用-y参数时,仅显示不同之处。
实例:
[root@localhost www]# diff test1.rb test.rb #比较二个文件的不同
1c1,6
< puts "hekkk"
---
> require "mysql"
> dbc=Mysql.real_connect('localhost','root','','test')
> query_parse=dbc.query('select * from user')
> while row=query_parse.fetch_row do
> puts "#{row[0]},#{row[1]}"
> end
[root@localhost www]# diff myweb/ html/ #比较二个文件夹的不同
Only in html/: a.php
Only in html/: phpmyadmin
[root@localhost www]# diff -r myweb/ html/ #递归比较二个文件夹的不同
Only in html/: a.php
Only in html/: phpmyadmin
[root@localhost www]# diff -ruN test.rb test1.rb #补定文件的内容
--- test.rb 2013-01-31 21:24:57.000000000 +0800
+++ test1.rb 2013-01-31 21:10:08.000000000 +0800
@@ -1,6 +1 @@
-require "mysql"
-dbc=Mysql.real_connect('localhost','root','','test')
-query_parse=dbc.query('select * from user')
-while row=query_parse.fetch_row do
- puts "#{row[0]},#{row[1]}"
-end
+puts "hekkk"
[root@localhost www]# diff -ruN test.rb test1.rb > test.diff #产生补定文件
正常模式下:
上下文格式显示:
合并格式显示: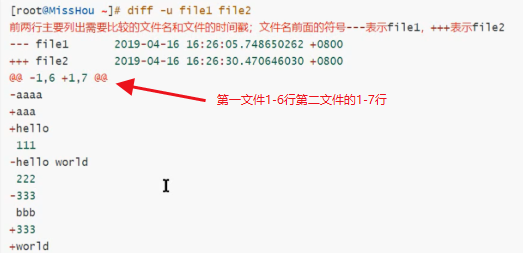
比较俩个目录不同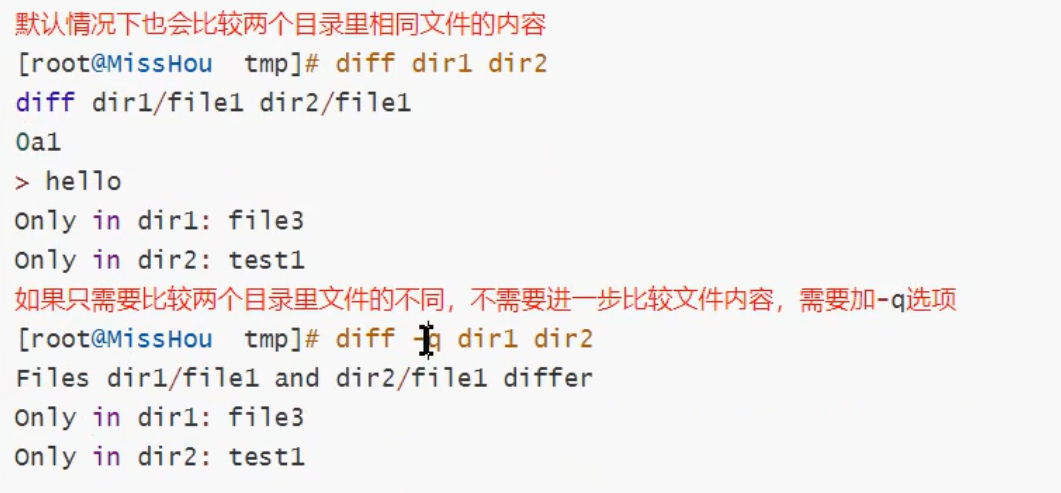
其他小技巧:有时候我们需要以一个文件为标准,去修改另一个文件,并且修改的地方比较多时,我们可以通过打补丁的方式完成。
patch修补文件(补丁)
-b或--backup:备份每一个原始文件;
-B<备份字首字符串>或--prefix=<备份字首字符串>:设置文件备份时,附加在文件名称前面的字首字符串,该字符串可以是路径名称;
-c或--context:把修补数据解译成关联性的差异;
-d<工作目录>或--directory=<工作目录>:设置工作目录;
-D<标示符号>或--ifdef=<标示符号>:用指定的符号把改变的地方标示出来;
-e或--ed:把修补数据解译成ed指令可用的叙述文件;
-E或--remove-empty-files:若修补过后输出的文件其内容是一片空白,则移除该文件;
-f或--force:此参数的效果和指定"-t"参数类似,但会假设修补数据的版本为新版本;
-F<监别列数>或--fuzz<监别列数>:设置监别列数的最大值;
-g<控制数值>或--get=<控制数值>:设置以RSC或SCCS控制修补作业;
-i<修补文件>或--input=<修补文件>:读取指定的修补问家你;
-l或--ignore-whitespace:忽略修补数据与输入数据的跳格,空格字符;
-n或--normal:把修补数据解译成一般性的差异;
-N或--forward:忽略修补的数据较原始文件的版本更旧,或该版本的修补数据已使 用过;
-o<输出文件>或--output=<输出文件>:设置输出文件的名称,修补过的文件会以该名称存放;
-p<剥离层级>或--strip=<剥离层级>:设置欲剥离几层路径名称;
-f<拒绝文件>或--reject-file=<拒绝文件>:设置保存拒绝修补相关信息的文件名称,预设的文件名称为.rej;
-R或--reverse:假设修补数据是由新旧文件交换位置而产生;
-s或--quiet或--silent:不显示指令执行过程,除非发生错误;
-t或--batch:自动略过错误,不询问任何问题;
-T或--set-time:此参数的效果和指定"-Z"参数类似,但以本地时间为主;
-u或--unified:把修补数据解译成一致化的差异;
-v或--version:显示版本信息;
-V<备份方式>或--version-control=<备份方式>:用"-b"参数备份目标文件后,备份文件的字尾会被加上一个备份字符串,这个字符串不仅可用"-z"参数变更,当使用"-V"参数指定不同备份方式时,也会产生不同字尾的备份字符串;
-Y<备份字首字符串>或--basename-prefix=--<备份字首字符串>:设置文件备份时,附加在文件基本名称开头的字首字符串;
-z<备份字尾字符串>或--suffix=<备份字尾字符串>:此参数的效果和指定"-B"参数类似,差别在于修补作业使用的路径与文件名若为src/linux/fs/super.c,加上"backup/"字符串后,文件super.c会备份于/src/linux/fs/backup目录里;
-Z或--set-utc:把修补过的文件更改,存取时间设为UTC;
--backup-if-mismatch:在修补数据不完全吻合,且没有刻意指定要备份文件时,才备份文件;
--binary:以二进制模式读写数据,而不通过标准输出设备;
--help:在线帮助;
--nobackup-if-mismatch:在修补数据不完全吻合,且没有刻意指定要备份文件时,不要备份文件;
--verbose:详细显示指令的执行过程。
使用patch指令将文件”file1″升级,其升级补丁文件为”file.patch”:
[root@linuxcool ~]# patch -p0 file1 file.patch
使用patch来应用补丁:
[root@linuxcool ~]# patch -p0 < foo.patch

若有收获,就点个赞吧
0 人点赞
