- 删除一个目录下所有文件保留指定文件。
- 筛选出catalina.out日志中2021年3月30号9点30分-9点50分的日志(如下两方法)
- 已知文件test.txt内容为:请打印出test.txt内容时,不包括oldboy字符串的命令。
- 已知/tmp目录下已经存在了test.txt文件,如何执行命令才能把/mnt/test.txt拷贝到/tmp下覆盖掉/tmp/test.txt,而让Linux不提示覆盖。(root)
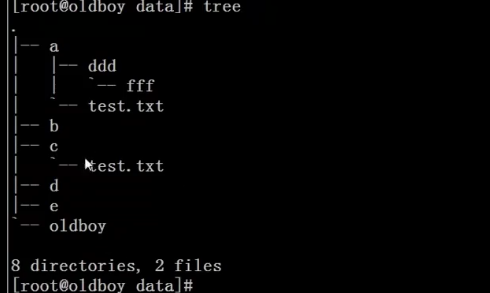
- tree目录树
- 只查看一个文件(100行)内的第20-30行的内容:
- 替换test.txt文件中的oldboy为oldgirl
- 把/oldboy目录下及其子目录下所有以.txt文件中包含oldboy的字符串全部替换为oldgirl
- 批量创建目录100个
- 调出最近执行的命令
- 查询最近一次以m开头执行的命令:
- 查看执行命令历史记录:
- 回到上一次用户所在目录:
- 打印第一列和第二列
- 清掉文件内所有内容:
- 查看系统版本内核位数
- 设置开机自启动服务:
- 基础正则表达式:
- 利用shell中awk和xargs以及sed将多行多列文本中某一列合并成一行
- linux系统磁盘分区知识介绍:
- Linux筛选top前五行信息
- 用进程号发服务路径
删除一个目录下所有文件保留指定文件。
find /root/data/ -type f ! -name “zktest.txt” |xargs rm -f
注释:!(非 取反)表示这个名字外 {}表示传递的数据 -type文件类型
find /root/data/ -type f ! -name “zktest.txt” exec rm -f {} \;
注释:它的终止是以;为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。{} 花括号代表前面find查找出来的文件名。
筛选出catalina.out日志中2021年3月30号9点30分-9点50分的日志(如下两方法)
sed -n ‘/2021-03-30 09:[3-5][0-9]:[0-9][0-9]/p’ catalina.out
grep -E ‘2021-03-30 09:[3-5][0-9]:[0-9][0-9]’ catalina.out
注释:09:表示09时,[3-5][0-9]表示(30、31、32…59、59),[0-9][0-9]表示(00-99)秒
-n表示取消自动打印模式空间 -p列印,亦即将某个选择的资料印出。通常 p 会与参数 sed -n 一起运作~ -E表示使用正则表达式。
已知文件test.txt内容为:请打印出test.txt内容时,不包括oldboy字符串的命令。
test
liyao
oldboy
grep -v “oldboy” test.txt
sed ‘/oldboy/d’ test.txt (d:删除)
sed -n ‘/oldboy/p’ test.txt(n:取消自动打印 p:打印到屏幕)
已知/tmp目录下已经存在了test.txt文件,如何执行命令才能把/mnt/test.txt拷贝到/tmp下覆盖掉/tmp/test.txt,而让Linux不提示覆盖。(root)
Linux命令默认都带别名,比如直接rm会问你要不要删除
alias查看以及定义命令别名
取消别名:unalias
加别名例子:alias cp=’cp -i’
屏蔽别名的两种方法:
定义别名: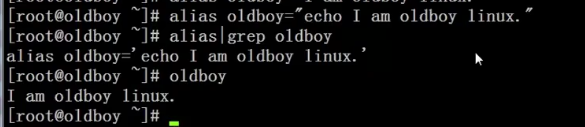
root用户别名生效位置:/root/.bashrc
所有用户别名生效位置:/etc/bashrc或/etc/profile
tree目录树
只查看一个文件(100行)内的第20-30行的内容:
sed -n ‘20,30p’ 文件名
awk ‘{if(NR<31 && NR>19) print $1 “\n”}’ test.txt
注释: 条件判断NR(行号)小于31大于19的数据输出并结合回车
grep 30 -B 10 文件名
grep 20 -A 10 文件名
grep 25 -C 5 文件名
注释:-B打印匹配本身以及前面的几个行,表示过滤30开始往前10行的数据
-B, —before-context=NUM 打印匹配本身以及前面的几个行由NUM控制
-A, —after-context=NUM 打印匹配本身以及随后的几个行由NUM控制
-C, —context=NUM 打印匹配本身以及随后,前面的几个行由NUM控制
(grep适合过滤 sed适合筛选行、替换 awk适合筛选列)
替换test.txt文件中的oldboy为oldgirl
sed ‘s#oldboy#oldboy#g’ test.txt(这样的替换不会改变实际文件内容)
sed -i’s#oldboy#oldboy#g’ test.txt(将改变内容插入到实际文件中)
前俩#号间表示准备替换的后俩表示要替换成的,#号为分隔符可以用@和/等代替。
s 替换指定字符 g(全部) 获得内存缓冲区的内容,并替代当前模板块中的文本
把/oldboy目录下及其子目录下所有以.txt文件中包含oldboy的字符串全部替换为oldgirl
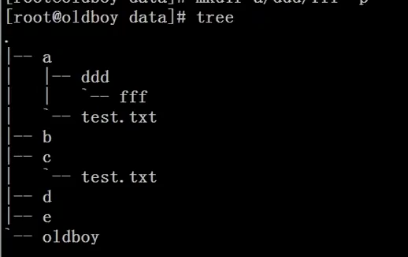
查看所有路径
find ./ -type f -name “test.txt” |sargs sed -i ‘s#oldboy#oldgirl#g’
find ./ -type f -name “test.txt” -exec sed -i ‘s#oldboy#oldgirl#g’ {} \;
批量创建目录100个
调出最近执行的命令

查询最近一次以m开头执行的命令:
查看执行命令历史记录:
回到上一次用户所在目录:
- 由OLDPWD控制
cd -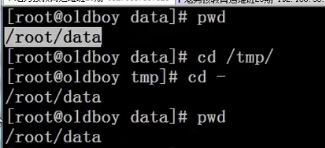
打印第一列和第二列

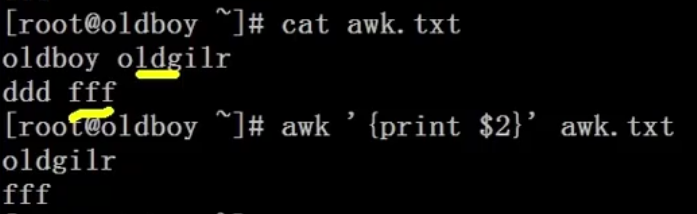
-F指定分隔符
清掉文件内所有内容:
查看系统版本内核位数
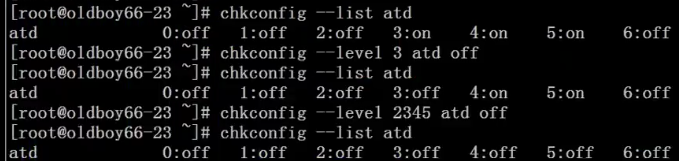
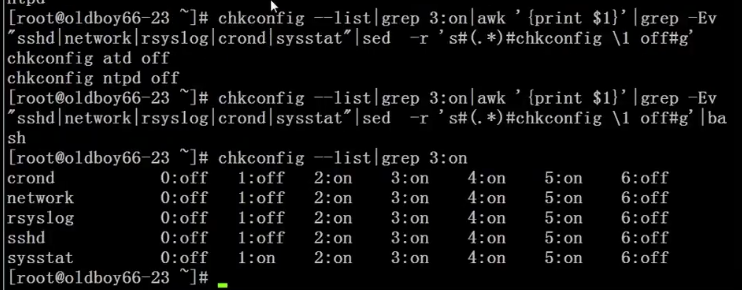
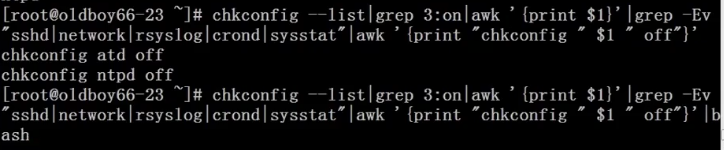
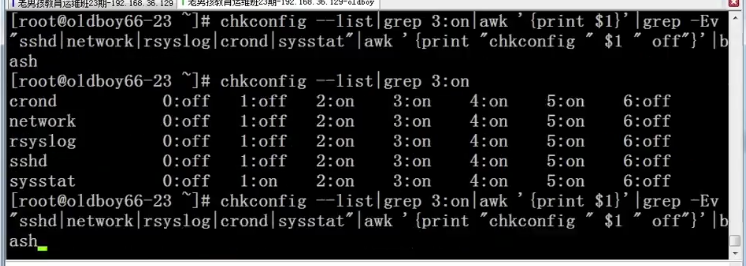
设置开机自启动服务:
控制Linux服务启动命令:chkconfig —list
只关闭atd的3模式:
基础正则表达式:

sed -r ‘s#()#\1#g’ oldboy.txt (第一个括号可以内可以使用正则匹配,-r表示使用正则表达式)解释:把前面正则匹配的括号内的结果,在后面用\1取出来操作。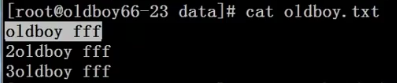
例子1:sed -r ‘s#(.*) fff#\1#g’ oldboy.txt
例子2:sed -r ‘s#(.*)ff#\1#g’ oldboy.txt
例子3:sed -r ‘s#(.) (.)#\1 \2#g’ oldboy.txt
例子4:将文件中包含3306和1521的字符串的过滤出来
为普通用户添加权限:
sudo命令:
配置文件再/etc/sudoers
编辑配置文件时visudo和vi /etc/sudoers
修改配置文件来为普通用户添加权限。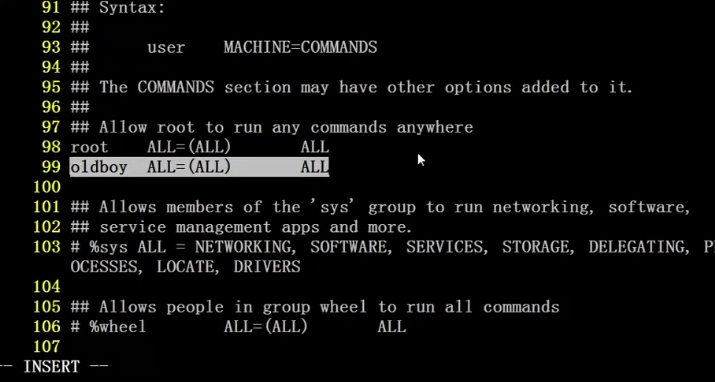
执行试下: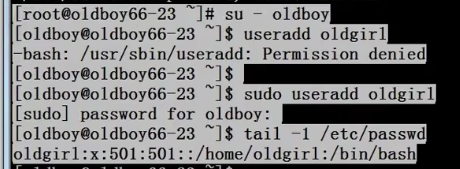
解释:尽管添加上管理员全部权限,但是也得sudo一下才可以用。利用shell中awk和xargs以及sed将多行多列文本中某一列合并成一行
一、问题描述
最近需要利用Shell将多行多列文本中某一列,通过指定的分隔符合并成一行。假设需要处理的文本如下: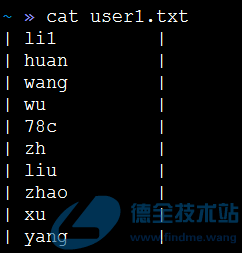
我们主要处理的是,将用户名提取处理,合并成一行,并通过逗号进行分隔。最终的格式如下:
“li1”,”huan”,”wang”,”wu”,”78c”,”zh”,”liu”,”zhao”,”xu”,”yang”
二、解决方案
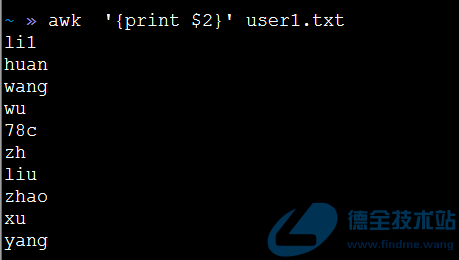
首先是提取每一行的第X列,我最先能够想到的是awk命令,如下:



| 1 | awk ‘{print $2}’ user1.txt |
|---|---|
接着,是不是可以把替换符替换为逗号呢?
使用tr命令
| 1 | awk ‘{print $2}’ user1.txt |tr “\n” “,” |
|---|---|

看着好像是很接近,我们将上面的 , 分隔改为“,”分隔,是不是就okey了呢?命令如下:
| 1 | awk ‘{print $2}’ user1.txt |tr “\n” “\“,\“” |
|---|---|
只是很遗憾,执行效果如下:
为什么呢?
因为tr是单个字符处理工具,而不是字符串处理工具。
既然tr不可以替换字符串,那么咱们就用sed命令。因为sed命令不仅仅可以处理字符,还可以处理字符串。
先来个简单的,将换行替换成逗号,命令如下:
| 1 | awk ‘{print $2}’ user1.txt |sed ‘s/\n/,/g’ |
|---|---|
执行结果如下: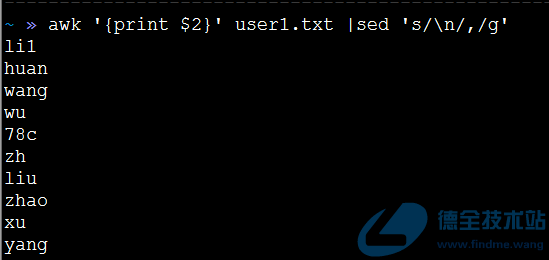
好吧,竟然不听话。为什么呢?
因为sed命令处理过程是:从文本流中读取一行文本后,先把换行符去掉,然后进行相应的命令,处理完后再添加上换行符。这就导致sed命令,无法对换行符进行直接替换。
既然这样行不通,怎么搞呢?
解决方案一:
既然sed不能修改换行符,那就是在使用sed之前,把换行符干掉。干掉换行符,可以使用tr和xargs命令。
| 1 2 3 4 |
#使用xargs命令干掉换行符 awk ‘{print $2}’ user1.txt |xargs #使用tr命令干掉换行符 awk ‘{print $2}’ user1.txt |tr “\n” “ “ |
|---|---|
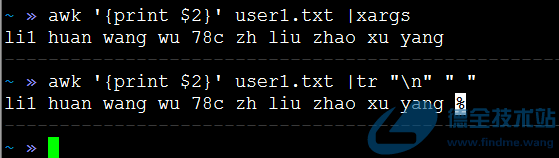
使用sed命令将空格替换成“,”,命令如下:
| 1 | awk ‘{print $2}’ user1.txt |xargs |sed ‘s/ /“,”/g’ |
|---|---|

但是开头和结尾少了一个双引号,解决方案如下:
| 1 | echo ‘“‘awk '{print $2}' user1.txt |xargs |sed 's/ /","/g'‘“‘ |
|---|---|

解决方案二:
| 1 | echo ‘“‘awk '{print $2}' user1.txt | sed ':label;N;s/\\n/","/;b label'‘“‘ |
|---|---|

linux系统磁盘分区知识介绍:
primary主分区 lextend拓展分区,扩展分区不能直接用必需在扩展分区上分出逻辑分区才能用。
例如分5个分区:
p主分区 e扩展分区 L逻辑分区
硬盘分区命名及编号方式:




挂载点:


Linux筛选top前五行信息
一般的巡检需要查看cpu的使用率以及swap空间的使用率(当然如果系统并没有使用可以忽略)
top -b -n 1 | grep ‘top -‘ -A 5 > /tmp/top_temp.txt
top -n 1 |head -5
注释:top -b (-b 按批次处理) -n 1 (-n 1 更新1次) |grep ‘top -‘ -A 5 ( -A 打印匹配本身以及随行)
用进程号发服务路径
ll /proc/进程号

若有收获,就点个赞吧
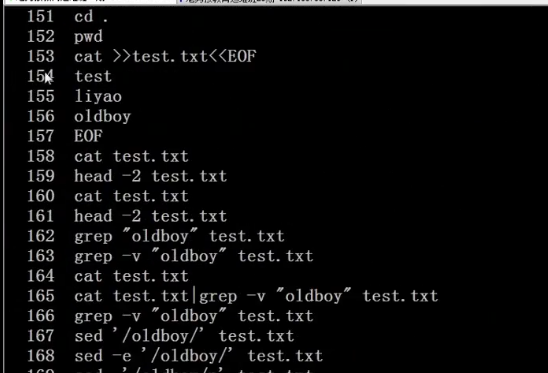
0 人点赞
