- 数据集Binary Classifier for XOR
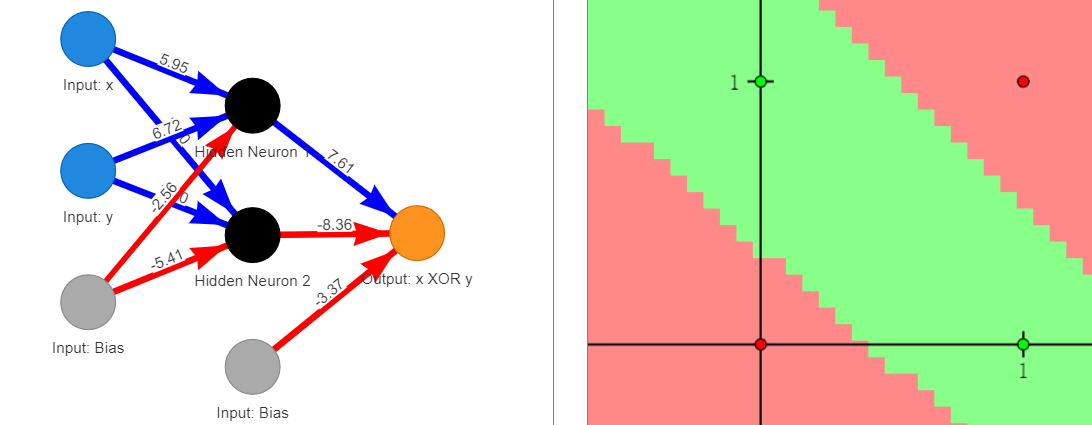
注意:上述隐藏层和输出层神经元是sigmoid
1 如果两个都是linear,无法完成正确分类
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt%matplotlib inline#从输入层到隐藏层mat_1 = np.array([[5.95, 6.72],[3.50, 3.60]])#从隐藏层到输出层mat_2 = np.array([7.61, -8.36])#从输入层到隐藏层的偏置b_1 = np.array([-2.56, -5.41])#从隐藏层到输出层的偏置b_2 = np.array([-3.37])xor_points = [np.array([0, 0]), np.array([0, 1]), np.array([1, 0]), np.array([1, 1])]x = []y = []for point in xor_points:num1, num2 = (mat_1@point+b_1)[0], (mat_1@point+b_1)[1]print(num1, num2)x.append(num1)y.append(num2)plt.scatter(x, y)### 输出结果:对输入样本进行变换之后-2.56 -5.414.16 -1.813.39 -1.910000000000000110.11 1.6899999999999995

直观上看散点图:无法完成线性分类
而且从计算公式来看:从隐藏层到输出层仍然是矩阵 => 矩阵本质是线性变换
plt.scatter([0,0,1,1], [0,1,0,1])plt.plot([0, 0.5],[0.5,0])plt.plot([0, 1.5],[1.5,0])plt.show()
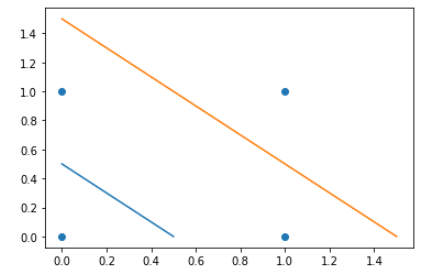
针对蓝色、橙色的线:蓝色的函数曲线表示为
- 左下为负号,右上为正号
- 1)最初的直觉是:改变橙色线的正负号,然后中间区域都是正号,两边区域都是负号
2)实际操作:在橙色线的正负号改变之后,
点(0,0)(应该是负号),由于橙色线的关系,导致最后(0,0)以正号的“权重”为主,最终分类错误
- 右上角的点(1,1)同理
分析|是否线性可分?
分析原因:
- 分类错误的点的权重由于线性分界线的关系,离哪条分界线更近,影响更大
- 改变分界线的正负号时:影响也和距离挂钩
改进思考|假如基于激活函数,非线性化 => 能否达成下列效果?
- 对于分类错误的点:距离越大,影响效果并不是那么明显(比如橙色分界线对(0,0)点的影响) => 还可以“抢救”挽回
- 即如下映射
- D(x)表示矩阵的线性变换/映射
- 表示激活函数(一般是非线性映射):从而类似SVM的核函数,映射到高维空间,从而在高维空间“可分”
- 在下一层线性可分:输出层是linear
- 在下一层非线性可分:配置激活函数
重点|矩阵表示
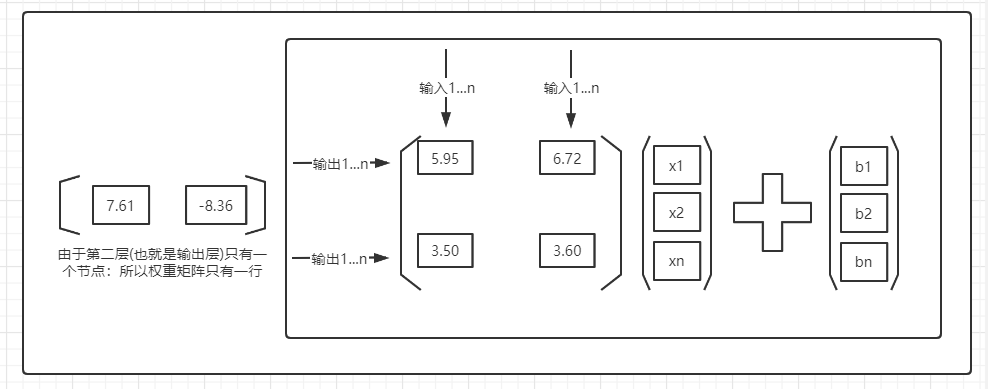
补充|实验
聚焦隐藏层、输出层的激活函数
| linear | 不可行 |
| sigmoid | 可行 |
| tanh | 可行 |
| ReLU | 可行 |
| leak ReLU | 可行 |
| softmax: 多输出/多分类 | 此数据集不适合 |
2 不同的激活函数
| 隐藏层 | 输出层 | 结果 | | —- | —- | —- |
| linear+ | sigmoid | 不可行 |
|
| tanh | 不可行 |
|
| relu | 不可行 |
|
| lrelu | 不可行 |
| sigmoid+ | linear | 可行 |
|
| 其余均可行 | |
| tanh+ | linear | 可行 |
|
| sigmoid | 不可行 说明tanh非线性化的能力有限 |
|
| 其余均可行 | |
| relu+ | linear | 可行 |
|
| 其余均可行 | |
| lrelu+ | linear | 可行 |
|
| tanh | 不可行 |
|
| sigmoid | 很纠结 => 最后过程突然学顺了 |
总结|非线性映射 => 线性可分
1 双曲线(椭圆)
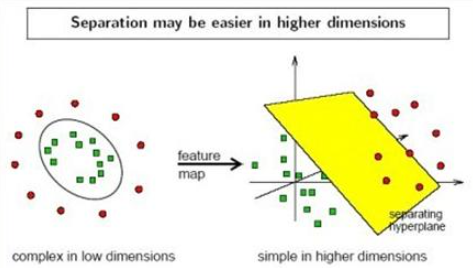
这种变换可以理解为引入了一个非线性变换函数∅(·)将空间的样本X映射到空间,其中n<
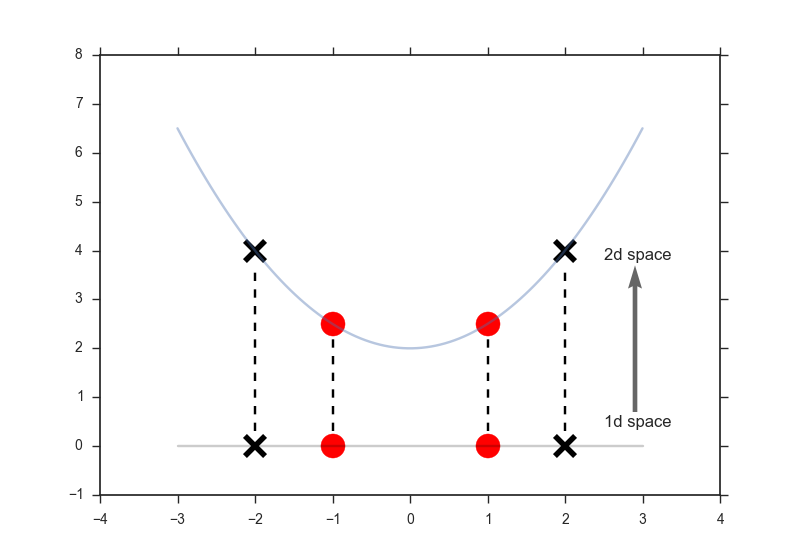
 ## 2 直线到抛物线
## 2 直线到抛物线
 ## 3 理论SVM|西瓜书
## 3 理论SVM|西瓜书

若有收获,就点个赞吧
0 人点赞
