Scala编程语言简介
pass
为什么会有Spark?
- MR对于迭代共享内存处理不够
- 对于本地内存运用不够
-
Data sharing
问题:MapReduce是通过磁盘进行数据共享,I/O以及序列化占据大量时间。
解决:弹性分布式数据集(Resilient Distrubuted Datasets)
理解:能跨集群所有节点,进行并行计算,分区元素集合。【分区:每个集合只进行一部分】
Spark使用RDD以及对应的Transform/Ation进行操作(transform和action是两类算法集合)弹性分布式数据集
进行RDDS的操作后,会生成一个RDDs的集合,其中有依赖关系组成lineage,重计算以及checkpoint来保证分布式计算的容错性。
- 只读,可分区:部分数据可缓存在内存中;弹性:可理解为一个无限大的集合,内存不够时与磁盘进行交换,使用磁盘来进行扩充
例子
在一个存储于HDFS的Log文件中,计算出现ERROR的行数
lines = spark.textFile(“hdfs://...”) //创建一个名为lines的RDD[base RDD]//hdfs上包含多个partition,spark也会构建对应数量的partitionerrors = lines.filter(lambda s: s.startswith(“ERROR”))//lambda匿名函数,s以ERROR开头,存放在errors的RDD中messages = errors.map(lambda s: s.split(‘\t’)[2]) //map进行映射messages.cache() //将RDD缓冲到本地内存messages.filter(lambda s: “foo” in s).count() //过滤并计数messages.filter(lambda s: “bar” in s).count()
Spark基本构架与组件(了解)
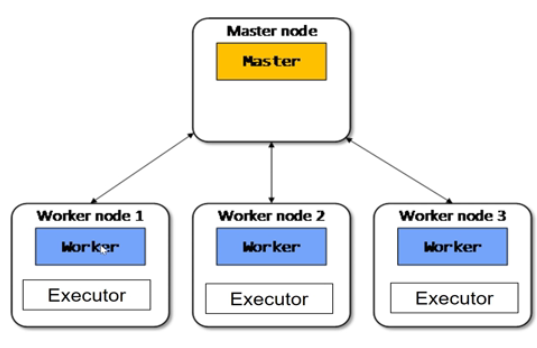
- Master node:是集群部署时的概念,是整个集群的控制器,负责整个集群的正常运行,管理Worker node。
- Worker node:计算节点,接收主节点命令与进行状态汇报;上面分配内存
Executors:每个Worker上有一个Executor,负责完成Task程序的执行
应用架构
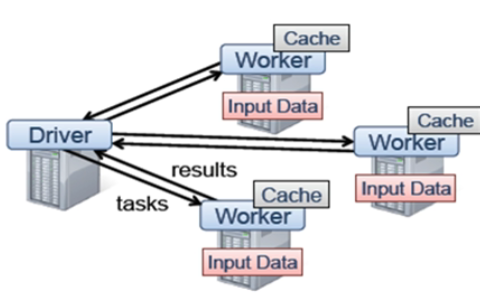
Driver是应用执行起点,负责作业调度
- Worker管理计算节点及创建并行处理任务
- Cache存储中间结果等
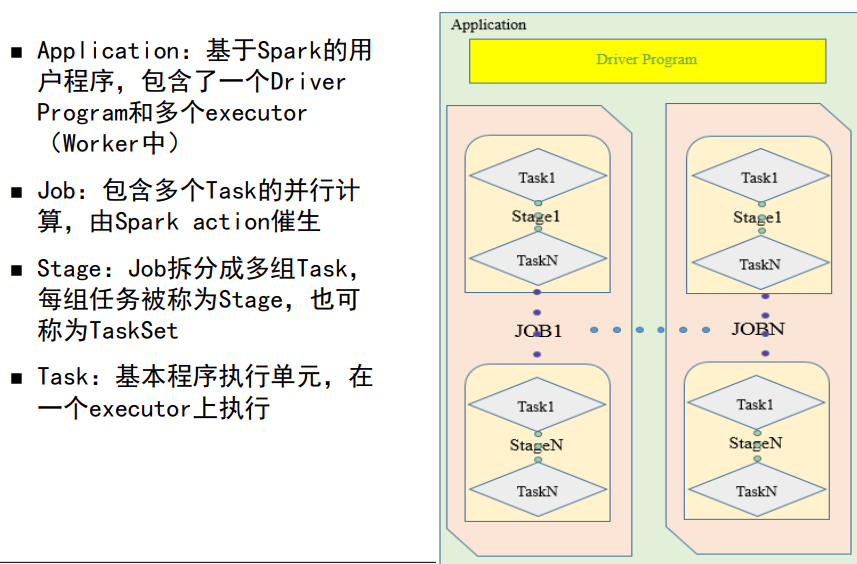

Spark的执行过程
运行框架主节点
- Application: driver program 和 executor
- Driver Program:执行main,创建SparkContext
- Cluster manager:资源调度
- Job:由某个RDD的Action算子 生成或提交 的 一个或多个 一系列的调度阶段。Job中分为多个stage

- Stage生成情况:1.final stage 2.shuffle stage; 原因:运行顺序有一个拓扑关系,需要依赖前者完成
- 一个job是一组Transformation操作和一个action操作的集合。
考点?Task的单位是Partition,针对同一个stage,分发到不同的Partition上执行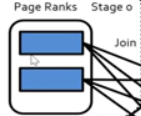 有两个partition**
有两个partition**
Spark技术特点
- RDD: 弹性分布式数据集,最核心的分布式数据抽象。
- Transformation & Action : 在RDD的Transformation时,未进行作业提交;在Action操作时,才会触发SparkContext
- Lineage(世系关系):记录一个RDD世系关系,用于进行RDD数据恢复。
- Spark调度:事件驱动方式;复用线程池的方式来取代MapReduce启动
Spark编程模型和编程接口(了解
示例
def main(args: Array[String]) { //定义一个main函数val conf = new SparkConf().setAppName(“二次排序") //定义一个sparkConf ,//提供Spark运行的各种参数,如程序名称、用户名称等val sc = new SparkContext(conf) //创建Spark的运行环境,并将Spark运行的参数传入Spark的运行环境中val fileRDD =sc.textFile(“hdfs:///root/Log”)//调用Spark的读文件函数,从HDFS//中读取Log文件,输出一个RDD类型的实例: fileRDD//具体类型:RDD[String]val rdd = fileRDD.map(x => x.replaceAll("\\s+"," ").split(" ")).map(x => (x(0),x(1))) //调用RDD的map函数,对RDD中每一行执行括号中定义的函数,//第一个map将多个空白符替换成一个空格,并按照空格进行拆分。//第二个map将上一个map输出的每个数组只取前两个元素,转换为二元组.groupByKey() //调用RDD的groupByKey函数,//该函数用于将RDD[K,V]中每个K对应的V值,合并到一个集合Iterable[V]中。//本示例中K是第一列数据, V是第二列数据。.mapValues(x => x.toList.sortBy(x=>x))//调用RDD的mapValues函数,//同基本转换操作中的map, 区别是mapValues是针对[K,V]中的V值进行map操作。//本示例中将每一个K对应的集合Iterable[V]进行排序。.sortByKey() //调用RDD的sortByKey函数,//该函数用于将RDD[K,V]按照K的顺序进行排序,默认是升序foreach(println) //调用RDD的foreach函数,该函数对RDD中每一行执行括号中定义的函数,//和map函数区别在于://map:用于遍历RDD,将函数f应用于每一个元素,返回新的RDD(transformation算子)。//foreach: 用于遍历RDD,将函数f应用于每一个元素,//无返回值(action算子)。sc.stop() //关闭Spark运行环境}
RDD创建

RDD操作

具体操作,查API表。
RDD容错实现
- Lineage
- Checkpoint
- 对于很长的lineage的RDD,通过lineage来恢复比较耗时。且由于RDD只读,使得Spark比常用的共享内存更容易完成checkpoint
依赖关系
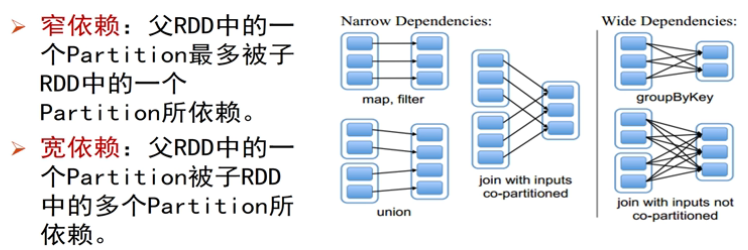
故在此定义下,shuffle操作是一个宽依赖。
持久化
- 未序列化的Java对象,存在内存中。
- 序列化的数据,存在内存中。
- 磁盘存储
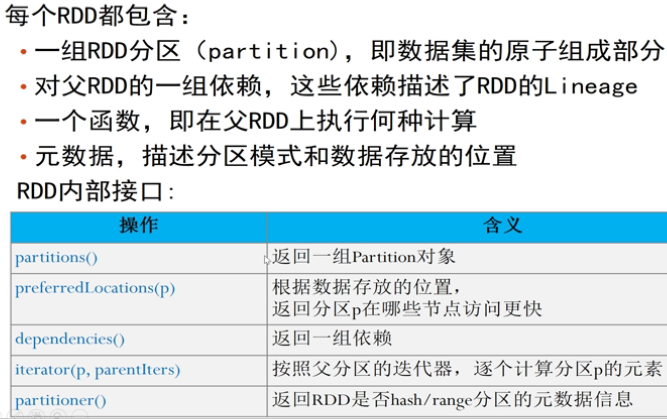
RDD内部结构

若有收获,就点个赞吧
0 人点赞
