数据挖掘的特征: 海量数据
数据越大,机器学习精度越高;当数据不断增长的时候,不同算法分类精度趋近于相同。
->工业界:可以通过增大语料量,而非改进算法来提高精度
K-Means聚类算法
Introduction
- 定义:将给定的多个对象分成若干组;组内各个对象相似,组间的对象不相似。划分过程为聚类过程,划分后的组称为簇(cluster)。
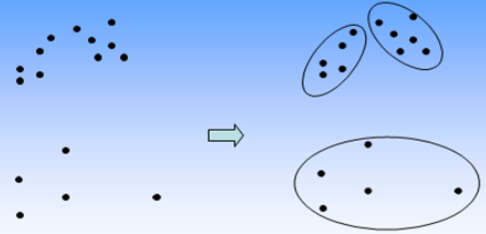
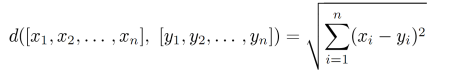

- 给定N个对象,构造K个分组,每个分组代表一个聚类
- 每个分组至少一个对象
- 每个对象仅属于一个分组
- 算法:

Notes:
只用中心点即可以判断新点与cluster的距离。
初始点可以随意选择,最后会自调整成为合适的cluster
每次迭代中心点后,重新计算每个点到聚类的值,再进行归类;若聚类无变化,则结束迭代
- 局限性
- 可由于初始点选取原因,得到的只是一个局部最优解
- 相似度计算与比较时计算较大
MapReduce K-Means并行算法设计【重点】**
数据相关度
- 只需要知道各个cluter的中心点信息;不需要知道其他数据点信息
设计思路
- 每个Map节点读取上一次生成的 cluster centers
- 每个Reduce计算出新的cluster centers
全局文件
- 当前迭代次数
- k个聚类中心
- cluster id
- cluster center
- 属于该cluster center的数据点个数
Map阶段处理
setup()读取cluter center 信息map()对于每个点p,计算与各个center距离,选择dmin作为center; Emitcombiner()对于每个键值对,合并相同ID的数据点,并求这些点的均值pm以及个数n


理解这里的均值算的是什么? 点(x,y)的均值
Notes:

notes:记住这里的n并非由n个1组成,而是由一个长度为n的nums数组组成,例如[1,2,3,4,5….,n],实验bug
终止迭代
在第i次迭代之后,已经生成了K个聚类。
终止条件
分类算法
基本描述
- 作用:从一组已经带有分类标记的训练样本数据集来预测一个测试样本的分类结果
- 描述
- 训练集 TR = {tr1, tr2, tr3….}
- tri = (tid, A, y) : tid为标识符,A是一组特征属性值(a1, a2, ….) ,y是训练样本已知的分类标记。
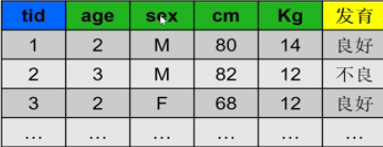
- 测试样本数据集 TS = {ts1, ts2, ts3….} ,区别为y未知 ,发育这一栏为 ?
- 待解决问题: 根据训练数据集来预测每个ts的未知分类标记
基本算法
KNN分类并行算法
- 算法思想: 计算测试样本到各训练样本的距离,选择其中距离最小的k个,根据这k个训练样本标记投票得到测试样本的标记(选择k个是为了消除误差)
- 进阶:加权KNN思想: 距离大小越小,作用权重越大。
- DistributedCache : 全局共享且只可读
- 算法
- Map
- 计算与每个训练样本的相似度 S = Sim(A’,A)
- 存入一个priority queue中,大小为k
- y’ = ∑Si*yi/∑Si 计算出分类标记值y’,Emit (tsid, y’)
- 伪代码
- Map

朴素贝叶斯分类并行化算法
- 问题描述:每个样本有一个n维特征向量(x1,x2,…xn);有m个类,Y1,Y2….
- 算法思想:
- 对于一个未分类数据样本X,若朴素贝叶斯分类将X分配给类Yi,则一定有P(Yi|X)>P(Yj|x),j≠i
- 贝叶斯定理公式:P(Yi|X) = P(X|Yi)*P(Yi)/P(X) [P(x)为常数]
- 假设各属性相互独立,即可把P(X|Yi)展开成为P(x1|Yi)* …. P(xn|Yi)
- 选择P(X|Yi)*P(Yi)概率最大的Yi
- 转换为算法时,实际上就是简单统计Yi以及每个xj在Yi上出现的频度。P(Yi)以及P(xm|Yi)由训练样本所得。
伪代码
【训练】获取一个测试数据文件

- 这里先Emit的是P(Yi),后Emit P(xm|Yi)的频度

【分类】

- 对于每一个Yi,计算出一个值,选择值最大的Yi
SVM短文本多分类并行化算法【不考】
- 问题描述:提供1万条已标注短文本样本数据训练样本,480个类别。测试数据有1000万条短文本数据,且有不属于480类的异常测试样本。每个短文本由一个n维高维特征向量构成。
- 基本算法设计思路
- linear SVM
- 训练:针对每个类做一个2-Class两类分类器
- 预测:用480个分类器对每个待预测样本进行分类并打分(置信度),选择“是”并打分最高的为可能预测类别。打分低于最低阈值的,判定为不属于480类的异常测试样本。
- 算法设计
- 训练
- Map:将每个训练样本的分类标签ClassID作为主键,输出(ClassID,
) - 每个训练样本发射480次,1个true, 479个false
- Reduce: 具有相同ClassID的键值对进入同一个Reduce,然后训练出一个2-Class SVM分类模型
- Map:将每个训练样本的分类标签ClassID作为主键,输出(ClassID,
- 预测
- Map:将每个测试样本,以SampleID作为主键,输出(SampleID,
) [480个] - Reduce:具有相同SampleID的键值对进入同一个Reduce,然后以最高评分者对应的标记作为该样
本最终的标记
- Map:将每个测试样本,以SampleID作为主键,输出(SampleID,
- 训练
- linear SVM

若有收获,就点个赞吧
0 人点赞
