复合键值对的使用
复合键完成排序
【用复合键让系统完成排序,把小的键值对合并成大的键值对】
- 核心思想:进行Partition处理时,系统自动按照map的输出键进行排序。
- 适用情况:value中某些值需要进行排序时,加入key中形成复合键。
- Note:参考前面倒排索引实现,需要实现一个新的Partitioner,保证同一个key的键值对被分到同一个节点上。
小键值对合并成大键值对
例:
用户自定义数据类型
Hadoop内置数据类型
都实现了WritbaleComparable接口,以实现网络传输和文件存储,以及大小比较。
例: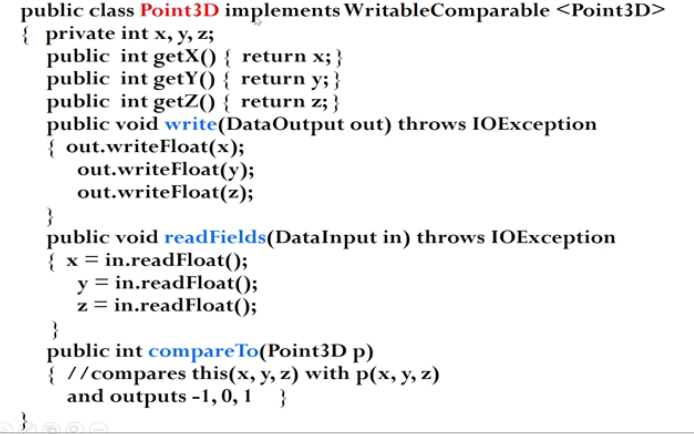
- Write,readFields进行序列化与反序列化,进行网络传输。
- write和read顺序一致,此处为管道模型
Notes:
关于Array,List类型的传输:
- 在readFields里面进行数组或列表初始化
- 对于数组中元素进行拷贝时,注意区分变量为 基本数据类型 or 引用数据类型,否则会出现深拷贝与浅拷贝方面错误
用户自定义输入输出格式
内置
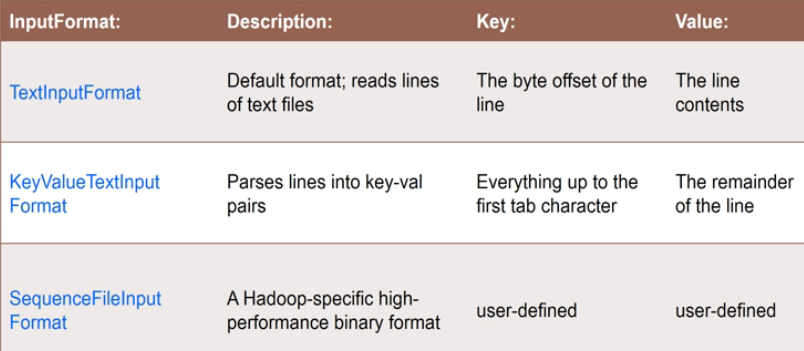

RecordReader用于读取InputFormat
可能考点?[如果需要将行划分为key-val形式读入,使用哪种InputFormat? : KeyValueTextInputFormat]
例子:在倒排索引一节时,期望将offset与filename拼接作为Key:
解决方案:自定义一个RecordReader
代码:
public class FileNameOffsetRecordReader extends RecordReader<Text, Text>{String fileName;LineRecordReader lrr = new LineRecordReader(); //默认的reader……@Override//该函数的返回值,作为map的key的输入,此处将filename与offset进行拼接public Text getCurrentKey() throws IOException, InterruptedException{ return new Text("(" + fileName + “#" + lrr.getCurrentKey() + ")"); }@Override//默认value返回值public Text getCurrentValue() throws IOException, InterruptedException{ return lrr.getCurrentValue(); }@Override//initialize用于获取filename,与Mapper的setup函数类似,在创建时执行public void initialize(InputSplit arg0, TaskAttemptContext arg1)throws IOException, InterruptedException{lrr.initialize(arg0, arg1);fileName = ((FileSplit)arg0).getPath().getName();}}
job.setInputFormatClass(``FileNameOffsetInputFormat``.class); //在Job中进行指定
用户自定义Partitioner和Combiner
考点:为什么Combiner输出时不能改变其输入键值对的格式?答:Combiner的输出是Reducer的输入,添加Combiner的绝不能改变最终的计算结果。
定制Partitioner
Class NewPartitioner extends HashPartitioner<K,V>{ // override the methodvoid getPartition(K key, V value, int numReduceTasks){term = key.toString().split(“,”)[0]; //<term, docid>=>termsuper.getPartition(term, value, numReduceTasks); //调用默认partition函数,} //此处改变的仅是key值}
Job.setPartitionerClass(NewPartitioner)
定制Combiner
作用:减少网络数据的传输量,提高系统效率
public static class NewCombiner extends Reducer< Text, IntWritable, Text, IntWritable >{public void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException{ //具体实现}}
组合式MapReduce的设计【PASS】
基本问题:一些问题难以用一趟MapReduce处理来完成,需要分成多趟MapReduce的子任务组合。
链式作业
每个子任务提供独立的Jobconf,并按照前后子任务间输入输出关系设置路径。例如:

数据依赖关系MapReduce子任务
比如:Z任务,需要依赖X,Y的执行结果。
jobx = new Job(jobxconf, “Jobx");……joby = new Job(jobyconf, “Joby");……jobz = new Job(jobzconf, “Jobz");jobz.addDependingJob(jobx); // jobz将等待jobx执行完毕jobz.addDependingJob(joby); // jobz将等待joby执行完毕JobControl JC = new JobControl(“XYZJob”);JC.addJob(jobx);JC.addJob(joby);JC.addJob(jobz);JC.run()
addDepending实际形成了一个拓扑图,使得JobControl优先处理没有依赖关系的job
预处理和后处理链式执行
Hadoop提供 链式
ChainMapper与ChainReducer完成处理。
但现在Spark能够实现的更好。
多数据源的连接
- 基本问题:MapReduce任务需要访问和处理两个甚至多个数据集。关系数据库中使用Join进行连接,但Hadoop系统没有Join,故需要基于MapReduce来实现Join功能。
- 思想:
- Map中将Key相同的数据发到同一个Reduce进行处理
- Reduce对来自不同表的数据进行笛卡尔积运算
- combine对笛卡尔积结果进行处理
- 例子:

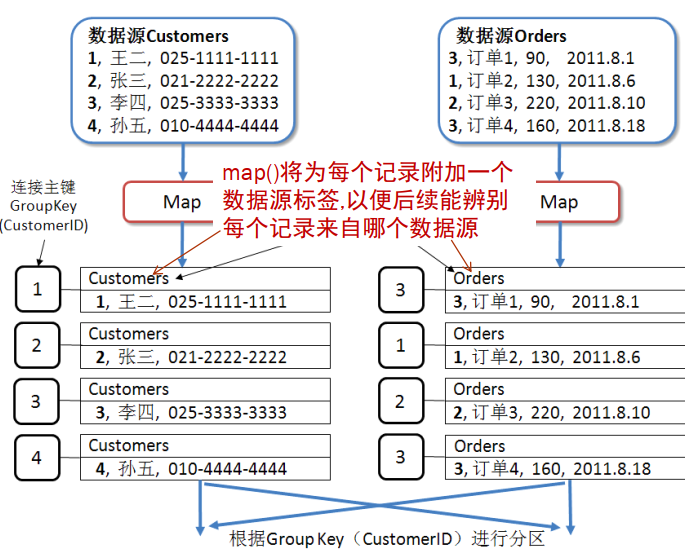

DataJoin类实现Reduce端的Join
课件P46-60,平时使用不多,且不灵活。
【不知道会不会考】
全局参数/数据文件的传递
全局作业参数
- Configuration类提供用于保存和获取属性的方法
mapper/reducer类初始化方法
setup()从confiuration对象中读出属性全局数据文件的传递
使用DistributedCache文件传递机制
Job.addCacheFile(URI uri)//添加文件Path[] cacheFiles = context.getLocalCacheFiles()//获取文件路径
其他处理技术
划分多个输出文件集合
- 应用场景:作业需要输出多个文件集合。
解决方案:MultipleOutputFormat类中的
generateFileNameForKeyValue``(K key, V value,String current_filename)根据键值对和当前数据文件名返回一个输出文件路径
输入输出到关系数据库
- OLTP (online transaction processing)
- 联机事务处理:主要是关系数据库应用系统中前台常规的各种事务处理
- OLAP (online analytical processing)
- 联机分析处理:主要是进行基于数据仓库的后台数据分析和挖掘,提供优化的客户服务和运营决策支持
Q1: OLAP端采用基于关系数据库仓库的解决方案,在数据量巨大的情况下,复杂数据分析和挖掘处理负载很大
解决方案:提供基于MapReduce大规模数据并行处理的OLAP
- 输入输出简单记为普通格式前加个DB

若有收获,就点个赞吧
0 人点赞
