MapReduce的处理流程
- map(K1,V1)->[(K2,V2)]
- shuffle and sort
- reduce(K2,[V2]) -> [(K3,V3)]
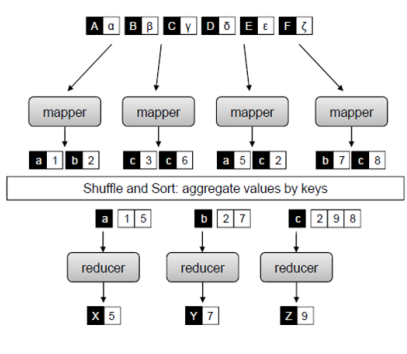
note: 如果在shuffle and sort之后,每一个部分不止一个key,如上图 a->1->5,下面还有一行f->2->4,那么reducer会调用两次分别处理a和f两个key的组
**
可编程控制的阶段
- Mapper
- Initialize:
setup() map():对于每一个input split的键值对,都调用一个map- Close:
cleanup()
- Initialize:
- Shuffle
- Partitioner : 输入为map的结果,由其决定输出到哪个reducer
- 通常为
HashPartitioner - 发到同一个reducer上的item不一定是相同key
- Sort
- 使用comtomized(定制) comparator将key定义为可排序类型
- Reducer
- Initialize:
setup(),eg:打开文件、建立数据库连接 reduce(): 对于每个key调用一次close(),eg:关闭文件,断开连接
- Initialize:
- 常用key-value对数据类型
- Text、ByteWritable、IntWritable….
- 实现WritableComparable接口,进行了序列化(变成byte串)与反序列化操作,从而以便进行网络传输和文件存储,以及大小比较
- Map输出之后的key,需要支持Comparable;因为要进行比较
排序算法
- map(k1, _) -> (k1, _) // Identity function //把要排序的数据作为key,直接emit
- shuffle and sort
- (1) total-order partitioning //自定义partitioner
- (2) local sorting
- reduce(k1, _) -> (k1, _) // Identity function
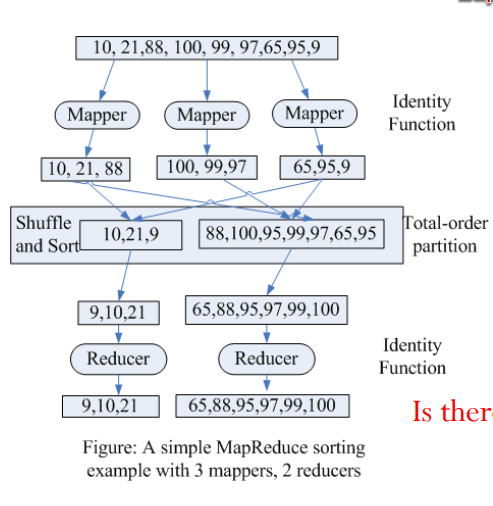
案例分析:
- map直接emit key/value
- 自定义partitioner将数据进行分段,例如上图我们以50为分界线,50以下划分给左侧reducer,以上给右侧
- local sorting,此时reducer所取得即排好序后的数据
- reduce,例如[9,10,21]分别进行三次reduce操作并输出
- 拼接,将左右结果进行拼接即得到排序后的结果
Partitioner 问题与解决
- 问题
- 某些Reducer上数据过多,拖慢整个程序
- 大量key要分配到多个partition时,如何快速找到key所属的partition
- 要求
- 划分均匀
- 查找快速
- 解决方案:
TotalOrderPartitioner
单词同现算法
- 二维矩阵 N x N[N为词汇量],M[i,j]代表单词i与单词j在一定范围内出现的次数。
```
1: class Mapper
2: method Map(docid a, doc d)
3: for all term w ∈ doc d do
4: for all term u ∈ Neighbors(w) do //对于每个word所规定区域内的neighbors 5: //Emit count for each co-occurrence //将其打包为(word,neighbor)的pair进行发射Emit(pair (w, u), count 1)
1: class Reducer 2: method Reduce(pair p; counts [c1, c2,…]) 3: s ← 0 4: for all count c in counts [c1, c2,…] do //键值对count计数 5: s ← s + c //Sum co-occurrence counts 6: Emit(pair p, count s)
<a name="Qz2ED"></a>## 文档倒排索引算法基于索引结构,给出一个词(term),能取得含有这个term的文档列表(the list of docs)<br />代码理解
public class InvertedIndexMapper extends Mapper
StringTokenizer itr = new StringTokenizer(value.toString());
for(; itr.hasMoreTokens(); )
{
word.set(itr.nextToken());
context.write(word, fileName_lineOffset); //emit (word,value)
}
}
}
```public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text>{@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException{Iterator<Text> it = values.iterator(); //此时value是一个队列,对应同一个key下的各个值StringBuilder all = new StringBuilder();if(it.hasNext()) all.append(it.next().toString());for(; it.hasNext(); ){all.append(“;");all.append(it.next().toString());}context.write(key, new Text(all.toString()));} //最终输出键值对示例:(“fish", “doc1#0; doc1#8;doc2#0;doc2#8 ")}
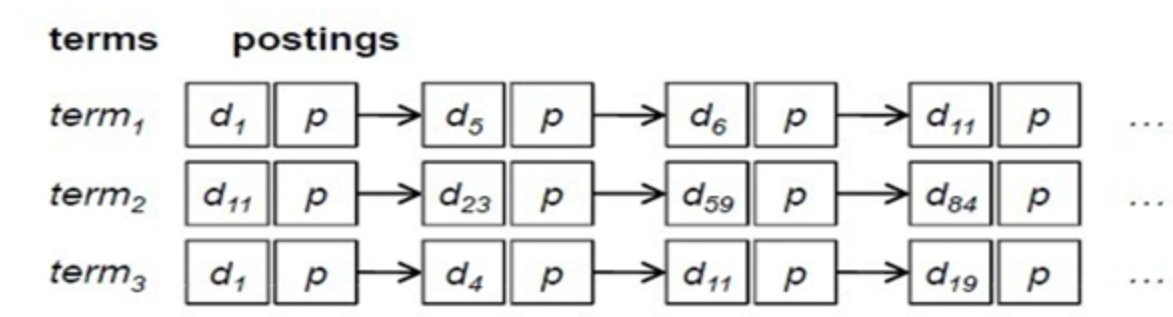
基本的倒排索引结构
带词频属性的文档倒排算法
伪代码实现:
1: class Mapper2: procedure Map(docid dn, doc d)3: F ← new AssociativeArray4: for all term t ∈ doc d do5: F{t} ← F{t} + 1 //统计词频6: for all term t ∈ F do7: Emit(term t, posting <dn, F{t}>) //key:word value:{docn,freq}1: class Reducer2: procedure Reduce(term t, postings [<dn1, f1>, <dn2, f2>…])3: P ← new List4: for all posting <dn, f> ∈ postings [<dn1, f1>, <dn2, f2>…] do5: Append(P, <dn, f>) //拼接操作6: Sort(P)7: Emit(term t; postings P)
补充:可扩展的带词频属性的文档倒排
- 设计思想:将需要排序的部分与原来的key组成一个pair,利用MR框架的shuffle处理进行排序。
伪代码
Mapperclass Mappermethod Map(docid dn; doc d)F ← new AssociativeArrayfor all term t ∈ doc d doF{t} ← F{t} + 1for all term t ∈ F doEmit(tuple<t, dn>, tf F{t}) //此处将word与doc合并成为pair,即可保证对于每个word下面的doc//按字典序排序输出
产生问题:同一个term的键值对可能被分区到不同的Reducer
- 解决方案:定制Partitioner ``` Reducer 1: class Reducer 2: method Setup // 初始化 3: tprev ← Ø; //记录上一个word是否与当前word一致,若不一致,则将上一个word的合并结果emit 4: P ← new PostingsList
5: method Reduce(tuple
11: method Close 12: Emit(t, P) ```
Customized partitioner
easy

若有收获,就点个赞吧
0 人点赞
