CH1
- 单指令单数据流
- 单指令多数据流
- 多指令单数据流
-
按并行类型分类
位级并行
- 指令级并行
线程级并行
共享内存
- 分布共享存储体系结构
-
按系统类型分布
多核并行计算系统
- 对称多处理系统
- 大规模并行处理
- 集群
-
按计算特征
数据密集型并行计算
- 计算密集型…
-
按并行设计模型分类
共享内存变量
- 消息传递方式
- MapReduce方式
如何评估程序的可并行度
程序并行度评估:
Amadahl定律
作用:一个并行程序可加速程度有限,并非可无限加速,并非处理器越多越好。
MPI[了解]
- 功能特点
- 点对点通信
- 节点集合通信
- 用户自定义符合数据类型传输
- 优缺点[相对重要]
- 优点
- 灵活性好
- 可移植性好
- 有众多机构实现与支持
- 缺点
- 无良好数据、任务划分
- 缺少分布文件系统
- 通信开销大
- 无节点失效恢复机制
- 缺少架构支持
- 优点
为什么需要大规模数据并行处理
- 处理数据能力大幅落后于数据增长
- 海量数据隐含更准确信息
【Attention】
CH2
MapReduce对付大数据处理的基本思想是 分而治之 ,主要设计思想是 为大数据处理过程中Map和Reduce操作构建抽象模型[模型], 目的是 为程序员隐藏系统层面的处理细节[框架]。
构建抽象数据模型
- 流式大数据问题特征
- 大量数据重复处理
- 对每条数据只进行感兴趣的处理以及获取结果
- 收集整理中间结果
- 产生最终结果输出
- 抽象描述
- map: (k1;v1) -> [(k2;v2)]
- reduce: (k2;[v2]) -> [(k3;v3)]
- 提供了一种抽象机制,把做什么和怎么做分开。
- 计算模型
- map: 对划分数据并行处理,产生不同中间结果
- reduce: 并行计算,处理不同中间结束数据集合
- 进入Recue前需设置一个barrier,以等待所有的map做完;并对中间结果进行整理与shuffle
上升到框架
主要需求、目标与设计思想

CH3
Google MapReduce基本工作原理
过程:数据进行划分->用户提交作业->master为作业分配map节点并传输数据与程序[你写的]->master为作业分配reduce节点并传输程序->启动map->map处理并进行整理,存放中间结果->reduce读取并汇总
- 失效处理
- master:checkpoint
- 工作节点:终止并重新分配任务给其他节点
- 计算优化:把一个map任务给多个map节点做,取最快做完者。【卷!】
- 带宽优化
- combiner上述作用
- 用数据分区解决数据相关性
- partitioner
GFS基本工作原理【了解,我猜的】
- 廉价本地磁盘分布存储
- 多数据自动备份解决可靠性
为上层的MapReduce计算框架提供支撑
GFS Master作用:提供容错处理以及错误恢复。
- GFS ChunkServer:保存大量实际数据。
- 访问工作工程:(自我理解)
- 应用程序告诉GFS filename或 index —>GFS查找定位,返回位置信息给应用程序 —> 访问对应的chunk server—> 读取数据进行计算处理
系统管理技术
大规模集群安装、故障检测、节点动态加入、节能
BigTable
为什么需要BigTable
需要存储管理海量结构化数据
- 海量服务需求
-
BigTable数据结构
多维表:行关键字、列关键字、时间戳[Hadoop HBase的基本数据模型]
子表服务器[不太重要?]
SSTable:基本存储结构。对应GFS的chunk
- 子表数据格式:子表可以由多个SSTable构成;一个SSTable也可以被多个子表共享
-
HDFS
基本特征【略】
数据分布设计【多副本数据块形式】
可靠性与出错恢复【略】基本框架【ppt写了个锤子】
NameNode:存储和管理分布式系统元数据
DataNode:作为实际存储大规模数据的从节点,存储实际数据
Hadoop MR基本工作原理
JobTracker:Hadoop的主控节点,负责调度管理作业的任务。
- TaskTracker:作为从节点,执行JobTracker分来的任务。
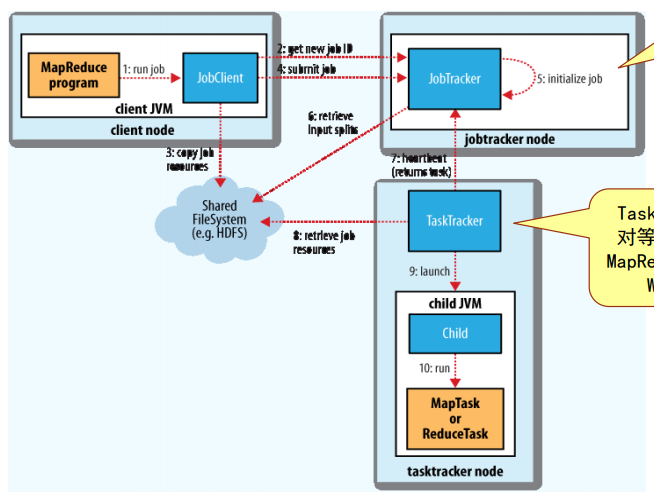
Hadoop MapReduce主要组件[了解]
- InputFormat:定义数据文件如何分割和读取
- InputSplit:定义 输入到 单个Map任务 的输入数据
- RecordReader:定义如何将数据记录转化为(key,value)对
- Mapper :(作用)
- Combiner
- Partitioner
- Reducer :
- OutputFormat
CH5
Call Back
Mapper
- 初始化:
setup() - 清理:
cleanup()
Notes:如果在shuffle and sort之后,每一个部分不止一个key,那么reducer会调用两次分别处理两个key的组 [因为partition函数]
语雀内容
CH6
Hive的基本工作原理
- 使用Hadoop上用SQL进行数据分析
- Hive的组成模块
- HiveQL:Hive的数据查询语言
- Driver:执行驱动程序。
- Complier:编译器,将HiveQL语言编译成中间表示。
- Execution Engine:在Driver的驱动下,具体完成执行操作。
- Metastore:存储元数据(操作的数据对象格式信息,HDFS中存储位置信息等)
- 数据模型
- Tables:Hive数据模型由数据表组成
- Partitions:数据表按照一定的规则划分Partiion
- Buckets:数据存储的桶
Partitions(分区表)与buckets(分桶表)的区别:划分粗细粒度不同,buckets采用更为细粒度的数据范围划分。
CH7
CH8
伪代码
语雀内容
CH9
数据并行算法研究重要性:数据挖掘是通过对大规模观测数据集的分析,大数据中隐含着更为准确的事实。
语雀内容
CH10
为什么需要Spark:MR计算模式缺陷,计算模式产生新变化,很多计算需要data sharing
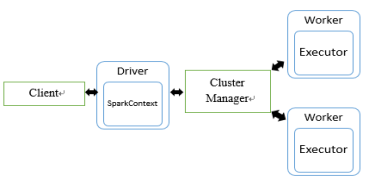
基本构架与组件
- Master node:是集群部署时的概念,是整个集群的控制器,负责整个集群的正常运行,管理Worker node。
- Driver:应用执行起点,负责作业调度
- Worker node:计算节点,接收主节点命令与进行状态汇报;上面分配内存
- Executors:每个Worker上有一个Executor,负责完成Task程序的执行
- 执行过程:Application->Job->Stage->Task
【猜测】
- Stage生成情况:1.final stage 2.shuffle stage; 原因:运行顺序有一个拓扑关系,需要依赖前者完成
- 一个job是一组Transformation操作和一个action操作的集合。**
考点**?Task的单位是Partition,针对同一个stage,分发到不同的Partition上执行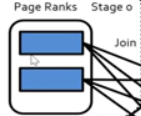 有两个partition**
有两个partition**
技术特点
- RDD(基于内存计算的弹性分布式数据集):核心分布式数据抽象
- Transformation & Action : 在RDD的Transformation时,未进行作业提交;在Action操作时,才会触发SparkContext
- 只读,可分区:部分数据可缓存在内存中;弹性:可理解为一个无限大的集合,内存不够时与磁盘进行交换,使用磁盘来进行扩充
- 灵活的计算流图(DAG)
-
其他功能组件
Spark SQL:用来处理结构化数据的分布式SQL查询引擎
- Spark Streaming:对实时数据进行高吞吐量、容错处理的流式数据处理系统
- GraphX:Spark系统中对图进行表示和并行处理的组件
- MLlib(machine learning lib):Spark的分布式机器学习算法库

若有收获,就点个赞吧
0 人点赞
