DF上的预测算法主要基于深度学习模型来开发,深度学习虽然具有强大的特征提取能力,能够很好地面对复杂多变的实际环境。但是,深度学习也不是万能的,我们需要引入各种技术来辅助深度学习模型进行决策。此外,为了保证算法的失效性,我们的模型也不能太复杂,这也限制了我们通过简单地增加网络层数和节点数来提高模型的拟合能力。
模型架构设计:模型由一个LSTM层,两个全连接层,一个输出层组成。其中,输出层的节点数等于预测的时间步。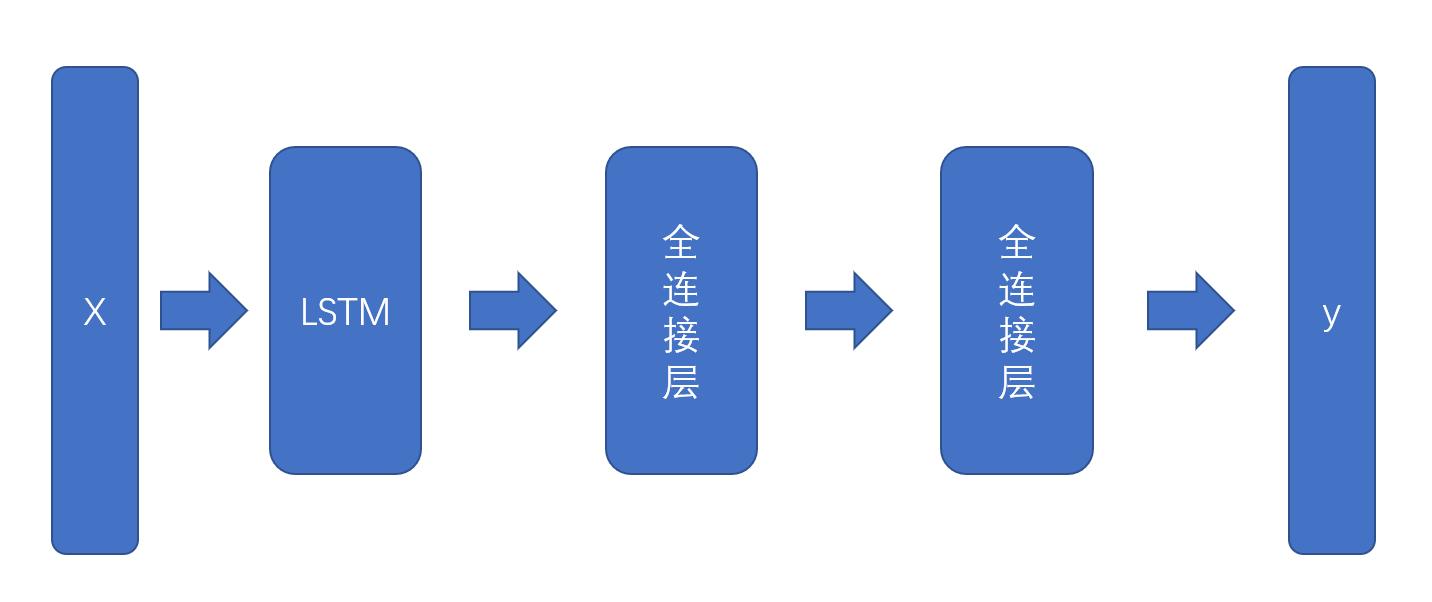
model
model = keras.Sequential()
model.add(layers.LSTM(64,input_shape=(used_steps, 1)))
model.add(layers.Dense(64,activation=’relu’))
model.add(layers.Dense(64, activation=’relu’))
model.add(layers.Dense(forecasted_steps))
外层封装函数:
def forecastmonitor(data, used_steps, forecasted_steps):
‘’’
LSTM预测算法,根据 data 生成训练集,然后使用 LSTM 算法拟合,并预测。
usedsteps为生成的训练集中 x 的特征数,forecasted_steps为生成的训练集中 y 的特征数,
:param data: 指标过去值,[[time,value]] or pd.DataFrame(columns=[time,value])
:param used_steps:使用的时间步,int
:param forecasted_steps: 预测的时间步,int
:return:预测值,[[time,value]]
‘’’
整体预测流程:
step 1: 输入数据,确定函数调用形式
data = [
[100, 1], [101, 1],
[102, 2], [103, 3],
[104, 5], [105, 8],
[106, 13], [107, 21],
[108, 34], [109, 55],
[110, 89], [111, 144]
]
data为时间序列数据,每一个元素代表一个时间步,它由两部分组成,即 time 和 value。如果只看value的部分,你会发现这是一个斐波那契数列:1,1,2,3,5,8,……。假设我们根据前三个时间点来预测后两个时间点,则调用函数如下:
pre = forecast_monitor(deepcopy(data), 4, 2)
pre为函数的预测值,在此,它的理论值为 pre = [ [112, 233], [113, 377] ]
step 2:归一化
首先我们我们把 data 转换成 pandas 的 DataFrame 格式,以便各种计算。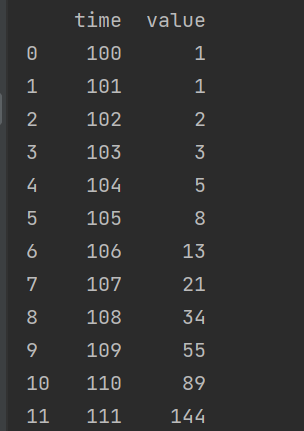
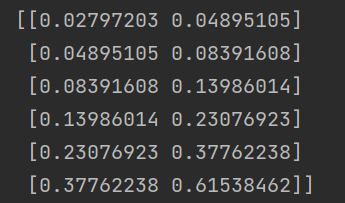
由于 time 在预测中并没有实际作用,因此我们只需要对 value 进行归一化,如采用 0-1 归一化。
处理后的值为: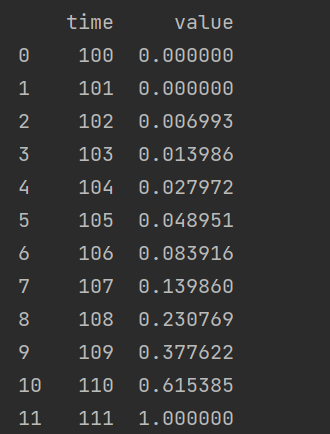
step 3:得到训练集
根据我们调用函数的方式,pre = forecast_monitor(deepcopy(data), 4, 2),我们是根据前4个时间点来预测后2个时间点,则产生的训练集如下:
[1, 1, 2, 3], [5, 8]
[1, 2, 3, 5], [8, 13]
…
为了方便理解,此处我用的是归一化之前的值,实际产生的训练集如下: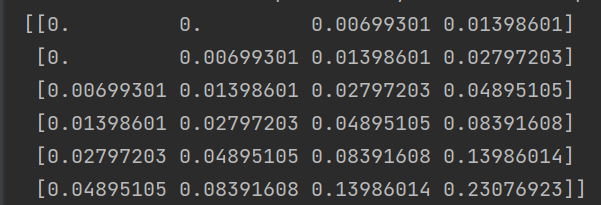
step 4:确定模型,并拟合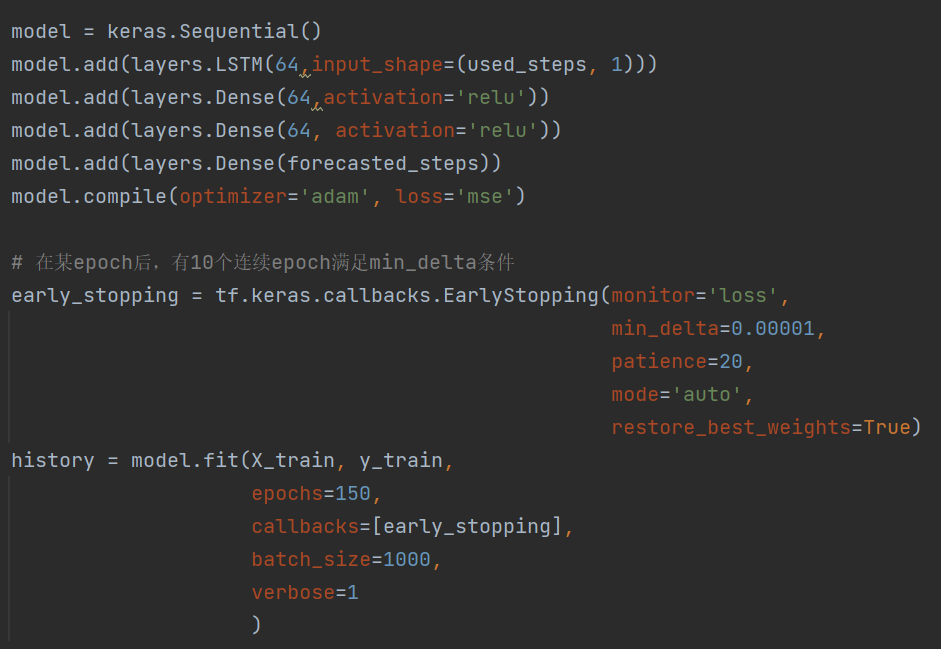
模型采用adam优化器,mse损失函数,并且以1000个样本进行批量梯度下降,此外,模型还引入了提前终止技术。
由于在Tensorflow中,LSTM要求输入必须是一个三位数组,即[ batch_size, time_steps, features ]。在我们的例子中,batchsize=128,time_steps=4, features=1。因此应该构造如下数据集进行训练。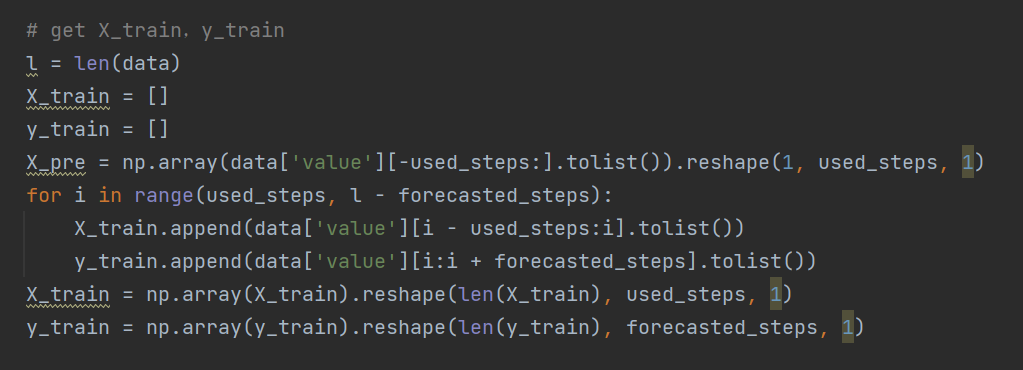
需要注意的是,此处的 features 代表的是一个每个时间点的数据的维度,对于我们的斐波那契数列来说,一个时间点就是一个数字,features=1。
step 5:预测
对于我们的例子,预测的话只需要取最后的4个数据点构成的向量。由于我们使用归一化后的值进行建模,所以预测的值也是归一化后的值,我们还需反归一化来得到实际值。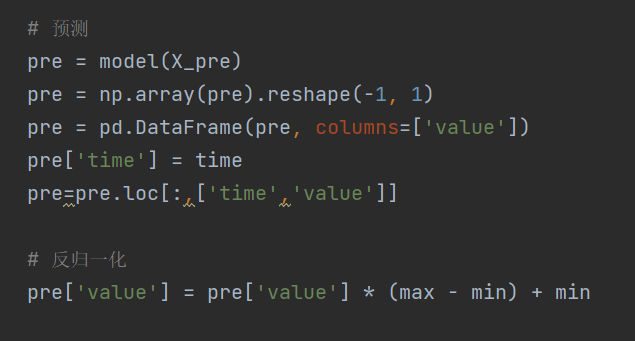
step 6:预测效果
对于上述的斐波那契数列,其预测效果如下: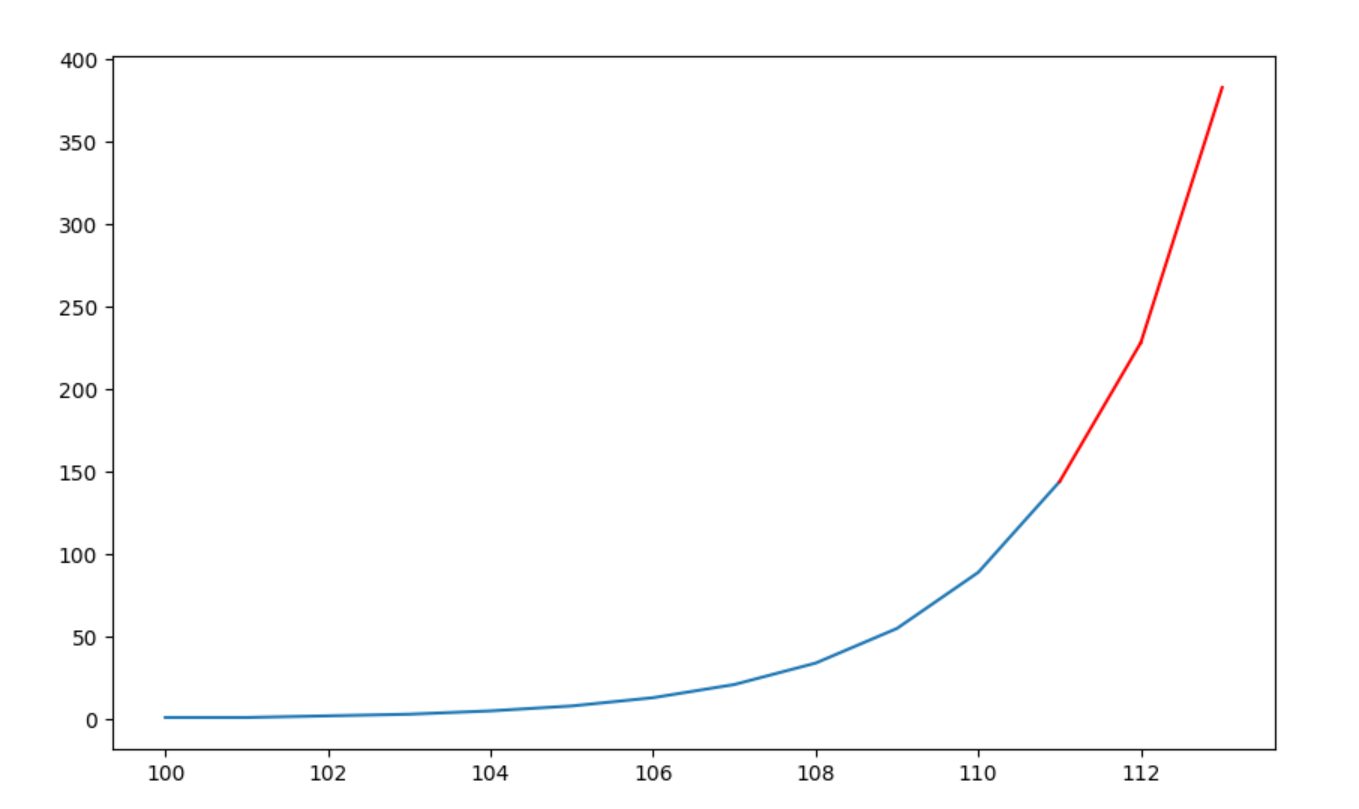
对于[34, 55, 89, 144], 它后面序列的理论值为233,377,实际预测如上所示,为228.33,382.99,大体上比较准确。
对于其他类型的数据,测试结果如下: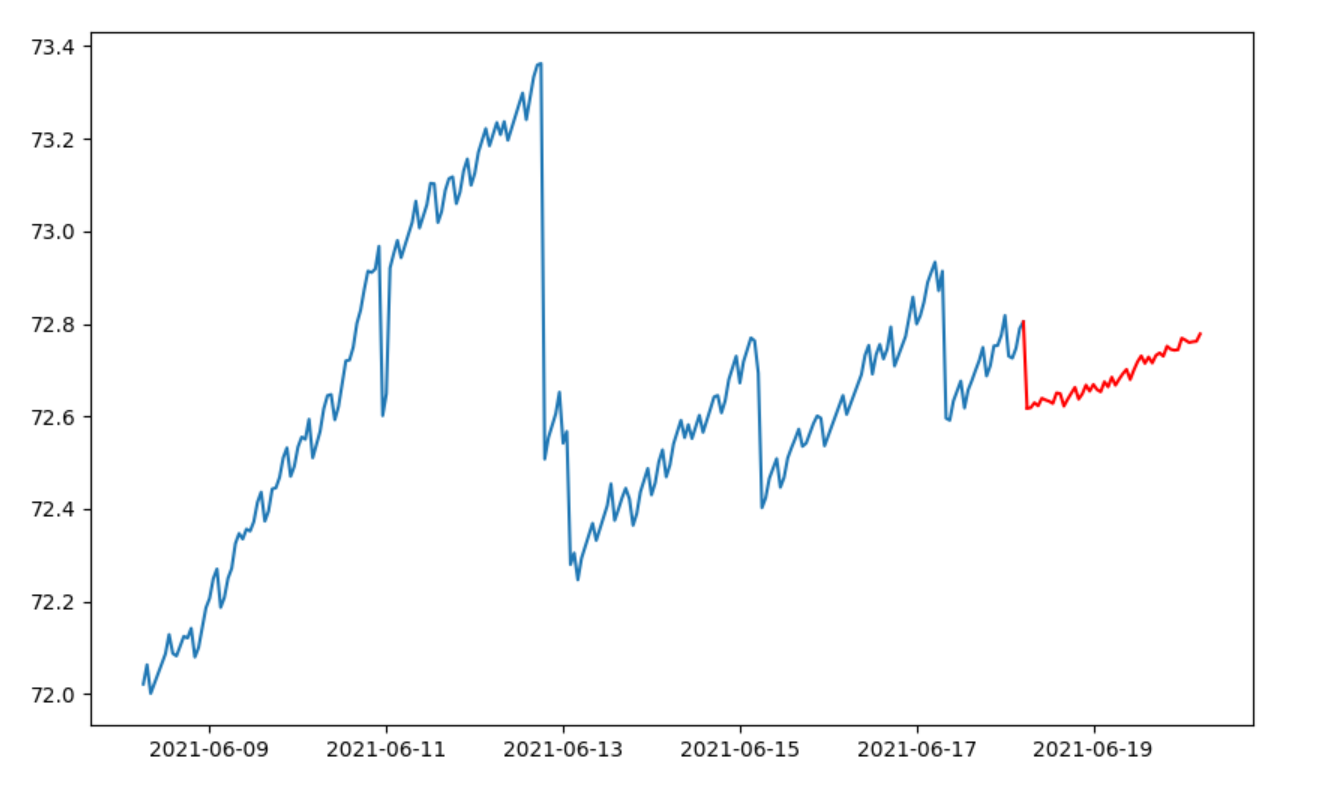
某硬盘使用率数据:由于硬盘有人在定期清理数据,所以在图像上会呈现断崖式下跌,
模型预测基本正确。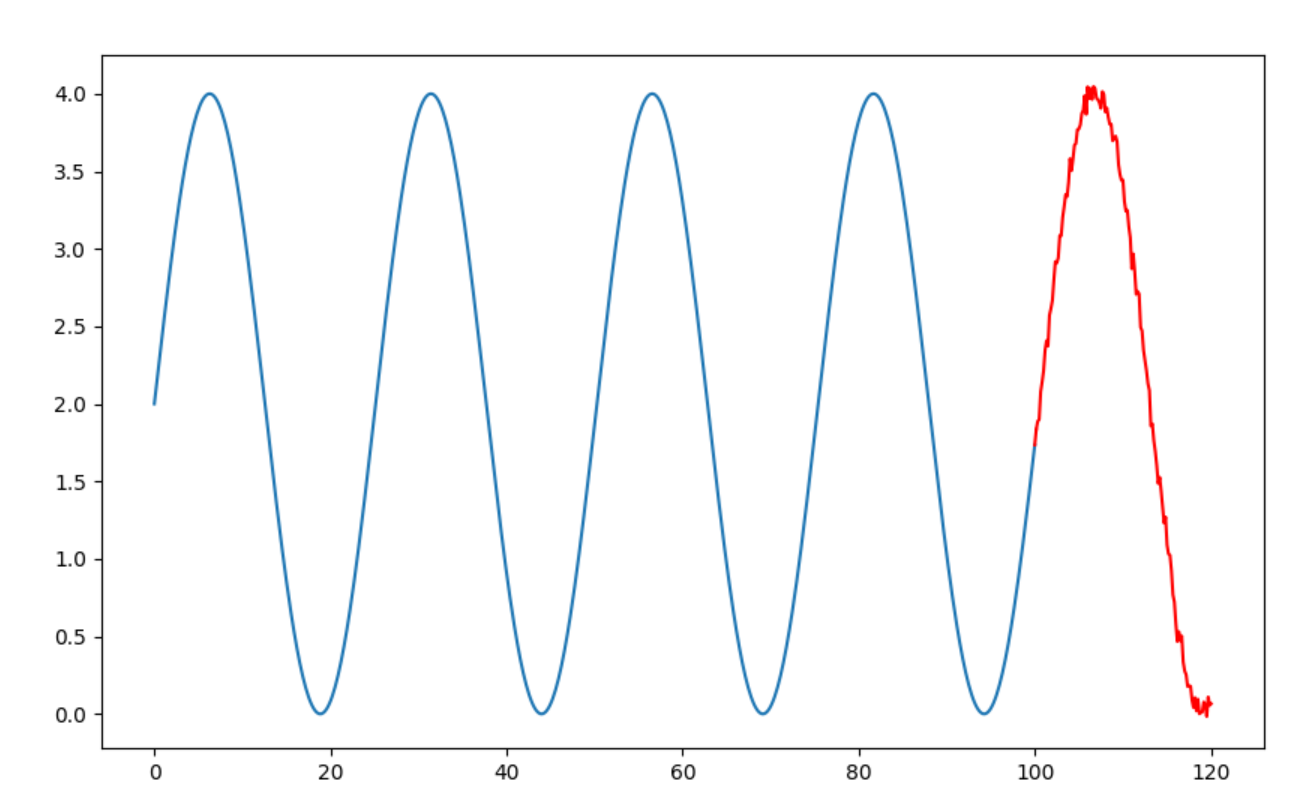
正弦函数:模型预测基本正确。
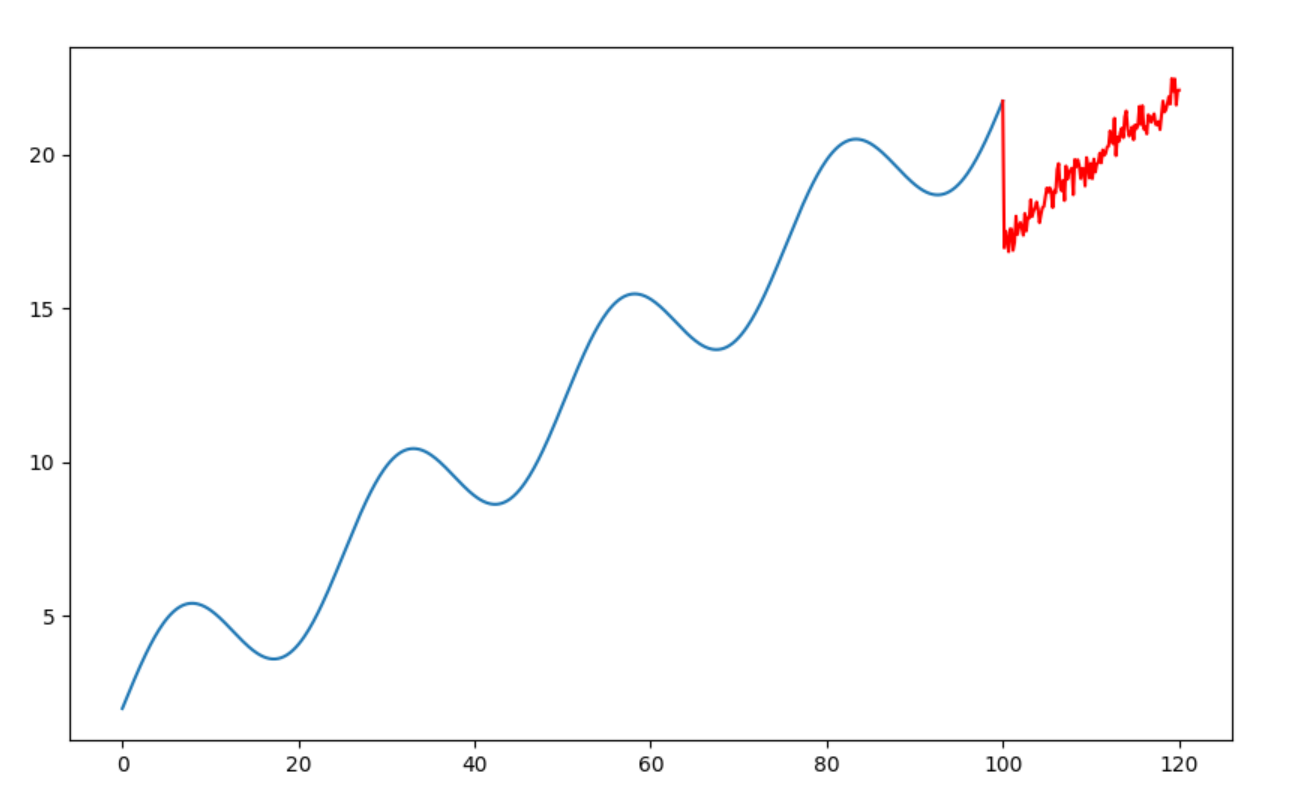
带上升趋势的正弦函数:从上图可以看到,模型的预测效果并不是很好。也就是说,对于同时含有趋势信息和周期信息的数据,该模型的预测结果不会很理想。
问题:
1 如何调整上述模型,使得它能够对同时含有趋势和周期信息的数据进行预测。
2 怎么调整模型参数,即 used_steps, forecasted_steps。
3 数据量过大或者过小怎么办。
4 数据缺失怎么解决。
5 在指定的训练轮次下,模型结果不收敛怎么解决。
6 为什么不设置测试集。

若有收获,就点个赞吧
0 人点赞
