解决方案概述
空气质量的好坏反映了空气污染程度,它是依据空气中污染物浓度的高低来判断的。空气污染是一个复杂的现象,在特定时间和地点空气污染物浓度受到许多因素影响。随着人们生活水平的逐步提高,对于生活环境的标准也日益提高。近年来,利用传感器、物联网技术,实现空气污染指数采集,并进行空气污染指数预报的技术已经日趋成熟。
本文以2021年上海市空气质量数据集为例,介绍一种基于DataFlux func服务快速实现空气质量数据采集,数据分析,并进行预测的解决方案。可划分为以下几个部分:
- 通过func爬取数据;
- 得到数据放到观测云里;
- 通过dql查数据,取到func里;
- 通过func兼容的算法包进行分析-建模-预测-验证;
- 通过观测云仪表盘进行可视化。
数据源说明
数据来源:http://tianqihoubao.com/
选取指标:date,level,AQI,AQI_rank,PM2.5,PM10,So2,No2,Co,O3
自变量:PM2.5,PM10,So2,No2,Co,O3
因变量:AQI
类别变量:level
(注:AQI,即空气质量指数(Air Quality Index),是定量描述空气质量状况的无量纲指数。)
可用库说明:
numpy==1.19.5;pandas==1.3.1;scipy==1.8.0;
adtk==0.6.2;statsmodels==0.13.2;scikit-learn==0.23.2
通过func爬取数据
数据采集主要通过func的API接口调用,将采集到的数据存储到观测云中,为下一步数据分析奠定基础。
面板数据概览: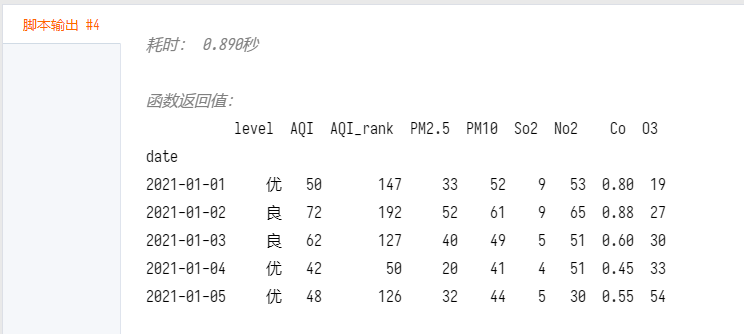
将数据放到观测云里并使用DQL查询
例如:
通过func兼容算法包进行分析-建模-预测-验证
平稳性检验:
#from statsmodels.tsa.stattools import adfuller, kpss
平稳性意味着时间序列的统计特性,即均值、方差和协方差不会随时间变化。许多统计模型要求序列是平稳的,才能做出有效和精确的预测。
将使用两个统计测试来检查时间序列的平稳性——Augmented Dickey Fuller (“ADF”) 测试和 Kwiatkowski-Phillips-Schmidt-Shin (“KPSS”) 测试。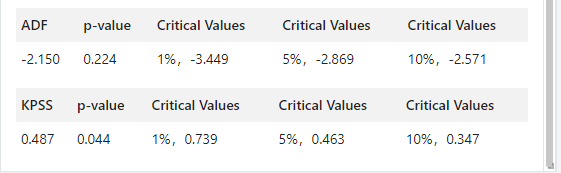
ADF 检验给出以下结果 - 检验统计量、p 值和 1%、5% 和 10% 置信区间的临界值。基于 0.05 的显着性水平和 ADF 检验的 p 值,不能拒绝原假设。因此,该系列是非平稳的。
KPSS 检验给出以下结果 - 检验统计量、p 值和 1%、5% 和 10% 置信区间基于 0.05 的显着性水平和 KPSS 检验的 p 值,有证据表明拒绝原假设而支持替代假设。因此,根据 KPSS 测试,该系列是非平稳的。
查看各变量之间的相关系数: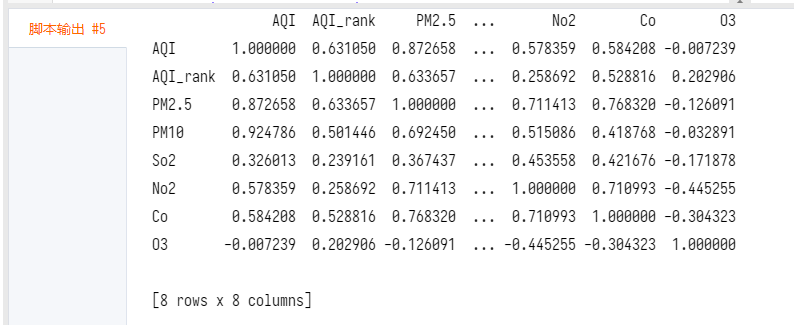
根据相关系数表,PM2.5和PM10与AQI的线性相关性最大,相关系数超过了0.8,其次是CO和NO2。但是,PM2.5与NO2、CO的相关系数超过了0.7,CO与NO2的相关系数也超过了0.7,即各因素间存在多重共线性,不满足相互独立的条件,不能直接进行线性回归,对此不用对数据进行平滑处理,因此选用随机森林预测AQI。
训练集和验证集为2021年上海全年的空气质量数据,训练集90%,验证集10%;
测试集为2022年一月上海整个月的数据。
训练集和验证集的统计分析: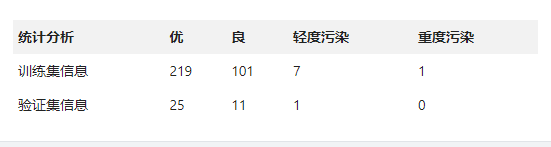
随机森林模型评估:
#from sklearn.ensemble import RandomForestClassifier
#from sklearn.ensemble import RandomForestRegressor
#from sklearn.preprocessing import LabelEncoder
#from sklearn.metrics import confusion_matrix
#from sklearn.metrics import classification_report
#from sklearn.model_selection import train_test_split
通过模型评估表得,所构建的随机森林预测AQI模型,训练集和验证集上拟合优度R^2分别为0.9502、0.9405,模型效果不错,可以用该模型对AQI进行预测。
预测结果显示: 黄色为预测值,绿色为真实值
黄色为预测值,绿色为真实值
通过观测云仪表盘进行可视化
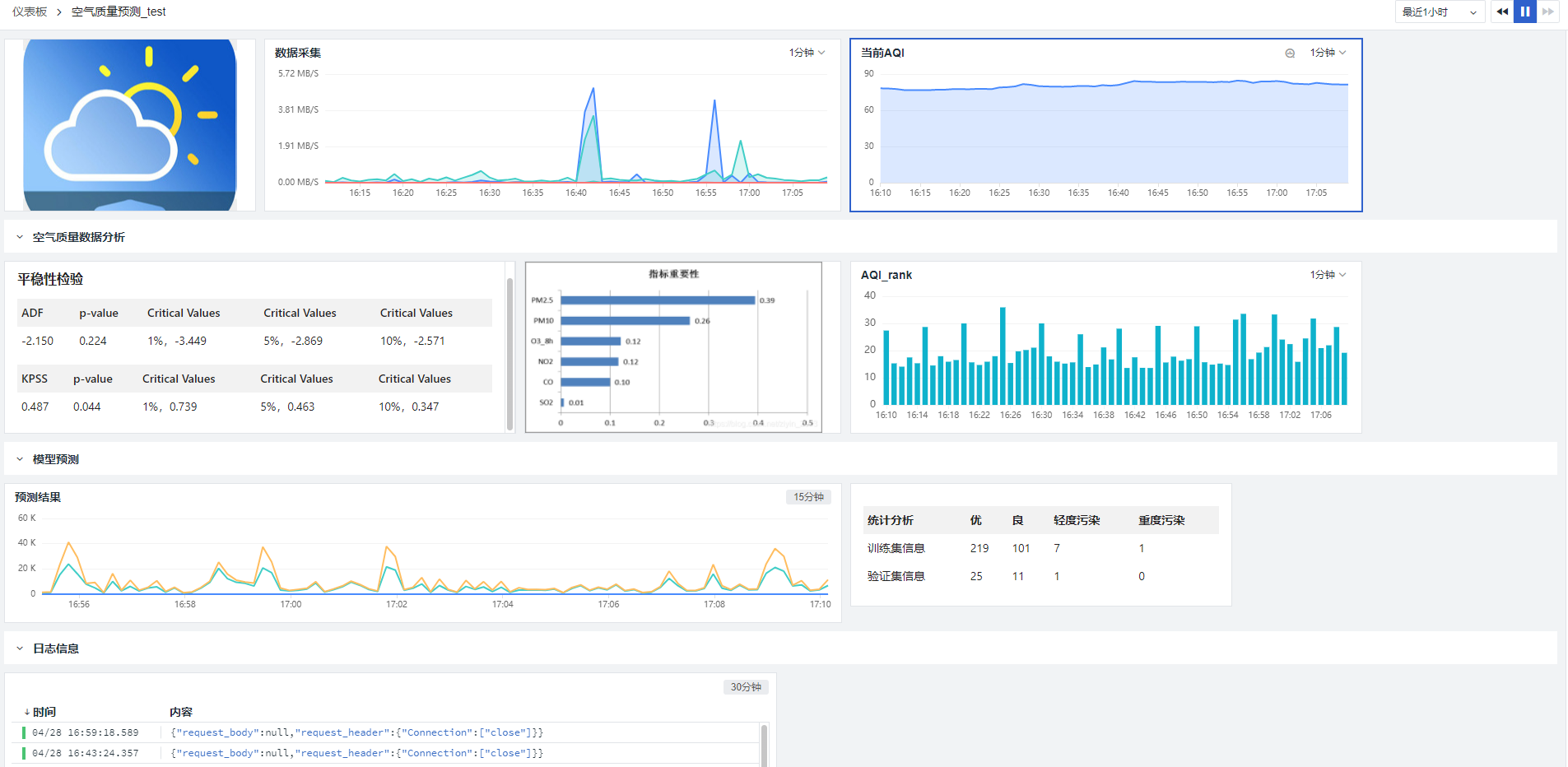
小结:
DataFlux Func对于全流程pipeline应用十分便捷,是一个基于Python 的脚本开发、管理、执行平台。使用者只需编写具体业务处理函数脚本,即可自动生成标准 HTTP API 接口,供外部系统调用完成具体任务。
观测云包含了数据采集、展现、自定义等功能,由数据采集器 DataKit,Function 函数平台和观测云中心组成。Datakit是在主机或者容器平台的 Agent 代理,负责数据采集和上报;观测云中心,是个强大的可观测平台,可使用DQL 数据查询语言和自定义的仪表盘。

若有收获,就点个赞吧
0 人点赞
