监控的意义
监控将系统和应用程序生成的指标转换为对应的业务价值;不构建指标或监控将存在严重的业务和运营风险,这将导致:
·无法识别或诊断故障;
·无法衡量应用程序的运行性能;
·无法衡量应用程序或组件的业务指标以及成功与否,例如跟踪销售数据或交易价值
四大黄金指标
Four Golden Signals是Google针对大量分布式监控的经验总结,4个黄金指标可以在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题。主要关注与以下四种类型的指标:延迟,通讯量,错误以及饱和度:
- Latency:延时(延迟)
- Utilization:使用率(流量,通讯量)
- Saturation:饱和度
- Errors:错误数或错误率
延迟:服务请求所需时间。
记录用户所有请求所需的时间,重点是要区分成功请求的延迟时间和失败请求的延迟时间。 例如在数据库或者其他关键祸端服务异常触发HTTP 500的情况下,用户也可能会很快得到请求失败的响应内容,如果不加区分计算这些请求的延迟,可能导致计算结果与实际结果产生巨大的差异。除此以外,在微服务中通常提倡“快速失败”,开发人员需要特别注意这些延迟较大的错误,因为这些缓慢的错误会明显影响系统的性能,因此追踪这些错误的延迟也是非常重要的。
通讯量:监控当前系统的流量,用于衡量服务的容量需求。
流量对于不同类型的系统而言可能代表不同的含义。例如,在HTTP REST API中, 流量通常是每秒HTTP请求数;
错误:监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。
对于失败而言有些是显式的(比如, HTTP 500错误),而有些是隐式(比如,HTTP响应200,单实际业务流程依然是失败的)。
对于一些显式的错误如HTTP 500可以通过在负载均衡器(如Nginx)上进行捕获,而对于一些系统内部的异常,则可能需要直接从服务中添加钩子统计并进行获取。
饱和度:衡量当前服务的饱和度。
主要强调最能影响服务状态的受限制的资源。 例如,如果系统主要受内存影响,那就主要关注系统的内存状态,如果系统主要受限与磁盘I/O,那就主要观测磁盘I/O的状态。因为通常情况下,当这些资源达到饱和后,服务的性能会明显下降。同时还可以利用饱和度对系统做出预测,比如,“磁盘是否可能在4个小时候就满了”。
这个四个黄金指标在在任何系统中都是很好的性能状态指标,他们之所以被称为”黄金“指标,很大一个因素是因为他们反映了终端用户的感知,因此任何监控系统都会提供被监控对象的这些指标或其变形,并在此基础上辅助:
- 问题定位 - 方便用户发现系统问题并最终修复或绕开系统问题
- 告警 - 提前对系统的不正常状况进行提示,避免系统进一步恶化
系统调优或容量预测 - 让用户针对性的对系统做出调整或增强,让其能更好的满足业务的需求。
USE&RED
这四个指标并不是唯一的系统性能或状况的衡量标准,系统可以简单分为两类
资源提供系统 - 对外提供简单的资源,比如CPU(计算资源),存储,网络带宽
- 服务提供系统 - 对外提供更高层次与业务相关的任务处理能力,比如订票,购物等等
针对资源提供型系统,有一个更简单直观的USE标准
- Utilization - 往往体现为资源使用的百分比(利用率)
- Saturation - 资源使用的饱和度或过载程度,过载的系统往往意味着系统需要辅助的排队系统完成相关任务。这个和上面的Utilization指标有一定的关系但衡量的是不同的状况,以CPU为例,Utilization往往是CPU的使用百分比而Saturation则是当前等待调度CPU的县城或进程队列长度
- Errors - 这个可能是使用资源的出错率或出错数量,比如网络的丢包率或误码率等等
针对服务型系统,则往往用RED方式进行衡量
- Rate - 单位时间内完成服务请求的能力(速率)
- Errors - 错误率或错误数量:单位时间内服务出错的比列或数量
- Duration - 平均单次服务的持续时长(或用户得到服务响应的时延)
RED 方法关注请求、实际工作以及外部视角(即来自服务消费方的视角)。
通过对黄金指标量化,能够确保系统在扩展时保持快速且可靠的运作效果。
每个人似乎都对这些指标的重要意义表示认同,但如何对相关指标进行关联和呈现加以实际的监控和量化?这是本文做的主要工作。
在本文当中,我们将关注重点放在由五种指标组成的简单超集身上:
1.速率:请求速率,请每秒请求数量。
2.错误: — 错误率,即每秒错误数量。
3.延迟:— 响应时间,包括队列 / 等待时间,以毫秒为单位。
4.饱和度:—即过载程度,这项指标与资源利用率相关,但也可通过队列深度(或者并发水平)等方式进行直接衡量。从队列深度的角度来理解,当系统逐渐趋于饱和时,队列深度将由零变为非零。饱和度指标通常体现为计数器形式。
5.利用率: — 资源或系统的繁忙程度。通常表示为 0% 至 100%,这项指标对预测而言非常重要(同样重要的还有饱和度指标)。请注意,这里我们并没有使用“利用率法则”的定义,即速率 x 服务时间 / 工作程序,而是选择了大家更为熟悉的直接衡量指标。
在上述指标当中,饱和度与利用率往往最难以衡量,且充满假设、提示与计算复杂性——因此将其视为近似值。
上述全部指标皆可通过多种方式进行拆分及 / 或合并。比如,错误的延迟等。虽然拆分或合并工作非常重要但其超出了本文的讨论范畴,在本文中,我们将着重于更基础的数据本身,而不会探讨更多与指标标准、事件、乃至高基数分析相关的复杂议题。
使用评分卡模型一个比较大的问题在于各个指标之间不具有相关性,很难通过做回归分析得到想要的数值划分。因此在第一版对于数值的设定上是基于对大量数据的观察和经验设定。此外,饱和度和利用率数据在第一版中未利用。因此着重关注前三个指标。
评分卡模型主要根据数据本身的各种属性和指标数据,利用评分模型,决定(1)是否报警(2)是否预警(3)应用程序的健康程度等信息,从而减少使用过程中存在的风险。在使用过程中,当黄金指标输出后评分进行决策。
健康度评分为所有指标在特定权重下的分数之和,系数为该指标的重要程度。
Score==aA+bB+cC+dD+eE
下表为当前方案: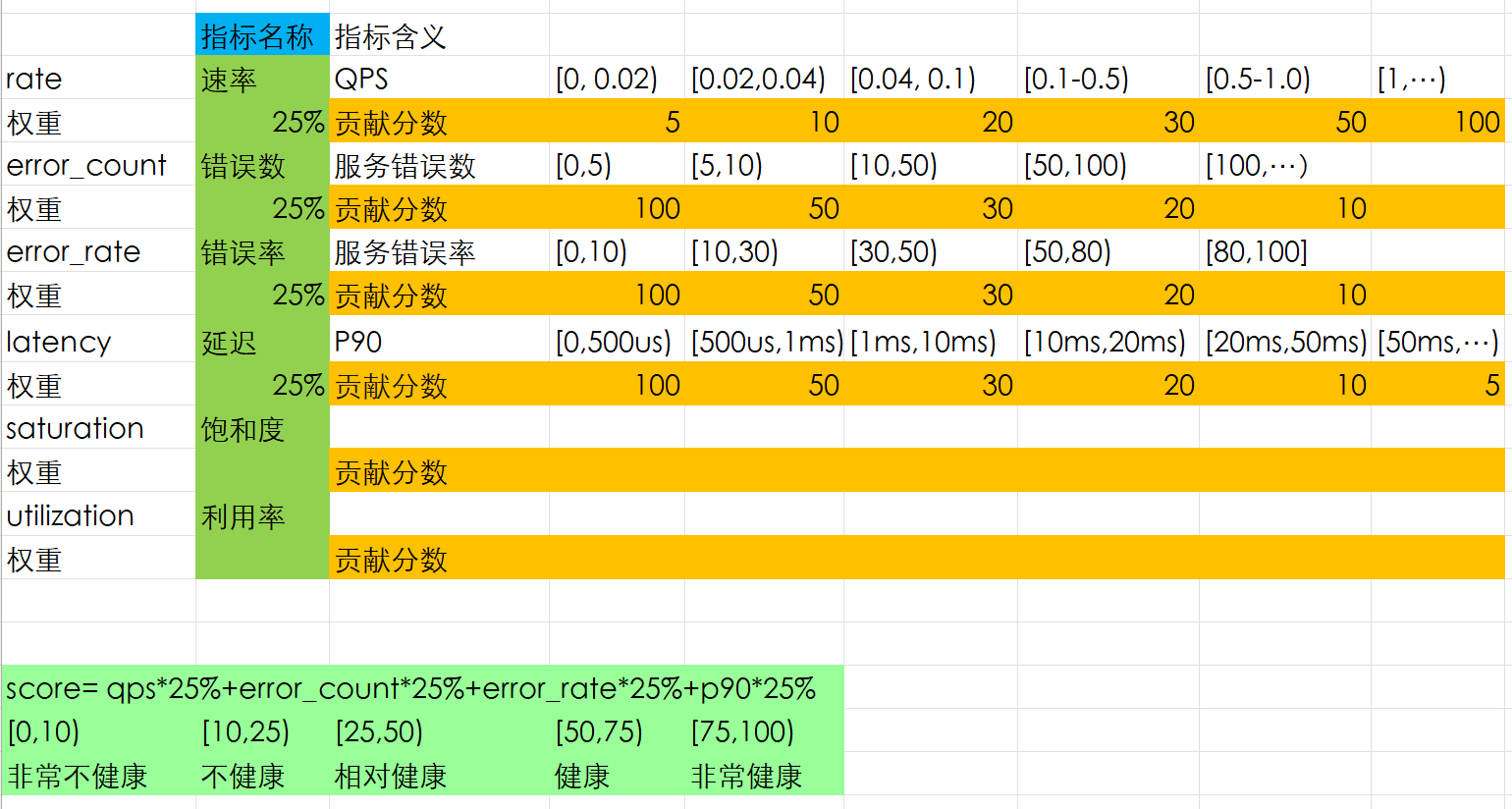

若有收获,就点个赞吧
0 人点赞
