0. 背景
watchdog v1 版本支持主机 Disk / IO 使用率、主机内存泄漏、APM 请求速率、APM 延时、APM 错误率 等 5 种智能巡检场景。
基于上述 5 种场景观测云侧 UI 需要支持如下功能:
- 创建智能巡检
- 查看智能巡检结果
1. 创建智能巡检
1.1 创建基础设施类智能巡检
包含:主机Disk / IO 使用率、主机内存泄漏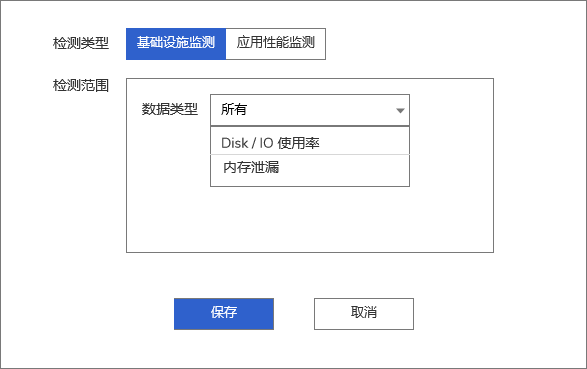
1.1.1 Disk / IO 使用率
检测粒度:host,device
数据点颗粒度(频率):1 分钟
检测数据范围:6 小时1.1.2 内存泄漏
检测粒度:host
数据点颗粒度(频率):1 分钟
检测数据范围:6 小时1.2 创建APM类智能巡检
包含:APM 请求速率、APM 延时、APM 错误率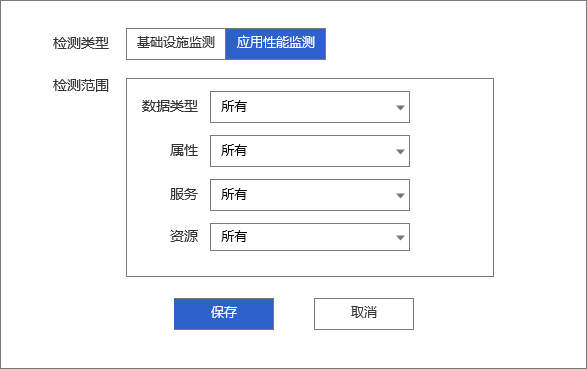
1.2.1 APM 请求速率
检测粒度:resource
数据点颗粒度(频率):1 分钟
检测数据范围:6 小时1.2.2 APM 延时
检测粒度:resource
数据点颗粒度(频率):1 分钟
检测数据范围:6 小时1.2.3 APM 错误率
检测粒度:resource
数据点颗粒度(频率):1 分钟
检测数据范围:6 小时
2. 字段定义
| 字段名 | 类型 | 说明 |
|---|---|---|
| date | interger | 智能巡检事件产生时间。Unix时间戳,单位 ms |
| df_event_id | string | 事件 id。注意:相同事件存在ongoing,resolved两种状态。 |
| df_status | string | 状态。智能巡检状态取值:ongoing , resolved |
| df_watchdog_category | string | 智能巡检分类。取值:apm , infrastructure |
| df_watchdog_type | string | 智能巡检类型。取值:disk_usage , mem_leak , apm_request_rate,apm_latency,apm_error_rate |
| df_watchdog_object | string | 智能巡检对象。取值:host,device,resource |
| df_watchdog_tags | string | 智能巡检对象标签。 |
| df_title | string | 标题。 |
| df_message | string | 详细内容。 |
3. 智能巡检事件内容
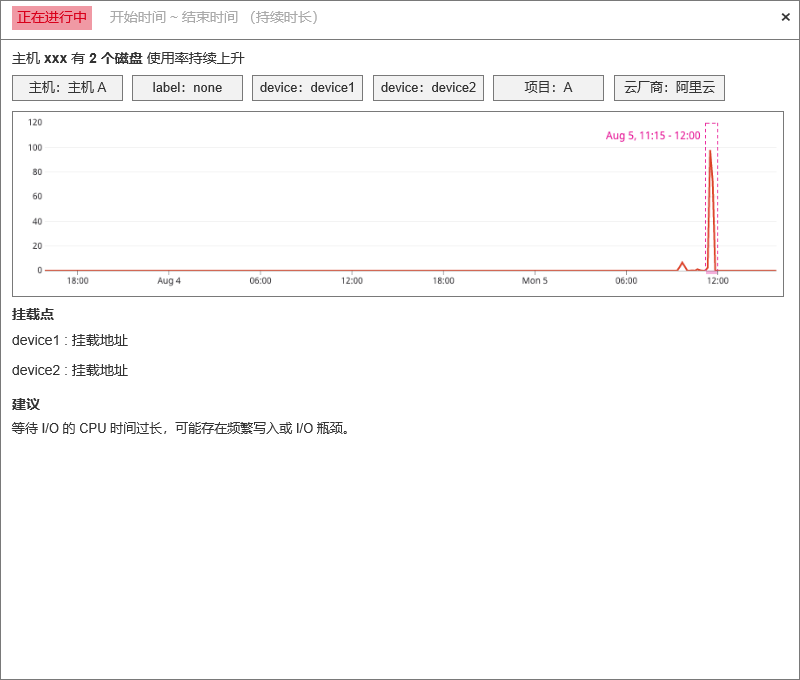
3.1 主机 Disk / IO 使用率
output 格式
| 字段 | 说明 |
|---|---|
| date | 智能巡检事件产生时间。Unix时间戳,单位 ms |
| df_event_id | 事件 id。注意:相同事件存在ongoing,resolved两种状态。 |
| df_status | 状态。取值:ongoing , resolved |
| df_watchdog_category | 巡检分类。取值:infrastructure |
| df_watchdog_type | 巡检类型。取值:disk_usage |
| df_watchdog_object | 巡检对象。取值: 主机(host) 磁盘(device) |
| df_watchdog_tags | 固定标签。取值: 项目(project) 云厂商(cloud_provider) Label 属性(df_label) |
| df_title | 固定格式。 主机 {#host} 有 {#N} 个磁盘使用率持续升高 |
| df_message | 固定格式。 - Disk 使用率趋势图 - 近 6 小时 Disk 使用率数据点 - 当前磁盘挂载点位置 - 获取问题 device 的挂载地址 - 建议信息 - 待补全 |
原型示例
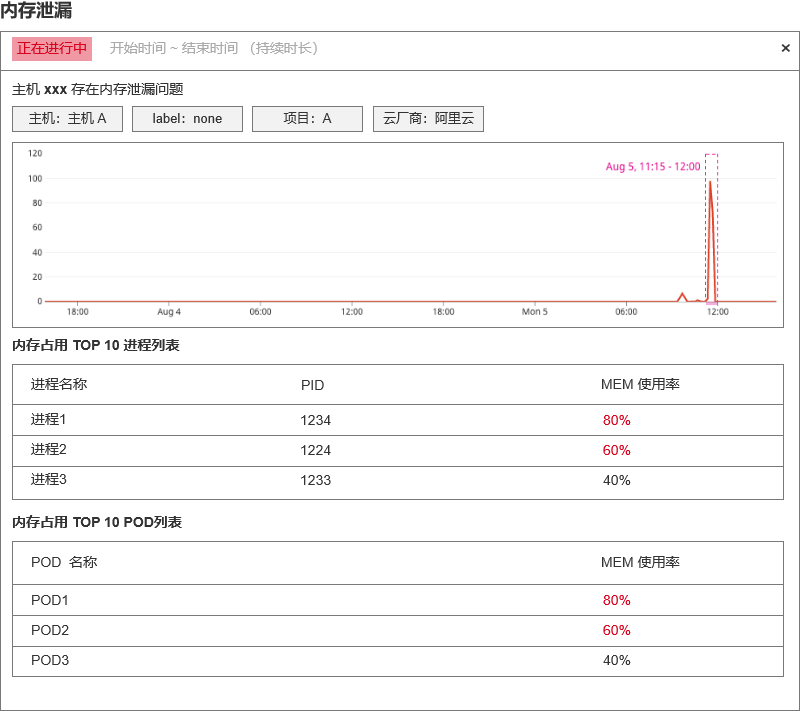
3.2 内存泄漏
output 格式
| 字段 | 说明 |
|---|---|
| date | 智能巡检事件产生时间。Unix时间戳,单位 ms |
| df_event_id | 事件 id。注意:相同事件存在ongoing,resolved两种状态。 |
| df_status | 状态。取值:ongoing , resolved |
| df_watchdog_category | 巡检分类。取值:infrastructure |
| df_watchdog_type | 巡检类型。取值:mem_leak |
| df_watchdog_object | 巡检对象。取值: 主机(host) |
| df_watchdog_tags | 固定标签。取值: 项目(project) 云厂商(cloud_provider) Label 属性(df_label) |
| df_title | 固定格式。 主机 {#host} 存在内存泄漏问题 |
| df_message | 固定格式。 - 内存率趋势图 - 近 6 小时内存使用率数据点 - 巡检对象上内存占用 TOP 10 进程列表 - process_name - pid - mem_usage - 巡检对象上内存占用 TOP 10 POD列表 - pod_name - mem_usage |
原型示例
3.3 APM 请求速率
output 格式
| 字段 | 说明 |
|---|---|
| date | 智能巡检事件产生时间。Unix时间戳,单位 ms |
| df_event_id | 事件 id。注意:相同事件存在ongoing,resolved两种状态。 |
| df_status | 状态。取值:ongoing , resolved |
| df_watchdog_category | 巡检分类。取值:apm |
| df_watchdog_type | 巡检类型。取值:apm_request_rate |
| df_watchdog_object | 巡检对象。取值: 资源(resource) |
| df_watchdog_tags | 固定标签。取值: 服务(service) 环境(env) 版本(version) 项目(project) |
| df_title | 固定格式。 {#service} 服务中有 {#N} 个资源请求速率异常 |
| df_message | 固定格式。 - 资源请求速率趋势图 - 近 6 小时资源请求速率数据点 - 资源请求速率异常结果 - 资源(resource) - 请求速率(request_rate) - 异常资源关联的span 列表 - 异常资源关联 trace_id列表 - 基于异常 trace_id 的 service_map —- 前端查询获得 - 基于异常 trace_id 关联的 前端应用、用户数、页面地址 - 查询 RUM View 数据获取 app_id,userid,view_url 具体值及数量统计值 |
原型示例
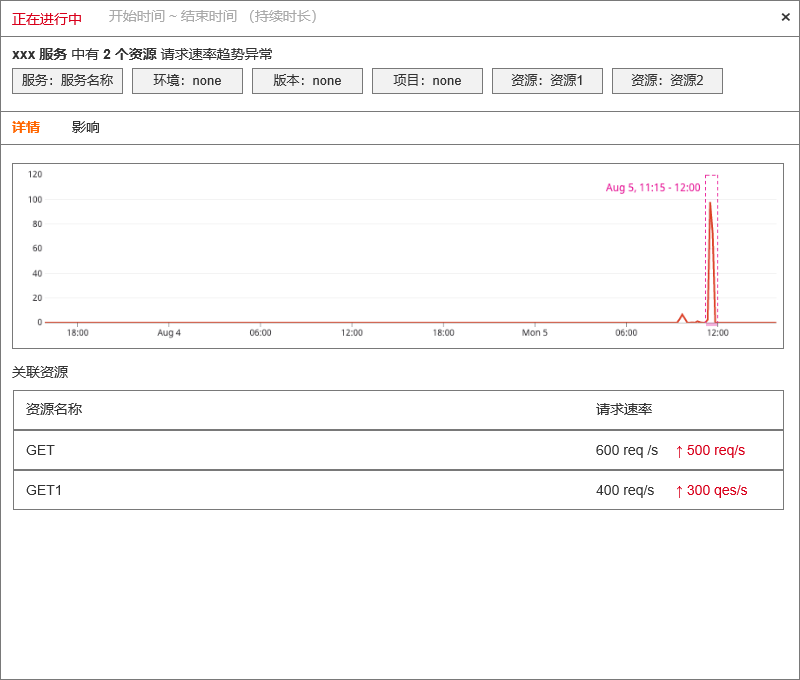
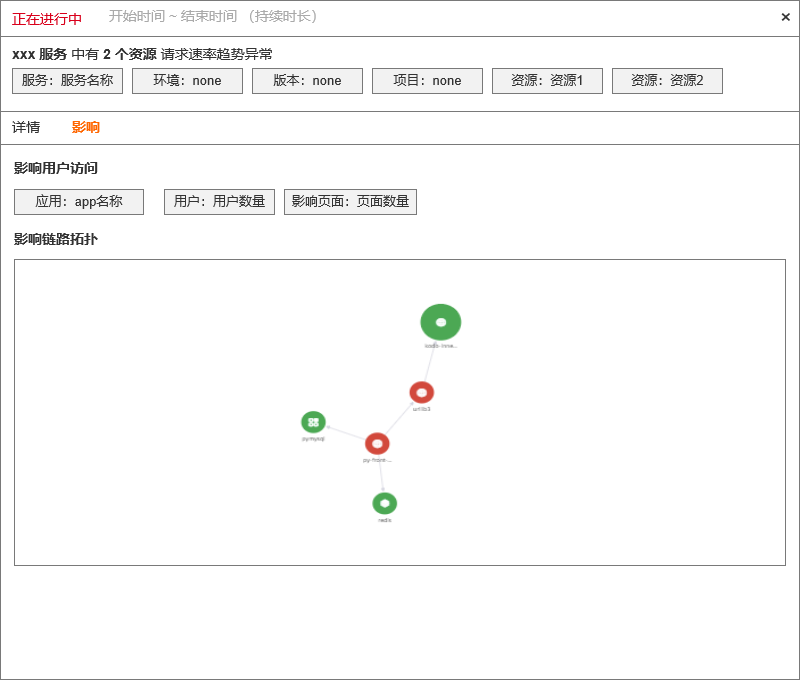
3.4 APM 延时
output 格式
| 字段 | 说明 |
|---|---|
| date | 智能巡检事件产生时间。Unix时间戳,单位 ms |
| df_event_id | 事件 id。注意:相同事件存在ongoing,resolved两种状态。 |
| df_status | 状态。取值:ongoing , resolved |
| df_watchdog_category | 巡检分类。取值:apm |
| df_watchdog_type | 巡检类型。取值:apm_latency |
| df_watchdog_object | 巡检对象。取值: 资源(resource) |
| df_watchdog_tags | 固定标签。取值: 服务(service) 环境(env) 版本(version) 项目(project) |
| df_title | 固定格式。 {#service} 服务中有 {#N} 个资源延时波动异常 |
| df_message | 固定格式。 - 资源延时趋势图 - 近 6 小时资源延时数据点 - 资源延时异常结果 - 资源(resource) - 延时(duration) - 异常资源关联的span 列表 - 异常资源关联 trace_id列表 - 基于异常 trace_id 的 service_map —- 前端查询获得 - 基于异常 trace_id 关联的 前端应用、用户数、页面地址 - 查询 RUM View 数据获取 app_id,userid,view_url 具体值及数量统计值 |
原型示例
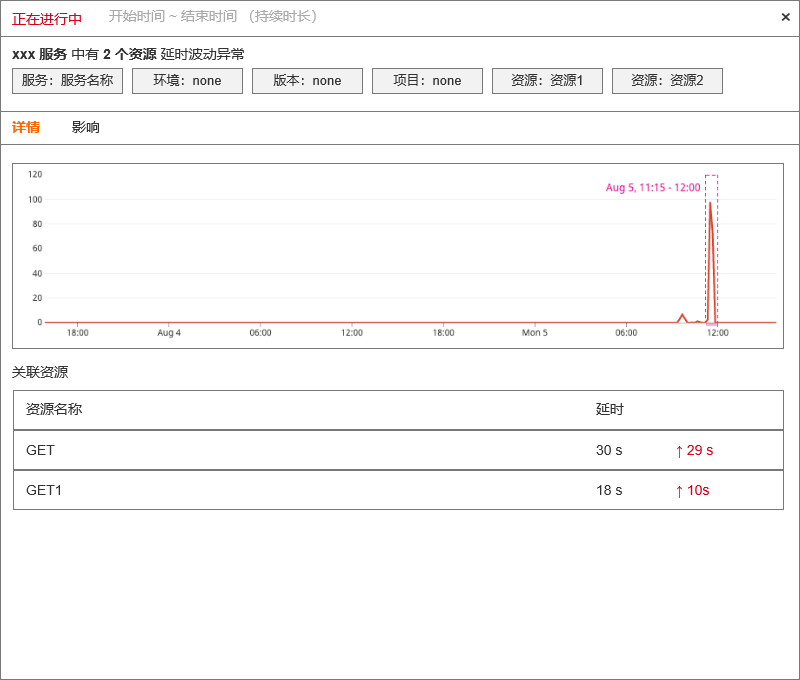
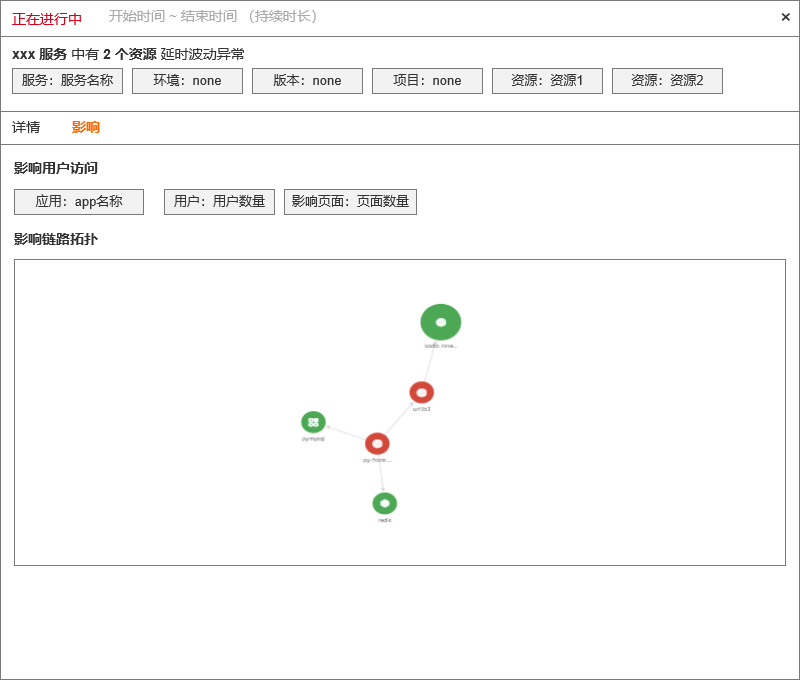
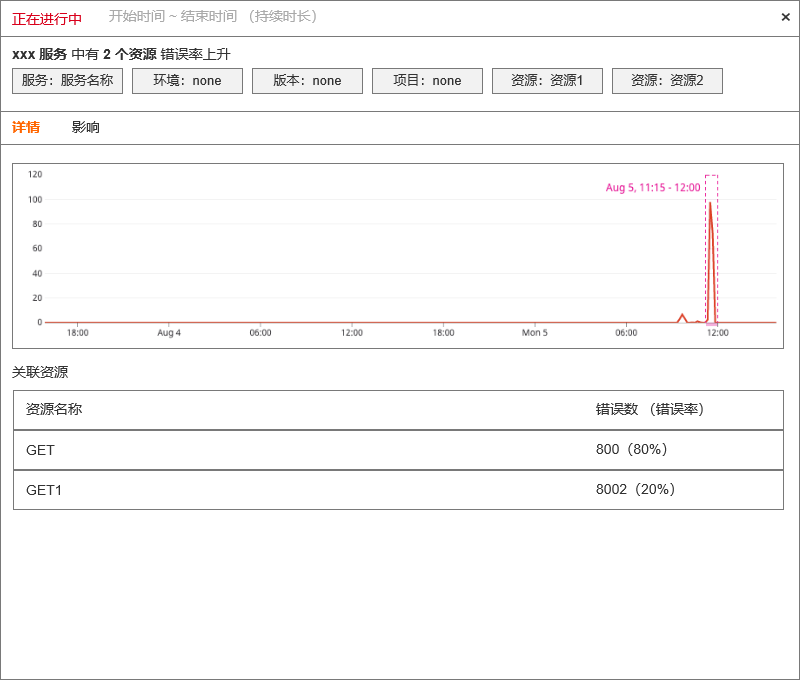
3.5 APM 错误率
output 格式
| 字段 | 说明 |
|---|---|
| date | 智能巡检事件产生时间。Unix时间戳,单位 ms |
| df_event_id | 事件 id。注意:相同事件存在ongoing,resolved两种状态。 |
| df_status | 状态。取值:ongoing , resolved |
| df_watchdog_category | 巡检分类。取值:apm |
| df_watchdog_type | 巡检类型。取值:apm_error_rate |
| df_watchdog_object | 巡检对象。取值: 资源(resource) |
| df_watchdog_tags | 固定标签。取值: 服务(service) 环境(env) 版本(version) 项目(project) |
| df_title | 固定格式。 {#service} 服务中有 {#N} 个资源导致错误率上升 |
| df_message | 固定格式。 - 资源错误率分布趋势图 - 近 6 小时资源错误率数据点 - 资源延时异常结果 - 资源(resource) - 错误数(error_count) - 错误率(error_rate) - 异常资源关联的span 列表 - 异常资源关联 trace_id列表 - 基于异常 trace_id 的 service_map —- 前端查询获得 - 基于异常 trace_id 关联的 前端应用、用户数、页面地址 - 查询 RUM View 数据获取 app_id,userid,view_url 具体值及数量统计值 |
原型示例

4. 巡检事件数据获取 DQL
服务异常检测
请求数(线)—- 获取服务一分钟内的所有请求数量,加上时间范围查询即可得出服务的每分钟请求数变化趋势
T::re(.*):(sum(r_request_count)) {source = ‘service_list_1m’} [::1m] by r_service
错误数(线)—- 获取服务一分钟内的所有错误请求数量,加上时间范围查询即可得出服务每分钟错误请求数变化趋势
T::re(.*):(sum(r_error_count)) {source = ‘service_list_1m’} [::1m] by r_service
错误率(线)—- 获取服务一分钟内的请求错误率,加上时间范围查询即可得出服务每分钟的错误率变化趋势
eval(A/B100, A=”T::re(`.):(sum(r_error_count)) {source = 'service_list_1m'} [::1m] by r_service", B="T::re(.*`):(sum(r_request_count)) {source = ‘service_list_1m’} [::1m] by r_service”)
平均响应时间(线)—- 获取服务一分钟内的平均响应时间,加上时间范围查询即可得出服务每分钟的平均响应时间变化趋势
eval(A/B,A=”T::re(.*):(sum(r_resp_time)) {source = ‘service_list_1m’} [::1m] by r_service”,B=”T::re(.*):(sum(r_request_count)) {source = ‘service_list_1m’} [::1m] by r_service”)
QPS(线)—- 获取服务一分钟内的所有请求数量,除以60 秒,加上时间范围查询即可得出服务的QPS(每秒请求速率)变化趋势
eval(A/60,A=”T::re(.*):(sum(r_request_count)) {source = ‘service_list_1m’} [::1m] by r_service”)
P90(点)
接口文档:https://confluence.jiagouyun.com/pages/viewpage.action?pageId=139763636
找杨智对下实际实现
RUM 关联数据查询 — 关联影响服务、影响用户、影响页面
前提:需要用户 SDK 中配置 service ,username 信息。service 填写:SDK 引入时,username :通过自定义 tag 标注用户名信息
1)影响服务数量和服务名称 — 通过 APM 的异常服务列表跟 RUM 的服务列表求交集获得
R::view:(count_distinct(service),distinct(service)) {service = #{服务}} [异常开始时间:结束时间]
2)影响用户数量和用户名称
R::view:(count_distinct(userid),distinct(username)) {service = #{服务}} [异常开始时间:结束时间]
3)影响页面数量和页面名称
R::view:(count_distinct(view_url),distinct(view_url)) {service = #{服务}} [异常开始时间:结束时间]

若有收获,就点个赞吧
0 人点赞
